



DML: 7-steps on how to fine-tune an open-source LLM to create your real-time financial advisor
Lesson 8 | The Hands-on LLMs Series

Hello there, I am Paul Iusztin 👋🏼
Within this newsletter, I will help you decode complex topics about ML & MLOps one week at a time 🔥
Lesson 8 | The Hands-on LLMs Series
Table of Contents:
What is Beam? How does serverless make deploying ML models easy?
7 tips you must know to reduce your VRAM consumption of your LLMs during training
7-steps on how to fine-tune an open-source LLM to create your real-time financial advisor
Previous Lessons:
Lesson 6: What do you need to fine-tune an open-source LLM to create your financial advisor?
Lesson 7: How do you generate a Q&A dataset in <30 minutes to fine-tune your LLMs?
↳🔗 Check out the Hands-on LLMs course and support it with a ⭐.
#1. What is Beam? How does serverless make deploying ML models easy?
𝗗𝗲𝗽𝗹𝗼𝘆𝗶𝗻𝗴 & 𝗺𝗮𝗻𝗮𝗴𝗶𝗻𝗴 ML models is 𝗵𝗮𝗿𝗱, especially when running your models on GPUs.
But 𝘀𝗲𝗿𝘃𝗲𝗿𝗹𝗲𝘀𝘀 makes things 𝗲𝗮𝘀𝘆.
Using Beam as your serverless provider, deploying & managing ML models can be as easy as ↓
𝗗𝗲𝗳𝗶𝗻𝗲 𝘆𝗼𝘂𝗿 𝗶𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 & 𝗱𝗲𝗽𝗲𝗻𝗱𝗲𝗻𝗰𝗶𝗲𝘀
In a few lines of code, you define the application that contains:
- the requirements of your infrastructure, such as the CPU, RAM, and GPU
- the dependencies of your application
- the volumes from where you can load your data and store your artifacts
𝗗𝗲𝗽𝗹𝗼𝘆 𝘆𝗼𝘂𝗿 𝗷𝗼𝗯𝘀
Using the Beam application, you can quickly decore your Python functions to:
- run them once on the given serverless application
- put your task/job in a queue to be processed or even schedule it using a CRON-based syntax
- even deploy it as a RESTful API endpoint
