



DML: Why & when do you need to fine-tune open-source LLMs? What about fine-tuning vs. prompt engineering?
Lesson 5 | The Hands-on LLMs Series

Hello there, I am Paul Iusztin 👋🏼
Within this newsletter, I will help you decode complex topics about ML & MLOps one week at a time 🔥
Lesson 5 | The Hands-on LLMs Series
Table of Contents:
Using this Python package, you can x10 your text preprocessing pipeline development.
Why & when do you need to fine-tune open-source LLMs? What about fine-tuning vs. prompt engineering?
Fine-tuning video lessons
Previous Lessons:
↳🔗 Check out the Hands-on LLMs course and support it with a ⭐.
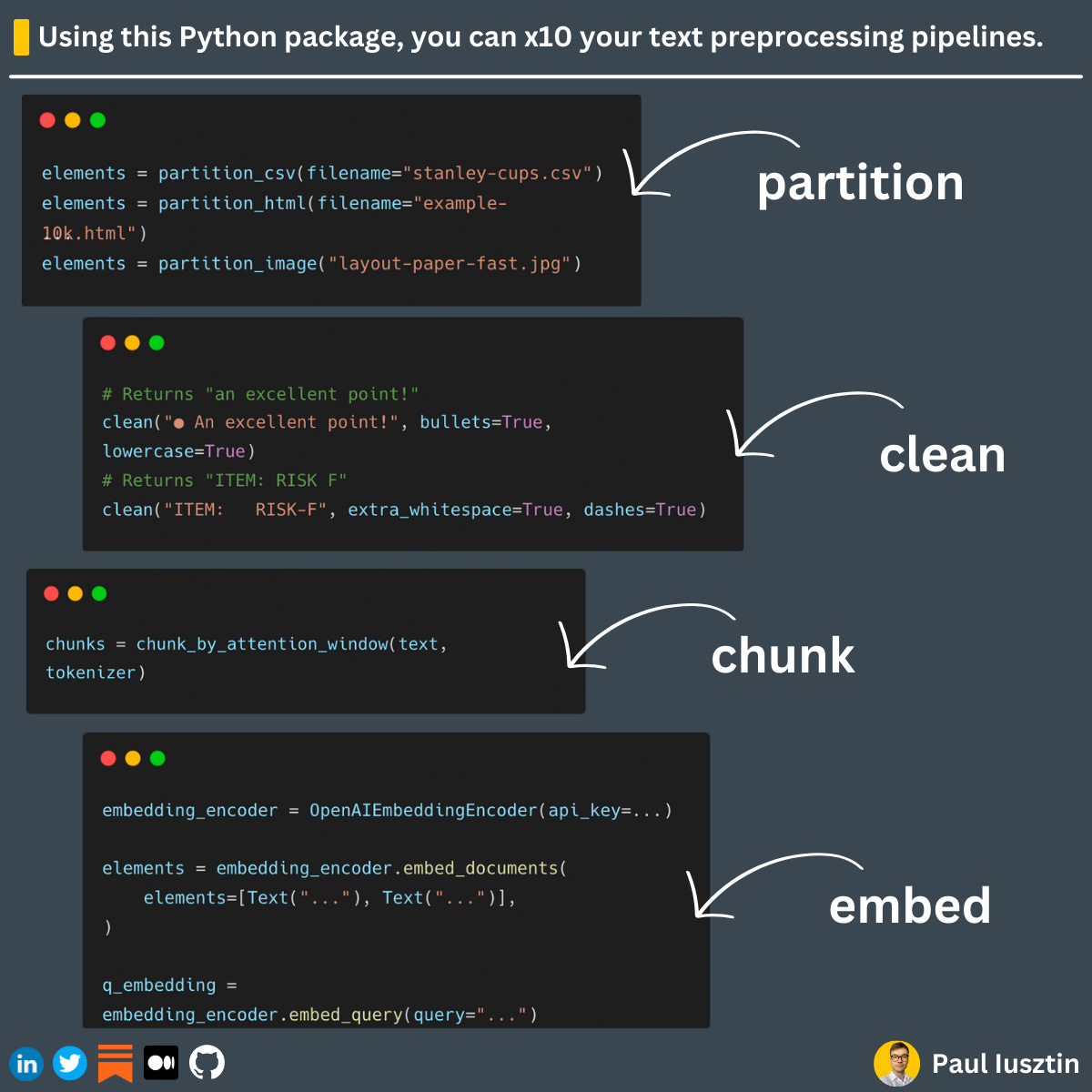
#1. Using this Python package, you can x10 your text preprocessing pipeline development
Any text preprocessing pipeline has to clean, partition, extract, or chunk text data to feed it into your LLMs.
