

Context Engineering: 2025’s #1 Skill in AI
Everything you must know about context engineering to ship successful AI apps

Let’s get one thing straight: if you’re still only talking about "prompt engineering," you’re behind the curve. In the early days of Large Language Models (LLMs), crafting the perfect prompt was the name of the game.
For simple chatbots in 2022, it was enough. Then came Retrieval-Augmented Generation (RAG) in 2023, where we started feeding models domain-specific knowledge. Now, we have tool-using, memory-enabled agents that need to build relationships and maintain state over time. The single-interaction focus of prompt engineering just doesn’t cut it anymore.
As AI applications grow more complex, simply throwing more information into the prompt leads to serious issues. First, there’s context decay. Models get confused by long, messy contexts, leading to hallucinations and misguided answers. A recent study found that model correctness can start dropping significantly once the context exceeds 32,000 tokens, long before the advertised 2 million-token limits are reached [1].
Second, the context window—the model's working memory—is finite. Even with massive windows, every token adds to cost and latency. I once built a workflow where I stuffed everything into the context: research, guidelines, examples, and reviews. The result? A 30-minute run time. It was unusable. This naive approach of "context-augmented generation," or just dumping everything in, is a recipe for failure in production.
This is where context engineering comes in. It’s a shift in mindset from crafting individual prompts to architecting an AI’s entire information ecosystem. We dynamically gather and filter information from memory, databases, and tools to provide the LLM with only what’s essential for the task at hand. This makes our systems more accurate, faster, and cost-effective.
Understanding Context Engineering
So, what exactly is context engineering? The formal answer is that it is an optimization problem: finding the ideal set of functions to assemble a context that maximizes the quality of the LLM's output for a given task [2].
To put it simply, context engineering is about strategically filling the model’s limited context window with the right information, at the right time, and in the right format. We retrieve the necessary pieces from both short-term and long-term memory to solve a task without overwhelming the model.
Andrej Karpathy offered a great analogy for this: LLMs are like a new kind of operating system, where the model acts as the CPU and its context window functions as the RAM [3]. Just as an operating system manages what fits into RAM, context engineering curates what occupies the model’s working memory. It is important to note that the context is a subset of the system's total working memory; you can hold information without passing it to the LLM on every turn.
This new discipline is fundamentally different from just writing good prompts. To engineer the context effectively, you first need to understand what components you can actually manipulate.
Context engineering is not replacing prompt engineering. Instead, you can intuitively see prompt engineering as a part of context engineering. You still need to learn how to write good prompts while gathering the right context and stuff it into your prompt without breaking the LLM. That’s what context engineering is all about! More in the table below.
What Makes Up the Context
The context we pass to an LLM isn't a static string; we dynamically assemble this payload for each and every interaction. Various memory systems construct this payload, each serving a distinct purpose inspired by cognitive science [4].
Here are the core components that make up your LLM's context:
System Prompt: This contains the core instructions, rules, and persona for the agent. Think of it as the agent's procedural memory, defining how it should behave.
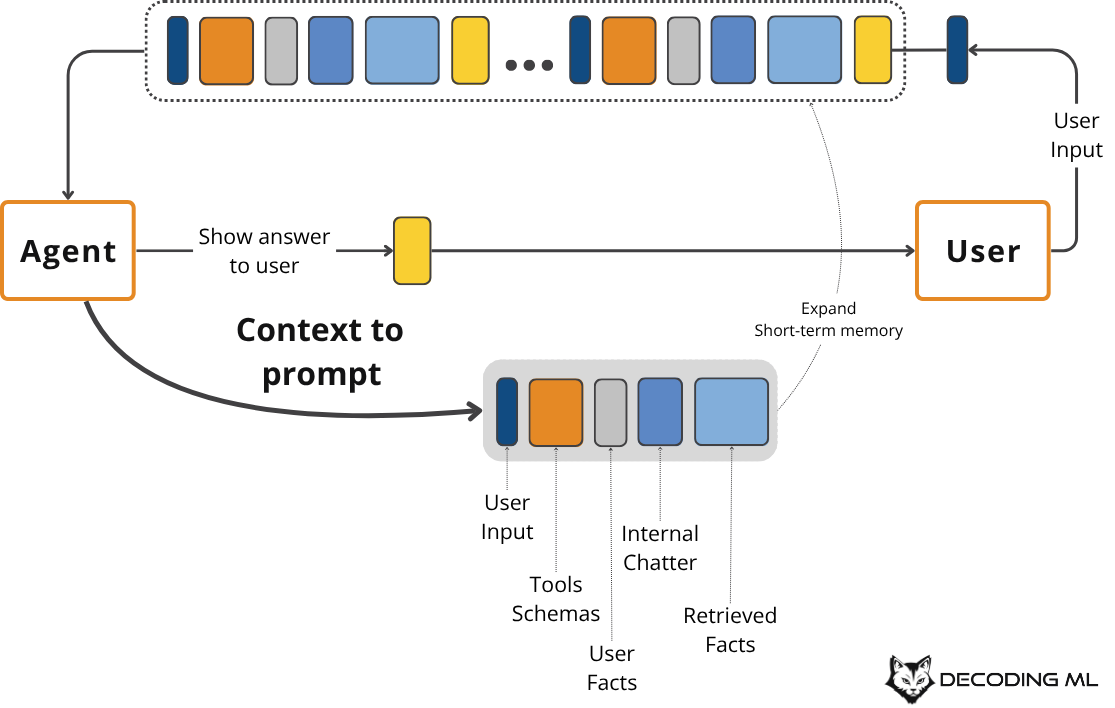
Message History: This is the recent back-and-forth of the conversation, including user inputs and the agent's internal monologue (thoughts, actions, and observations from tool use). This acts as the agent's short-term working memory.
