

Forget text-to-SQL: Use this natural query instead
Tabular semantic search engine on e-commerce using natural queries

Search has been around for a long time, but it still often gives us bad or irrelevant results on many popular websites. Things got even trickier with the rise of GenAI chatbots like ChatGPT. Thanks to Google, people who have mostly learned to use keywords now want to talk to search apps more naturally and expect them to get what they mean without using specific keywords.
As highlighted by Algolia's CTO, one of the leaders in search technology: "We observed twice as many keywords per search six months after the launch of ChatGPT.”
As illustrated in the image below, even developers at top retail brands face challenges meeting this need.
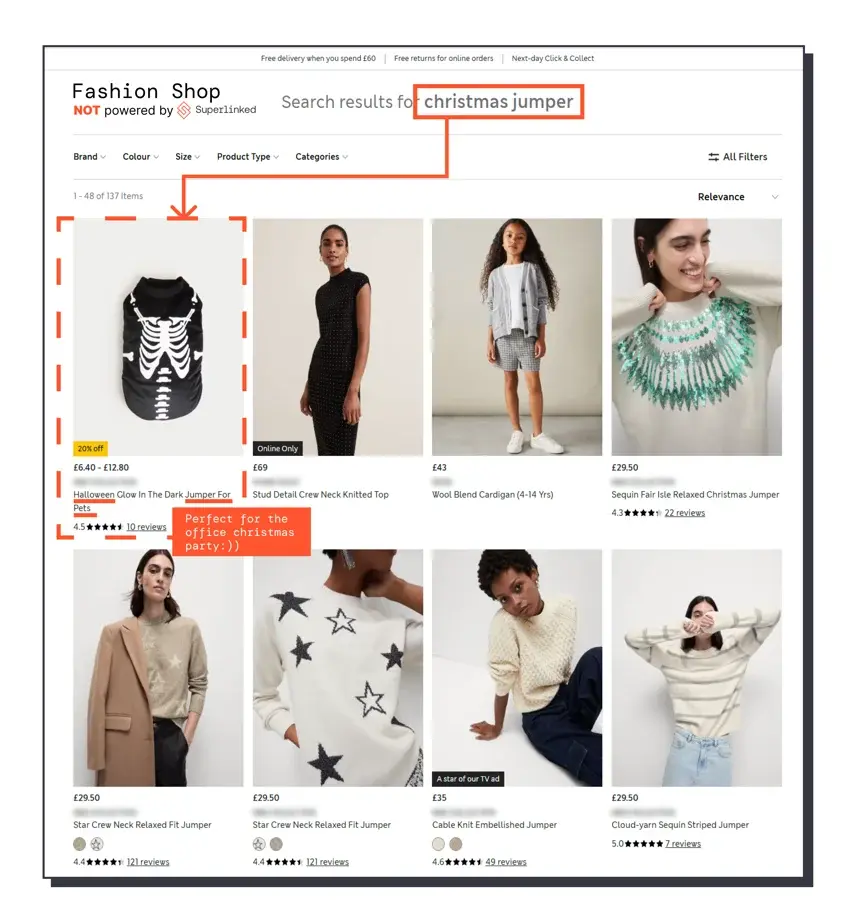
In this article, we will examine a method for modernizing search for the 21st century and demonstrate it by creating a tabular semantic search retrieval service for Amazon e-commerce products.
This service can further be used for plain search (which we will show in this article) or attached to an RAG or analytics application.
Instead of building a standard text or image semantic search application, we will show you how to do it for tabular data.
Instead of using text-to-SQL methods, we will leverage embeddings for all the product fields, whether text, floats, integers or categorical variables.
This approach is powerful, as text-to-SQL methods have demonstrated shortcomings in reliably generating complex SQL queries dependent on training data and other factors.
Building retrieval systems for unstructured data is fantastic, but unfortunately, many use cases require a tabular format, the most popular of which is “search.”
Other broad use cases are recommender systems, RAG and analytics.
In addition to that, almost every application has a combination of structured and unstructured data.
For example, along with finding products that have their description similar to your query (text), you can leverage their price (float), rating (float), number of reviews (int), or type (categorical) to increase the accuracy of your retrieval algorithm.
These are not rigid filters but embeddings that capture more nuances between the relationships of your data.
Directly stringifying and embedding floats or integers doesn’t keep the semantic relationship between numbers. Thus, we need more innovative ways to embed and index them.
The solution?
Using Superlinked and MongoDB vector search, we will build a multi-attribute search application on top of Amazon products. We will leverage natural queries that an LLM will decompose in tabular semantic queries and filters, as seen in Figure 1.
