

DML: Unwrapping the 3-pipeline design of a financial assistant powered by LLMs | LLMOps vs. MLOps
Lesson 2 | The Hands-on LLMs Series

Hello there, I am Paul Iusztin 👋🏼
Within this newsletter, I will help you decode complex topics about ML & MLOps one week at a time 🔥
Lesson 2 | The Hands-on LLMs Series
Table of Contents:
Introduction video lessons
What is LLMOps? MLOps vs. LLMOps
Unwrapping step-by-step the 3-pipeline design of a financial assistant powered by LLMs
Previous Lessons:
↳🔗 Check out the Hands-on LLMs course and support it with a ⭐.
#1. Introduction video lessons
We started releasing the first video lessons of the course.
This is a recording of me, where I presented at a webinar hosted by Gathers, a 1.5-hour overview of the 𝗛𝗮𝗻𝗱𝘀-𝗼𝗻 𝗟𝗟𝗠𝘀 course.
Check it out to get a gut feeling of the LLM system ↓
This is the 1st official lesson of the Hands-on LLMs course presented by no other but
from the Real-World Machine Learning newsletter (if you wonder, the course is the result of our collaboration).Pau is one of the best teachers I know. If you have some spare time, it is worth it ↓
↳🔗 Check out the Hands-on LLMs course and support it with a ⭐.
#2. What is LLMOps? MLOps vs. LLMOps
LLMOps here, LLMOps there, but did you take the time to see how it differs from MLOps?
If not, here is a 2-min LLMOps vs. MLOps summary ↓
𝗪𝗵𝗮𝘁 𝗶𝘀 𝗟𝗟𝗠𝗢𝗽𝘀?
Well, everything revolves around the idea that "Size matters."
LLMOps is about best practices for efficient deployment, monitoring and maintenance, but this time for large language models.
LLMOps is a subset of MLOps, focusing on training & deploying large models trained on big data.
Intuitive right?
𝗕𝘂𝘁 𝗵𝗲𝗿𝗲 𝗮𝗿𝗲 𝟱 𝗟𝗟𝗠𝗢𝗽𝘀 𝘂𝗻𝗶𝗾𝘂𝗲 𝗳𝗮𝗰𝘁𝗼𝗿𝘀 𝘁𝗵𝗮𝘁 𝘀𝗲𝘁 𝗶𝘁 𝗮𝗽𝗮𝗿𝘁 𝗳𝗿𝗼𝗺 𝗠𝗟𝗢𝗽𝘀 ↓
𝟭. 𝗖𝗼𝗺𝗽𝘂𝘁𝗮𝘁𝗶𝗼𝗻𝗮𝗹 𝗿𝗲𝘀𝗼𝘂𝗿𝗰𝗲𝘀: training your models on CUDA-enabled GPUs is more critical than ever, along with knowing how to run your jobs on a cluster of GPUs leveraging data & model parallelism using techniques such as ZeRO from DeepSpeed. Also, the high cost of inference makes model compression techniques essential for deployment.
𝟮. 𝗧𝗿𝗮𝗻𝘀𝗳𝗲𝗿 𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴: training models from scratch is a thing of the past. In most use cases, you will fine-tune the model on specific tasks, leveraging techniques such as LLaMA-Adapters or QLora.
𝟯. 𝗛𝘂𝗺𝗮𝗻 𝗳𝗲𝗲𝗱𝗯𝗮𝗰𝗸: reinforcement learning from human feedback (RLHF) showed much potential in improving the quality of generated outputs. But to do RLHF, you have to introduce a feedback loop within your ML system that lets you evaluate the generated results based on human feedback, which are even further used to fine-tune your LLMs.
𝟰. 𝗚𝘂𝗮𝗿𝗱𝗿𝗮𝗶𝗹𝘀: to create safe systems, you must protect your systems against harmful or violent inputs and outputs. Also, when designing your prompt templates, you must consider hallucinations and prompt hacking.
𝟱. 𝗠𝗼𝗻𝗶𝘁𝗼𝗿𝗶𝗻𝗴 & 𝗮𝗻𝗮𝗹𝘆𝘇𝗶𝗻𝗴 𝗽𝗿𝗼𝗺𝗽𝘁𝘀: most ML platforms (e.g., Comet ML) introduced specialized logging tools to debug and monitor your LLMs to help you find better prompt templates and protect against hallucination and hacking.

