

DML: Top 6 ML Platform Features You Must Know to Build an ML System
Why serving an ML model using a batch architecture is so powerful? Top 6 ML platform features you must know.

Hello there, I am Paul Iusztin 👋🏼
Within this newsletter, I will help you decode complex topics about ML & MLOps one week at a time 🔥
This week we will cover:
Top 6 ML platform features you must know to build an ML system
Why serving an ML model using a batch architecture is so powerful?
Story: “I never forget anything” - said no one but your second brain.
This week, no shameless promotion 👀
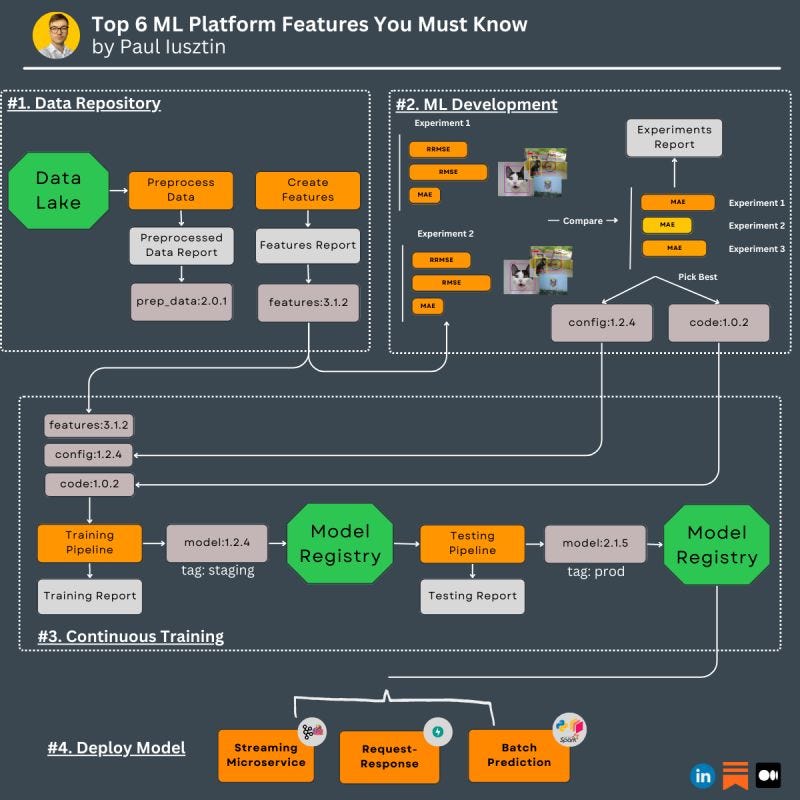
#1. Top 6 ML platform features you must know to build an ML system
Here they are ↓
#𝟭. 𝗘𝘅𝗽𝗲𝗿𝗶𝗺𝗲𝗻𝘁 𝗧𝗿𝗮𝗰𝗸𝗶𝗻𝗴
In your ML development phase, you generate lots of experiments.
Tracking and comparing the metrics between them is crucial in finding the optimal model.
#𝟮. 𝗠𝗲𝘁𝗮𝗱𝗮𝘁𝗮 𝗦𝘁𝗼𝗿𝗲
Its primary purpose is reproducibility.
To know how a model was generated, you need to know:
- the version of the code
- the version of the packages
- hyperparameters/config
- total compute
- version of the dataset
... and more
#𝟯. 𝗩𝗶𝘀𝘂𝗮𝗹𝗶𝘀𝗮𝘁𝗶𝗼𝗻𝘀
Most of the time, along with the metrics, you must log a set of visualizations for your experiment.
Such as:
- images
- videos
- prompts
- t-SNE graphs
- 3D point clouds
... and more
#𝟰. 𝗥𝗲𝗽𝗼𝗿𝘁𝘀
You don't work in a vacuum.
You have to present your work to other colleges or clients.
A report lets you take the metadata and visualizations from your experiment...
...and create, deliver and share a targeted presentation for your clients or peers.
#𝟱. 𝗔𝗿𝘁𝗶𝗳𝗮𝗰𝘁𝘀
The most powerful feature out of them all.
An artifact is a versioned object that is an input or output for your task.