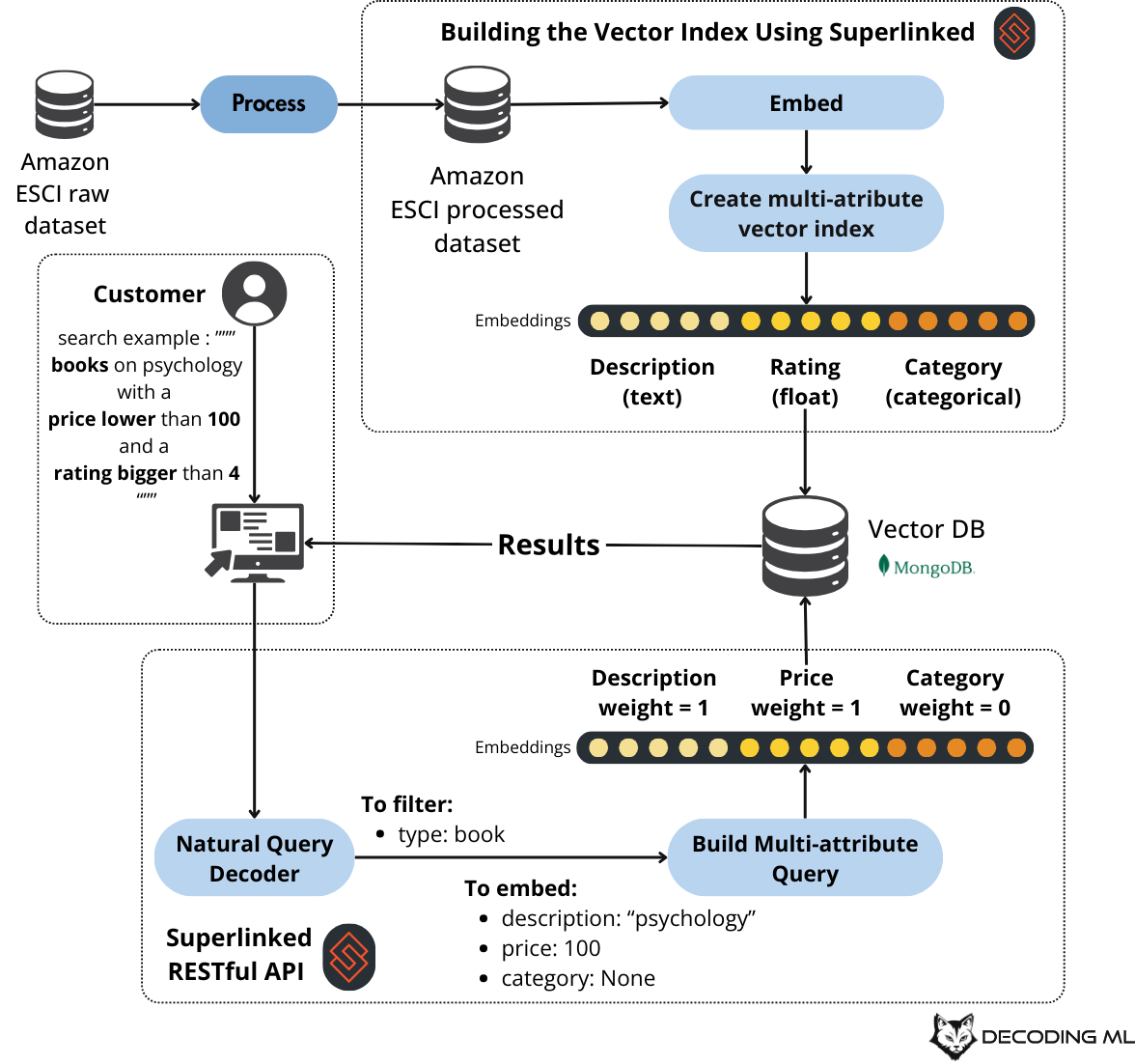
To conclude, in this article, you will learn to build an Amazon product search PoC (as seen in Figure 2), where you will:
Building semantic search for multi-attribute structured data (prices, ratings, categories) beyond just text.
Implement natural queries using LLMs and Superlinked that are automatically decoded in semantic queries and filters (no SQL code involved!).
Use MongoDB Atlas vector search as our vector database.
Wrap the retrieval code as a RESTful API.
Hook the RESTful API to a Streamlit app.
