

Building ML systems the right way using the FTI architecture
The fundamentals of the FTI architecture that will help you build modular and scalable ML systems using MLOps best practices.

This article presents the feature/training/inference (FTI) architecture to build scalable and modular ML systems using MLOps best practices. Jim Dowling, CEO at Hopsworks, proposed the design [1, 2].
We will start by discussing the problems of naively building ML systems. Then, we will examine other potential solutions and their problems.
Ultimately, we will present the feature/training/inference (FTI) design pattern and its benefits. We will also understand the benefits of using a feature store and model registry when architecting your ML system.
The problem with building ML systems
Building production-ready ML systems is much more than just training a model. From an engineering point of view, training the model is the most straightforward step in most use cases.
However, training a model becomes complex when deciding on the correct architecture and hyperparameters. That’s not an engineering problem but a research problem.
At this point, we want to focus on how to design a production-ready architecture. Training a model with high accuracy is extremely valuable, but just by training it on a static dataset, you are far from deploying it robustly. We have to consider how to:
ingest, clean and validate fresh data
training vs. inference setups
compute and serve features in the right environment
serve the model in a cost-effective way
version, track and share the datasets and models
monitor your infrastructure and models
deploy the model on a scalable infrastructure
automate the deployments and training
These are the types of problems an ML or MLOps engineer must consider, while the research or data science team is often responsible for training the model.

Figure 1 shows all the components the Google Cloud team suggests that a mature ML and MLOps system requires. Along with the ML code, there are many moving pieces. The rest of the system comprises configuration, automation, data collection, data verification, testing and debugging, resource management, model analysis, process and metadata management, serving infrastructure, and monitoring. The point is that there are many components we must consider when productionizing an ML model.
Thus, the critical question is: “How do we connect all these components into a single homogenous system”?
We must create a boilerplate for clearly designing ML systems to answer that question.
Similar solutions exist for classic software. For example, if you zoom out, most software applications can be split between a database, business logic and UI layer. Every layer can be as complex as needed, but at a high-level overview, the architecture of standard software can be boiled down to these three components.
Do we have something similar for ML applications? The first step is to examine previous solutions and why they are unsuitable for building scalable ML systems.
The issue with previous solutions
