


2 Key LLMOps Concepts
2 Key LLMOps Concepts
How to monitor LLM & RAG applications. Evaluate your RAG like a pro. Learn about memory/compute requirements on LLMs.

Decoding ML Notes
This week’s topics:
A powerful framework to evaluate RAG pipelines
Why do LLMs require so much VRAM?
LLMOps Chain Monitoring
𝗢𝗻𝗲 𝗳𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 𝘁𝗼 𝗲𝘃𝗮𝗹𝘂𝗮𝘁𝗲 𝘆𝗼𝘂𝗿 𝗥𝗔𝗚 - 𝗥𝗔𝗚𝗔𝘀
Building an RAG pipeline is fairly simple. You just need a Vector-DB knowledge base, an LLM to process your prompts, plus additional logic for interactions between these modules.
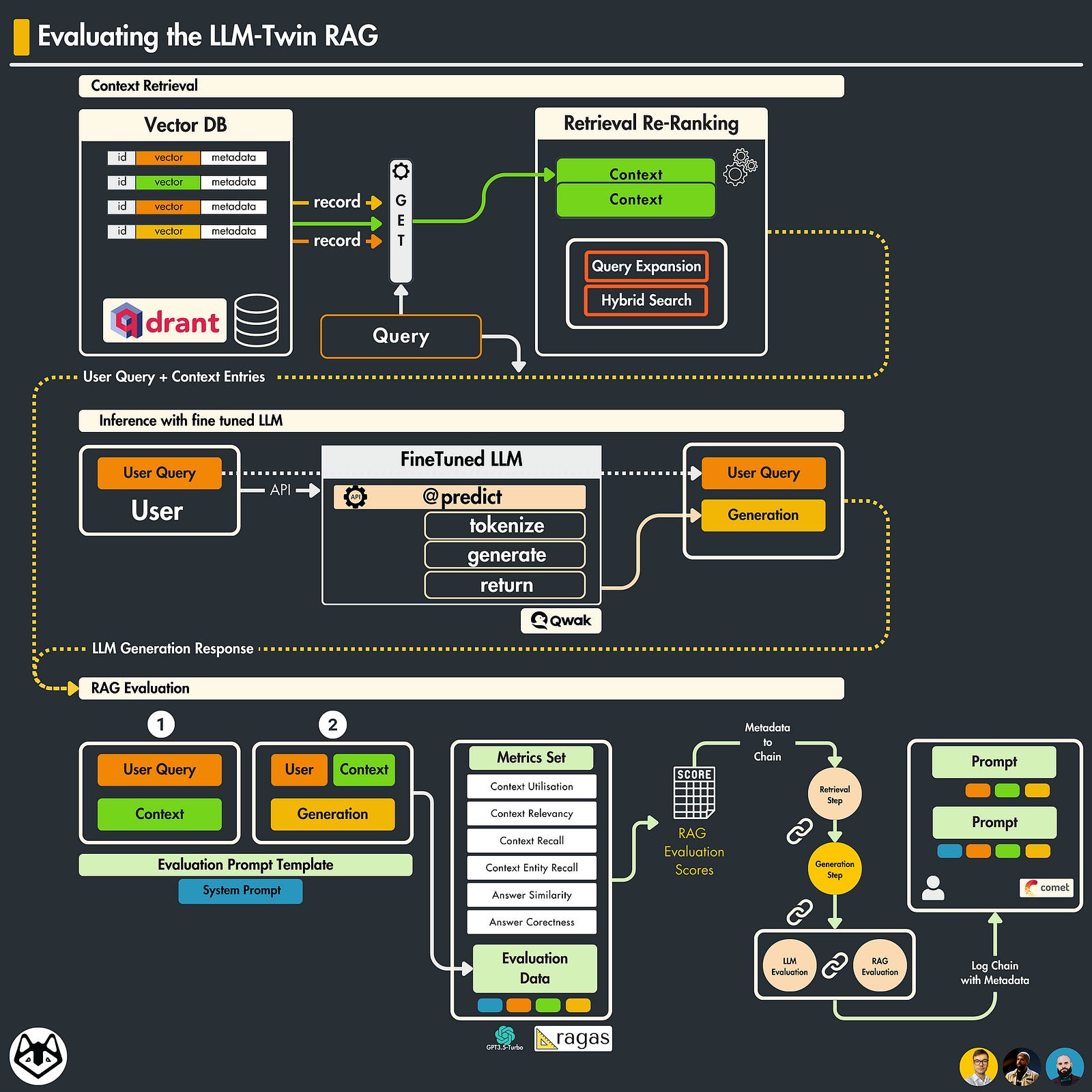
However, reaching a satisfying performance level imposes its challenges due to the “separate” components:
Retriever — which takes care of querying the Knowledge DB and retrieves additional context that matches the user’s query.