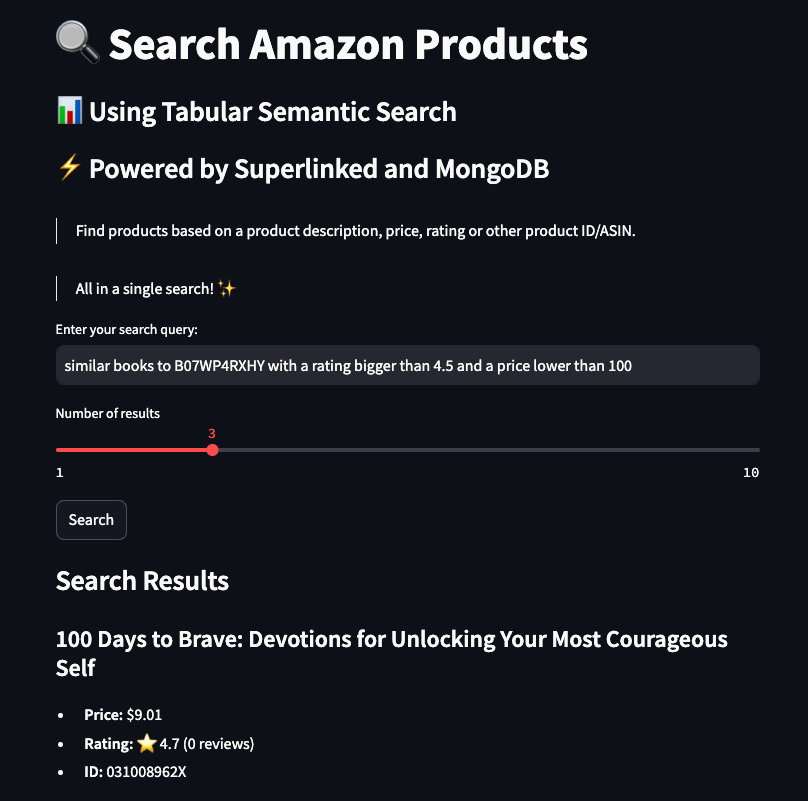
The complete code can freely be accessed on our GitHub [1].
Table of Contents:
Understanding why we used Superlinked
Exploring the Amazon dataset
Processing the Amazon dataset
Building the multi-attribute vector index using Superlinked
Implementing natural language queries using Superlinked
Deploying the retrieval microservice as a RESTful API
Why Mongo as our vector DB?
Running the Amazon product search PoC from a Streamlit UI
1. Understanding why we used Superlinked
The rapidly evolving landscape of search and information retrieval, mainly triggered by the GenAI/LLM revolution, is witnessing a fundamental shift in how users interact with search systems.
Fuzzy keyword searches with filters are no longer enough!
While vector embeddings have revolutionized search capabilities, they face notable limitations when handling complex queries, such as using multiple attributes, entities or types in a single query.
Consider these illustrative examples:
E-commerce: A query like "comfortable running shoes for marathon training under $150" involves text, numerical data (price), and categorical information (product type, use case).
Content platforms: "Popular science fiction movies from the 80s with strong female leads" combines text analysis, temporal data, and popularity metrics.
Job search: "Entry-level data science positions in tech startups with good work-life balance" requires an understanding of the text, categorical data (industry, job level), and even subjective metrics.
To address these evolving needs, Superlinked offers a comprehensive solution designed specifically for handling complex data structures. The framework serves as:
A versatile vector embedding, indexing, and query solution
A self-hostable REST API server
An intermediary layer between data sources, vector databases, and backend services
The framework's primary strength lies in its ability to construct custom data and query embedding models from pre-trained encoders, making it particularly valuable for:
RAG (Retrieval-Augmented Generation)
Advanced search implementations ← Our use case (tailored to e-commerce data)
Recommendation systems
Analytics applications
What is even more beautiful is that Superlinked is open-source, released under the Apache-2 LICENSE, as seen on their GitHub.
With Superlinked, we will build our Amazon product search PoC that will:
Index multiple product attributes into a multi-attribute vector index loaded to MongoDB.
Use a single search phrase by leveraging natural queries using LLMs to decode them automatically in semantic search and filtering elements.
For example, when a customer searches for:
psychology books with a price lower than 100 and a rating bigger than 4It will automatically be decoded as:
semantic search elements: `description = psychology
`,filters: `type = book`
2. Exploring the Amazon dataset
To build our tabular semantic search PoC, we will use the Amazon ESCI dataset, which Amazon released under the Apache-2.0 license.
It is an e-commerce dataset on Amazon products.
The full dataset references ~1.8M unique products. We will work with a sample of 4400 products to make everything lighter, but the code is compatible with the whole dataset.
