


Custom AI solutions are overrated
Build a production RAG app in <30 minutes using Snowflake Cortex AI

Building custom AI, ML & MLOps solutions from scratch is overrated.
In many scenarios, using a fully managed platform makes more sense, as it will reduce your development time by x10.

Complete control over your system is a beautiful idea, as you own your data, models and infrastructure.
Unfortunately, building ML and MLOps solutions from scratch is complex and time-consuming!
Using fully managed platforms such as Snowflake will 10x your productivity and, indirectly, the value you bring to the company.
A fully managed platform takes off the weight of managing your:
- infrastructure
- ML & MLOps tools
- storing your data
- hosting your models
Making dev x10 easier, faster and more reliable.
.
For example, Snowflake Cortex AI provides out-of-the-box solutions for:
- hosted foundational LLMs (Mistral, Llama, Arctic, etc.) for parsing documents and RAG
- databases with vector support
- deploying ML pipelines
- scheduling and monitoring ML pipelines
To build this stuff from scratch at a production level will take years!
Especially when running LLMs on clusters of GPUs and scaling them accordingly.
.
In one of my previous projects, I had to deploy, automate, monitor and scale multiple ML pipelines, implementing a custom solution built with Prefect, which took me a couple of months and still wasn't completely stable.
On the other hand, you can do the same thing in a few days using a fully managed platform such as Snowflake Cortex AI.
→ But robustly and at a production level.
.
You might say that this will cost more than building it yourself... Which might be true...
However, if you don't have:
an MLOps platform ready to go
a team of skilled DE & MLE
the necessary computing
> It will probably take months to build a viable solution.
Thus, a good strategy is to delegate infrastructure management to a fully managed platform and focus on quickly delivering value to your business.
It will surprise you that it might outweigh the additional cost of maintaining and building a custom solution.
.
To better understand what I am saying…
💡 Check out the quick tutorial below on how to build a production-ready RAG application using Snowflake Cortex AI - in just a few lines of code!
How to build a production-level RAG app using Snowflake Cortex AI

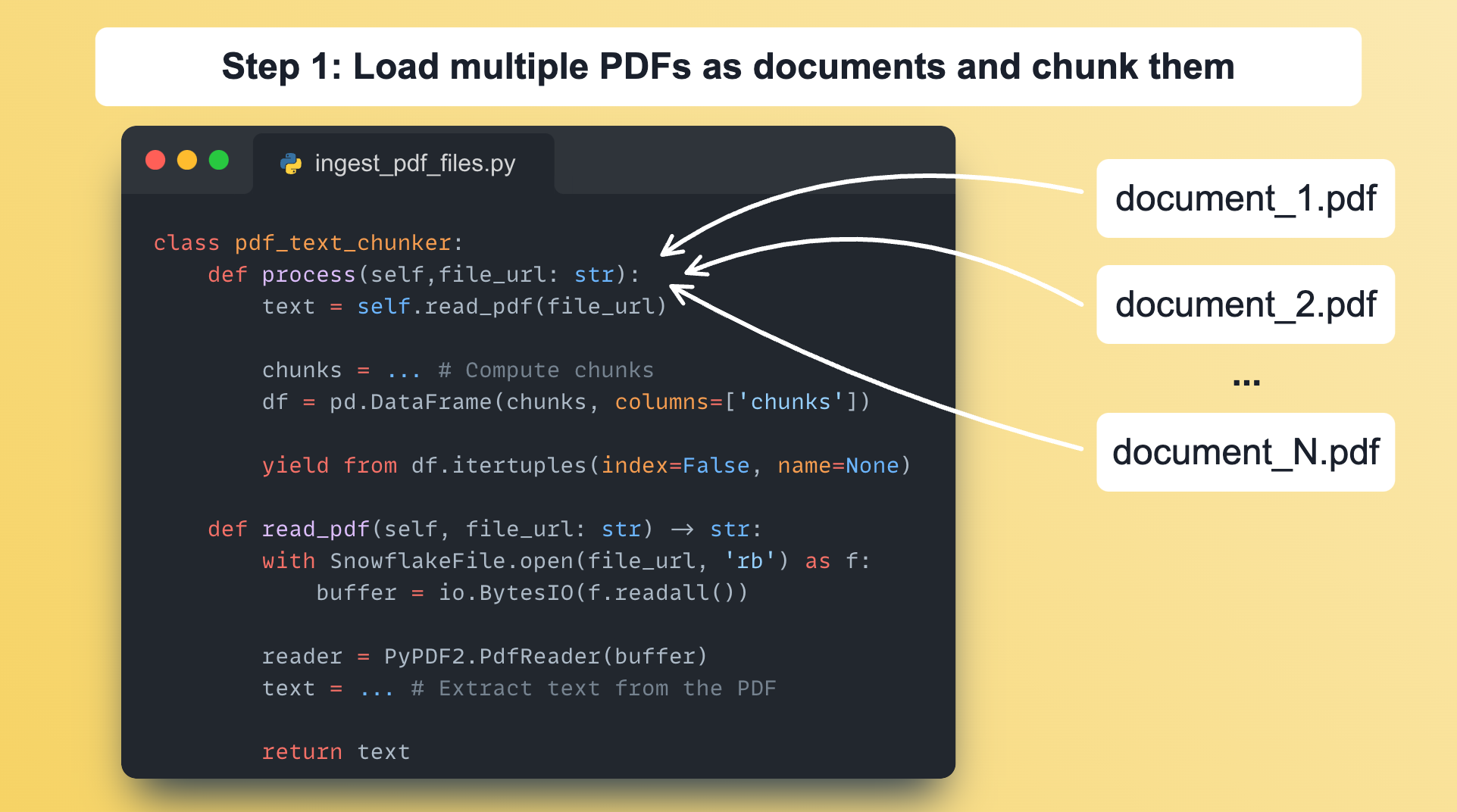
Step 1: Define a class that implements a process() function to load and chunk the documents.
Step 2: Use Snowflake’s self-hosted `e5-base-v2` embedding model to embed all the documents and insert them into the table under the chunk_vec column, which is of the VECTOR type.

→ We are done populating the vector db with the embeddings of the chunked documents.
Step 3: On the retrieval side, we can quickly query (using SQL) similar chunks using their `e5-base-v2` self-hosted model.

Step 4: Also, we easily leverage their self-hosted LLMs to do end-to-end RAG at scale.

Step 5: We can choose from all the foundation models, such as Llama, Mistral, Artic, Gemma, and more! Also, Snowflake supports hosting Streamlit apps, which allow you to quickly add an intuitive interface to your RAG backend.

Step 6: The last step is to schedule the ingestion pipeline to update the vector DB with new documents every minute. Every minute, the pipeline looks for new documents. If it finds any, it processes them and updates the vector DB.

Implementing and deploying an end-to-end RAG application using Snowflake Cortex AI is that easy. Serverless: no more infrastructure headaches!
What you learned:
Creating functions to extract text and chunk PDF files
Creating embeddings with Snowflake Cortex
Use Snowflake VECTOR data type for similarity search
Using Snowflake Cortex to use LLMs to answer questions
Building an application front-end with Streamlit
Using directory tables and streams to process files automatically
🔗 𝘍𝘶𝘭𝘭 𝘵𝘶𝘵𝘰𝘳𝘪𝘢𝘭 𝘩𝘦𝘳𝘦 → Build A Document Search Assistant using Vector Embeddings in Cortex AI
Images
If not otherwise stated, all images are created by the author.