Generator — which encompasses the LLM module, generating an answer based on the context-augmented prompt. When evaluating a RAG pipeline, we must evaluate both components separately and together.
🔸 What is RAGAs?
A framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. One of the core concepts of RAGAs is Metric-Driven-Development (MDD) which is a product development approach that relies on data to make well-informed decisions.
🔸 What metrics do RAGAs expose?
🔽 For 𝗥𝗲𝘁𝗿𝗶𝗲𝘃𝗮𝗹 Stage :
↳ 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗣𝗿𝗲𝗰𝗶𝘀𝗶𝗼𝗻 Evaluates the precision of the context used to generate an answer, ensuring relevant information is selected from the context
↳ 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗥𝗲𝗹𝗲𝘃𝗮𝗻𝗰𝘆 Measures how relevant the selected context is to the question. ↳ 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗥𝗲𝗰𝗮𝗹𝗹 Measures if all the relevant information required to answer the question was retrieved.
↳ 𝗖𝗼𝗻𝘁𝗲𝘅𝘁 𝗘𝗻𝘁𝗶𝘁𝗶𝗲𝘀 𝗥𝗲𝗰𝗮𝗹𝗹 Evaluates the recall of entities within the context, ensuring that no important entities are overlooked.
🔽 For 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 Stage :
↳ 𝗙𝗮𝗶𝘁𝗵𝗳𝘂𝗹𝗻𝗲𝘀𝘀 Measures how accurately the generated answer reflects the source content, ensuring the generated content is truthful and reliable.
↳ 𝗔𝗻𝘀𝘄𝗲𝗿 𝗥𝗲𝗹𝗲𝘃𝗮𝗻𝗰𝗲 It is validating that the response directly addresses the user’s query.
↳ 𝗔𝗻𝘀𝘄𝗲𝗿 𝗦𝗲𝗺𝗮𝗻𝘁𝗶𝗰 𝗦𝗶𝗺𝗶𝗹𝗮𝗿𝗶𝘁𝘆 Shows that the generated content is semantically aligned with expected responses.
↳ 𝗔𝗻𝘀𝘄𝗲𝗿 𝗖𝗼𝗿𝗿𝗲𝗰𝘁𝗻𝗲𝘀𝘀 Focuses on fact-checking, assessing the factual accuracy of the generated answer.
🔸 How to evaluate using RAGAs?
1. Prepare your 𝘲𝘶𝘦𝘴𝘵𝘪𝘰𝘯𝘴,𝘢𝘯𝘴𝘸𝘦𝘳𝘴,𝘤𝘰𝘯𝘵𝘦𝘹𝘵𝘴 and 𝘨𝘳𝘰𝘶𝘯𝘥_𝘵𝘳𝘶𝘵𝘩𝘴
2. Compose a Dataset object
3. Select metrics
4. Evaluate
5. Monitor scores or log the entire evaluation chain to a platform like CometML.
For a full end-to-end workflow of RAGAs evaluation in practice, I've described it in this LLM-Twin Course Article 👇:
Why are LLMs so Memory-hungry?
LLMs require lots of GPU memory, but let's see why that's the case. 👇

🔸 What is an LLM parameter?
LLMs, like Mistral 7B or LLama3-8B, have billions of parameters. 𝗘𝗮𝗰𝗵 𝗽𝗮𝗿𝗮𝗺𝗲𝘁𝗲𝗿 𝗶𝘀 𝗮 𝘄𝗲𝗶𝗴𝗵𝘁 stored and accessed during computation.
🔸 How much GPU VRAM is required? There are three popular precision formats that LLMs are trained in:
→ FP32 - 32bits floating point
→ FP16/BFP16 - 16 bits floating point
Most use mixed precision, e.g., matmul in BFP16 and accumulations in FP32.
For this example, we'll use half-precision BFP16.
Here's a deeper dive on this topic:
🔗 Google BFloat16
🔗 LLMs Precision Benchmark
🔹 Let's calculate the VRAM required:
As 1byte=8bits, we've got:
→ FP32 = 32 bits = 4 bytes
→ FP16/BFP16 = 16bits = 2 bytes
Now, for a 7B model, we would require:
→ VRAM = 7 * 10^9 (billion) * 2 bytes = 14 * 10^9 bytes
Knowing that 1GB = 10 ^ 9 bytes we have 𝟭𝟰𝗚𝗕 as the required VRAM to load a 𝟳𝗕 𝗺𝗼𝗱𝗲𝗹 𝗳𝗼𝗿 𝗶𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲 in half BF16 precision.
𝗧𝗵𝗶𝘀 𝗶𝘀 𝗽𝘂𝗿𝗲𝗹𝘆 𝗳𝗼𝗿 𝗹𝗼𝗮𝗱𝗶𝗻𝗴 𝘁𝗵𝗲 𝗽𝗮𝗿𝗮𝗺𝗲𝘁𝗲𝗿𝘀.