After keeping only the columns we are interested in, here is what the head of the raw dataset looks like:
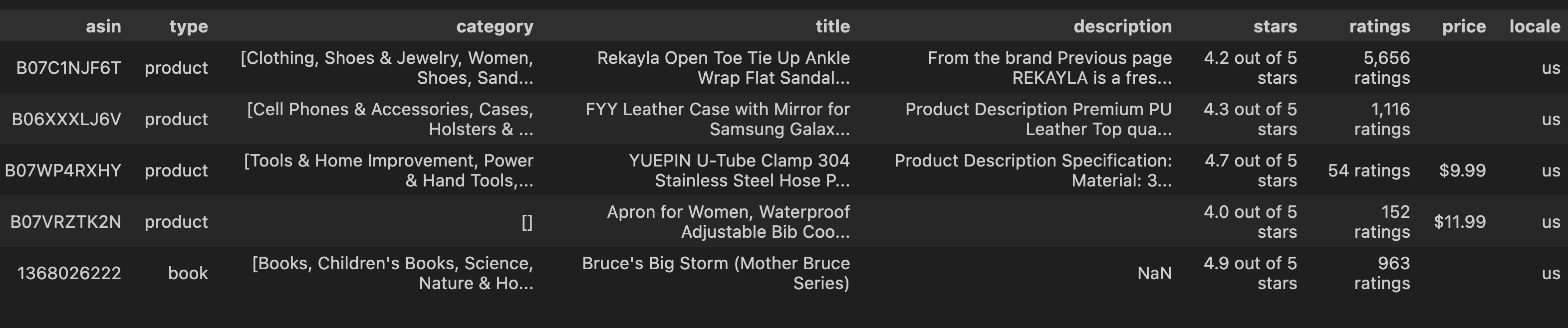
Here is a quick overview of each column:
asin - String/Object (product identifier, e.g., "B07C1NJ6T")
type - String/Object ("product" or "book")
category - List/Array of strings (hierarchical categories in brackets)
title - String/Object (product name)
description - String/Object (product description)
stars - String/Object (formatted as "X.X out of 5 stars")
ratings - String/Object (formatted as "X,XXX ratings")
price - String/Object or Float (when present, formatted with "$" prefix)
locale - String/Object (e.g., "us")
We will skip the data's exploratory data analysis (EDA) step to avoid making this article too long.
Still, if you are curious about the raw dataset, we have prepared a notebook that digs into it.
💻 Explore the dataset more deeply in our EDA notebook [1].
Also, you can read more about the dataset on the Amazon ESCI dataset [2] official page.
3. Processing the Amazon dataset
Before diving into the Superlinked application, we want to quickly review how we processed the dataset before loading it into the MongoDB vector database.
No chunking is needed!
Because we work with tabular data, we don’t have to chunk our data, as we will treat each table row as a different entry.
Even if we work with text data, the title or description of an Amazon product is relatively concise. Thus, we don’t have to chunk it.
For example, we could summarize each description to reduce noise, but we will keep it as is in our use case for simplicity.
But, similar to standard data science problems, we must:
fill in NaNs
clean columns in our desired format
remove outliers
For example, we want to transform the review count from a string to an int and replace NaNs with 0:
def parse_review_count(ratings: str) -> Optional[int]:
if pd.isna(ratings):
return 0
try:
# Remove commas and get first number
ratings_str = str(ratings).split()[0].replace(",.", "")
return int(ratings_str)
except (ValueError, IndexError):
return 0Similarly, we want to transform the rating from a string to a float and replace NaNs with -1:
def parse_review_rating(stars: str) -> Optional[float]:
if pd.isna(stars):
return -1.0
stars_str = str(stars).replace(",", ".") # Handle European number format
try:
return float(stars_str.split()[0])
except (ValueError, IndexError):
return -1.0Why -1 instead of NaN? When encoding floats into vectors, we want to reflect that the value is missing. By using a negative number instead of 0, the signal is stronger.
We did the same for the price and category.
In Figure 5, you can observe the processed Amazon dataset. We will take this stage of the data, embed it, and load it into a Mongo vector DB.

4. Building the multi-attribute vector index using Superlinked
Enough talking about the data. Let’s dive into building the multi-attribute vector index using Superlinked.
A quick intro into Superlinked’s components:
Describe your data using Python classes with the @schema decorator.
Describe your vector embeddings from building blocks with Spaces.
Combine your embeddings into a queryable Index.
Define your search with dynamic parameters and weights as a Query.
Load your data using a Source.
Define your transformations with a Parser (e.g., from
pd.DataFrame).Run your configuration with an Executor.
Let’s put these components into action. You will see how easy it is to build advanced retrieval services using Superlinked.
First, let's examine how we define our product data structure using Superlinked's schema system. The schema is a blueprint for our Amazon product data, ensuring type safety and providing a straightforward interface for our search implementation.
It’s similar to using Python data classes or Pyndantic.
from superlinked import framework as sl
from superlinked_app import constants
class ProductSchema(sl.Schema):
id: sl.IdField
type: sl.String
category: sl.StringList
title: sl.String
description: sl.String
review_rating: sl.Float
review_count: sl.Integer
price: sl.Float
product = ProductSchema()With our schema defined, we can create different similarity spaces to power our multi-attribute search. Each space represents a different aspect of our product data and how we want to search through it.
