



An End-to-End Framework for Production-Ready LLM Systems by Building Your LLM Twin
From data gathering to productionizing LLMs using LLMOps good practices.

→ the 1st out of 11 lessons of the LLM Twin free course
What is your LLM Twin? It is an AI character that writes like yourself by incorporating your style, personality and voice into an LLM.

Why is this course different?
By finishing the “LLM Twin: Building Your Production-Ready AI Replica” free course, you will learn how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices.
Why should you care? 🫵
→ No more isolated scripts or Notebooks! Learn production ML by building and deploying an end-to-end production-grade LLM system.
More details on what you will learn within the LLM Twin course, here 👈
Are you ready to build your AI replica? 🫢
Let’s start with Lesson 1 ↓↓↓
Lesson 1: End-to-end framework for production-ready LLM systems
In the first lesson, we will present the project you will build during the course: your production-ready LLM Twin/AI replica.
Afterward, we will dig into the LLM project system design.
We will present all our architectural decisions regarding the design of the data collection pipeline for social media data and how we applied the 3-pipeline architecture to our LLM microservices.
In the following lessons, we will examine each component’s code and learn how to implement and deploy it to AWS and Qwak.

Table of Contents
What are you going to build? The LLM twin concept
LLM twin system design
1. What are you going to build? The LLM twin concept
The outcome of this course is to learn to build your own AI replica. We will use an LLM to do that, hence the name of the course: LLM Twin: Building Your Production-Ready AI Replica.
But what is an LLM twin?
Shortly, your LLM twin will be an AI character who writes like you, using your writing style and personality.
It will not be you. It will be your writing copycat.
More concretely, you will build an AI replica that writes social media posts or technical articles (like this one) using your own voice.
Why not directly use ChatGPT? You may ask…
When trying to generate an article or post using an LLM, the results tend to be:
very generic and unarticulated,
contain misinformation (due to hallucination),
require tedious prompting to achieve the desired result.
But here is what we are going to do to fix that ↓↓↓
First, we will fine-tune an LLM on your digital data gathered from LinkedIn, Medium, Substack and GitHub.
By doing so, the LLM will align with your writing style and online personality. It will teach the LLM to talk like the online version of yourself.
Our use case will focus on an LLM twin who writes social media posts or articles that reflect and articulate your voice.
Secondly, we will give the LLM access to a vector DB to access external information to avoid hallucinating.
Ultimately, in addition to accessing the vector DB for information, you can provide external links that will act as the building block of the generation process.
Excited? Let’s get started 🔥
2. LLM Twin System design
Let’s understand how to apply the 3-pipeline architecture to our LLM system.
The architecture of the LLM twin is split into 4 Python microservices:
The data collection pipeline
The feature pipeline
The training pipeline
The inference pipeline
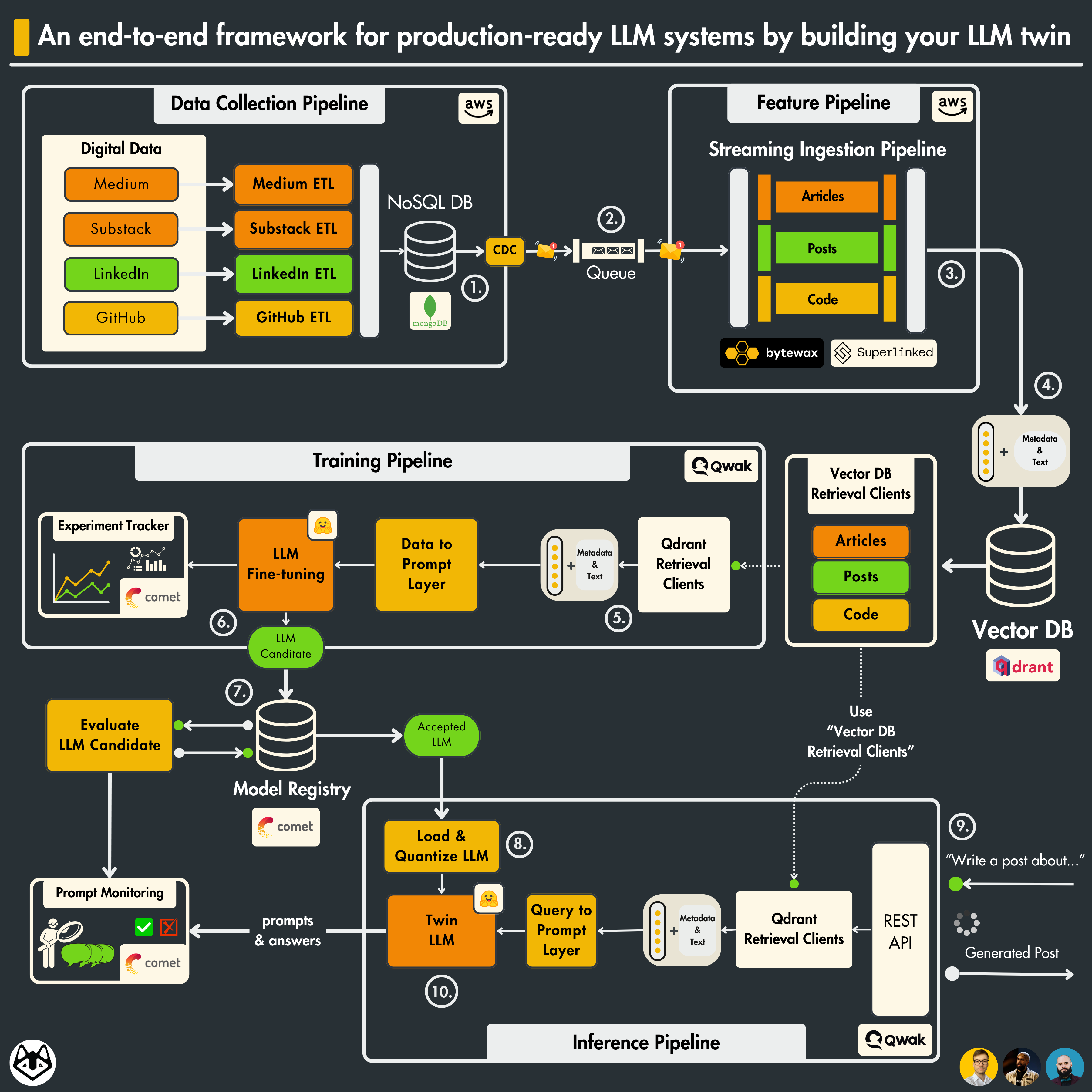
Now, let’s zoom in on each component to understand how they work individually and interact with each other. ↓↓↓
2.1. The data collection pipeline
Its scope is to crawl data for a given user from:
Medium (articles)
Substack (articles)
LinkedIn (posts)
GitHub (code)
As every platform is unique, we implemented a different Extract Transform Load (ETL) pipeline for each website.
However, the baseline steps are the same for each platform.
Thus, for each ETL pipeline, we can abstract away the following baseline steps:
log in using your credentials
use selenium to crawl your profile
use BeatifulSoup to parse the HTML
clean & normalize the extracted HTML
save the normalized (but still raw) data to Mongo DB
Important note: We are crawling only our data, as most platforms do not allow us to access other people’s data due to privacy issues. But this is perfect for us, as to build our LLM twin, we need only our own digital data.
Why Mongo DB?
We wanted a NoSQL database that quickly allows us to store unstructured data (aka text).
How will the data pipeline communicate with the feature pipeline?
We will use the Change Data Capture (CDC) pattern to inform the feature pipeline of any change on our Mongo DB.
To explain the CDC briefly, a watcher listens 24/7 for any CRUD operation that happens to the Mongo DB.
The watcher will issue an event informing us what has been modified. We will add that event to a RabbitMQ queue.
The feature pipeline will constantly listen to the queue, process the messages, and add them to the Qdrant vector DB.
For example, when we write a new document to the Mongo DB, the watcher creates a new event. The event is added to the RabbitMQ queue; ultimately, the feature pipeline consumes and processes it.
Where will the data pipeline be deployed?
The data collection pipeline and RabbitMQ service will be deployed to AWS. We will also use the freemium serverless version of Mongo DB.
2.2. The feature pipeline
The feature pipeline is implemented using Bytewax (a Rust streaming engine with a Python interface). Thus, in our specific use case, we will also refer to it as a streaming ingestion pipeline.
It is an entirely different service than the data collection pipeline.
How does it communicate with the data pipeline?
As explained above, the feature pipeline communicates with the data pipeline through a RabbitMQ queue.
Currently, the streaming pipeline doesn’t care how the data is generated or where it comes from.
It knows it has to listen to a given queue, consume messages from there and process them.
By doing so, we decouple the two components entirely.
What is the scope of the feature pipeline?
It represents the ingestion component of the RAG system.
It will take the raw data passed through the queue and:
clean the data;
chunk it;
embed it using the embedding models from Superlinked;
load it to the Qdrant vector DB.
What data will be stored?
The training pipeline will have access only to the feature store, which, in our case, is represented by the Qdrant vector DB.