Ever encountered the 𝗖𝗨𝗗𝗔 𝗢𝗢𝗠 Error e.g "𝘛𝘳𝘪𝘦𝘥 𝘵𝘰 𝘢𝘭𝘭𝘰𝘤𝘢𝘵𝘦 +56𝘔𝘉 ..." when inferencing? here's the most plausible cause for that:
⭕ No GPU VRAM left for the activations. Let's figure out the activation size required by using 𝗟𝗟𝗮𝗺𝗮𝟮-𝟳𝗕 as an example.
🔸 Activations are a combination of the following model parameters:
- Context Length (N)
- Hidden Size (H)
- Precision (P)
After a quick look at the LLama2-7b model configuration, we get these values:
- Context Length (N) = 4096 tokens
- Hidden Size (H) = 4096 dims
- Precision (P) = BF16 = 2bytes
🔗 𝗟𝗟𝗮𝗺𝗮𝟮-𝟳𝗯 𝗠𝗼𝗱𝗲𝗹 𝗣𝗮𝗿𝗮𝗺𝘀: shorturl.at/CWOJ9
Consult this interactive LLM-VRAM calculator to check on the different memory segments reserved when inferencing/training LLMs.
🟢 Inference/Training VRAM Calculator
🟡 For training, things stay a little different, as more factors come into play, as memory is allocated for:
↳ Full Activations considering N(Heads) and N( Layers)
↳ Optimizer States which differ based on the optimizer type
↳ Gradients
Here's a tutorial on PEFT, QLoRA fine-tuning in action 👇:
Other Resources:
📔 Model Anatomy: shorturl.at/nJeu0
📔 VRAM for Serving: shorturl.at/9UPBE
📔 LLM VRAM Explorer: shorturl.at/yAcTU
One key LLMOps concept - Chain Monitoring
In traditional ML systems, it is easier to backtrack to a problem compared to Generative AI ones based on LLMs. When working with LLMs, their generative nature can lead to complex and sometimes unpredictable behavior.
🔹 𝗔 𝘀𝗼𝗹𝘂𝘁𝗶𝗼𝗻 𝗳𝗼𝗿 𝘁𝗵𝗮𝘁?
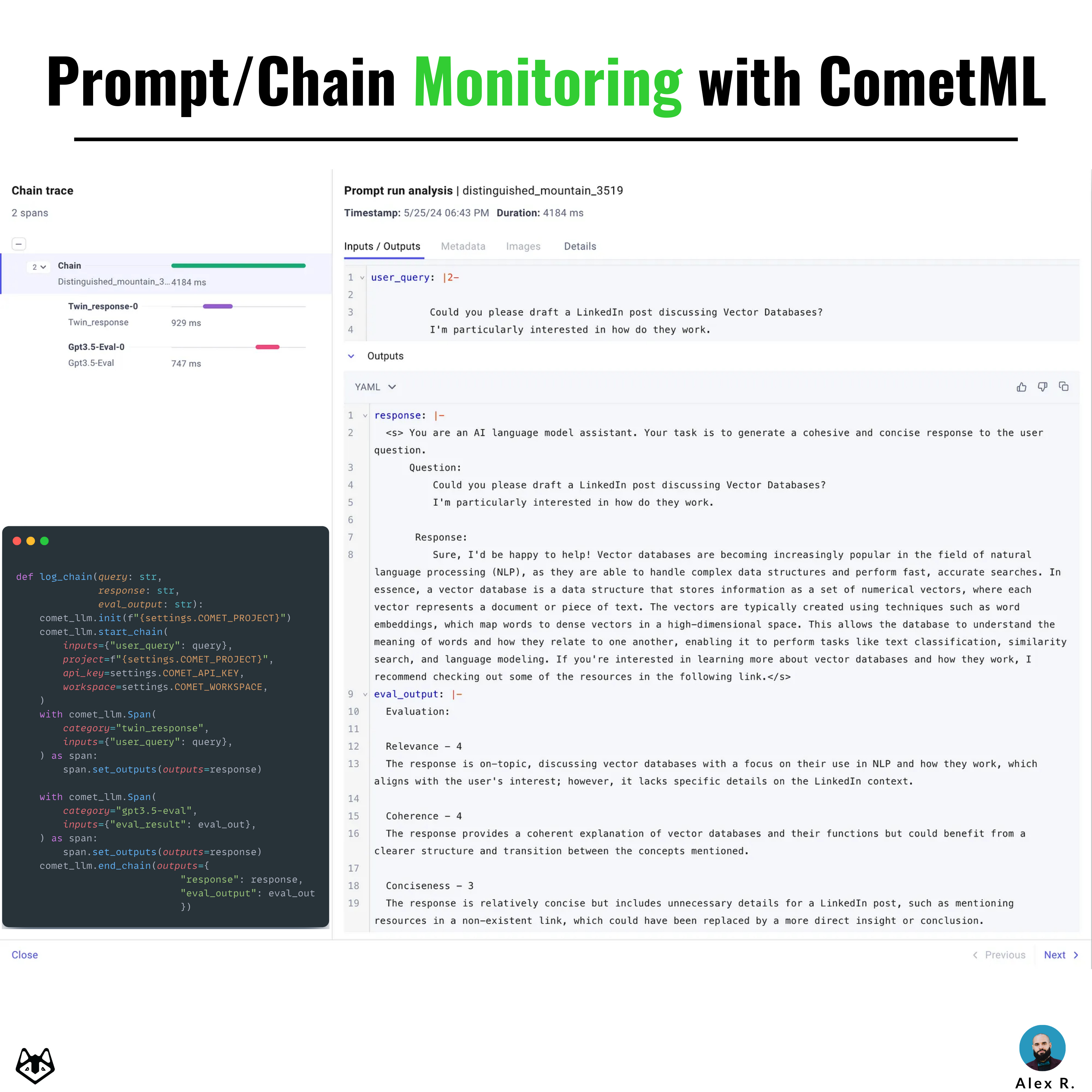
"Log prompts or entire chains with representative metadata when testing/evaluating your LLM." 𝘖𝘯𝘦 𝘱𝘭𝘢𝘵𝘧𝘰𝘳𝘮 𝘵𝘩𝘢𝘵 𝘐 𝘭𝘪𝘬𝘦 𝘢𝘯𝘥 𝘐'𝘷𝘦 𝘣𝘦𝘦𝘯 𝘶𝘴𝘪𝘯𝘨 𝘧𝘰𝘳 𝘵𝘩𝘪𝘴 𝘵𝘢𝘴𝘬 𝘪𝘴 𝗖𝗼𝗺𝗲𝘁𝗠𝗟 - 𝗟𝗟𝗠.
🔸 𝗛𝗲𝗿𝗲 𝗮𝗿𝗲 𝗮 𝗳𝗲𝘄 𝗰𝗮𝘀𝗲𝘀 𝘄𝗵𝗲𝗿𝗲 𝗶𝘁 𝗽𝗿𝗼𝘃𝗲𝘀 𝗯𝗲𝗻𝗲𝗳𝗶𝗰𝗶𝗮𝗹:
→ 𝗙𝗼𝗿 𝗦𝘂𝗺𝗺𝗮𝗿𝗶𝘀𝗮𝘁𝗶𝗼𝗻 𝗧𝗮𝘀𝗸𝘀