Each space will have its embedding, such as embedding the text description field using the `Alibaba-NLP/gte-large-en-v1.5` embedding model. Similar techniques are applied to the rest of the fields. Thus, each space can be queried independently or combined for more advanced solutions.

The beauty of Superlinked's approach is that it allows us to combine various types of data into a single vector index, such as:
categorical
text
numbers (floats and integers)
temporal (not used in our use case, but it’s supported)
category_space = sl.CategoricalSimilaritySpace(
category_input=product.category,
categories=constants.CATEGORIES,
uncategorized_as_category=True,
negative_filter=-1,
)
description_space = sl.TextSimilaritySpace(
text=product.description, model="Alibaba-NLP/gte-large-en-v1.5"
)
review_rating_maximizer_space = sl.NumberSpace(
number=product.review_rating, min_value=-1.0, max_value=5.0, mode=sl.Mode.MAXIMUM
)
price_minimizer_space = sl.NumberSpace(
number=product.price, min_value=0.0, max_value=1000, mode=sl.Mode.MINIMUM
)Finally, we bring everything together by creating our product index. This index combines all our similarity spaces and specifies which fields we want to include in our search results.
Notice how we're optimizing for both high ratings and low prices while maintaining the ability to search by category and description.
product_index = sl.Index(
spaces=[
category_space,
description_space,
review_rating_maximizer_space,
price_minimizer_space,
],
fields=[product.type, product.category, product.review_rating, product.price],
)This implementation allows us to handle complex queries that combine text similarity (through the description), categorical matching (through product categories), and numerical optimization (maximizing ratings while minimizing prices).
5. Implementing natural language queries using Superlinked
In the previous section, we defined the multi-attribute vector index, describing how to query our Amazon products.
In addition to the index, we must explicitly implement various queries, leveraging Superlinked’s multi-attribute approach and natural query decoder.

The foundation of our search system begins with configuring the OpenAI client, which will power our natural language understanding capabilities. This setup ensures that our search system can interpret complex user queries in a human-like manner.
from superlinked import framework as sl
from superlinked_app import constants, index
from superlinked_app.config import settings
openai_config = sl.OpenAIClientConfig(
api_key=settings.OPENAI_API_KEY.get_secret_value(), model=settings.OPENAI_MODEL_ID
)Next, we define the semantic parameters to help decode natural language queries into structured search components, as seen in Figure 7.
category_similar_param = sl.Param(
"query_category",
description=(
"The text in the user's query that is used to search in the products' description."
" Extract info that does not apply to other spaces or params."
),
options=constants.CATEGORIES,
)
text_similar_param = sl.Param(
"query_description",
description=(
"The text in the user's query that is used to search in the products' description."
" Extract info that does not apply to other spaces or params."
),
)
price_param = sl.Param(
"query_price",
description=(
"The text in the user's query that is used to search based on the products price."
" Extract info that does not apply to other spaces or params."
),
)
review_rating_param = sl.Param(
"query_review_rating",
description=(
"The text in the user's query that is used to search based on the products review rating."
" Extract info that does not apply to other spaces or params."
),
)The heart of our search system lies in the base query configuration. This foundational query structure establishes the weighted relationships between different search spaces - description, review ratings, and price - allowing for a nuanced balance in search results:
base_query = (
sl.Query(
index.product_index,
weights={
index.description_space: sl.Param("description_weight"),
index.review_rating_maximizer_space: sl.Param("review_rating_maximizer_weight"),
index.price_minimizer_space: sl.Param("price_minimizer_weights"),
},
)
.find(index.product)
.limit(sl.Param("limit"))
.with_natural_query(sl.Param("natural_query"), openai_config)
.filter(
index.product.type == sl.Param("filter_by_type", options=constants.TYPES)
)
)Building upon this foundation, we create two specialized query variants:
Filter-focused query
Semantic-focused query
Filter-focused query
The filter-focused query combines semantic search with traditional filtering capabilities:
filter_query = (
base_query.similar(
index.description_space,
text_similar_param,
sl.Param("description_similar_clause_weight"),
)
.filter(
index.product.category == sl.Param("filter_by_cateogry", options=constants.CATEGORIES)
)
.filter(index.product.review_rating >= sl.Param("review_rating_bigger_than"))
.filter(index.product.price <= sl.Param("price_smaller_than"))
)Let’s query our vector DB populated with Amazon products using the filter_query:
results = app.query(
query.filter_query,
natural_query="books with a price lower than 100 and a rating bigger than 4",
limit=3,
)Leveraging Superlinked’s natural query feature, the “books with a price lower than 100 and a rating bigger than 4” query is automatically decoded to:
{'description_weight': 1.0,
'review_rating_maximizer_weight': 0.0,
'price_minimizer_weights': 0.0,
'limit': 3,
'natural_query': 'books with a price lower than 100 and a rating bigger than 4',
'filter_by_type': 'book',
'query_description': 'books',
'filter_by_cateogry': None,
'review_rating_bigger_than': 4.0,
'price_smaller_than': 100.0,
'radius_param': None,
'space_weight_CategoricalSimilaritySpace_7675648664809431098_param': 0.0,
'description_similar_clause_weight': 1.0}The `description_weight`, `review_rating_maximizer_weight` and `price_minimizer_weights` show the weight we attribute to each element of the multi-attribute vector index.