In Figure 2, you can observe the typical architecture present in most ML applications. It is based on a monolithic batch architecture that couples the feature creation, model training, and inference into the same component.
By taking this approach, you quickly solve one critical problem in the ML world: the training-serving skew. The training-serving skew happens when the features passed to the model are computed differently at training and inference time. In this architecture, the features are created using the same code. Hence, the training-serving skew issue is solved by default.
This pattern works fine when working with small data. The pipeline runs on a schedule in batch mode, and the predictions are consumed by a third-party application such as a dashboard.
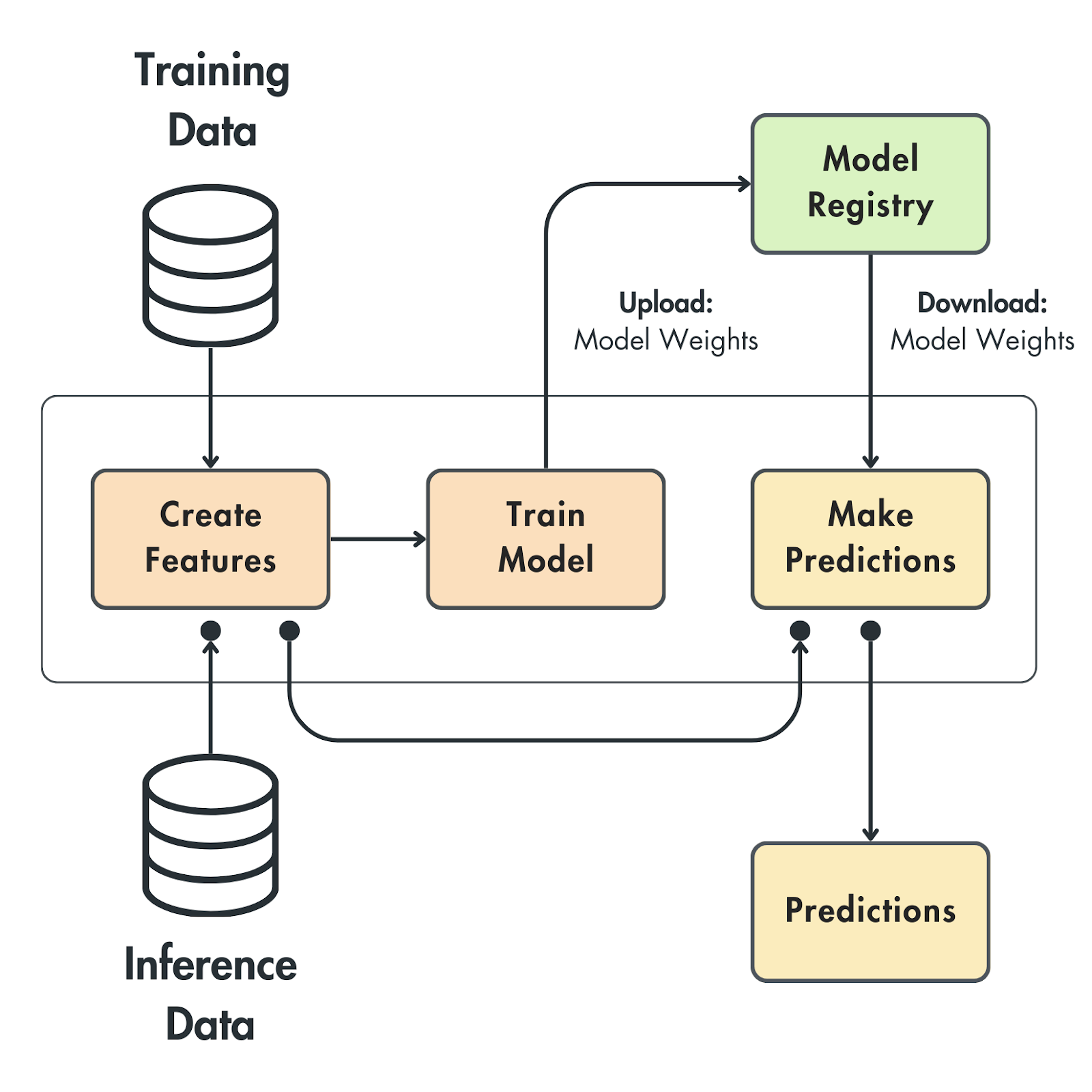
Unfortunately, building a monolithic batch system raises many other issues, such as:
features are not reusable (by your system or others)
if the data increases, you have to refactor the whole code to support PySpark or Ray
hard to rewrite the prediction module in a more efficient language such as C++, Java or Rust
hard to share the work between multiple teams between the features, training, and prediction modules
impossible to switch to a streaming technology for real-time training
In Figure 3, we can see a similar scenario for a real-time system. This use case introduces another issue in addition to what we listed before. To make the predictions, we have to transfer the whole state through the client request so the features can be computed and passed to the model.
Consider the scenario of computing movie recommendations for a user. Instead of simply passing the user ID, we must transmit the entire user state, including their name, age, gender, movie history, and more. This approach is fraught with potential errors, as the client must understand how to access this state, and it’s tightly coupled with the model service.
Another example would be when implementing an LLM with RAG support. The documents we add as context along the query represent our external state. If we didn’t store the records in a vector DB, we would have to pass them with the user query. To do so, the client must know how to query and retrieve the documents, which is not feasible. It is an antipattern for the client application to know how to access or compute the features. If you don’t understand how RAG works, we will explain it in future chapters.

In conclusion, our problem is accessing the features to make predictions without passing them at the client’s request. For example, based on our first user movie recommendation example, how can we predict the recommendations solely based on the user’s ID?
Remember these questions, as we will answer them shortly.
The solution: the FTI architecture
The solution is based on creating a clear and straightforward mind map that any team or person can follow to compute the features, train the model, and make predictions.
Based on these three critical steps that any ML system requires, the pattern is known as the FTI (feature, training, inference) pipelines. So, how does this differ from what we presented before?