To conclude...
LLMOps isn't anything new for those familiar with MLOps and Deep Learning.
For example, training deep learning models on clusters of GPUs or fine-tuning them isn't new, but now it is more important than ever to master these skills as models get bigger and bigger.
But it indeed introduced novel techniques to fine-tune models (e.g., QLora), to merge the fields of RL and DL, and a plethora of tools around prompt manipulation & storing, such as:
- vector DBs (e.g., Qdrant)
- prompt chaining (e.g., LangChain)
- prompt logging & analytics (e.g., Comet LLMOps)
.
But with the new multi-modal large models trend, these tips & tricks will converge towards all deep learning models (e.g., computer vision), and soon, we will change the name of LLMOps to DLOps or LMOps.
What do you think? Is the term of LLMOps going to stick around?
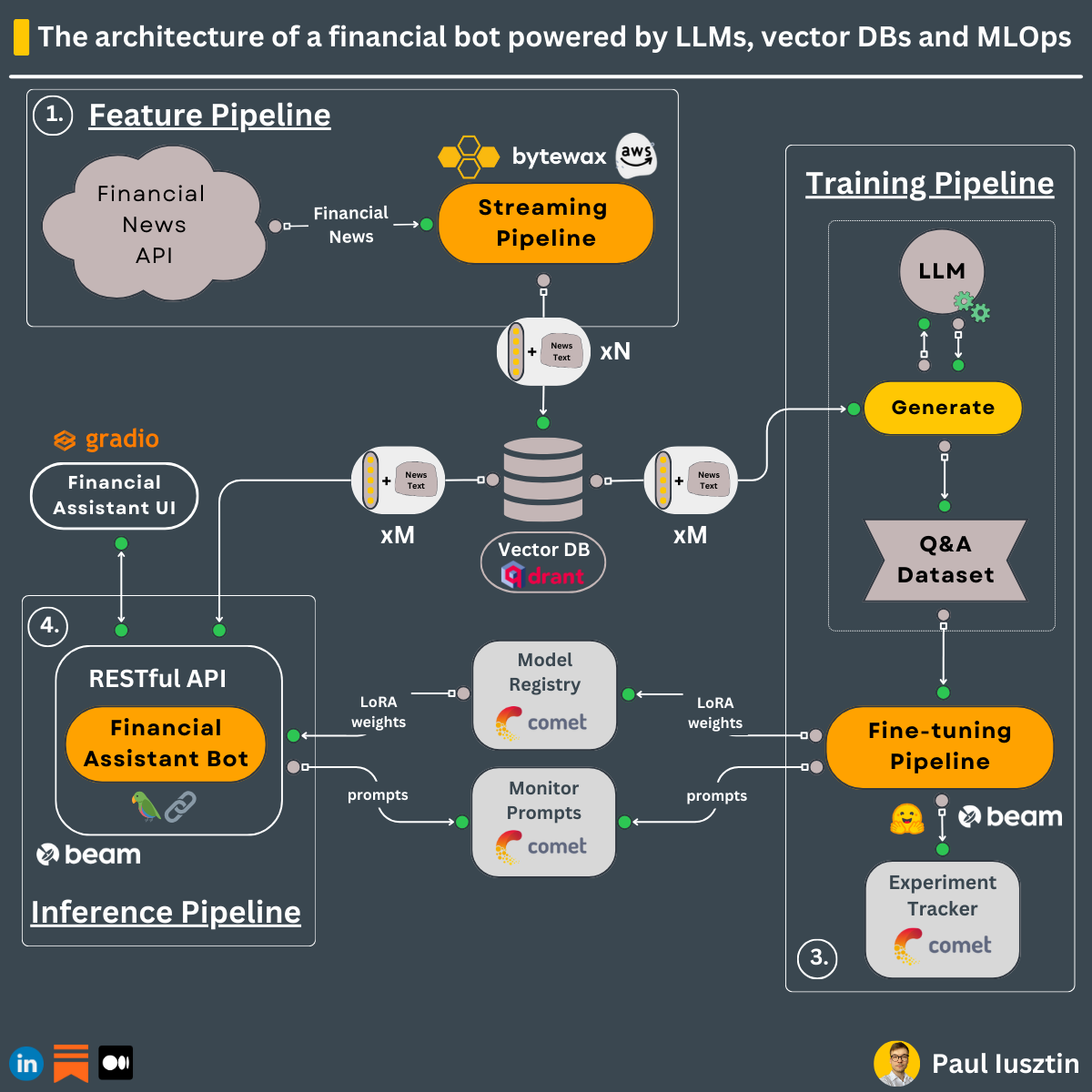
#3. Unwrapping step-by-step the 3-pipeline design of a financial assistant powered by LLMs
Here is a step-by-step guide on designing the architecture of a financial assistant powered by LLMs, vector DBs and MLOps.