In this case, as we leverage filters for the rating and price, the semantic search functionality is turned off for them.
Meanwhile, note how the `natural_query` was automatically decoded in:
`filter_by_type`: `book`
`query_description`: `book`
`review_rating_bigger_than`: 4.0
`price_smaller_than`: 100
Beautiful!
Still, this is not what makes Superlinked special. This is similar to what happens in a text-to-SQL setup, without the SQL syntax, as we do rigid filters into our query space.
Let’s see how this behaves when we unlock the semantic features of Superlinked.
Semantic-focused query
The second variant is our semantic query, which leverages the full power of vector spaces to understand and match complex search intentions across multiple attributes:
semantic_query = (
base_query.similar(
index.description_space,
text_similar_param,
sl.Param("description_similar_clause_weight"),
)
.similar(
index.price_minimizer_space,
price_param,
sl.Param("price_similar_clause_weight"),
)
.similar(
index.review_rating_maximizer_space,
review_rating_param,
sl.Param("review_rating_similar_clause_weight"),
)
)Let’s query our vector DB populated with Amazon products using the semantic_query:
results = app.query(
query.semantic_query,
natural_query="books with a price lower than 100 and a rating bigger than 4",
limit=3,
)Leveraging Superlinked’s natural query feature, the “books with a price lower than 100 and a rating bigger than 4” query is automatically decoded to:
{'description_weight': 0.0,
'review_rating_maximizer_weight': 1.0,
'price_minimizer_weights': 1.0,
'limit': 3,
'natural_query': 'books with a price lower than 100 and a rating bigger than 4',
'filter_by_type': 'book',
'query_description': '',
'query_price': 100.0,
'query_review_rating': 4.0,
'radius_param': None,
'space_weight_CategoricalSimilaritySpace_7675648664809431098_param': 0.0,
'description_similar_clause_weight': 0.0,
'price_similar_clause_weight': 1.0,
'review_rating_similar_clause_weight': 1.0}Notice how the `review_rating_maximizer_weight` and `price_minimizer_weights` weights parameters are now turned on, while the `query_price = 100` and `query_review_rating = 4.0`.
Instead of a binary filter, we are doing a semantic search for products with a price smaller than 100 (as we defined the price space as a minimizer) and a rating bigger than 4 (as we defined the rating space as a maximizer).
Ultimately, we can extend our semantic query to support finding similar items based on a specific product ID, enabling product recommendations and "more like this" functionality:
similar_items_query = semantic_query.with_vector(index.product, sl.Param("product_id"))Now, we can do something like the following:
results = app.query(
query.similar_items_query,
natural_query="similar books to B07WP4RXHY with a price lower than 100 and a rating bigger than 4",
limit=3,
)In addition to searching the price and rating space, we guide the query to look for similar items to the book with `ASIN = B07WP4RXHY`.
{'description_weight': 1.0,
'review_rating_maximizer_weight': 1.0,
'price_minimizer_weights': 1.0,
'limit': 3,
'natural_query': 'similar books to B07WP4RXHY with a price lower than 100 and a rating bigger than 4',
'filter_by_type': 'book',
'query_description': '',
'query_price': 100.0,
'query_review_rating': 4.0,
'product_id': 'B07WP4RXHY',
'radius_param': None,
'space_weight_CategoricalSimilaritySpace_-3191854600625402946_param': 1.0,
'description_similar_clause_weight': 1.0,
'price_similar_clause_weight': 1.0,
'review_rating_similar_clause_weight': 1.0,
'with_vector_id_weight_param': 1.0}This query architecture demonstrates the power of Superlinked's flexible query-building system. It allows us to combine traditional filtering with semantic search while maintaining fine-grained control over how different attributes influence the search results.
Benefits of assigning weights to embeddings
Because Superlinked permits you to assign weights when defining your queries, you can experiment and optimize without having to re-embed your dataset.
Assigning weights using dynamic parameters when you run the query offers the data scientist/user additional optimization control over what counts as relevant, even after the query definition.

Here are some excellent documents to investigate further how multi-attribute indexes [8] and Superlinked’s parametrized queries [7] work.
