

Instagram data mining using LLMs
Crawl Instagram posts and use LLMs to extract critical insights for business growth.

Hello. My name is Vlad, and I am a junior AI engineer at Cube Digital. I am super passionate about everything AI and video games.
We are in the golden age of automation, driven by the rapid advancement of LLMs. These models have revolutionized how we interact with data, transforming industries and unlocking countless applications by leveraging natural language processing.
In this article, I’ll explain how to instruct an LLM to parse social media noise and extract the most relevant information.
Specifically, we’ll focus on mining Instagram restaurant posts to gather valuable data such as special offers, discounts, and events and compile it into a sleek weekly report.
Additionally, I will demonstrate how to structure this data into formats like CSV or Excel for easy storage, querying, and filtering.

Table of Contents:
Data Crawling
Data Storage
Prompt Engineering
LLM Usage
Response Formatting
Putting Everything Together
The MLOps and GenAI event everyone is speaking about
🤔 Ever feel like you're missing out on MLOps and GenAI?
I am anti-FOMO, but one of the best ways to get exposed to **relevant** tech is through conferences.
Where you have the chance to meet new people who solve real-world problems.
No bull****.
But... The quality of the event is critical.
You want to be surrounded by value.
After some digging, I realized that the MLOps World and Generative AI World Conference is the right place to be.
It's an in-person event where you can learn about MLOps and GenAI.
.
Here are a few talks from the conference that caught my interest:
- "Everything you need to know about fine-tuning" by Maxime Labonne from Liquid
- "Optimizing AI/ML Workflows on Kubernetes: Advanced Techniques and Integration" by Anu Reddy from Google
- "Generative AI infrastructure at Lyft" Konstantin Gizdarski from Lyft
- "Scaling vector DB usage without breaking the bank: Quantization and adaptive retrieval" by Zain Hasan from Weaviate
+40 other talks and workshops from people working at companies leading the GenAI and MLOps space, such as Modal Labs, Hugging Face, Grammarly, Mistral AI, MongoDB, AutoGPT and Netflix.

The conference is hosted in Austin, Texas, starting on the 7th of Nov.
Consider buying a ticket — use my link to grab 15% off:
Back to our article ↓
1. Data Crawling
What is a Data Crawler? A data crawler, or web crawler, is an automated program or script that systematically browses the internet to collect and index data from websites.
In this case, we will use Instaloader, a Python library designed to handle the crawling process. Instaloader will provide us with all the information we need from a public Instagram profile, allowing us to extract and analyze the data efficiently.
We also use datetime to only extract the last 7 days’ worth of posts.
class InstagramCrawler:
def __init__(self, page_name: str, proxy=None):
self.page_name = page_name
self.loader = instaloader.Instaloader()
self._until = datetime.now()
self._since = self._until - timedelta(days=7)
def scrap(self) -> List[Dict[str, str | Any]]:
profile = instaloader.Profile.from_username(self.loader.context, self.page_name)
posts = takewhile(lambda p: p.date > self._since, dropwhile(lambda p: p.date > self._until, profile.get_posts()))
return [
{'content': post.caption, 'date': post.date, 'link': f"https://www.instagram.com/{self.page_name}"}
for post in posts
]This implementation might not work for everyone due to regional regulations governing web crawling. The method outlined was tested with a Romanian IP, so results may vary based on your location.
2. Data Storage
We also added a MongoDB database to deal with unstructured data. This way, we can store the entire content of the extracted posts without worrying too much about their particular structure:
from pymongo import MongoClient
from config import settings
class DatabaseConnection:
_client: MongoClient = None
@classmethod
def connect(cls):
if cls._client is None:
try:
cls._client = MongoClient(settings.MONGO_URI)
except ConnectionFailure as exc:
print(f'Exception while connecting to database: {exc}')
raise
@classmethod
def get_database(cls, name: str):
if cls._client is None:
cls.connect()
return cls._client[name]3. Prompt Engineering
Prompt engineering involves designing and refining prompts to effectively guide language models or AI systems.
It’s the process of crafting inputs that optimize the model’s output, ensuring accuracy, relevance, and coherence in responses based on the user’s needs. In essence, it’s about tweaking the input to maximize the quality of the output.