𝘂𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲𝗱 offers a 𝗿𝗶𝗰𝗵 and 𝗰𝗹𝗲𝗮𝗻 𝗔𝗣𝗜 that allows you to quickly:
- 𝘱𝘢𝘳𝘵𝘪𝘵𝘪𝘰𝘯 your data into smaller segments from various data sources (e.g., HTML, CSV, PDFs, even images, etc.)
- 𝘤𝘭𝘦𝘢𝘯𝘪𝘯𝘨 the text of anomalies (e.g., wrong ASCII characters), any irrelevant information (e.g., white spaces, bullets, etc.), and filling missing values
- 𝘦𝘹𝘵𝘳𝘢𝘤𝘵𝘪𝘯𝘨 information from pieces of text (e.g., datetimes, addresses, IP addresses, etc.)
- 𝘤𝘩𝘶𝘯𝘬𝘪𝘯𝘨 your text segments into pieces of text that can be inserted into your embedding model
- 𝘦𝘮𝘣𝘦𝘥𝘥𝘪𝘯𝘨 data (e.g., wrapper over OpenAIEmbeddingEncoder, HuggingFaceEmbeddingEncoders, etc.)
- 𝘴𝘵𝘢𝘨𝘦 your data to be fed into various tools (e.g., Label Studio, Label Box, etc.)
𝗔𝗹𝗹 𝘁𝗵𝗲𝘀𝗲 𝘀𝘁𝗲𝗽𝘀 𝗮𝗿𝗲 𝗲𝘀𝘀𝗲𝗻𝘁𝗶𝗮𝗹 𝗳𝗼𝗿:
- feeding your data into your LLMs
- embedding the data and ingesting it into a vector DB
- doing RAG
- labeling
- recommender systems
... basically for any LLM or multimodal applications
.
Implementing all these steps from scratch will take a lot of time.
I know some Python packages already do this, but the functionality is scattered across multiple packages.
𝘂𝗻𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲𝗱 packages everything together under a nice, clean API.
↳ Check it out.
#2. Why & when do you need to fine-tune open-source LLMs? What about fine-tuning vs. prompt engineering?
Fine-tuning is the process of taking a pre-trained model and further refining it on a specific task.
𝗙𝗶𝗿𝘀𝘁, 𝗹𝗲𝘁'𝘀 𝗰𝗹𝗮𝗿𝗶𝗳𝘆 𝘄𝗵𝗮𝘁 𝗺𝗲𝘁𝗵𝗼𝗱𝘀 𝗼𝗳 𝗳𝗶𝗻𝗲-𝘁𝘂𝗻𝗶𝗻𝗴 𝗮𝗻 𝗼𝗽𝗲𝗻-𝘀𝗼𝘂𝗿𝗰𝗲 𝗟𝗟𝗠 𝗲𝘅𝗶𝘀t ↓
- 𝘊𝘰𝘯𝘵𝘪𝘯𝘶𝘦𝘥 𝘱𝘳𝘦-𝘵𝘳𝘢𝘪𝘯𝘪𝘯𝘨: utilize domain-specific data to apply the same pre-training process (next token prediction) on the pre-trained (base) model
- 𝘐𝘯𝘴𝘵𝘳𝘶𝘤𝘵𝘪𝘰𝘯 𝘧𝘪𝘯𝘦-𝘵𝘶𝘯𝘪𝘯𝘨: the pre-trained (base) model is fine-tuned on a Q&A dataset to learn to answer questions
- 𝘚𝘪𝘯𝘨𝘭𝘦-𝘵𝘢𝘴𝘬 𝘧𝘪𝘯𝘦-𝘵𝘶𝘯𝘪𝘯𝘨: the pre-trained model is refined for a specific task, such as toxicity detection, coding, medicine advice, etc.