User Preferences and Past Experiences: This is the agent's episodic memory, storing specific events and user-related facts, often in a vector or graph database. It allows for personalization, like remembering your role or previous requests [5].
Retrieved Information: This is the semantic memory—factual knowledge pulled from internal knowledge bases (like company documents or records) or external sources via real-time API calls. This is the core of RAG.
Tool and Structured Output Schemas: These are also a form of procedural memory, defining the tools the agent can use and the format it should use for its response.
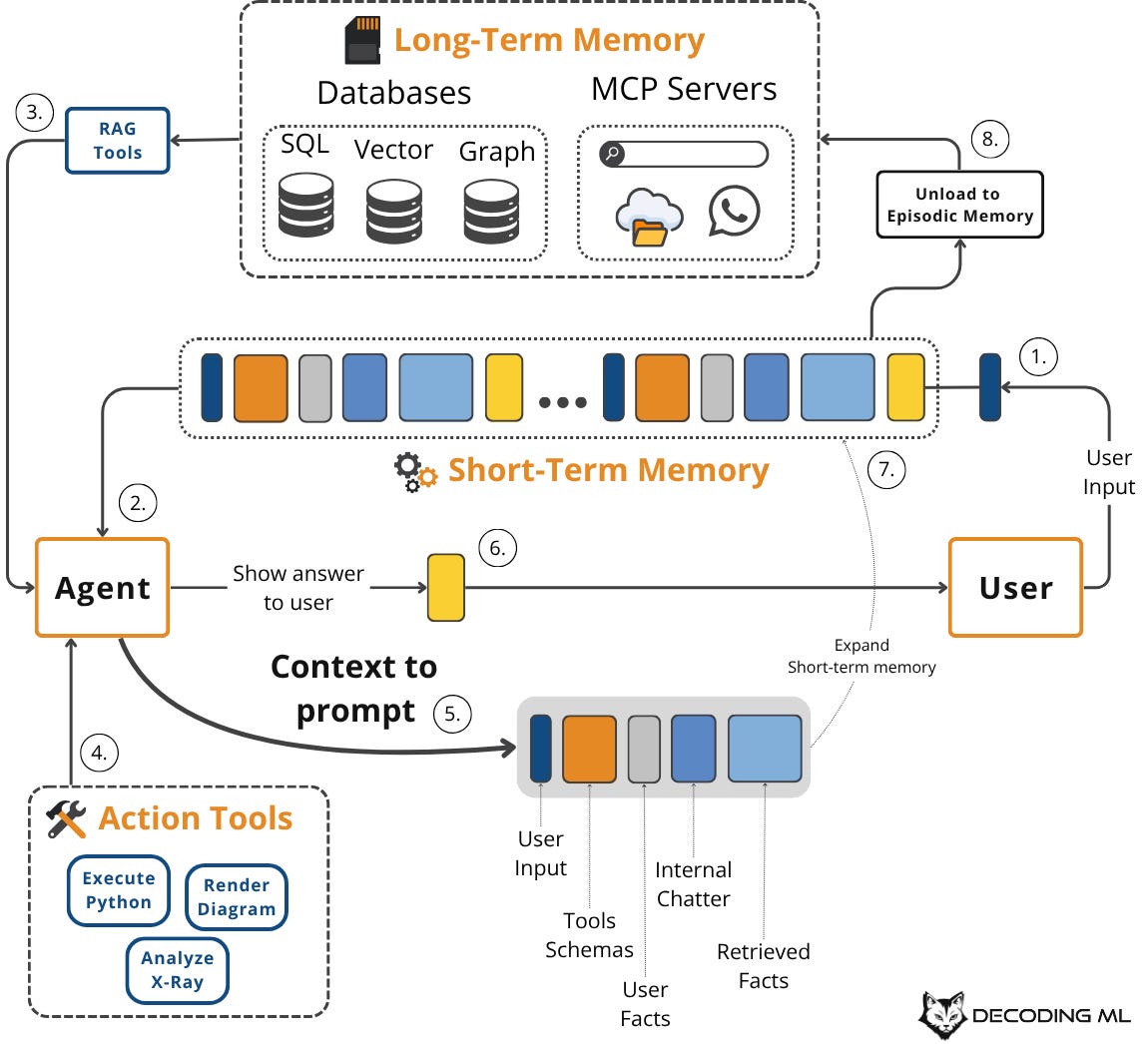
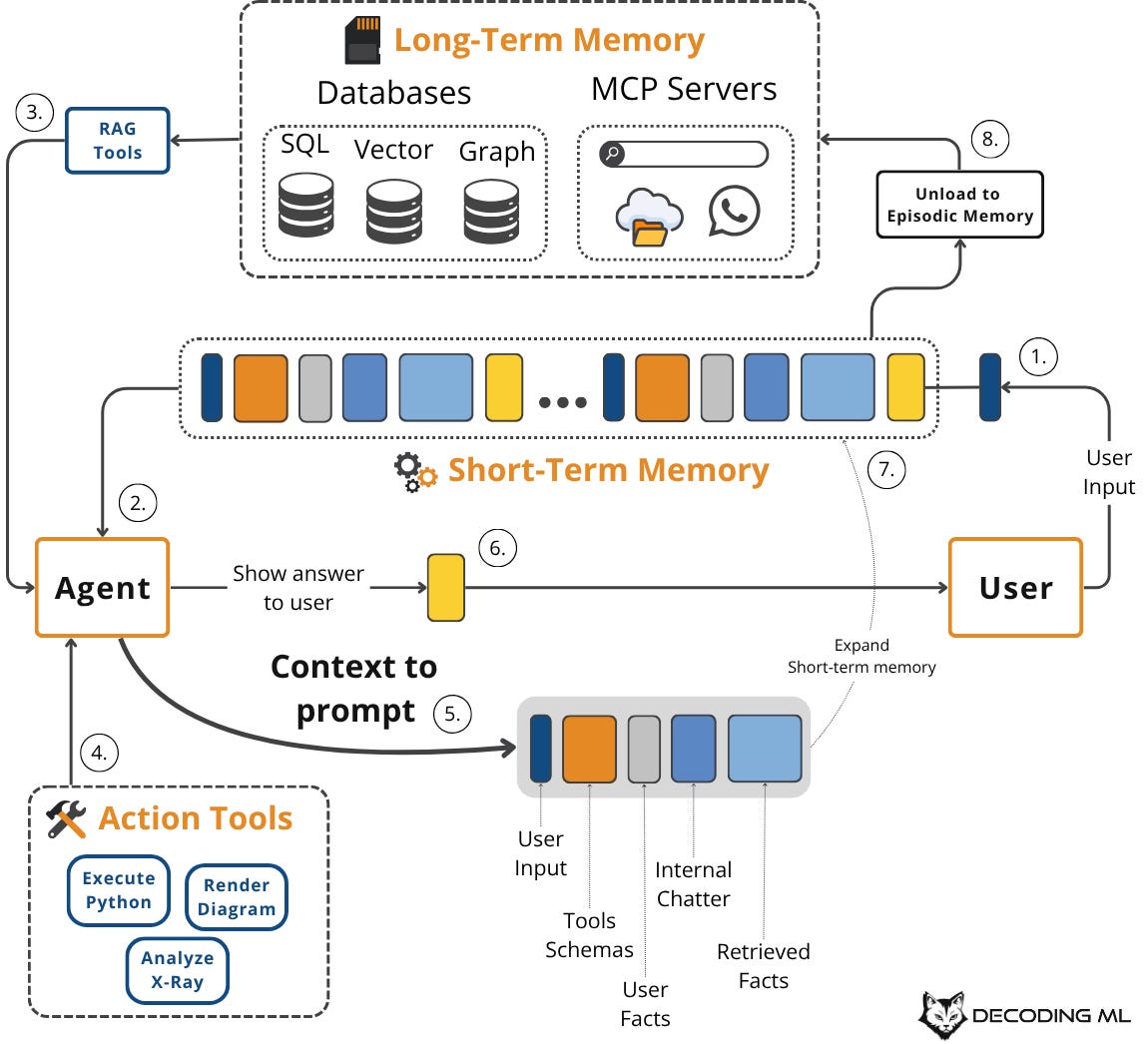
This flow is cyclical and dynamic. A user query or task triggers retrieval from long-term memory sources (episodic, semantic, procedural). This is known as the agentic RAG component of the system.