Everything can be an artifact, but the most common cases are:
- data
- model
- code
Wrapping your assets around an artifact ensures reproducibility.
For example, you wrap your features into an artifact (e.g., features:3.1.2), which you can consume into your ML development step.
The ML development step will generate config (e.g., config:1.2.4) and code (e.g., code:1.0.2) artifacts used in the continuous training pipeline.
Doing so lets you quickly respond to questions such as "What I used to generate the model?" and "What Version?"
#𝟲. 𝗠𝗼𝗱𝗲𝗹 𝗥𝗲𝗴𝗶𝘀𝘁𝗿𝘆
The model registry is the ultimate way to make your model accessible to your production ecosystem.
For example, in your continuous training pipeline, after the model is trained, you load the weights as an artifact into the model registry (e.g., model:1.2.4).
You label this model as "staging" under a new version and prepare it for testing. If the tests pass, mark it as "production" under a new version and prepare it for deployment (e.g., model:2.1.5).
.
All of these features are used in a mature ML system. What is your favorite one?
↳ You can see all these features in action in my: 🔗 The Full Stack 7-Steps MLOps Framework FREE course.
#2. Why serving an ML model using a batch architecture is so powerful?
When you first start deploying your ML model, you want an initial end-to-end flow as fast as possible.
Doing so lets you quickly provide value, get feedback, and even collect data.
.
But here is the catch...
Successfully serving an ML model is tricky as you need many iterations to optimize your model to work in real-time:
- low latency
- high throughput
Initially, serving your model in batch mode is like a hack.
By storing the model's predictions in dedicated storage, you automatically move your model from offline mode to a real-time online model.
Thus, you no longer have to care for your model's latency and throughput. The consumer will directly load the predictions from the given storage.
𝐓𝐡𝐞𝐬𝐞 𝐚𝐫𝐞 𝐭𝐡𝐞 𝐦𝐚𝐢𝐧 𝐬𝐭𝐞𝐩𝐬 𝐨𝐟 𝐚 𝐛𝐚𝐭𝐜𝐡 𝐚𝐫𝐜𝐡𝐢𝐭𝐞𝐜𝐭𝐮𝐫𝐞:
- extracts raw data from a real data source
- clean, validate, and aggregate the raw data within a feature pipeline
- load the cleaned data into a feature store
- experiment to find the best model + transformations using the data from the feature store
- upload the best model from the training pipeline into the model registry
- inside a batch prediction pipeline, use the best model from the model registry to compute the predictions
- store the predictions in some storage
- the consumer will download the predictions from the storage
- repeat the whole process hourly, daily, weekly, etc. (it depends on your context)
.
𝘛𝘩𝘦 𝘮𝘢𝘪𝘯 𝘥𝘰𝘸𝘯𝘴𝘪𝘥𝘦 of deploying your model in batch mode is that the predictions will have a level of lag.
For example, in a recommender system, if you make your predictions daily, it won't capture a user's behavior in real-time, and it will update the predictions only at the end of the day.
Moving to other architectures, such as request-response or streaming, will be natural after your system matures in batch mode.
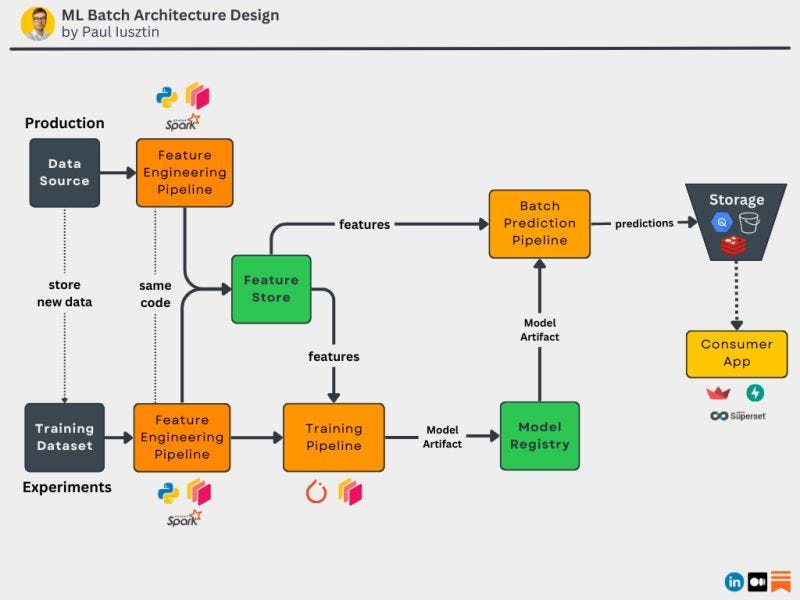
So remember, when you initially deploy your model, using a batch mode architecture will be your best shot for a good user experience.
