A practical guide to deploying Deepseek-R1 on GCP, Latitude.sh, and Modal
Since 2019, Louis-François and Towards AI have shared thousands of articles through their publication and hundreds of videos via the What’s AI channel. Building on that foundation, they launched an education platform built by practitioners for practitioners, now trusted by over 100,000 learners. With a mission to make AI accessible and a focus on applied learning, their hands-on LLM development courses bridge the gap between academic research and real-world industry needs.
Deploying Large Language Models (LLMs) like DeepSeek-R1 involves more than just running code—it requires the right infrastructure, careful memory management, and cost awareness. With billions of parameters, these models need powerful GPUs or TPUs, large storage capacity, and thoughtful scaling to meet real-world performance needs. Inference alone can sometimes cost more than training, especially when serving high-traffic workloads at scale.
In this article, we walk you through three common deployment paths—cloud (Google Cloud Platform), bare-metal (Latitude.sh), and serverless (Modal)—and explain how each performs when running DeepSeek-R1, a popular open-source reasoning model. Rather than focusing on the theory behind each platform, we’ll walk through working examples. You’ll learn how to set up each environment, run the model, and compare trade-offs across cost, latency, setup complexity, and scalability. If you're evaluating which setup best fits your workloads—whether it’s constant inference, irregular traffic, or experimental fine-tuning—this guide will help you make that decision with clarity.
Before jumping into platform-specific steps, we’ll first break down the fundamental differences between cloud, bare metal, and serverless. Each brings unique trade-offs—from pre-packaged managed services to low-level hardware access to on-demand auto-scaling—and your deployment strategy depends heavily on which priorities you want to optimize.
Cloud, Bare Metal, and Serverless: An Overview
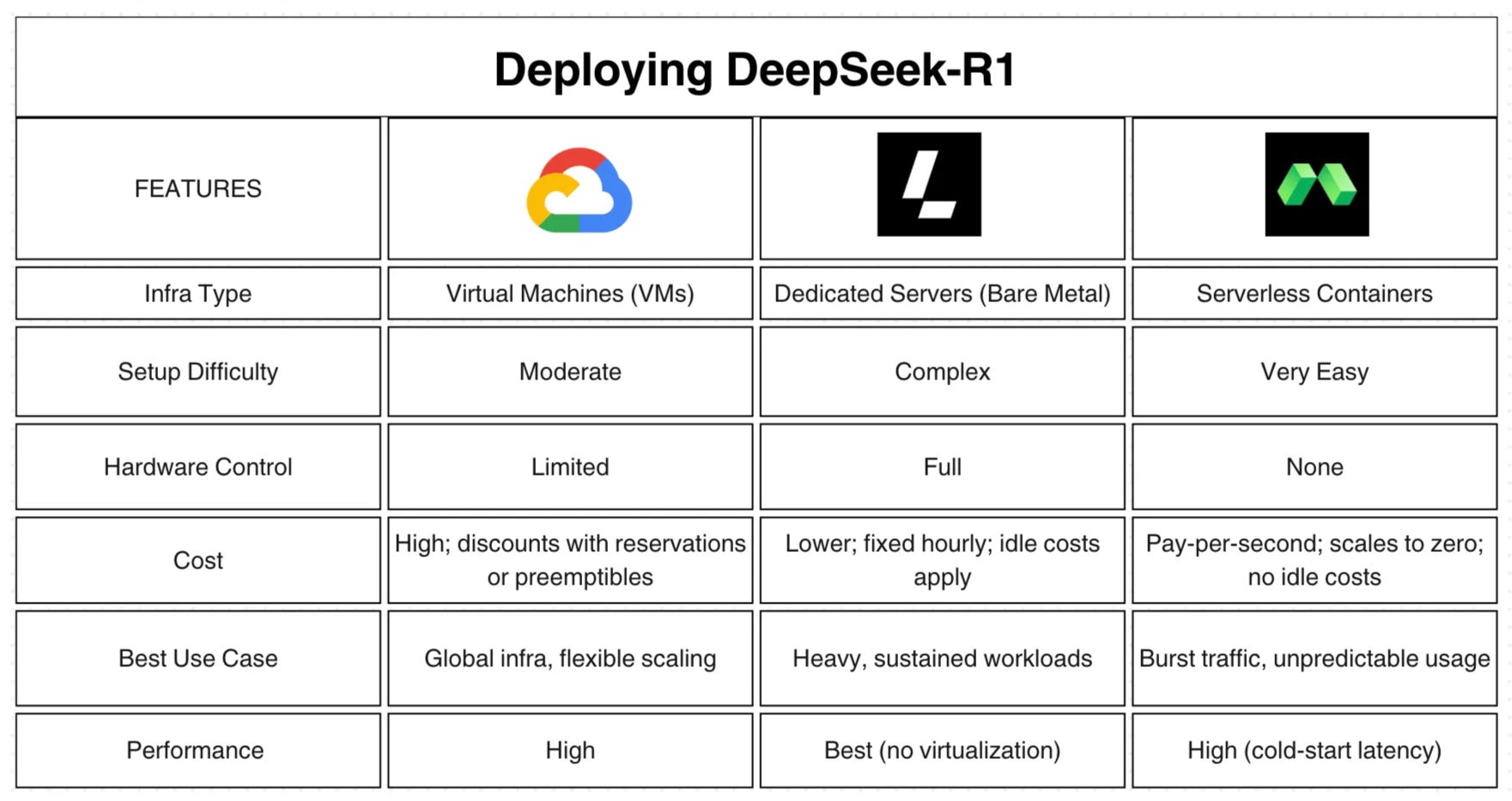
LLMs can be deployed on cloud, bare metal, and serverless platforms based on specific needs, such as performance, scalability, and cost considerations. Each option presents unique advantages and trade-offs. The table below provides a side-by-side comparison of these three approaches:
Choosing among these three deployment models depends on your priorities—be it operational simplicity, maximum performance, or cost efficiency. While each model presents its trade-offs, deployment optimization techniques such as quantization, pruning, and knowledge distillation can help improve efficiency across environments. For instance, quantization can reduce memory usage and latency in serverless setups with variable traffic, and distillation can make large models more manageable for cloud deployment. Even bare-metal configurations benefit by improving hardware utilization and reducing energy demands.