The pattern suggests that any ML system can be boiled down to these three pipelines: feature, training, and inference (similar to the database, business logic and UI layers from classic software).
This is powerful, as we can clearly define the scope and interface of each pipeline. Also, it’s easier to understand how the three components interact.
As shown in Figure 4, we have the feature, training and inference pipelines. We will zoom in on each of them and understand their scope and interface.
Before going into the details, it is essential to understand that each pipeline is a different component that can run on a different process or hardware. Thus, each pipeline can be written using a different technology, by a different team, or scaled differently. The key idea is that the design is very flexible to the needs of your team. It acts as a mind map for structuring your architecture.
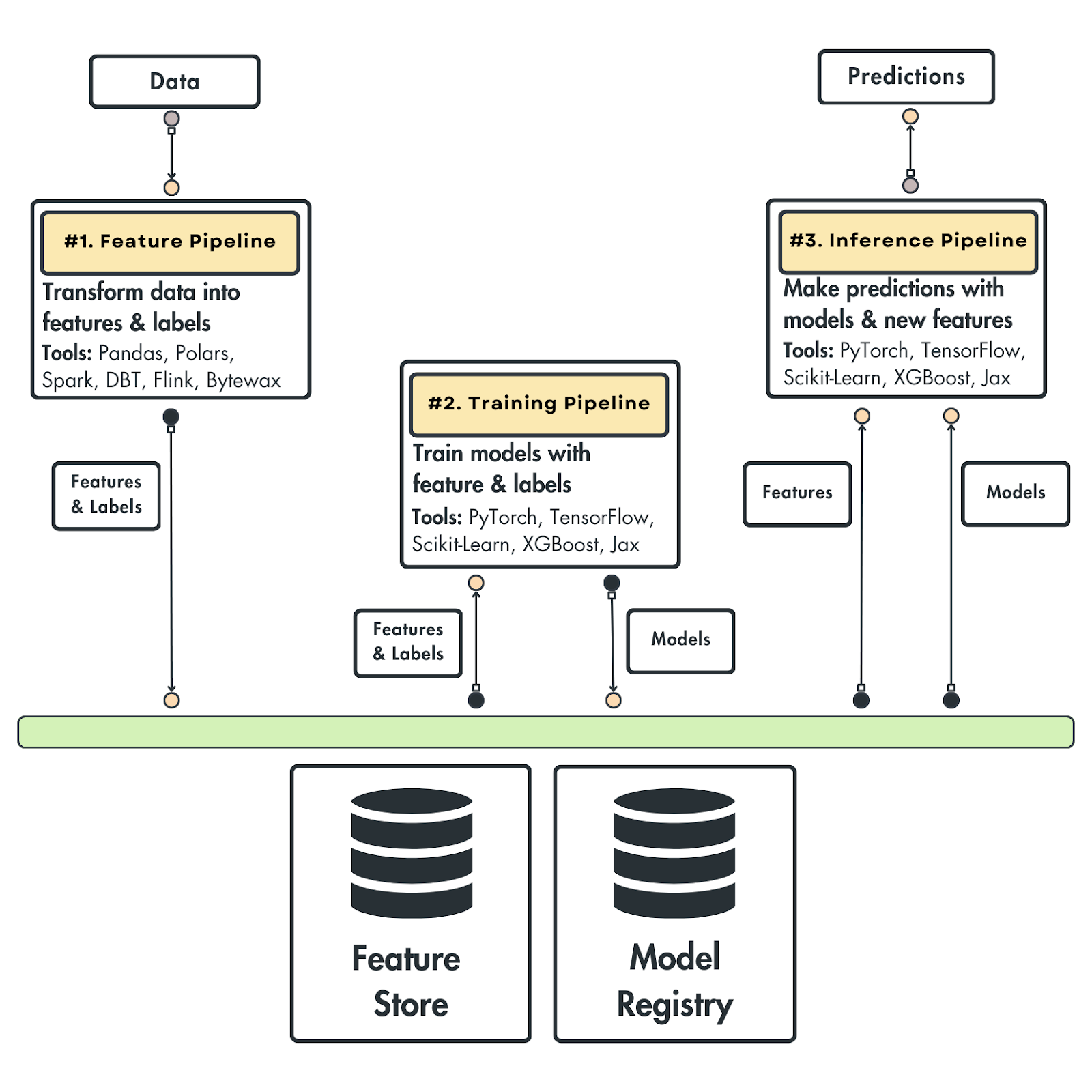
The feature pipeline
The feature pipelines take as input data and output features & labels used to train the model.