Next, we combine this information with short-term working memory, tool schemas, and structured output schemas to create the final context for the LLM call. The LLM's response updates the working memory, and we might write key insights back to long-term memory, refining the system for future interactions.
Production Implementation Challenges
Building a robust context engineering pipeline is not trivial. In production, you will run into several hard problems that can degrade your agent's performance if you do not manage them properly.
First is the context window challenge. Even with massive context windows, this space is a finite and expensive resource. The self-attention mechanism, central to LLMs, imposes quadratic computational and memory overhead [2]. Every token adds to cost and latency, quickly filling the context window with chat history, tool outputs, and retrieved documents, creating a hard limit on what the agent can "see."
This leads to information overload, also known as context decay or the "lost-in-the-middle" problem. Research shows that as you stuff more information into the context, models lose their ability to focus on critical details [1]. Performance often falls off a cliff, leading to confused or irrelevant responses. This information loss can also trigger hallucinations, as models attempt to fill in perceived gaps [6].
Another subtle issue is context drift, where conflicting versions of the truth accumulate over time. For example, if the memory contains both "The user's budget is $500" and later "The user's budget is $1,000," the agent can get confused. Without a mechanism to resolve or prune outdated facts, the agent's knowledge base becomes unreliable.
Finally, there is tool confusion. We often see failure when we provide an agent with too many tools, especially with poorly written descriptions or overlapping functionalities. The Gorilla benchmark shows that nearly all models perform worse when given more than one tool [7]. The agent gets paralyzed by choice or picks the wrong tool, leading to failed tasks.
Key Strategies for Context Optimization
In the early days, most AI applications were simple RAG systems. Today, agents juggle multiple data sources, tools, and memory types, requiring a sophisticated approach to context engineering. Here are key strategies to manage the LLM context window effectively.
Selecting the right context
Selecting the right context is your first line of defense. Avoid providing all available context; instead, use RAG with reranking to retrieve only the most relevant facts.
Structured outputs can also ensure the LLM breaks responses into logical parts, passing only necessary pieces downstream. This dynamic context optimization filters content and selects critical information to maximize density within the limited context window [2].
Context compression
Context compression is crucial for managing long-running conversations. As message history grows, summarize or condense it to avoid overflowing the context window, much like managing your computer's RAM.
You can use an LLM to create summaries of old conversation turns, move key facts to long-term episodic memory using tools such as mem0, or use deduplication using MinHash [8].
Context ordering
LLMs pay more attention to the beginning and end of a prompt, often losing information in the middle—the "lost-in-the-middle" phenomenon [1].
Place critical instructions at the start and the most recent or relevant data at the end.
Reranking and temporal relevance ensure LLMs do not bury key information [2]. Dynamic context prioritization can also resolve ambiguities and maintain personalized responses by adapting to evolving user preferences [9].
Isolating context
Isolating context involves splitting a complex problem across multiple specialized agents. Each agent maintains its own focused context window, preventing interference and improving performance.
This is a core principle behind multi-agent systems, leveraging the good old separation of concerns principle from software engineering.
Format Optimization
Finally, format optimization using structures like XML or YAML makes the context more digestible for the model. This clearly delineates different information types and improves reasoning reliability.
💡 Tip: Always use YAML instead of JSON, as it’s 66% more token-efficient.

Here is an Example
Context engineering is not just a theoretical concept; we apply it to build powerful AI systems in various domains.
In healthcare, an AI assistant can access a patient's history, current symptoms, and relevant medical literature to suggest personalized diagnoses.
In finance, an agent might integrate with a company's Customer Relationship Management (CRM) system, calendars, and financial data to make decisions based on user preferences.
For project management, an AI system can access enterprise tools like CRMs, Slack, Zoom, calendars, and task managers to automatically understand project requirements and update tasks.
Let's walk through a concrete example. Imagine a user asks a healthcare assistant: I have a headache. What can I do to stop it? I would prefer not to take any medicine.
Before the LLM even sees this query, a context engineering system gets to work:
It retrieves the user's patient history, known allergies, and lifestyle habits from an episodic memory store, often a vector or graph database [5].
It queries a semantic memory of up-to-date medical literature for non-medicinal headache remedies [4].
It assembles this information, along with the user's query and the conversation history, into a structured prompt.
