



DML: What do you need to fine-tune an open-source LLM to create your financial advisor?
Lesson 6 | The Hands-on LLMs Series

Hello there, I am Paul Iusztin 👋🏼
Within this newsletter, I will help you decode complex topics about ML & MLOps one week at a time 🔥
Lesson 6 | The Hands-on LLMs Series
Table of Contents:
The difference between encoders, decoders, and encoder-decoder LLMs.
You must know these 3 main stages of training an LLM to train your own LLM on your proprietary data.
What do you need to fine-tune an open-source LLM to create your own financial advisor?
Previous Lessons:
↳🔗 Check out the Hands-on LLMs course and support it with a ⭐.
#1. The difference between encoders, decoders, and encoder-decoder LLMs
Let's see when to use each architecture ↓
As embeddings are everywhere, both encoders and decoders use self-attention layers to encode word tokens into embeddings.
The devil is in the details. Let's clarify it ↓
𝗧𝗵𝗲 𝗢𝗿𝗶𝗴𝗶𝗻𝗮𝗹 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺𝗲𝗿
It is an encoder-decoder setup. The encoder processes the input text and hands off its understanding as embeddings to the decoder, which will generate the final output.
The key difference between an encoder & decoder is in how it processes its inputs & outputs.
=== 𝗘𝗻𝗰𝗼𝗱𝗲𝗿𝘀 ===
The role of an encoder is to extract relevant information from the whole input and encode it into an embedding (e.g., BERT, RoBERTa).
Within the "Multi-head attention" of the transformer, all the tokens are allowed to speak to each other.
A token at position t can talk to all other previous tokens [0, t-1] and future tokens [t+1, T]. This means that the attention mask is computed along the whole vector.
Thus, because the encoder processes the whole input, it is helpful for classification tasks (e.g., sentiment analysis) and creates embeddings for clustering, recommender systems, vector DB indexes, etc.
=== 𝗗𝗲𝗰𝗼𝗱𝗲𝗿𝘀 ===
On the flip side, if you want to generate text, use decoder-only models (e.g., GPT family).
Only the current and previous tokens (not the whole input) are used to predict the next token.
Within the "Masked Multi-head attention," the future positions are masked to maintain the autoregressive property of the decoding process.
For example, within the "Masked Multi-head attention," instead of all the tokens talking to each other, a token at position t will have access only to previous tokens at positions t-1, t-2, t-3, ..., 0.
=== 𝗘𝗻𝗰𝗼𝗱𝗲𝗿-𝗱𝗲𝗰𝗼𝗱𝗲𝗿 ===
This technique is used when you have to understand the entire input sequence (encoder) and the previously generated sequence (decoder -> autoregressive).
Typical use cases are text translation & summarization (the original transformer was built for text translation), where the output heavily relies on the input.
