


This week’s topics:
The Real Challenges in Production-Ready Environment
System components for LLM evaluation
Composed summary metric
If you are wondering why I picked this title, consider the fact that I wrote this article on a Sunday, at 2 AM, and let’s just say, irony hits me sometimes!
That being said, let’s talk about how summarizing documents has become a deceptively simple job.
Just a call to OpenAI's API, and voilà – you have a summary.
? But what about when things get complex? What about when you have thousands of documents per day that your system must analyze and summarize?
A summary is not just a text that contains information about original documents, it’s an entire structure that must respect some constraints.
The biggest problem we are trying to tackle here is building a system ready to evaluate the summary task in a production-ready environment.
A system controlled by a Large Language Model(LLM) and doesn’t have a strong evaluation and validation is like a race car without a pilot.
Now you know, this is what we are going to discuss in today’s newsletter: summary tasks and how they can be solved using a private LLM like Llama2-7b or Mixtral-7b.
1. The Real Challenges in Production-Ready Environment
Deploying Large Language Models (LLMs) in a production environment presents a unique set of challenges that go beyond the capabilities of the models themselves. Consider these critical scenarios and their implications:
No Access to OpenAI API:
Many organizations rely on external APIs, such as OpenAI, for their language processing needs. However, what if access to these APIs is restricted due to cost, privacy concerns, or regulatory issues? - you can leave a comment!Alternative LLMs:
Private LLMs like Llama2-7b or Mixtral-7b may offer a solution to the dependency issue, but they come with their own set of challenges. Adapting these models to your specific needs requires a deep understanding of their architecture and capabilities. This process involves not only fine-tuning the models on domain-specific data but also ensuring they integrate seamlessly with your existing infrastructure.Context Window Limitations:
LLMs, by design, have limitations on the size of the input they can process (known as the 'context window').
When dealing with extensive documents or datasets, this limitation becomes a critical hurdle. Efficiently managing and summarizing such large volumes of data requires innovative strategies to break down the content into manageable parts without losing context or meaning.
Scalability and Performance:
As the volume of data increases, the system needs to scale accordingly. Ensuring consistent performance under varying loads is a significant challenge. This involves not just scaling the model's computational resources but also maintaining the quality of output and processing speed.
Quality of Summarization:
The ultimate goal of using an LLM in production is to produce high-quality, relevant summaries. However, ensuring the consistency and accuracy of these summaries is challenging. It requires continuous monitoring and fine-tuning of the model, along with robust validation and evaluation mechanisms to ensure the summaries meet the desired standards.
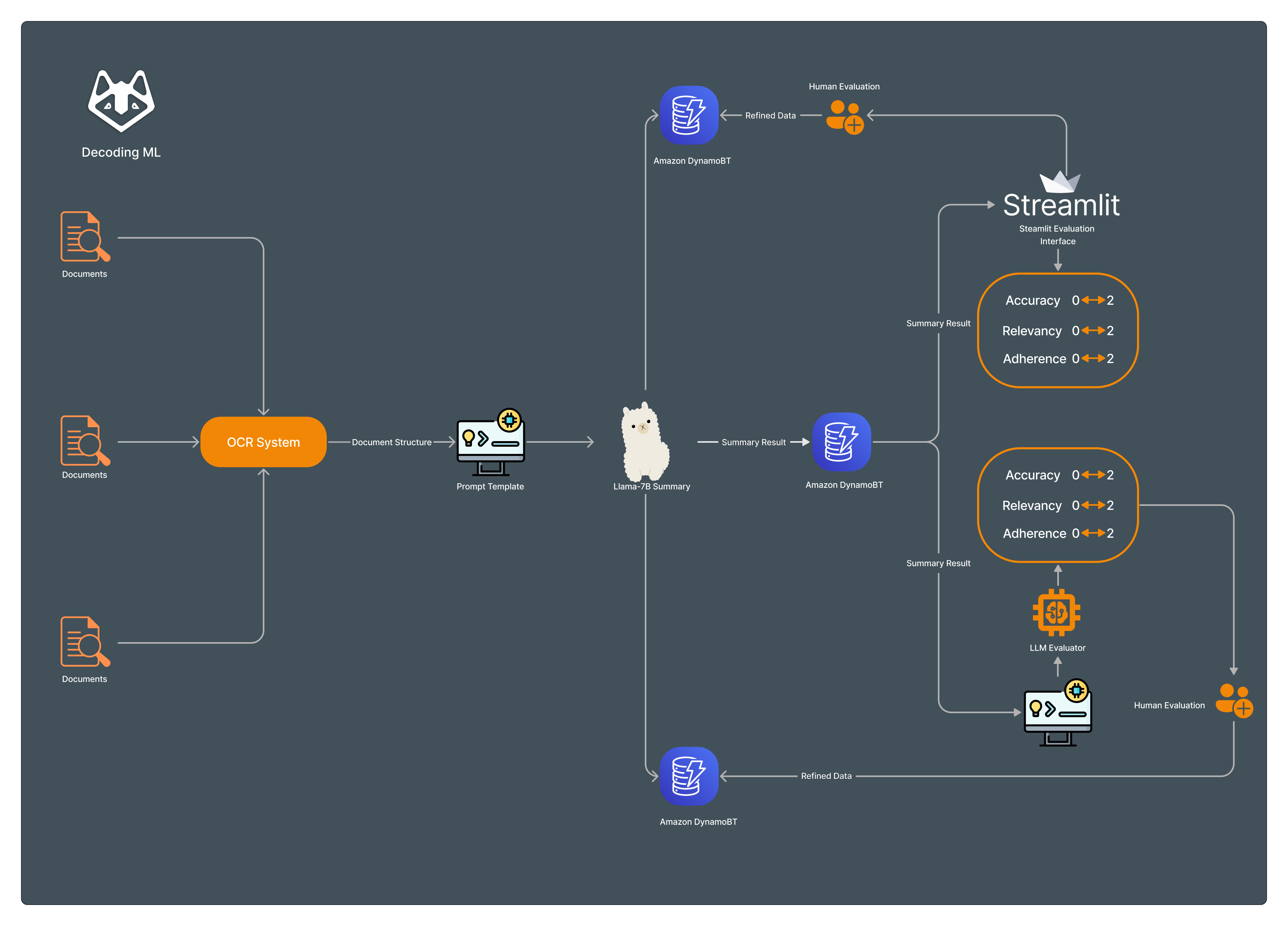
2. System components for LLM evaluation
A common pitfall in LLM-based summarization is the tendency to "hallucinate" – introducing non-existent information. So, how do we mitigate this?
Strategies for Ensuring Quality Summaries:
Prompt Techniques: Fine-tuning prompts to align with desired outputs.
From my personal experience, the CoT (Chain of Thoughts) prompt gives the best results when it comes to summary tasks.
SUMMARY_PROMPT_TEMPLATE:
Category: Detailed Analysis and Summarization
Focus: This template provides extensive guidelines for analyzing and summarizing legal or financial documents. It emphasizes:
Identifying document types and parties involved.
Stating the main purpose and context.
Detailing financial information.
Noting specific requests and legal or financial terms.
Strict adherence to the original text's content.
Avoiding the addition of new information and correcting inaccuracies.
SUMMARY_PROMPT_TEMPLATE = (
"Task: Analyze and summarize the provided legal or financial text enclosed within triple backticks. "
"Your summary should be concise, aiming for around 150 words, while capturing all essential aspects of the document. "
"Focus on the following key elements: "
"Think step by step:"
"1. Accurately identify the document's nature (e.g., legal letter, invoice, power of attorney) and the involved parties, including specific names, addresses, and roles (sender, recipient, debtor, creditor, etc.). "
"2. Clearly state the main purpose or subject matter of the document, including any legal or financial context (e.g., debt collection, contract details, claim settlement). "
"3. Provide exact financial details as mentioned in the document. This includes total amounts, itemized costs, interest rates, and any other monetary figures. Be precise in interpreting terms like 'percentage points above the base interest rate' and avoid misinterpretations. "
"4. If applicable, note any specific requests, deadlines, or instructions mentioned in the document (e.g., repayment plans, settlement offers). "
"5. Correctly interpret and include any relevant legal or financial terminology. "
"6. Identify and include any additional details that provide context or clarity to the document's purpose and contents, such as case numbers, invoice details, or specific legal references. "
"7. Avoid introducing information not present in the original text. Ensure your summary corrects any inaccuracies identified in previous evaluations and does not repeat them. "
"8.Recheck for step 7: do not introduce details there are not present in the original texts "
"Don't do assumption about some information.Focus only on original text"
"Text: {text} "
"SUMMARY:"
)This prompt template can be used with LangChain to build a Prompt Template and run the inference.