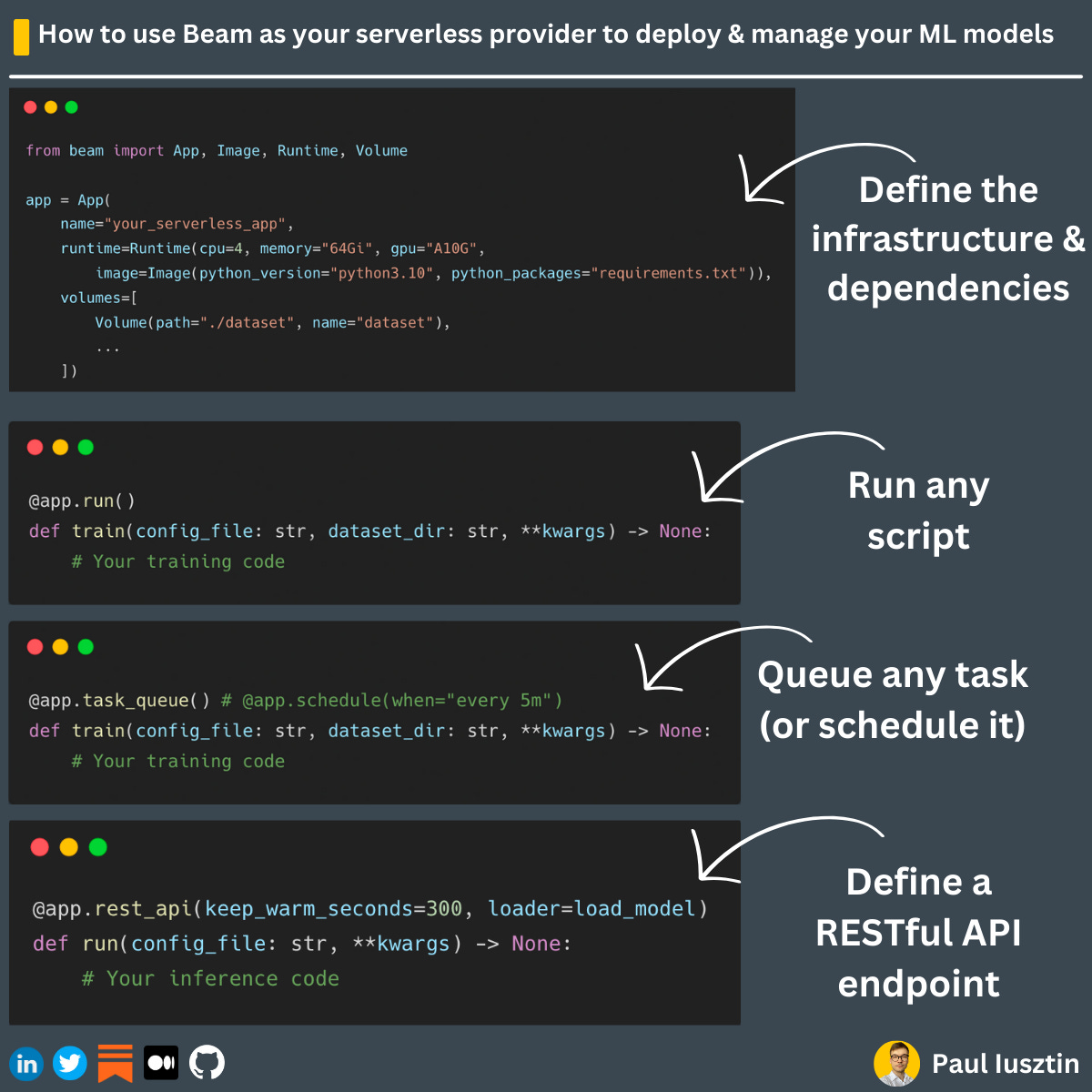
As you can see in the image below, you can have one central function for training or inference, and with minimal effort, you can switch from all these deployment methods.
Also, you don't have to bother at all with managing the infrastructure on which your jobs run. You specify what you need, and Beam takes care of the rest.
By doing so, you can directly start to focus on your application and stop carrying about the infrastructure.
This is the power of serverless!
↳🔗 Check out Beam to learn more
#2. 7 tips you must know to reduce your VRAM consumption of your LLMs during training
Here are 𝟳 𝘁𝗶𝗽𝘀 you must know to 𝗿𝗲𝗱𝘂𝗰𝗲 your 𝗩𝗥𝗔𝗠 𝗰𝗼𝗻𝘀𝘂𝗺𝗽𝘁𝗶𝗼𝗻 of your 𝗟𝗟𝗠𝘀 during 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 so you can 𝗳𝗶𝘁 it on 𝘅𝟭 𝗚𝗣𝗨.
When training LLMs, one of the pain points is to have enough VRAM on your system.
The good news is that the gods of DL are with us, and there are methods to lower your VRAM consumption without a significant impact on your performance ↓
𝟭. 𝗠𝗶𝘅𝗲𝗱-𝗽𝗿𝗲𝗰𝗶𝘀𝗶𝗼𝗻: During training you use both FP32 and FP16 in the following way: "FP32 weights" -> "FP16 weights" -> "FP16 gradients" -> "FP32 gradients" -> "Update weights" -> "FP32 weights" (and repeat). As you can see, the forward & backward passes are done in FP16, and only the optimization step is done in FP32, which reduces both the VRAM and runtime.
𝟮. 𝗟𝗼𝘄𝗲𝗿-𝗽𝗿𝗲𝗰𝗶𝘀𝗶𝗼𝗻: All your computations are done in FP16 instead of FP32. But the key is using bfloat16 ("Brain Floating Point"), a numerical representation Google developed for deep learning. It allows you to represent very large and small numbers, avoiding overflowing or underflowing scenarios.
