

DML: How to implement a streaming pipeline to populate a vector DB for real-time RAG?
Lesson 4 | The Hands-on LLMs Series

Hello there, I am Paul Iusztin 👋🏼
Within this newsletter, I will help you decode complex topics about ML & MLOps one week at a time 🔥
Lesson 4 | The Hands-on LLMs Series
Table of Contents:
What is Bytewax?
Why have vector DBs become so popular? Why are they so crucial for most ML applications?
How to implement a streaming pipeline to populate a vector DB for real-time RAG?
Previous Lessons:
↳🔗 Check out the Hands-on LLMs course and support it with a ⭐.
#1. What is Bytewax?
Are you afraid of writing 𝘀𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲𝘀? Or do you think they are hard to implement?
I did until I discovered Bytewax 🐝. Let me show you ↓
Bytewax 🐝 is an 𝗼𝗽𝗲𝗻-𝘀𝗼𝘂𝗿𝗰𝗲 𝘀𝘁𝗿𝗲𝗮𝗺 𝗽𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴 𝗳𝗿𝗮𝗺𝗲𝘄𝗼𝗿𝗸 that:
- is built in Rust ⚙️ for performance
- has Python 🐍 binding for ease of use
... so for all the Python fanatics out there, no more JVM headaches for you.
Jokes aside, here is why Bytewax 🐝 is so powerful ↓
- Bytewax local setup is plug-and-play
- can quickly be integrated into any Python project (you can go wild -- even use it in Notebooks)
- can easily be integrated with other Python packages (NumPy, PyTorch, HuggingFace, OpenCV, SkLearn, you name it)