We send the prompt to the LLM, which generates a personalized, safe, and relevant recommendation.
We log the interaction and save any new preferences back to the user's episodic memory.
Here’s a simplified Python example showing how these components might be assembled into a complete system prompt. Notice the clear structure and ordering.
System prompt for a healthcare AI assistant:
SYSTEM_PROMPT = """
You are a helpful and cautious AI healthcare assistant. Your goal is to provide safe, non-medicinal advice. Do not provide medical diagnoses.
<INSTRUCTIONS>
1. Analyze the user's query and the provided context.
2. Use the patient history to understand their health profile and preferences.
3. Use the retrieved medical knowledge to form your recommendation.
4. If you lack sufficient information, ask clarifying questions.
5. Always prioritize safety and advise consulting a doctor for serious issues.
</INSTRUCTIONS>
<PATIENT_HISTORY>
{retrieved_patient_history}
</PATIENT_HISTORY>
<MEDICAL_KNOWLEDGE>
{retrieved_medical_articles}
</MEDICAL_KNOWLEDGE>
<CONVERSATION_HISTORY>
{formatted_chat_history}
</CONVERSATION_HISTORY>
<USER_QUERY>
{user_query}
</USER_QUERY>
Based on all the information above, provide a helpful response.
"""Still, the key relies on the system around it that brings in the proper context to populate the system prompt.
To build such a system, you would use a combination of tools. An LLM like Gemini provides the reasoning engine. A framework like LangChain orchestrates the workflow. Databases such as PostgreSQL, Qdrant, or Neo4j serve as long-term memory stores. Specialized tools like Mem0 can manage memory state, and observability platforms are essential for debugging complex interactions.
Connecting Context Engineering to AI Engineering
Mastering context engineering is less about learning a specific algorithm and more about building intuition. It’s the art of knowing how to structure prompts, what information to include, and how to order it for maximum impact.
This skill doesn't exist in a vacuum. It’s a multidisciplinary practice that sits at the intersection of several key engineering fields:
AI Engineering: Understanding LLMs, RAG, and AI agents is the foundation.
Software Engineering: You need to build scalable and maintainable systems to aggregate context and wrap agents in robust APIs.
Data Engineering: Constructing reliable data pipelines for RAG and other memory systems is critical.
MLOps: Deploying agents on the right infrastructure and automating Continuous Integration/Continuous Deployment (CI/CD) makes them reproducible, observable, and scalable.
The best way to develop your context engineering skills is to get your hands dirty.
Start building AI agents that integrate RAG for semantic memory, tools for procedural memory, and user profiles for episodic memory. By wrestling with the trade-offs of context management in a real project, you’ll build the intuition that separates a simple chatbot from a truly intelligent agent.
Now stop reading and build your next AI app using all these context engineering skills!
See you next week,
👋 I’d love your feedback to help improve Decoding ML.
Share what you want to see next or your top takeaway. I read and reply to every comment!
Whenever you’re ready, there are 3 ways we can help you:
Perks: Exclusive discounts on our recommended learning resources
(books, live courses, self-paced courses and learning platforms).
The LLM Engineer’s Handbook: Our bestseller book on teaching you an end-to-end framework for building production-ready LLM and RAG applications, from data collection to deployment (get up to 20% off using our discount code).
Free open-source courses: Master production AI with our end-to-end open-source courses, which reflect real-world AI projects and cover everything from system architecture to data collection, training and deployment.
References
[1] Long-context RAG performance on LLMs
[2] A Survey of Context Engineering for Large Language Models
[3] Andrej Karpathy on Context Engineering
[5] AI agent memory
[6] LLM-based Generation of E-commerce Product Descriptions
[9] Dynamic Context Prioritization for Personalized Response Generation
[10] Building a multi-agent research system
[11] AI Agent Architecture Patterns
[12] The 12-Factor Agent: Own Your Context Window
Images
If not otherwise stated, all images are created by the author.
fantastic piece Paul!
On "Tool Confusion": You mentioned the Gorilla benchmark shows models struggle when given more than one tool. I'm curious about your take on this: Is the core challenge truly the number of tools, or is it the agent's underlying reasoning and planning ability in complex, multi-step workflows? Newer benchmarks seem to focus more on testing this multi-turn reasoning capability.
On the 32k Token "Limit": You highlighted that model accuracy can drop significantly after 32,000 tokens, which is a critical warning for production systems. Since some of the latest models (like GPT-4o and Claude 3.5 Sonnet) are showing strong performance well beyond this point, how do you see this "soft limit" evolving? Is it a moving target that engineers need to constantly re-evaluate for each specific model they use?