- 𝘙𝘓𝘏𝘍: It requires collecting human preferences (e.g., pairwise comparisons), which are then used to train a reward model. The reward model is used to fine-tune the LLM via RL techniques such as PPO.
Common approaches are to take a pre-trained LLM (next-word prediction) and apply instruction & single-task fine-tuning.
𝗪𝗵𝘆 𝗱𝗼 𝘆𝗼𝘂 𝗻𝗲𝗲𝗱 𝘁𝗼 𝗳𝗶𝗻𝗲-𝘁𝘂𝗻𝗲 𝘁𝗵𝗲 𝗟𝗟𝗠?
You do instruction fine-tuning to make the LLM learn to answer your questions.
The exciting part is when you want to fine-tune your LLM on a single task.
Here is why ↓
𝘱𝘦𝘳𝘧𝘰𝘳𝘮𝘢𝘯𝘤𝘦: it will improve your LLM performance on given use cases (e.g., coding, extracting text, etc.). Mainly, the LLM will specialize in a given task (a specialist will always beat a generalist in its domain)
𝘤𝘰𝘯𝘵𝘳𝘰𝘭: you can refine how your model should behave on specific inputs and outputs, resulting in a more robust product
𝘮𝘰𝘥𝘶𝘭𝘢𝘳𝘪𝘻𝘢𝘵𝘪𝘰𝘯: you can create an army of smaller models, where each is specialized on a particular task, increasing the overall system's performance. Usually, when you fine-tune one task, it reduces the performance of the other tasks (known as the
alignment tax). Thus, having an expert system of multiple smaller models can improve the overall performance.
𝗪𝗵𝗮𝘁 𝗮𝗯𝗼𝘂𝘁 𝗽𝗿𝗼𝗺𝗽𝘁 𝗲𝗻𝗴𝗶𝗻𝗲𝗲𝗿𝗶𝗻𝗴 𝘃𝘀 𝗳𝗶𝗻𝗲-𝘁𝘂𝗻𝗶𝗻𝗴?
𝘥𝘢𝘵𝘢: use prompting when you don't have data available (~2 examples are enough). Fine-tuning needs at least >=100 examples to work.
𝘤𝘰𝘴𝘵: prompting forces you to write long & detailed prompts to achieve your level of performance. You pay per token (API or compute-wise). Thus, when a prompt gets bigger, your costs increase. But, when fine-tuning an LLM, you incorporate all that knowledge inside the model. Hence, you can use smaller prompts with similar performance.

When you start a project, a good strategy is to write a wrapper over an API (e.g., OpenAI's GPT-4, Anyscale, etc.) that defines a desired interface that can easily be swapped with your open-source implementation in future iterations.
↳🔗 Check out the Hands-on LLMs course to see this in action.
#3. Fine-tuning video lessons
As you might know,
from and I are also working on a free Hands-on LLMs course that contains the open-source code + a set of video lessons.Here are the 2 video lessons about fine-tuning ↓
01 Hands-on LLMS | Theoretical Part
Here is a 𝘴𝘶𝘮𝘮𝘢𝘳𝘺 of the 1𝘴𝘵 𝘷𝘪𝘥𝘦𝘰 𝘭𝘦𝘴𝘴𝘰𝘯 ↓
𝗪𝗵𝘆 𝗳𝗶𝗻𝗲-𝘁𝘂𝗻𝗲 𝗹𝗮𝗿𝗴𝗲 𝗹𝗮𝗻𝗴𝘂𝗮𝗴𝗲 𝗺𝗼𝗱𝗲𝗹𝘀?