Several deployment optimization techniques have become more accessible with the development of modern tooling and open-source libraries. If you want to apply these techniques practically and at scale across different deployment environments, we cover them in detail in our Beginner to Advanced LLM Developer course.
To better understand how each deployment model can be used in practice, we’ll go through them one by one—starting with Google Cloud Platform (GCP).
Google Cloud Platform (GCP)
GCP is a major cloud platform recognized for its extensive infrastructure and managed services. For LLM deployments, GCP offers flexible compute options, ranging from fully managed ML endpoints to custom VM instances with GPU support. For deploying DeepSeek-R1, GCP gives you two paths:
Managed deployment: Use Vertex AI to serve the model with minimal configuration. Ideal for those who want scaling, monitoring, and a production-ready endpoint without managing infra.
Custom deployment: Launch a GPU-enabled Compute Engine instance and run the model directly. This approach gives more control and transparency—perfect for debugging, testing, or cost optimization.
We’ll focus on the second route, using a self-managed VM with an L4 GPU.
Step-by-Step: Deploying DeepSeek-R1’s Distill model on GCP
Create a GCP VM with an L4 GPU
In the GCP Console, go to Compute Engine → VM instances and create a new instance with:
Machine type: g2-standard-8 and add 1 NVIDIA L4 GPU.
Select Ubuntu 22.04, 100GB disk space. Ensure GPU quota is available.
SSH into the VM and run the following commands to install NVIDIA GPU drivers:
# Install the Google Cloud GPU driver script
curl <https://raw.githubusercontent.com/GoogleCloudPlatform/compute-gpu-installation/main/linux/install_gpu_driver.py> -o install_gpu_driver.py
# Run the installation script
sudo python3 install_gpu_driver.py
# Reboot your system
sudo reboot
After rebooting, confirm that NVIDIA tools were installed correctly:
# After reboot, check if nvidia-smi works
nvidia-smi
Next, update your system, install the required packages, and create a Python virtual environment:
Once your environment is setup, create a script (run_deepseek.py) to load the model and perform inference:
# Create the inference script
cat > run_deepseek.py << 'EOF'
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
if torch.cuda.device_count() > 0:
print(f"GPU name: {torch.cuda.get_device_name(0)}")
model_name = "deepseek-ai/DeepSeek-R1-Distill-Llama-8B"
# Load tokenizer
print("Loading tokenizer...")
tokenizer = AutoTokenizer.from_pretrained(model_name)
# Load model
print("Loading model...")