Here you might have a query that represents the larger text, the LLMs response which is the summary, and you could calculate the ROUGE score inline between query & response and add it to the metadata field. Then you can compose a JSON with query, response, and rouge_score and log it to comet.
→ 𝗙𝗼𝗿 𝗤&𝗔 𝗧𝗮𝘀𝗸𝘀 Here, you could log the Q&A pairs separately, or even add an evaluation step using a larger model to evaluate the response. Each pair would be composed of Q, A, GT, and True/False to mark the evaluation.
↳ 𝗙𝗼𝗿 𝗚𝗲𝗻𝗲𝗿𝗮𝘁𝗶𝗼𝗻 𝗧𝗮𝘀𝗸𝘀 You could log the query and response, and append in the metadata a few qualitative metrics (e.g. relevance, cohesiveness).
↳𝗙𝗼𝗿 𝗥𝗔𝗚 If you have complex chains within your RAG application, you could log prompt structures (sys_prompt, query), and LLM responses and track the chain execution step by step.
↳ 𝗙𝗼𝗿 𝗡𝗘𝗥 You could define the entity fields and log the query, response, entities_list, and extracted_entities in the same prompt payload.
↳𝗙𝗼𝗿 𝗩𝗶𝘀𝗶𝗼𝗻 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿𝘀 CometML LLM also allows you to log images associated with a prompt or a chain. If you’re working with GPT4-Vision for example, you could log the query and the generated image in the same payload.
Also, besides the actual prompt payload, you could inspect the processing time per each step of a chain.
For example, a 3-step chain in an RAG application might query the Vector DB, compose the prompt, and pass it to the LLM, and when logging the chain to CometML, you could see the processing time/chain step.
🔹 𝗧𝗼 𝘀𝗲𝘁 𝗶𝘁 𝘂𝗽, 𝘆𝗼𝘂'𝗹𝗹 𝗻𝗲𝗲𝗱:
- CometML pip package
- CometML API key - Workspace name and Project Name
I've used this approach when evaluating a fine-tuned LLM on a custom instruction dataset. For a detailed walkthrough 👇
Images
If not otherwise stated, all images are created by the author.