- out-of-the-box connectors for Kafka, local files, or you can quickly implement your own
- CLI tool to easily deploy it to K8s, AWS, or GCP.
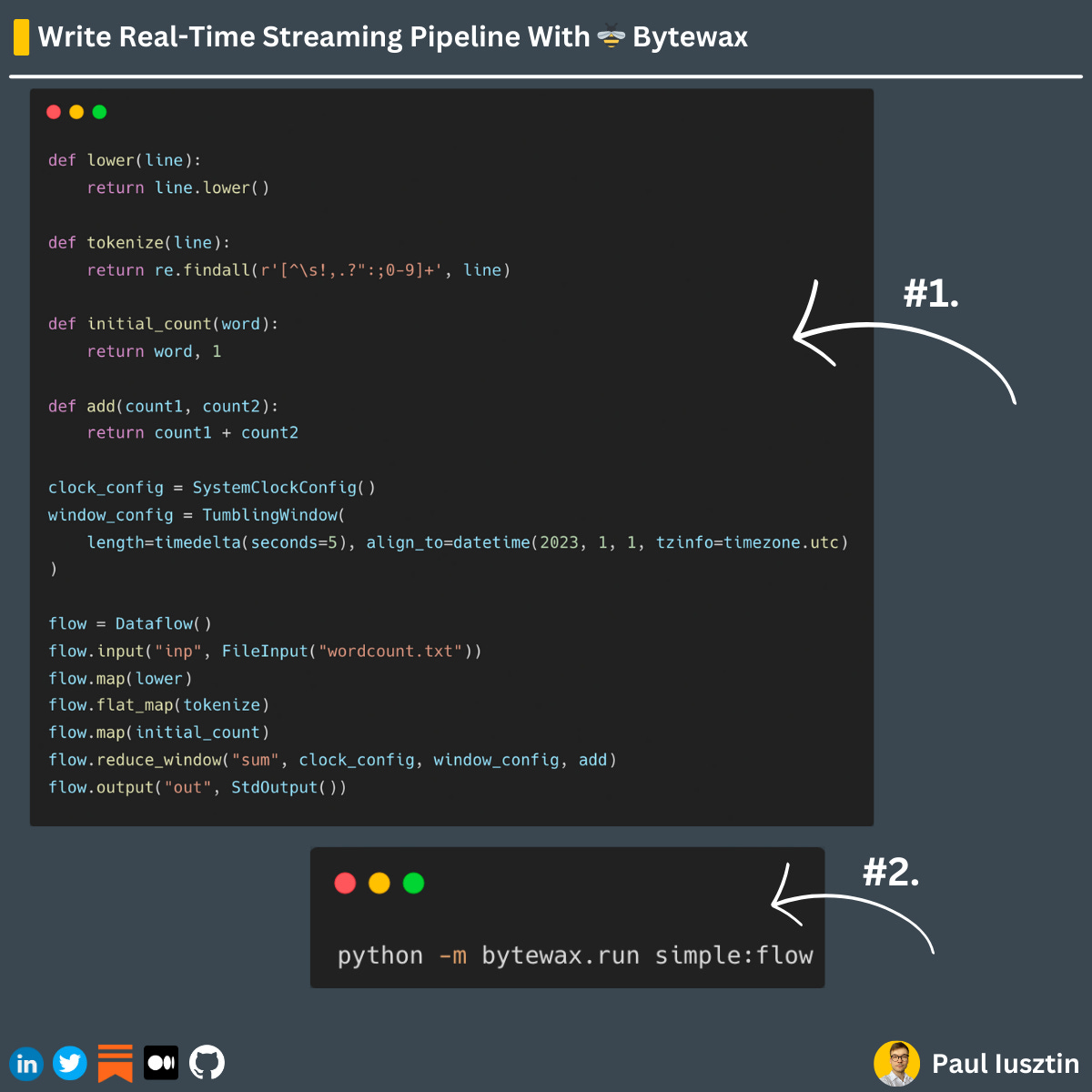
𝘍𝘰𝘳 𝘦𝘹𝘢𝘮𝘱𝘭𝘦 (𝘭𝘰𝘰𝘬 𝘢𝘵 𝘵𝘩𝘦 𝘪𝘮𝘢𝘨𝘦 𝘣𝘦𝘭𝘰𝘸):
1. We defined a streaming app in a few lines of code.
2. We run the streaming app with one command.
.
The thing is that I worked in Kafka Streams (in Kotlin) for one year.
I loved & understood the power of building streaming applications. The only thing that stood in my way was, well... Java.
I don't have something with Java; it is a powerful language. However, building an ML application in Java + Python takes much time due to a more significant resistance to integrating the two.
...and that's where Bytewax 🐝 kicks in.
We used Bytewax 🐝 for building the streaming pipeline for the 𝗛𝗮𝗻𝗱𝘀-𝗼𝗻 𝗟𝗟𝗠𝘀 course and loved it.
#2. Why have vector DBs become so popular? Why are they so crucial for most ML applications?
In the world of ML, everything can be represented as an embedding.
A vector DB is an intelligent way to use your data embeddings as an index and perform fast and scalable searches between unstructured data points.
Simply put, a vector DB allows you to find matches between anything and anything (e.g., use an image as a query to find similar pieces of text, video, other images, etc.).
.