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
# Your prompt
prompt = "<|User|>You are an assistant. Q: what is the capital of france.<|Assistant|>"
inputs = tokenizer(prompt, return_tensors='pt')
with torch.no_grad():
outputs = model.generate(**inputs,max_new_tokens=200)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("Model output:")
print(result)
EOF
# Run the inference script
python run_deepseek.py
The script will generate a response from the DeepSeek-R1’s Distill model.
This setup gives you full control, access to Google’s global infra, and a baseline for comparing other platforms. Although, keep in mind that GCP GPU costs can add up quickly—particularly for large-scale, always-on workloads.
Bare-metal cloud providers offer dedicated physical servers instead of virtual machines. Latitude.sh provides infrastructure suitable for AI workloads, including inference and fine-tuning of LLMs. It offers three categories of compute products:
Their Metal product line provides general-purpose bare metal servers for various tasks, including hosting applications. The Accelerate lineup has high-performance servers equipped with powerful GPUs for AI workloads like model training and real-time inference. Finally, their Build service allows users to build custom infrastructure stacks where users define their requirements, and Latitude.sh manages procurement, setup, and maintenance of the hardware.
In this tutorial, bare metal is used because it is good at supporting long-running, resource-heavy tasks like continuous LLM services or training. When hardware is fully utilized, it may be more cost-effective than equivalent virtual machines. Bare-metal setups also allow for more control over hardware configurations, including specific CPU and GPU pairings that may not be available on traditional public cloud platforms. The trade-off is that users are responsible for managing the entire software stack, and scaling requires manual provisioning—there is no built-in auto-scaling.
Step-by-Step: Deploying DeepSeek-R1’s Distill model on Latitude.sh
Deploying on bare metal is similar to working with a virtual machine but with additional control over the setup process. Below is a step-by-step guide for running the DeepSeek-R1 Distill model:
Log in to Latitude.sh and select a server configuration that meets your model’s GPU requirements. For the 8B distill model, we will use g3.h100.small with one NVIDIA H100 GPU (80GB). Latitude.sh offers an “Accelerate” lineup of GPU servers, such as a 1× A100 or 1× H100. Choose a location close to your user base for lower latency. Once you’ve ordered your server, it may take a few minutes before it’s ready.
After your server is provisioned, you’ll typically receive SSH access to a base OS (e.g., Ubuntu). Because this is bare metal, you must ensure the NVIDIA driver and CUDA are installed. Some providers allow you to preload an image with drivers; otherwise, download and install the necessary drivers (via the NVIDIA runfile or apt repositories). If you plan to use containers, install Docker at this stage or proceed with a conventional system-wide library setup.
Just as with the GCP example, use Python to load the model. The code is the same on bare metal:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "deepseek-ai/DeepSeek-R1-Distill-Llama-8B" # or another variant
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
device_map="auto"
)
This downloads the model weights from Hugging Face (ensure the server has internet access). Because the weights can be several gigabytes, the initial download may take a while. Once complete, the model is loaded into GPU memory (FP16 in this example).
Finally, confirm that inference works:
prompt = "You are an assistant. Q: What is the capital of France?\\nA:"
inputs = tokenizer(prompt, return_tensors="pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens=50)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(answer)
Bare metal offers complete hardware control and can deliver the best price-to-performance ratio for high-demand workloads. By bypassing the overhead of cloud providers, you can often secure powerful GPUs at lower rates if you anticipate high utilization. You also gain maximum freedom to configure system drivers and libraries. For large-scale production or specialized research, bare metal remains a top choice for both performance and cost management.
Serverless with Modal
Serverless GPU computing allows you to run machine learning workloads without managing infrastructure. Modal makes this especially accessible: you define a Python function, specify GPU requirements, and Modal handles the rest—including container setup, execution, and auto-scaling. It is particularly effective for LLMs, offering dynamic scaling and pay-per-use billing. When there are no requests, there are no idle GPU costs. During traffic spikes, Modal spins up multiple instances automatically to meet demand.
Modal and similar serverless GPU platforms work well for applications with elastic scaling needs or unpredictable traffic. If your LLM usage involves occasional heavy tasks, serverless deployment avoids the expense of keeping a GPU running full-time. It also reduces operational overhead by handling OS updates, Docker configurations, and driver compatibility. The trade-off is potential cold-start latency—the time it takes to launch a container on the first request—though this can often be mitigated. Since Modal’s compute is ephemeral, any persistent state needs to be managed externally.