Our system prompts that are used for data mining
This is where the magic happens in our application. At this stage, we define the behavior of our LLM, instructing it on what information to look for and extract.
To avoid hallucinations, we employ a two-prompt approach, found in the templates.py file.
The first prompt extracts specific business-related information from social media posts, filtering out irrelevant content.
For example, restaurants often post about promotions, events, or new menu items alongside unrelated content like aesthetic photos or dish descriptions. This prompt aims to sift through the noise and capture only the critical business data.
The second prompt serves as a refinement step.
After the initial extraction, it ensures that the output is concise, correctly formatted, and free of unnecessary information. This final refinement reanalyzes the data, ensuring it aligns with the predefined structure for precise, organized results.
PROFILES_REPORT_TEMPLATE = (
"You're a Restaurnat specialist. Analyze social media posts from various restaurant pages and create a concise report extracting the following information:\n"
"1. Giveaways\n"
"2. Events (including dates)\n"
"3. Deals and discounts (e.g., price reductions, 1+1 offers)\n"
"4. New menu items\n"
"For each item, include:\n"
"- Restaurant page name"
"- Post link"
"- Restaurant location (city)\n"
"Only include information from the provided posts that fits these categories. Avoid descriptive posts about dishes unless they mention specific offers or discounts.\n"
"Posts to analyze: {input_var}"
)
PROFILES_TEMPLATE_REFINE = (
"You're a restaurant specialist who has generated a report on various restaurant social media posts.\n"
"Previous report: {raport}\n"
"This report needs to be more concise and follow a predefined structure:\n"
"1. Analyze your previous report.\n"
"2. Adapt the report to the following structure: {format_instructions}\n"
"If there's no relevant information for a key, leave it as an empty list\n."
"Your response should only contain the specified structure, without ```json ``` tags."
)4. LLM Usage
At this stage, minimal manual work is involved. The main focus is establishing a method for creating a conversational chain that enables smooth interactions between the user and the LLM.
Here, we set up all the necessary configurations related to the LLM, such as specifying the model name. We also inject any variables we might need into the prompt, such as posts extracted from the database, which we need for the PROFILES_REPORT_TEMPLATE prompt template.
To achieve this, we will use Langchain, a framework specifically designed to build applications around LLMs.
Langchain provides tools to manage prompts, connect LLMs to external data sources, handle operation chains, and seamlessly integrate models into applications like chatbots or question-answering systems, streamlining the development of AI-powered solutions.
from langchain.chains.llm import LLMChain
from langchain_core.prompts import PromptTemplate
def get_chain(llm, template: str, input_variables=None, verbose=True, output_key=""):
return LLMChain(
llm=llm,
prompt=PromptTemplate(
input_variables=input_variables, template=template, verbose=verbose
),
output_key=output_key,
verbose=verbose,
)5. Response Formatting
Generative AI often produces diverse responses, sometimes containing inaccuracies or lacking consistent structure. This inconsistency poses a problem when writing the data in structured formats like Excel or CSV, as errors can occur if the data doesn’t follow a predefined format.
To resolve this issue, we use Pydantic, a Python library that allows developers to define data models using classes. Pydantic ensures that the data adheres to specified types and constraints, automatically converts types, and provides detailed error messages if anything goes wrong.
In this application, we implement three Pydantic classes passed to the second prompt (mentioned earlier). These classes help format the LLM’s response into a structured output, ensuring it can be easily written to an Excel file or other structured formats without errors. This guarantees that the data meets the requirements for seamless integration into reports.
from pydantic import BaseModel, Field
class InformationProfiles(BaseModel):
name: str = Field(description='Name of the page from where the information was extracted')
information: str = Field(description='Information extracted for the specified key.')
link: str = Field(description='Link of the post from where the information was extracted.')
city: str = Field(description='City of the restaurant.')
class FieldProfiles(BaseModel):
name: str = Field(description='Name of the key. Available options are: Giveaways, Deals and Discounts, Events.')
keys: list[InformationProfiles] = Field(description='List of restaurants and the information given about them.')
class ReportProfiles(BaseModel):
name: str = Field(description='Name of the report: REPORT RESTAURANTS NEWS')
fields: list[FieldProfiles] = Field(description='List of all relevant keys for this report.')6. Putting Everything Together
Now, we bring everything together in our ReportGenerator class, ensuring a smooth flow from data extraction to report generation.