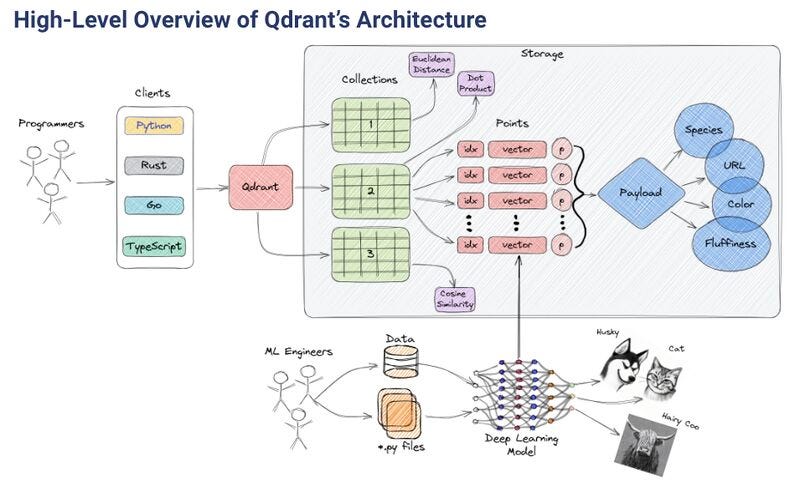
𝘐𝘯 𝘢 𝘯𝘶𝘵𝘴𝘩𝘦𝘭𝘭, 𝘵𝘩𝘪𝘴 𝘪𝘴 𝘩𝘰𝘸 𝘺𝘰𝘶 𝘤𝘢𝘯 𝘪𝘯𝘵𝘦𝘨𝘳𝘢𝘵𝘦 𝘢 𝘷𝘦𝘤𝘵𝘰𝘳 𝘋𝘉 𝘪𝘯 𝘳𝘦𝘢𝘭-𝘸𝘰𝘳𝘭𝘥 𝘴𝘤𝘦𝘯𝘢𝘳𝘪𝘰𝘴 ↓
Using various DL techniques, you can project your data points (images, videos, text, audio, user interactions) into the same vector space (aka the embeddings of the data).
You will load the embeddings along a payload (e.g., a URL to the image, date of creation, image description, properties, etc.) into the vector DB, where the data will be indexed along the:
- vector
- payload
- text within the payload
Now that the embedding indexes your data, you can query the vector DB by embedding any data point.
For example, you can query the vector DB with an image of your cat and use a filter to retrieve only "black" cats.
To do so, you must embed the image using the same model you used to embed the data within your vector DB. After you query the database using a given distance (e.g., cosine distance between 2 vectors) to find similar embeddings.
These similar embeddings have attached to them their payload that contains valuable information such as the URL to an image, a URL to a site, an ID of a user, a chapter from a book about the cat of a witch, etc.
.
Using this technique, I used Qdrant to implement RAG for a financial assistant powered by LLMs.
But vector DBs go beyond LLMs & RAG.
𝘏𝘦𝘳𝘦 𝘪𝘴 𝘢 𝘭𝘪𝘴𝘵 𝘰𝘧 𝘸𝘩𝘢𝘵 𝘺𝘰𝘶 𝘤𝘢𝘯 𝘣𝘶𝘪𝘭𝘥 𝘶𝘴𝘪𝘯𝘨 𝘷𝘦𝘤𝘵𝘰𝘳 𝘋𝘉𝘴 (e.g., Qdrant ):
- similar image search
- semantic text search (instead of plain text search)
- recommender systems
- RAG for chatbots
- anomalies detection
↳🔗 𝘊𝘩𝘦𝘤𝘬 𝘰𝘶𝘵 𝘘𝘥𝘳𝘢𝘯𝘵'𝘴 𝘨𝘶𝘪𝘥𝘦𝘴 𝘢𝘯𝘥 𝘵𝘶𝘵𝘰𝘳𝘪𝘢𝘭𝘴 𝘵𝘰 𝘭𝘦𝘢𝘳𝘯 𝘮𝘰𝘳𝘦 𝘢𝘣𝘰𝘶𝘵 𝘷𝘦𝘤𝘵𝘰𝘳 𝘋𝘉𝘴.
#3. How to implement a streaming pipeline to populate a vector DB for real-time RAG?