With this in mind, we will store in Qdrant 2 snapshots of our data:
1. The cleaned data (without using vectors as indexes — store them in a NoSQL fashion).
2. The cleaned, chunked, and embedded data (leveraging the vector indexes of Qdrant)
The training pipeline needs access to the data in both formats as we want to fine-tune the LLM on standard and augmented prompts.
Why implement a streaming pipeline instead of a batch pipeline?
There are 2 main reasons.
The first one is that, coupled with the CDC pattern, it is the most efficient way to sync two DBs between each other.
Using CDC + a streaming pipeline, you process only the changes to the source DB without any overhead.
The second reason is that by doing so, your source and vector DB will always be in sync. Thus, you will always have access to the latest data when doing RAG.
Why Bytewax?
Bytewax is a streaming engine built in Rust that exposes a Python interface. We use Bytewax because it combines Rust’s impressive speed and reliability with the ease of use and ecosystem of Python. It is incredibly light, powerful, and easy for a Python developer.
Where will the feature pipeline be deployed?
The feature pipeline will be deployed to AWS. We will also use the freemium serverless version of Qdrant.
2.3. The training pipeline
How do we have access to the training features?
As section 2.2 highlights, all the training data will be accessed from the feature store. In our case, the feature store is the Qdrant vector DB that contains:
the cleaned digital data from which we will create prompts & answers;
we will use the chunked & embedded data for RAG to augment the cleaned data.
We will implement a different vector DB retrieval client for each of our main types of data (posts, articles, code).
What will the training pipeline do?
The training pipeline contains a data-to-prompt layer that will preprocess the data retrieved from the vector DB into prompts.
It will also contain an LLM fine-tuning module that inputs a HuggingFace dataset and uses QLoRA to fine-tune a given LLM (e.g., Mistral).
All the experiments will be logged into Comet ML’s experiment tracker.
We will use a bigger LLM (e.g., GPT4) to evaluate the results of our fine-tuned LLM. These results will be logged into Comet’s experiment tracker.
Where will the production candidate LLM be stored?
We will compare multiple experiments, pick the best one, and issue an LLM production candidate for the model registry.
After, we will inspect the LLM production candidate manually using Comet’s prompt monitoring dashboard.
Where will the training pipeline be deployed?
The training pipeline will be deployed to Qwak.
Qwak is a serverless solution for training and deploying ML models. It makes scaling your operation easy while you can focus on building.
Also, we will use the freemium version of Comet ML for the following:
experiment tracker;
model registry;
prompt monitoring.
2.4. The inference pipeline
The inference pipeline is the final component of the LLM system. It is the one the clients will interact with.
It will be wrapped under a REST API. The clients can call it through HTTP requests, similar to your experience with ChatGPT or similar tools.
How do we access the features?
We will grab the features solely from the feature store. We will use the same Qdrant vector DB retrieval clients as in the training pipeline to use the features we need for RAG.
How do we access the fine-tuned LLM?
The fine-tuned LLM will always be downloaded from the model registry based on its tag (e.g., accepted) and version (e.g., v1.0.2, latest, etc.).
What are the components of the inference pipeline?
The first one is the retrieval client used to access the vector DB to do RAG.
After we have a query to prompt the layer, that will map the prompt and retrieved documents from Qdrant into a prompt.
After the LLM generates its answer, we will log it to Comet’s prompt monitoring dashboard and return it to the clients.
For example, the client will request the inference pipeline to:
“Write a 1000-word LinkedIn post about LLMs,” and the inference pipeline will go through all the steps above to return the generated post.
Where will the inference pipeline be deployed?
The inference pipeline will be deployed to Qwak.
As for the training pipeline, we will use a serverless freemium version of Comet for its prompt monitoring dashboard.
Conclusion
This is the 1st article of the LLM Twin: Building Your Production-Ready AI Replica free course.
In this lesson, we presented what you will build during the course.
Ultimately, we went through the system design of the course and presented the architecture of each microservice and how they interact with each other:
The data collection pipeline
The feature pipeline
The training pipeline
The inference pipeline
In Lesson 2, we will dive deeper into the data collection pipeline, learn how to implement crawlers for various social media platforms, clean the gathered data, store it in a Mongo DB, and finally, show you how to deploy it to AWS.
🔗 Check out the code on GitHub [1] and support us with a ⭐️
This is how we can further help you 🫵
In the Decoding ML newsletter, we want to keep things short & sweet.
To dive deeper into all the concepts presented in this article…
Check out the full-fledged version of the article on our Medium publication.
It’s FREE ↓↓↓