Why? Because the decoding step always has to be conditioned by the encoded information. Also known as cross-attention, the decoder queries the encoded information for information to guide the decoding process.
For example, when translating English to Spanish, every Spanish token predicted is conditioned by the previously predicted Spanish tokens & the entire English sentence.
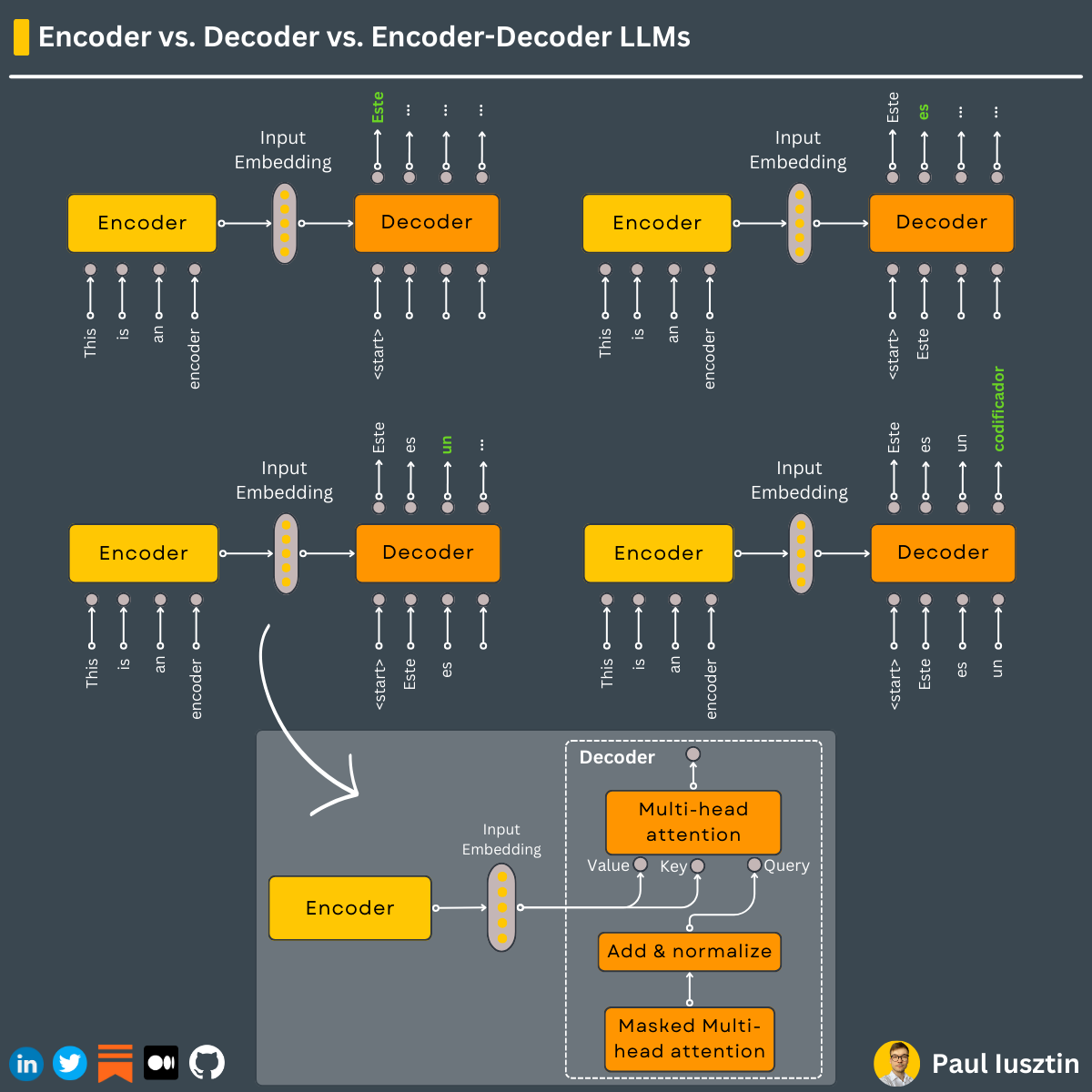
To conclude...
- a decoder takes as input previous tokens and predicts the next one (in an autoregressive way)
- by dropping the "Masked" logic from the "Masked Multi-head attention," you process the whole input, transforming the decoder into an encoder
- if you hook the encoder to the decoder through a cross-attention layer, you have an encoder-decoder architecture
#2. You must know these 3 main stages of training an LLM to train your own LLM on your proprietary data
You must know these 𝟯 𝗺𝗮𝗶𝗻 𝘀𝘁𝗮𝗴𝗲𝘀 of 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗮𝗻 𝗟𝗟𝗠 to train your own 𝗟𝗟𝗠 on your 𝗽𝗿𝗼𝗽𝗿𝗶𝗲𝘁𝗮𝗿𝘆 𝗱𝗮𝘁𝗮.
# 𝗦𝘁𝗮𝗴𝗲 𝟭: 𝗣𝗿𝗲𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴 𝗳𝗼𝗿 𝗰𝗼𝗺𝗽𝗹𝗲𝘁𝗶𝗼𝗻
You start with a bear foot randomly initialized LLM.
This stage aims to teach the model to spit out tokens. More concretely, based on previous tokens, the model learns to predict the next token with the highest probability.
For example, your input to the model is "The best programming language is ___", and it will answer, "The best programming language is Rust."
Intuitively, at this stage, the LLM learns to speak.
𝘋𝘢𝘵𝘢: >1 trillion token (~= 15 million books). The data quality doesn't have to be great. Hence, you can scrape data from the internet.
# 𝗦𝘁𝗮𝗴𝗲 𝟮: 𝗦𝘂𝗽𝗲𝗿𝘃𝗶𝘀𝗲𝗱 𝗳𝗶𝗻𝗲-𝘁𝘂𝗻𝗶𝗻𝗴 (𝗦𝗙𝗧) 𝗳𝗼𝗿 𝗱𝗶𝗮𝗹𝗼𝗴𝘂𝗲
You start with the pretrained model from stage 1.
This stage aims to teach the model to respond to the user's questions.
For example, without this step, when prompting: "What is the best programming language?", it has a high probability of creating a series of questions such as: "What is MLOps? What is MLE? etc."
As the model mimics the training data, you must fine-tune it on Q&A (questions & answers) data to align the model to respond to questions instead of predicting the following tokens.
After the fine-tuning step, when prompted, "What is the best programming language?", it will respond, "Rust".
𝘋𝘢𝘵𝘢: 10K - 100K Q&A example
𝘕𝘰𝘵𝘦: After aligning the model to respond to questions, you can further single-task fine-tune the model, on Q&A data, on a specific use case to specialize the LLM.
# 𝗦𝘁𝗮𝗴𝗲 𝟯: 𝗥𝗲𝗶𝗻𝗳𝗼𝗿𝗰𝗲𝗺𝗲𝗻𝘁 𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗳𝗿𝗼𝗺 𝗵𝘂𝗺𝗮𝗻 𝗳𝗲𝗲𝗱𝗯𝗮𝗰𝗸 (𝗥𝗟𝗛𝗙)
Demonstration data tells the model what kind of responses to give but doesn't tell the model how good or bad a response is.
The goal is to align your model with user feedback (what users liked or didn't like) to increase the probability of generating answers that users find helpful.