𝟯. 𝗥𝗲𝗱𝘂𝗰𝗶𝗻𝗴 𝘁𝗵𝗲 𝗯𝗮𝘁𝗰𝗵 𝘀𝗶𝘇𝗲: This one is straightforward. Fewer samples per training iteration result in smaller VRAM requirements. The downside of this method is that you can't go too low with your batch size without impacting your model's performance.
𝟰. 𝗚𝗿𝗮𝗱𝗶𝗲𝗻𝘁 𝗮𝗰𝗰𝘂𝗺𝘂𝗹𝗮𝘁𝗶𝗼𝗻: It is a simple & powerful trick to increase your batch size virtually. You compute the gradients for "micro" batches (forward + backward passes). Once the accumulated gradients reach the given "virtual" target, the model weights are updated with the accumulated gradients. For example, you have a batch size of 4 and a micro-batch size of 1. Then, the forward & backward passes will be done using only x1 sample, and the optimization step will be done using the aggregated gradient of the 4 samples.
𝟱. 𝗨𝘀𝗲 𝗮 𝘀𝘁𝗮𝘁𝗲𝗹𝗲𝘀𝘀 𝗼𝗽𝘁𝗶𝗺𝗶𝘇𝗲𝗿: Adam is the most popular optimizer. It is one of the most stable optimizers, but the downside is that it has 2 additional parameters (a mean & variance) for every model parameter. If you use a stateless optimizer, such as SGD, you can reduce the number of parameters by 2/3, which is significant for LLMs.
𝟲. 𝗚𝗿𝗮𝗱𝗶𝗲𝗻𝘁 (𝗼𝗿 𝗮𝗰𝘁𝗶𝘃𝗮𝘁𝗶𝗼𝗻) 𝗰𝗵𝗲𝗰𝗸𝗽𝗼𝗶𝗻𝘁𝗶𝗻𝗴: It drops specific activations during the forward pass and recomputes them during the backward pass. Thus, it eliminates the need to hold all activations simultaneously in VRAM. This technique reduces VRAM consumption but makes the training slower.
𝟳. 𝗖𝗣𝗨 𝗽𝗮𝗿𝗮𝗺𝗲𝘁𝗲𝗿 𝗼𝗳𝗳𝗹𝗼𝗮𝗱𝗶𝗻𝗴: As the name suggests, the parameters that do not fit on your GPU's VRAM are loaded on the CPU. Intuitively, you can see it as a model parallelism between your GPU & CPU.

Most of these methods are orthogonal, so you can combine them and drastically reduce your VRAM requirements during training.
#3. 7-steps on how to fine-tune an open-source LLM to create your real-time financial advisor
In the past weeks, we covered 𝘄𝗵𝘆 you have to fine-tune an LLM and 𝘄𝗵𝗮𝘁 resources & tools you need:
- Q&A dataset
- pre-trained LLM (Falcon 7B) & QLoRA
- MLOps: experiment tracker, model registry, prompt monitoring (Comet ML)
- compute platform (Beam)
.
Now, let's see how you can hook all of these pieces together into a single fine-tuning module ↓
𝟭. 𝗟𝗼𝗮𝗱 𝘁𝗵𝗲 𝗤&𝗔 𝗱𝗮𝘁𝗮𝘀𝗲𝘁
Our Q&A samples have the following structure keys: "about_me," "user_context," "question," and "answer."
For task-specific fine-tuning, you need only 100-1000 samples. Thus, you can directly load the whole JSON in memory.
After you map every sample to a list of Python 𝘥𝘢𝘵𝘢𝘤𝘭𝘢𝘴𝘴𝘦𝘴 to validate the structure & type of the ingested instances.
𝟮. 𝗣𝗿𝗲𝗽𝗿𝗼𝗰𝗲𝘀𝘀 𝘁𝗵𝗲 𝗤&𝗔 𝗱𝗮𝘁𝗮𝘀𝗲𝘁 𝗶𝗻𝘁𝗼 𝗽𝗿𝗼𝗺𝗽𝘁𝘀
The first step is to use 𝘶𝘯𝘴𝘵𝘳𝘶𝘤𝘵𝘶𝘳𝘦𝘥 to clean every sample by removing redundant characters.