6. Deploying the retrieval microservice as a RESTful API
The last step is to hook our Superlinked index and queries to a:
DataLoader: This will populate the Mongo vector DB with Amazon products
RestExecutor: This exposes the Superlinked search microservice as a RESTful API
First, we set up our data sources. Superlinked offers flexibility in loading our product data through two distinct source types.
Define the real-time data loader (takes items one by one through HTTP requests):
import superlinked.framework as sl
from loguru import logger
from superlinked_app import index, query
from superlinked_app.config import settings
product_source: sl.RestSource = sl.RestSource(index.product)
Define the batch data loader (loads our static dataset):
product_data_loader_parser = sl.DataFrameParser(
schema=index.product, mapping={index.product.id: "asin"}
)
product_data_loader_config = sl.DataLoaderConfig(
str(settings.PROCESSED_DATASET_PATH),
sl.DataFormat.JSON,
pandas_read_kwargs={"lines": True, "chunksize": 100},
)
product_loader_source: sl.DataLoaderSource = sl.DataLoaderSource(
index.product,
data_loader_config=product_data_loader_config,
parser=product_data_loader_parser,
)The vector database configuration demonstrates Superlinked's adaptability to different deployment scenarios. For production environments, we can leverage MongoDB Atlas's vector search capabilities, while development and testing can utilize an in-memory solution:
if settings.USE_MONGO_VECTOR_DB:
vector_database = sl.MongoDBVectorDatabase(
settings.MONGO_CLUSTER_URL,
settings.MONGO_DATABASE_NAME,
settings.MONGO_CLUSTER_NAME,
settings.MONGO_PROJECT_ID,
settings.MONGO_API_PUBLIC_KEY,
settings.MONGO_API_PRIVATE_KEY,
)
else:
vector_database = vector_database = sl.InMemoryVectorDatabase()Finally, we bring everything together with the RestExecutor, orchestrating our entire search infrastructure. This component binds our data sources, indices, and query types into a cohesive system that can handle various search scenarios - from simple filtering to sophisticated semantic queries:
executor = sl.RestExecutor(
sources=[product_source, product_loader_source],
indices=[index.product_index],
queries=[
sl.RestQuery(sl.RestDescriptor("filter_query"), query.filter_query),
sl.RestQuery(sl.RestDescriptor("semantic_query"), query.semantic_query),
sl.RestQuery(
sl.RestDescriptor("similar_items_query"), query.similar_items_query
),
],
vector_database=vector_database,
)
sl.SuperlinkedRegistry.register(executor)Now, you can call the same queries through HTTP(s). Here is an example:
curl -X 'POST' \
'http://localhost:8080/api/v1/search/semantic_query' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{"natural_query": "books with a price lower than 100", "limit": 3}' | jq '.'For the final PoC, we will hook the RESTful API to a Streamlit UI and run everything end-to-end.
The complete code can freely be accessed on our GitHub [1].
7. Why Mongo as our vector DB?
MongoDB is a battle-tested product released 15 years ago. Thus, it’s a stable and robust database that has passed the test of time, being the #1 used modern database.
By nature, they are a NoSQL database that powers 52k+ applications from small to enterprise.
In late 2023, they released a vector search feature on their NoSQL database. As you have both a NoSQL and vector database integrated under the same technology, everything becomes simpler:
You can already leverage your existing MongoDB database.
Less infrastructure to maintain.
Data is automatically synchronized between the two.
Developers work with the same MongoDB query API and technology.
Enables powerful hybrid search capabilities, combining vector queries with their NoSQL features: documents or graphs.
Its distributed architecture scales vector search independently from the core database.
Everything translates to a smaller learning curve, less development time, infrastructure and overall maintenance.
Vector search is available on MongoDB Atlas, a fully managed platform that allows you to focus on your problem instead of infrastructure issues.
Along with that, MongoDB provides all the goodies that come with modern vector databases, such as:
Integration with LangChain, LlamaIndex, HayStack, AWS, etc.
Supporting embeddings up to 4096
Metadata filtering
HNSW indexing
Quantization
Using MongoDB as your vector DB is a safe bet for building AI applications.
Read more on MongoDB Atlas Vector Search and its optimization features.
8. Running the Amazon product search PoC from a Streamlit UI
So far, we have understood how the Superlinked app works. In just a few lines of code, we defined:
multi-attribute indexes;
natural language queries;
a RESTful API server;
a scalable connection to MongoDB’s vector database.
The ultimate step is to start the server, populate the Mongo vector DB with our Amazon products and hook it to Streamlit UI.
Running the Superlinked server
We will use Make to manage all our CLI commands.
Configure MongoDB Atlas vector search and OpenAI, as our GitHub docs explain.