Instead of directly passing them to the model, the features and labels are stored inside a feature store. Its responsibility is to store, version, track, and share the features.
By saving the features into a feature store, we always have a state of our features. Thus, we can easily send the features to the training and inference pipeline(s).
As the data is versioned, we can always ensure that the training and inference time features match. Thus, we avoid the training-serving skew problem.
The training pipeline
The training pipeline takes the features and labels from the features store as input and outputs a train model or models.
The models are stored in a model registry. Its role is similar to that of feature stores, but this time, the model is the first-class citizen. Thus, the model registry will store, version, track, and share the model with the inference pipeline.
Also, most modern model registries support a metadata store that allows you to specify essential aspects of how the model was trained. The most important are the features, labels and their version used to train the model. Thus, we will always know what data the model was trained on.
The inference pipeline
The inference pipeline takes as input the features & labels from the feature store and the trained model from the model registry. With these two, predictions can be easily made in either batch or real-time mode.
As this is a versatile pattern, it is up to you to decide what you do with your predictions. If it’s a batch system, they will probably be stored in a database. If it’s a real-time system, the predictions will be served to the client who requested them.
As the features, labels, and model are versioned. We can easily upgrade or roll back the deployment of the model. For example, we will always know that model v1 uses features F1, F2, and F3, and model v2 uses F2, F3, and F4. Thus, we can quickly change the connections between the model and features.
Benefits of the FTI architecture
To conclude, the most important thing you must remember about the FTI pipelines is their interface:
The feature pipeline takes in data and outputs features & labels saved to the feature store.
The training pipelines query the features store for features & labels and output a model to the model registry.
The inference pipeline uses the features from the feature store and the model from the model registry to make predictions.
It doesn’t matter how complex your ML system gets. These interfaces will remain the same.
Now that we better understand how the pattern works, we want to highlight the main benefits of using this pattern:
as you have just three components, it is intuitive to use and easy to understand;
each component can be written into its tech stack, so we can quickly adapt them to specific needs, such as big or streaming data. Also, it allows us to pick the best tools for the job;
as there is a transparent interface between the three components, each one can be developed by a different team (if necessary), making the development more manageable and scalable;
every component can be deployed, scaled, and monitored independently.
The final thing you must understand about the FTI pattern is that the system doesn’t have to contain only three pipelines. In most cases, it will include more. For example, the feature pipeline can be composed of a service that computes the features and one that validates the data. Also, the training pipeline can be composed of the training and evaluation components.
The FTI pipelines act as logical layers. Thus, it is perfectly fine for each to be complex and contain multiple services. However, what is essential is to stick to the same interface on how the FTI pipelines interact with each other through the feature store and model registries. By doing so, each FTI component can evolve differently, without knowing the details of each other and without breaking the system on new changes.
Conclusion
In this article, we understood the fundamental problems when naively building ML systems.
We also looked at potential solutions and their downsides.
Ultimately, we presented the FTI architecture, its benefits, and how to apply it to modern ML systems.
This article was inspired by our latest book, “LLM Engineer’s Handbook.”
If you liked this article, consider supporting our work by buying our book and getting access to an end-to-end framework on how to engineer LLM & RAG applications, from data collection to fine-tuning, serving and LLMOps:

References
Literature
[1] Jim Dowling, From MLOps to ML Systems with Feature/Training/Inference Pipelines [2023], Hopsworks blog
[2] Jim Dowling, Modularity and Composability for AI Systems with AI Pipelines and Shared Storage [2024], Hopsworks blog
Images
If not otherwise stated, all images are created by the author.
How do we tie the code version to the model version?