It manages the entire process, with the generate_report() method serving as the “entry point” to the application. Inside this method, all the steps required to produce a weekly report are executed.
from src.config import settings
from src.crawler import InstagramCrawler
from src.db import database
from src.llm import get_chain
from schemas import ReportProfiles
from templates import PROFILES_REPORT_TEMPLATE, PROFILES_TEMPLATE_REFINE
class ReportGenerator:
def __init__(self):
self.crawler = InstagramCrawler()
self.database = database
self.llm = ChatOpenAI(model_name=settings.OPENAI_MODEl, api_key=settings.OPENAI_API_KEY)
def crawl_and_store_posts(self):
...
def get_posts_from_db(self) -> List[Dict[str, Any]]:
...
return list(posts_collection.find({
'date': {'$gte': start_date, '$lte': end_date}
}))
@staticmethod
def get_posts_text(posts: List[Dict[str, Any]]) -> List[str]:
unique_posts = set()
...
return unique_posts
def create_report(self, posts: List[str]) -> str:
chain_1 = get_chain(
self.llm,
PROFILES_REPORT_TEMPLATE,
input_variables=["input_var"],
output_key="report",
)
result_1 = chain_1.invoke({"input_var": posts})
report = result_1["report"]
output_parser = PydanticOutputParser(pydantic_object=ReportProfiles)
format_output = {"format_instructions": output_parser.get_format_instructions()}
chain_2 = get_chain(
self.llm,
PROFILES_TEMPLATE_REFINE,
input_variables=["raport", "format_instructions"],
output_key="formatted_report",
)
result_2 = chain_2.invoke({"raport": report, "format_instructions": format_output})
return result_2["formatted_report"]
@staticmethod
def create_excel_file(data: Dict[str, Any]):
...
return buffer, excel_filename
def generate_report(self):
# Step 1: Crawl and store Instagram posts
posts_count = self.crawl_and_store_posts()
print(f"Crawled and stored {posts_count} posts.")
# Step 2: Retrieve posts from the database
db_posts = self.get_posts_from_db()
print(f"Retrieved {len(db_posts)} posts from the database.")
# Step 3: Process posts and create report
posts_text = self.get_posts_text(db_posts)
report_data_str = self.create_report(posts_text)
print(f"Generated report from posts: {report_data_str}")
# Parse the JSON string
try:
report_data = json.loads(report_data_str)