Summary Metrics: Metrics to evaluate summary quality.
A metric based on Accuracy, Relevance, and Adherence (more details in the next section).
LLM Evaluator: A larger LLM, Llama2-13B or Mixtral-13B instructed to evaluate the summaries based on Accuracy, Relevance, and Adherence.
Human Feedback: Integrating humans check for final validation.
A Streamlit evaluation interface connected to DynamoDB where the summaries generated by our Llama2-7B/Mixtral-7B are stored. Human evaluators can read the original document and analyze the generated summary.
The evaluation is made based on a composed metric(accuracy, relevancy, and adherence) with a score between 0-2.
3. Composed summary metric
In my professional journey, I've developed a composed summary metric focusing on three key aspects: Accuracy, Relevance, and Adherence.
🎯 Accuracy
Score 0: We avoid summaries with significant inaccuracies or misleading information.
Score 1: We aim to improve summaries that are not fully accurate for reliable information extraction.
Score 2: Our goal is to achieve highly accurate summaries that capture the main points with only minor inaccuracies that don't impede understanding.
🔍 Relevancy
Score 0: We discard summaries that are completely irrelevant and lack meaningful information.
Score 1: We refine somewhat relevant summaries but miss some main themes of the document.
Score 2: We strive for highly relevant summaries, encapsulating all main themes with precision.
📐 Adherence
Score 0: We reject summaries that completely disregard the document's structure and content.
Score 1: We work on summaries with major adherence issues to reach a coherent structure.
Score 2: We aspire to create summaries that perfectly adhere to the document's structure, mirroring its logical flow with precision.
So, what have we learned today?
Exploring the Complexity of Summarizing Documents: Discussing the use of private LLMs like Llama2-7b or Mixtral-7b for summarizing large volumes of documents, highlighting the challenges beyond simple text extraction.
Challenges in Production-Ready Environments:
Addressing limited access to APIs such as OpenAI.
The challenges of adapting private LLMs to specific needs.
Ensuring consistent quality and accuracy in summarization.
System Components for LLM Evaluation:
Strategies to avoid "hallucinations" or inaccuracies in LLM-generated summaries.
Introduction of two prompt templates:
SUMMARY_PROMPT_TEMPLATE for detailed analysis.
SUMMARY_PROMPT_TEMPLATE_REFINED for streamlined structuring.
Both templates emphasize accuracy, focusing on original text content without assumptions.
Composed Summary Metric:
Introducing a new metric system based on three aspects: Accuracy, Relevance, and Adherence, each graded on a scale of 0 to 2.
The aim is to enhance the reliability and quality of LLM-generated summaries.
LLM Evaluator and Human Feedback Integration:
Using a larger LLM for evaluation.
Incorporating human feedback for final validation.
Utilizing a Streamlit interface connected to DynamoDB for storing and evaluating summaries.
Congrats on making it to the FINAL!
We hope this article was helpful for you and your LLMs Discovery process.
Don’t hesitate to share your thoughts - we would love to hear them.
See you next Thursday at 9 AM CET.
Remember, when ML looks encoded - we’ll help you decode it.
Have a fantastic week!
Hey 👋 thanks for sharing!
I have two questions:
- can you please explain in more details the workflow displayed in the diagram? Specifically, I would like to know how you combine the evaluation metrics provided by the evaluator LLM and the metrics provided by the user, and how data is updated in DynamoDB.
- i understand that context window is key, but how do you manage the summarization of a really really large document (say a 200 page document) that doesn’t fit in the context? do you split it into chunks and summarize it with a map reduce technique or do you another alternative ? I’ve tried map reduce, but it’s painfully slow. Anyway, curious to know 🙂.
Thanks !
Hey Thanks for sharing! i have similar question as Ahmed. How to summarize a 200 page document. i tried to split into chunks the output was 9 page but lot of noise was introduced and some sentences made no sense. Please advise. thanks