𝘙𝘓𝘏𝘍 𝘪𝘴 𝘴𝘱𝘭𝘪𝘵 𝘪𝘯 2:
1. Using the LLM from stage 2, train a reward model to act as a scoring function using (prompt, winning_response, losing_response) samples (= comparison data). The model will learn to maximize the difference between these 2. After training, this model outputs rewards for (prompt, response) tuples.
𝘋𝘢𝘵𝘢: 100K - 1M comparisons
2. Use an RL algorithm (e.g., PPO) to fine-tune the LLM from stage 2. Here, you will use the reward model trained above to give a score for every: (prompt, response). The RL algorithm will align the LLM to generate prompts with higher rewards, increasing the probability of generating responses that users liked.
𝘋𝘢𝘵𝘢: 10K - 100K prompts

Note: Post inspired by Chip Huyen's 🔗 RLHF: Reinforcement Learning from Human Feedback" article.
#3. What do you need to fine-tune an open-source LLM to create your own financial advisor?
This is the 𝗟𝗟𝗠 𝗳𝗶𝗻𝗲-𝘁𝘂𝗻𝗶𝗻𝗴 𝗸𝗶𝘁 you must know ↓
𝗗𝗮𝘁𝗮𝘀𝗲𝘁
The key component of any successful ML project is the data.
You need a 100 - 1000 sample Q&A (questions & answers) dataset with financial scenarios.
The best approach is to hire a bunch of experts to create it manually.
But, for a PoC, that might get expensive & slow.
The good news is that a method called "𝘍𝘪𝘯𝘦𝘵𝘶𝘯𝘪𝘯𝘨 𝘸𝘪𝘵𝘩 𝘥𝘪𝘴𝘵𝘪𝘭𝘭𝘢𝘵𝘪𝘰𝘯" exists.
In a nutshell, this is how it works: "Use a big & powerful LLM (e.g., GPT4) to generate your fine-tuning data. After, use this data to fine-tune a smaller model (e.g., Falcon 7B)."
For specializing smaller LLMs on specific use cases (e.g., financial advisors), this is an excellent method to kick off your project.
𝗣𝗿𝗲-𝘁𝗿𝗮𝗶𝗻𝗲𝗱 𝗼𝗽𝗲𝗻-𝘀𝗼𝘂𝗿𝗰𝗲 𝗟𝗟𝗠
You never want to start training your LLM from scratch (or rarely).
Why? Because you need trillions of tokens & millions of $$$ in compute power.
You want to fine-tune your LLM on your specific task.
The good news is that you can find a plethora of open-source LLMs on HuggingFace (e.g., Falcon, LLaMa, etc.)
𝗣𝗮𝗿𝗮𝗺𝗲𝘁𝗲𝗿 𝗲𝗳𝗳𝗶𝗰𝗶𝗲𝗻𝘁 𝗳𝗶𝗻𝗲-𝘁𝘂𝗻𝗶𝗻𝗴
As LLMs are big... duh...
... they don't fit on a single GPU.
As you want only to fine-tune the LLM, the community invented clever techniques that quantize the LLM (to fit on a single GPU) and fine-tune only a set of smaller adapters.
One popular approach is QLoRA, which can be implemented using HF's `𝘱𝘦𝘧𝘵` Python package.
𝗠𝗟𝗢𝗽𝘀
As you want your project to get to production, you have to integrate the following MLOps components:
- experiment tracker to monitor & compare your experiments
- model registry to version & share your models between the FTI pipelines
- prompts monitoring to debug & track complex chains
↳🔗 All of them are available on ML platforms, such as Comet ML
𝗖𝗼𝗺𝗽𝘂𝘁𝗲 𝗽𝗹𝗮𝘁𝗳𝗼𝗿𝗺
The most common approach is to train your LLM on your on-prem Nivida GPUs cluster or rent them on cloud providers such as AWS, Paperspace, etc.
But what if I told you that there is an easier way?
There is! It is called serverless.
For example, Beam is a GPU serverless provider that makes deploying your training pipeline as easy as decorating your Python function with `@𝘢𝘱𝘱.𝘳𝘶𝘯()`.
Along with ease of deployment, you can easily add your training code to your CI/CD to add the final piece of the MLOps puzzle, called CT (continuous training).
↳🔗 Beam

↳🔗 To see all these components in action, check out our FREE 𝗛𝗮𝗻𝗱𝘀-𝗼𝗻 𝗟𝗟𝗠𝘀 𝗰𝗼𝘂𝗿𝘀𝗲 & give it a ⭐
That’s it for today 👾
See you next Thursday at 9:00 a.m. CET.
Have a fantastic weekend!
…and see you next week for Lesson 7 of the Hands-On LLMs series 🔥
Paul
Whenever you’re ready, here is how I can help you:
The Full Stack 7-Steps MLOps Framework: a 7-lesson FREE course that will walk you step-by-step through how to design, implement, train, deploy, and monitor an ML batch system using MLOps good practices. It contains the source code + 2.5 hours of reading & video materials on Medium.
Machine Learning & MLOps Blog: in-depth topics about designing and productionizing ML systems using MLOps.
Machine Learning & MLOps Hub: a place where all my work is aggregated in one place (courses, articles, webinars, podcasts, etc.).