Step-by-Step: Deploying DeepSeek-R1’s Distill model on Modal
Modal uses a Python SDK to define applications and functions. Let’s walk through deploying our DeepSeek model:
If you haven’t used Modal before, install it locally with:
pip install modal
python3 -m modal setup
The first command pip install modal, installs the Modal client library and any required dependencies. The python3 -m modal setup command opens a browser tab to authenticate and create an API token. This token allows the Modal CLI and SDK to authenticate with your account.
Next, create a Python script (e.g., deploy_deepseek_modal.py) with the following content:
Let’s break down what this does. modal.App("deepseek-r1-distill-modal") creates a Modal app named "deepseek-r1-distill-modal". You’ll see this name in the Modal dashboard and logs when the function runs.
The custom image tells Modal which OS packages (via apt_install) and Python libraries (via pip_install) to include in the container environment. This ensures that torch, transformers, and accelerate are preinstalled and ready to use.
The @stub.function(...) decorator marks generate_response as a remote function that runs on an A100 GPU. When you invoke it, Modal provisions the container executes the function, and returns the result.
The @stub.local_entrypoint() decorator allows you to call the main() function from your terminal. Inside main(), the prompt is passed to the remote generate_response() function, which handles the inference and returns the generated output.
Finally, in the terminal in the same directory as deploy_deepseek_modal.py, run:
modal run deploy_deepseek_modal.py --prompt "You are an assistant. Q: What is the capital of France?"
In this code, Modal will build the container image if it hasn’t been built already (including installing torch, transformers, and other dependencies). It will then run the main() function. Because main() calls generate_response.remote(...), Modal will:
Spin up a GPU container in the cloud.
Load the DeepSeek-R1 Distill model from Hugging Face (initial load may take a couple of minutes)
Tokenize and run the prompt through the model.
Return the generated text, which prints in your local terminal.
On subsequent calls, the model is often cached, so it might load faster
Modal significantly simplifies LLM deployment, offering automatic scaling and a pay-per-use pricing model. For irregular workloads, you’ll pay only while GPUs are actively running, avoiding the cost of idle infrastructure. While cold-start latency and external state management can be considerations, serverless GPU solutions like Modal provide a powerful, streamlined way to integrate LLM capabilities into production.
Comparing the Platforms
Now that we’ve explored deploying DeepSeek-R1 Distill on GCP, Latitude.sh, and Modal, let’s compare these platforms across several important dimensions:
In summary, GCP excels in flexible, robust production environments, especially for teams that have experience with cloud configuration and want global infrastructure integration. Latitude.sh stands out with raw performance and cost-efficiency for ongoing, intensive workloads—perfect for users who can manage their hardware stack. Meanwhile, Modal offers the fastest path to deployment, making it ideal for rapid prototyping, experimentation, and applications with unpredictable traffic.
Conclusion
Choosing the right deployment strategy for large language models depends entirely on your use case. If you're looking for managed scalability and seamless integration with enterprise tools, cloud platforms like GCP offer a mature and flexible solution. For continuous, high-performance workloads and full hardware control, bare-metal providers such as Latitude.sh deliver strong price-to-performance value. And if your workloads are irregular or traffic patterns unpredictable, serverless platforms like Modal offer the fastest path to production with minimal infrastructure overhead.
While we’ve used DeepSeek-R1 as an example throughout this guide, the same principles apply to most open-source or commercial LLMs. Because of the growing availability of GPU infrastructure across different deployment models, it’s now easier than ever to prototype on a small variant and scale up as your requirements evolve.
Ultimately, the best approach comes down to understanding your performance goals, cost constraints, and operational preferences—and matching them to the platform that supports them best.
Deploying LLMs across cloud, bare metal, and serverless platforms isn’t straightforward—it takes trial, error, and real-world experience to get it right.
To fast-track your learning curve, we’ve built a comprehensive, hands-on course that teaches you how to deploy and optimize LLMs across diverse infrastructure setups.
Beginner to Advanced LLM Developer Course includes over 50 hours of in-depth content on model optimization, deployment strategies, and scaling techniques—everything you need to move from experimentation to production confidently.
As readers of Decoding ML, we recommend their course and offer a 15% discount using code Paul_15 (available for all the courses from the Towards AI Academy).
The courses are also 100% company reimbursement eligible.








Great to work with you again—always appreciate the chance to dig into these ideas together.