Story: “I never forget anything” - said no one but your second brain.
After 6+ months of refinement, this is my second brain strategy 👇
Tiago's Forte book inspired me, but I adapted his system to my needs.
.
#𝟬. 𝗖𝗼𝗹𝗹𝗲𝗰𝘁
This is where you are bombarded with information from all over the place.
#𝟭. 𝗧𝗵𝗲 𝗚𝗿𝗮𝘃𝗲𝘆𝗮𝗿𝗱
This is where I save everything that looks interesting.
I won't use 90% of what is here, but it satisfied my urge to save that "cool article" I saw on LinkedIn.
Tools: Mostly Browser Bookmarks, but I rarely use GitHub stars, Medium lists, etc.
#𝟮. 𝗧𝗵𝗲 𝗕𝗼𝗮𝗿𝗱
Here, I start converging the information and planning what to do next.
Tools: Notion
#𝟯. 𝗧𝗵𝗲 𝗙𝗶𝗲𝗹𝗱
Here is where I express myself through learning, coding, writing, etc.
Tools: whatever you need to express yourself.
2 & 3 are iterative processes. Thus I often bounce between them until the information is distilled.
#𝟰. 𝗧𝗵𝗲 𝗪𝗮𝗿𝗲𝗵𝗼𝘂𝘀𝗲
Here is where I take the distilled information and write it down for cold storage.
Tools: Notion, Google Drive
.
When I want to search for a piece of information, I start from the Warehouse and go backward until I find what I need.
As a minimalist, I kept my tools to a minimum. I primarily use only: Brave, Notion, and Google Drive.
You don't need 100+ tools to be productive. They just want to take your money from you.
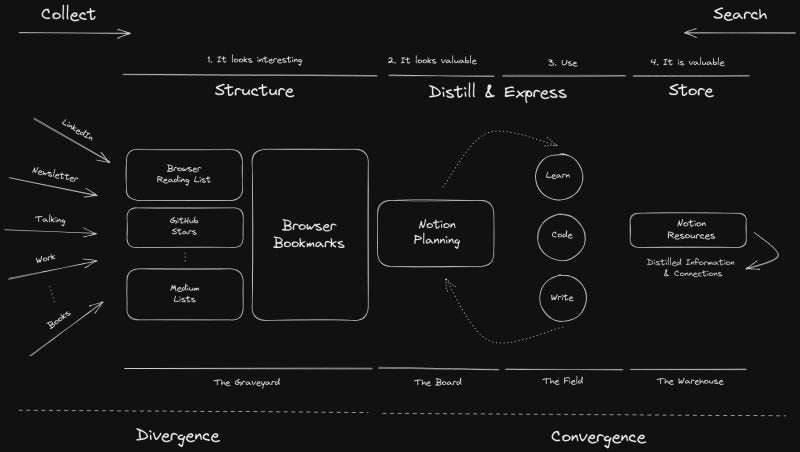
So remember...
You have to:
- collect
- link
- plan
- distill
- store
That’s it for today 👾
See you next Thursday at 9:00 am CET.
Have a fantastic weekend!
Paul
Whenever you’re ready, here is how I can help you:
The Full Stack 7-Steps MLOps Framework: a 7-lesson FREE course that will walk you step-by-step through how to design, implement, train, deploy, and monitor an ML batch system using MLOps good practices. It contains the source code + 2.5 hours of reading & video materials on Medium.
Machine Learning & MLOps Blog: here, I approach in-depth topics about designing and productionizing ML systems using MLOps.
Machine Learning & MLOps Hub: a place where I will constantly aggregate all my work (courses, articles, webinars, podcasts, etc.),
Hello Paul!
Great newsletter. It'd be even more useful to suggest tools for each of these features (e.g. the model registry, the feature store, etc)