1. 𝘗𝘦𝘳𝘧𝘰𝘳𝘮𝘢𝘯𝘤𝘦: Fine-tuning a large language model (LLM) can improve performance, especially for specialized tasks.
2. 𝘌𝘤𝘰𝘯𝘰𝘮𝘪𝘤𝘴: Fine-tuned models are smaller and thus cheaper to run. This is crucial, given that LLMs can have billions of parameters.
𝗪𝗵𝗮𝘁 𝗱𝗼 𝘆𝗼𝘂 𝗻𝗲𝗲𝗱 𝘁𝗼 𝗶𝗺𝗽𝗹𝗲𝗺𝗲𝗻𝘁 𝗮 𝗳𝗶𝗻𝗲-𝘁𝘂𝗻𝗶𝗻𝗴 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲?
1. 𝘋𝘢𝘵𝘢𝘴𝘦𝘵: You need a dataset of input-output examples. This dataset can be created manually or semi-automatically using existing LLMs like GPT-3.5.
2. 𝘉𝘢𝘴𝘦 𝘓𝘓𝘔: Choose an open-source LLM from repositories like Hugging Face's Model Hub (e.g., Falcon 7B)
3. 𝘍𝘪𝘯𝘦-𝘵𝘶𝘯𝘪𝘯𝘨 𝘴𝘤𝘳𝘪𝘱𝘵: Data loader + Trainer
4. 𝘈𝘥𝘷𝘢𝘯𝘤𝘦𝘥 𝘧𝘪𝘯𝘦-𝘵𝘶𝘯𝘪𝘯𝘨 𝘵𝘦𝘤𝘩𝘯𝘪𝘲𝘶𝘦𝘴 𝘵𝘰 𝘧𝘪𝘯𝘦-𝘵𝘶𝘯𝘦 𝘵𝘩𝘦 𝘮𝘰𝘥𝘦𝘭 𝘰𝘯 𝘤𝘩𝘦𝘢𝘱 𝘩𝘢𝘳𝘥𝘸𝘢𝘳𝘦: QLoRA
5. 𝘔𝘓𝘖𝘱𝘴: Experiment Tracker + Model Registry
6. 𝘐𝘯𝘧𝘳𝘢𝘴𝘵𝘳𝘶𝘤𝘵𝘶𝘳𝘦: Comet + Beam
02 Hands-on LLMS | Diving into the code
𝗛𝗲𝗿𝗲 𝗶𝘀 𝗮 𝘀𝗵𝗼𝗿𝘁 𝘄𝗮𝗹𝗸𝘁𝗵𝗿𝗼𝘂𝗴𝗵 𝗼𝗳 𝘁𝗵𝗲 𝗹𝗲𝘀𝘀𝗼𝗻 ↓
1. How to set up the code and environment using Poetry
2. How to configure Comet & Beam
3. How to start the training pipeline locally (if you have a CUDA-enabled GPU) or on Beam (for running your training pipeline on a serverless infrastructure -> doesn't matter what hardware you have).
4. An overview of the code
5. Clarifying why we integrated Poetry, a model registry and linting within the training pipeline.
❗This video is critical for everyone who wants to replicate the training pipeline of our course on their system. The previous lesson focused on the theoretical parts of the training pipeline.
↳🔗 To find out the code & all the videos, check out the Hands-on LLMs GitHub repository.
That’s it for today 👾
See you next Thursday at 9:00 a.m. CET.
Have a fantastic weekend!
…and see you next week for Lesson 6 of the Hands-On LLMs series 🔥
Paul
Whenever you’re ready, here is how I can help you:
The Full Stack 7-Steps MLOps Framework: a 7-lesson FREE course that will walk you step-by-step through how to design, implement, train, deploy, and monitor an ML batch system using MLOps good practices. It contains the source code + 2.5 hours of reading & video materials on Medium.
Machine Learning & MLOps Blog: in-depth topics about designing and productionizing ML systems using MLOps.
Machine Learning & MLOps Hub: a place where all my work is aggregated in one place (courses, articles, webinars, podcasts, etc.).