After, as every sample consists of multiple fields, you must map it to a single piece of text, also known as the prompt.
To do so, you define a 𝘗𝘳𝘰𝘮𝘱𝘵𝘛𝘦𝘮𝘱𝘭𝘢𝘵𝘦 class to manage all your prompts. You will use it to map all the sample keys to a prompt using a Python f-string.
The last step is to map the list of Python 𝘥𝘢𝘵𝘢𝘤𝘭𝘢𝘴𝘴𝘦𝘴 to a HuggingFace dataset and map every sample to a prompt, as discussed above.
𝟯. 𝗟𝗼𝗮𝗱 𝘁𝗵𝗲 𝗟𝗟𝗠 𝘂𝘀𝗶𝗻𝗴 𝗤𝗟𝗼𝗥𝗔
Load a pretrained Falcon 7B LLM by passing a 𝘣𝘪𝘵𝘴𝘢𝘯𝘥𝘣𝘺𝘵𝘦𝘴 quantization configuration that loads all the weights on 4 bits.
After using LoRA, you freeze the weights of the original Falcon LLM and attach to it a set of trainable adapters.
𝟰. 𝗙𝗶𝗻𝗲-𝘁𝘂𝗻𝗶𝗻𝗴
The 𝘵𝘳𝘭 Python package makes this step extremely simple.
You pass to the 𝘚𝘍𝘛𝘛𝘳𝘢𝘪𝘯𝘦𝘳 class the training arguments, the dataset and the model and call the 𝘵𝘳𝘢𝘪𝘯() method.
One crucial aspect is configuring an experiment tracker, such as Comet ML, to log the loss and other vital metrics & artifacts.
𝟱. 𝗣𝘂𝘀𝗵 𝘁𝗵𝗲 𝗯𝗲𝘀𝘁 𝗺𝗼𝗱𝗲𝗹 𝘁𝗼 𝘁𝗵𝗲 𝗺𝗼𝗱𝗲𝗹 𝗿𝗲𝗴𝗶𝘀𝘁𝗿𝘆
One of the final steps is to attach a callback to the 𝘚𝘍𝘛𝘛𝘳𝘢𝘪𝘯𝘦𝘳 class that runs when the training ends to push the model with the lowest loss to the model registry as the new production candidate.
𝟲. 𝗘𝘃𝗮𝗹𝘂𝗮𝘁𝗲 𝘁𝗵𝗲 𝗻𝗲𝘄 𝗽𝗿𝗼𝗱𝘂𝗰𝘁𝗶𝗼𝗻 𝗰𝗮𝗻𝗱𝗶𝗱𝗮𝘁𝗲
Evaluating generative AI models can be pretty tricky.
You can run the LLM on the test set and log the prompts & answers to Comet ML's monitoring system to check them manually.
If the provided answers are valid, using the model registry dashboard, you will manually release it to replace the old LLM.
𝟳. 𝗗𝗲𝗽𝗹𝗼𝘆 𝘁𝗼 𝗕𝗲𝗮𝗺
It is as easy as wrapping the training & inference functions (or classes) with a Python "@𝘢𝘱𝘱.𝘳𝘶𝘯()" decorator.

↳🔗 Check out the Hands-on LLMs course and support it with a ⭐.
That’s it for today 👾
See you next Thursday at 9:00 a.m. CET.
Have a fantastic weekend!
…and see you next week for Lesson 9, the last lesson of the Hands-On LLMs series 🔥
Paul
Whenever you’re ready, here is how I can help you:
The Full Stack 7-Steps MLOps Framework: a 7-lesson FREE course that will walk you step-by-step through how to design, implement, train, deploy, and monitor an ML batch system using MLOps good practices. It contains the source code + 2.5 hours of reading & video materials on Medium.
Machine Learning & MLOps Blog: in-depth topics about designing and productionizing ML systems using MLOps.
Machine Learning & MLOps Hub: a place where all my work is aggregated in one place (courses, articles, webinars, podcasts, etc.).