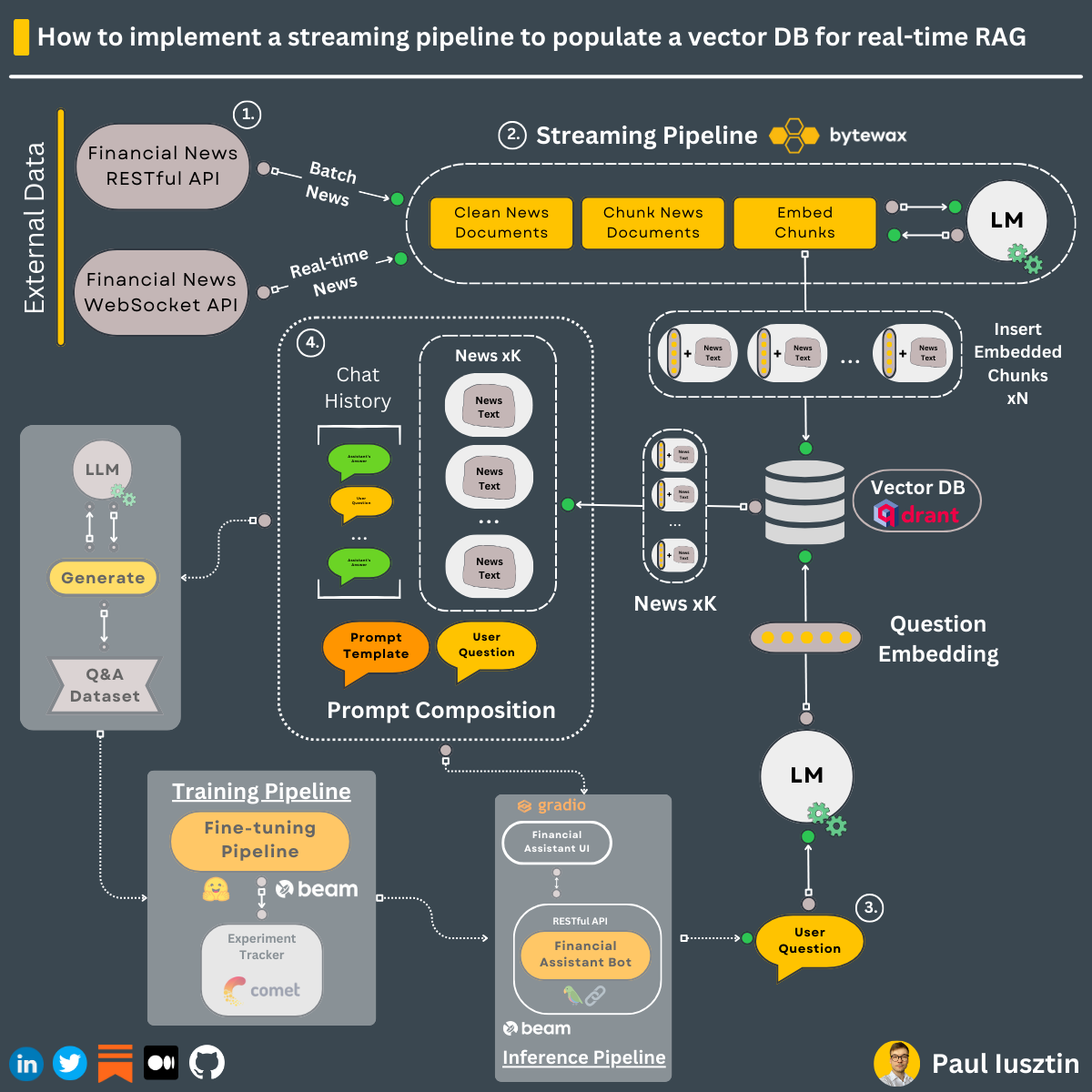
This is 𝗵𝗼𝘄 you can 𝗶𝗺𝗽𝗹𝗲𝗺𝗲𝗻𝘁 a 𝘀𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲 to populate a 𝘃𝗲𝗰𝘁𝗼𝗿 𝗗𝗕 to do 𝗥𝗔𝗚 for a 𝗳𝗶𝗻𝗮𝗻𝗰𝗶𝗮𝗹 𝗮𝘀𝘀𝗶𝘀𝘁𝗮𝗻𝘁 powered by 𝗟𝗟𝗠𝘀.
In a previous post, I covered 𝘄𝗵𝘆 you need a streaming pipeline over a batch pipeline when implementing RAG.
Now, we will focus on the 𝗵𝗼𝘄, aka implementation details ↓
🐝 All the following steps are wrapped in Bytewax functions and connected in a single streaming pipeline.