Download and process the Amazon dataset:
make download-and-process-sample-datasetYou will find the raw and processed dataset under the `data` directory:
├── processed_100_sample.jsonl
├── processed_300_sample.jsonl
├── processed_850_sample.jsonl
├── sample.json
└── sample.json.gzStart the Superlinked RESTful API server:
make start-superlinked-serverDocs are available out of the box at `http://localhost:8080/docs/`, as illustrated in Figure 9.

Load the processed Amazon dataset into the Mongo vector database:
make load-dataThis command will run as an async job. It can take a while, as it has to embed and index your entire dataset.
Go to MongoDB Atlas, navigate to Clusters → Browse Collections → tabular-semantic-search to verify that your vector database was populated successfully, as seen in Figure 10.
Now we can query the Superlinked RESTful API doing standard HTTP(S) requests:
curl -X 'POST' \
'http://localhost:8080/api/v1/search/semantic_query' \
-H 'accept: application/json' \
-H 'Content-Type: application/json' \
-d '{"natural_query": "similar books to B07WP4RXHY with a rating bigger than 4.5 and a price lower than 100", "limit": 3}' | jq '.'More details on setting up and running the code on our GitHub documentation.
Hooking a Streamlit App to the RESTful API server
As this article is already long, we won’t go into the details of the Streamlit app.
But you can start the Streamlit app by running the following:
make start-uiWhich will be available at `http://localhost:8501/`, as seen in Figure 11.
We are far from good designers, but we hope this UI will let you quickly play around with multiple searches, tweaking different prices, ratings, descriptions and product IDs.
Still, there are a few key things to notice.
First, instead of using clunky filters along the search bar, everything is aggregated into a singular natural query.
Superlinked will decode your query into price, rating, and product ID using its natural query technique.
Secondly, the Streamlit app mostly makes an HTTP request to the RESTful API and lists the results as follows:
def make_semantic_query(query: str, limit: int = 3) -> dict | None:
url = "http://localhost:8080/api/v1/search/semantic_query"
headers = {"accept": "application/json", "Content-Type": "application/json"}
payload = {"natural_query": query, "limit": limit}
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status()
return response.json()
except requests.exceptions.RequestException as e:
st.error(f"Error making request: {str(e)}")
return NoneMore details on setting up and running the code on our GitHub documentation.
Future steps in productionizing the PoC
Now, we are one step away from productionizing our PoC.
We don’t do it in these series, but here are some suggestions on what you can do to ship the app in a scalable way:
Deploy the Superlinked RESTful API in a K8s cluster or AWS ECS.
Deploy the Streamlit app to Streamlit Cloud.
The MongoDB vector DB is already deployed to MongoDB Atlas 🚀
Conclusion
This article taught us how to build a multi-attribute vector index and quickly explained why it’s better than standard SQL (or text-to-SQL) queries.
Then, we’ve looked into leveraging natural language queries to decode a single query into a complex search operation containing multiple embeddings and filters.
Ultimately, we’ve looked into how to ship the Amazon search PoC leveraging the MongoDB Atlas vector database, the Superlinked RESTful API and Streamlit UI.
The complete code can freely be accessed on our GitHub [1].
The second article from the series will investigate how the Superlinked multi-attribute vector index works more profoundly and compare Superlinked’s tabular semantic search with text-to-SQL solutions:

If you have any questions, feel free to ask them in the comments section ↓
References
Literature
[1] Decodingml. (n.d.). GitHub - decodingml/information-retrieval-tutorials. GitHub. https://github.com/decodingml/information-retrieval-tutorials
[2] Shuttie. (n.d.). GitHub - shuttie/esci-s: Extra product metadata for the Amazon ESCI dataset. GitHub. https://github.com/shuttie/esci-s
[3] Superlinked. (n.d.-b). superlinked/notebook/feature/natural_language_querying.ipynb at main · superlinked/superlinked. GitHub.
[4] MongoDB Atlas Vector Search. (n.d.-b). MongoDB. https://www.mongodb.com/products/platform/atlas-vector-search
[5] Superlinked - the vector computer. (n.d.). https://superlinked.com/
[6] Combining multiple embeddings for better retrieval outcomes | Superlinked Docs. (n.d.). https://docs.superlinked.com/concepts/multiple-embeddings
[7] Dynamic Parameters/Query Time weights | Superlinked Docs. (n.d.). https://docs.superlinked.com/concepts/dynamic-parameters
[8] Multi-attribute search with vector embeddings | VectorHub by Superlinked. (n.d.). https://superlinked.com/vectorhub/articles/multi-attribute-semantic-search
Images
If not otherwise stated, all images are created by the author.
Sponsors
Thank our sponsors for supporting our work!


Very Helpful Article
Love it! Thank you for the detailed tutorial 🙌