The 3-pipeline design, also known as the FTI architecture, makes things simple ↓
=== 𝗙𝗲𝗮𝘁𝘂𝗿𝗲 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲 ===
We want to build a streaming pipeline that listens to real-time financial news, embeds the news, and loads everything in a vector DB. The goal is to add up-to-date news to the user's questions using RAG to avoid retraining.
1. We listen 24/7 to financial news from Alpaca through a WebSocket wrapped over a Bytewax connector
2. Once any financial news is received, these are passed to the Bytewax flow that:
- extracts & cleans the necessary information from the news HTML document
- chunks the text based on the LLM's max context window
- embeds all the chunks using the "all-MiniLM-L6-v2" encoder-only model from sentence-transformers
- inserts all the embeddings along their metadata to Qdrant
3. The streaming pipeline is deployed to an EC2 machine that runs multiple Bytewax processes. It can be deployed to K8s into a multi-node setup to scale up.
=== 𝗧𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲 ===
We want to fine-tune a pretrained LLM to specialize the model to answer financial-based questions.
1. Manually fill ~100 financial questions.
2. Use RAG to enrich the questions using the financial news from the Qdrant vector DB.
3. Use a powerful model such as GPT-4 to answer them, or hire an expert if you have more time and resources.
4. Load Falcon from HuggingFace using QLoRA to fit on a single GPU.
5. Preprocess the Q&A dataset into prompts.
6. Fine-tune the LLM and log all the artifacts to Comet's experiment tracker (loss, model weights, etc.)
7. For every epoch, run the LLM on your test set, log the prompts to Comet's prompt logging feature and compute the metrics.
8. Send the best LoRA weights to the model registry as the next production candidate.
9. Deploy steps 4-8 to Beam to run the training on an A10G or A100 Nvidia GPU.
=== 𝗜𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲 𝗣𝗶𝗽𝗲𝗹𝗶𝗻𝗲 ===
We want to hook the financial news stored in the Qdrant Vector DB and the Falcon fine-tuned model into a single entity exposed under a RESTful API.
Steps 1-7 are all chained together using LangChain.
1. Use the "all-MiniLM-L6-v2" encoder-only model to embed the user's question.
2. Using the question embedding, query the Qdrant vector DB to find the top 3 related financial news.
3. Attach the text (stored as metadata along the embeddings) of the news to the prompt (aka RAG).
4. Download Falcon's pretrained weights from HF & LoRA's fine-tuned weights from Comet's model registry.
5. Load the LLM and pass the prompt (= the user's question, financial news, history) to it.
6. Store the conversation in LangChain's memory.
7. Deploy steps 1-7 under a RESTful API using Beam.
↳🔗 Check out the Hands-on LLMs course to see this in action.
That’s it for today 👾
See you next Thursday at 9:00 a.m. CET.
Have a fantastic weekend!
…and see you next week for Lesson 3 of the Hands-On LLMs series 🔥
Paul
Whenever you’re ready, here is how I can help you:
The Full Stack 7-Steps MLOps Framework: a 7-lesson FREE course that will walk you step-by-step through how to design, implement, train, deploy, and monitor an ML batch system using MLOps good practices. It contains the source code + 2.5 hours of reading & video materials on Medium.
Machine Learning & MLOps Blog: in-depth topics about designing and productionizing ML systems using MLOps.
Machine Learning & MLOps Hub: a place where all my work is aggregated in one place (courses, articles, webinars, podcasts, etc.).