𝗘𝘅𝘁𝗿𝗮𝗰𝘁 𝗳𝗶𝗻𝗮𝗻𝗰𝗶𝗮𝗹 𝗻𝗲𝘄𝘀 𝗳𝗿𝗼𝗺 𝗔𝗹𝗽𝗮𝗰𝗮
You need 2 types of inputs:
1. A WebSocket API to listen to financial news in real-time. This will be used to listen 24/7 for new data and ingest it as soon as it is available.
2. A RESTful API to ingest historical data in batch mode. When you deploy a fresh vector DB, you must populate it with data between a given range [date_start; date_end].
You wrap the ingested HTML document and its metadata in a `pydantic` NewsArticle model to validate its schema.
Regardless of the input type, the ingested data is the same. Thus, the following steps are the same for both data inputs ↓
𝗣𝗮𝗿𝘀𝗲 𝘁𝗵𝗲 𝗛𝗧𝗠𝗟 𝗰𝗼𝗻𝘁𝗲𝗻𝘁
As the ingested financial news is in HTML, you must extract the text from particular HTML tags.
`unstructured` makes it as easy as calling `partition_html(document)`, which will recursively return the text within all essential HTML tags.
The parsed NewsArticle model is mapped into another `pydantic` model to validate its new schema.
The elements of the news article are the headline, summary and full content.
𝗖𝗹𝗲𝗮𝗻 𝘁𝗵𝗲 𝘁𝗲𝘅𝘁
Now we have a bunch of text that has to be cleaned. Again, `unstructured` makes things easy. Calling a few functions we clean:
- the dashes & bullets
- extra whitespace & trailing punctuation
- non ascii chars
- invalid quotes
Finally, we standardize everything to lowercase.
𝗖𝗵𝘂𝗻𝗸 𝘁𝗵𝗲 𝘁𝗲𝘅𝘁
As the text can exceed the context window of the embedding model, we have to chunk it.
Yet again, `unstructured` provides a valuable function that splits the text based on the tokenized text and expected input length of the embedding model.
This strategy is naive, as it doesn't consider the text's structure, such as chapters, paragraphs, etc. As the news is short, this is not an issue, but LangChain provides a `RecursiveCharacterTextSplitter` class that does that if required.
𝗘𝗺𝗯𝗲𝗱 𝘁𝗵𝗲 𝗰𝗵𝘂𝗻𝗸𝘀
You pass all the chunks through an encoder-only model.
We have used `all-MiniLM-L6-v2` from `sentence-transformers`, a small model that can run on a CPU and outputs a 384 embedding.
But based on the size and complexity of your data, you might need more complex and bigger models.
𝗟𝗼𝗮𝗱 𝘁𝗵𝗲 𝗱𝗮𝘁𝗮 𝗶𝗻 𝘁𝗵𝗲 𝗤𝗱𝗿𝗮𝗻𝘁 𝘃𝗲𝗰𝘁𝗼𝗿 𝗗𝗕
Finally, you insert the embedded chunks and their metadata into the Qdrant vector DB.
The metadata contains the embedded text, the source_url and the publish date.
↳🔗 Check out the Hands-on LLMs course to see this in action.
That’s it for today 👾
See you next Thursday at 9:00 a.m. CET.
Have a fantastic weekend!
…and see you next week for Lesson 5 of the Hands-On LLMs series 🔥
Paul
Whenever you’re ready, here is how I can help you:
The Full Stack 7-Steps MLOps Framework: a 7-lesson FREE course that will walk you step-by-step through how to design, implement, train, deploy, and monitor an ML batch system using MLOps good practices. It contains the source code + 2.5 hours of reading & video materials on Medium.
Machine Learning & MLOps Blog: in-depth topics about designing and productionizing ML systems using MLOps.
Machine Learning & MLOps Hub: a place where all my work is aggregated in one place (courses, articles, webinars, podcasts, etc.).