except json.JSONDecodeError:
print("Error: Unable to parse the report data as JSON.")
return None
# Step 4: Create Excel file
excel_buffer, excel_filename = self.create_excel_file(report_data)
# Step 5: Save Excel file
with open(excel_filename, 'wb') as f:
f.write(excel_buffer.getvalue())
return excel_filename
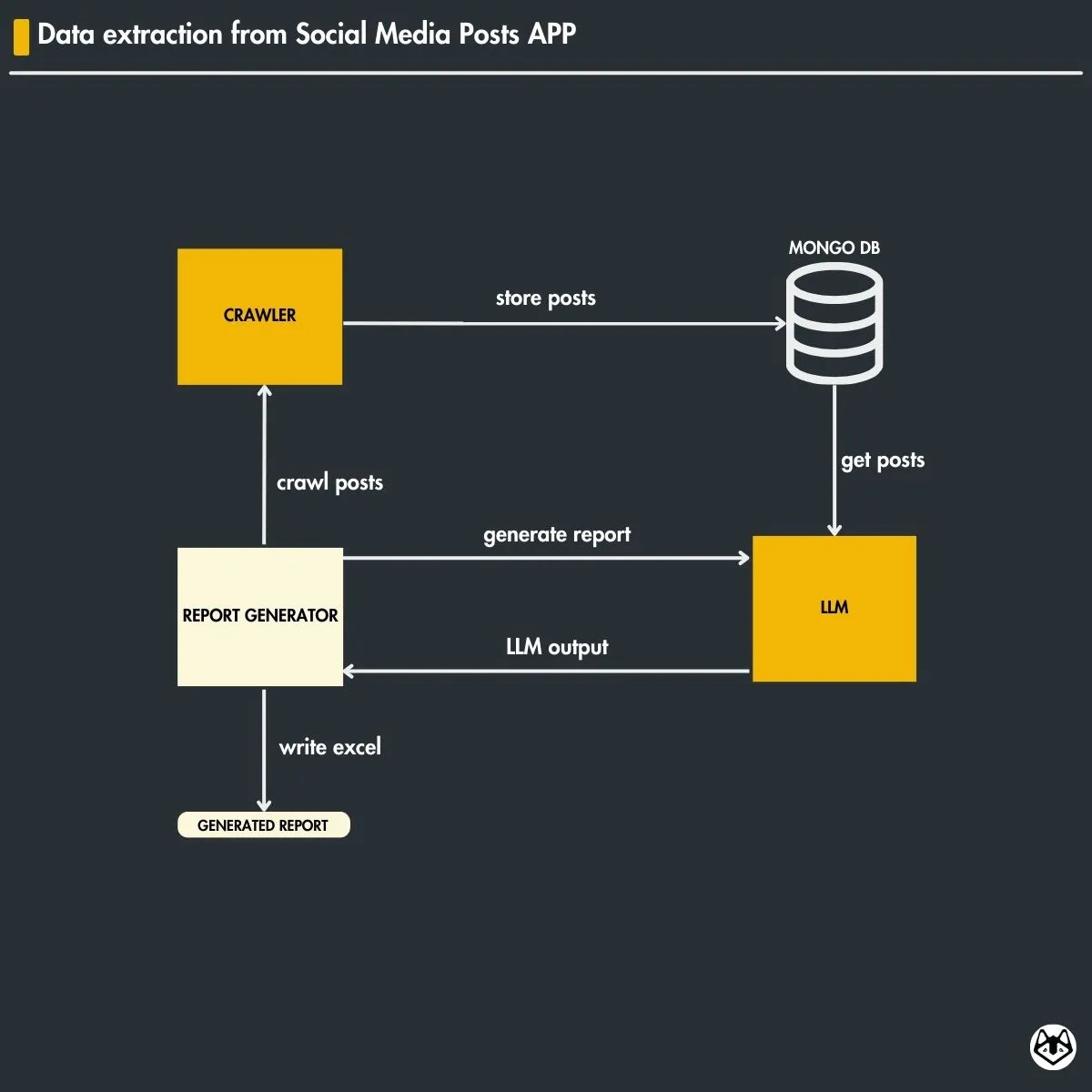
Here is a breakdown of the ReportGenerator class:
self.crawl_and_store_posts()
This method retrieves the posts from the selected Instagram profiles from the previous week and stores them in our database for further processing.
self.get_posts_from_db()
Here, we extract the posts stored in the database, applying a filter based on the date to ensure we retrieve only the posts from the last week, avoiding older stored posts.
self.get_posts_text() and self.create_report()
The first method extracts the text content from the stored posts to pass as input to the prompt. The second method uses the LLM to process this data and generate the weekly report.
self.create_excel_file()
This method takes the formatted report and writes it to an Excel file, ensuring it’s ready for easy access and review.
generate_report()
It glues all the steps together, such as crawling, storing them in the MongoDB database, and creating the report. It enables automatically generating a structured, data-driven weekly report using Instagram posts.
Key Takeaways
In this article, you learned how to use LLMs to data mine Instagram posts and extract valuable business-related data.
You can easily automate a time-consuming process by setting up a method to crawl Instagram posts, filter out irrelevant content using LLMs, and format the extracted information into structured reports.
You also gained insight into how to solve the problem of inconsistent responses from generative AI by using prompt engineering and tools like Pydantic. This ensures the data is neatly formatted and ready for use in Excel or CSV files.
Ultimately, you learned how to combine web crawling, data filtering, LLM prompts, and response formatting to create an efficient report generator that delivers structured, actionable insights from social media posts.
If you consider trying the code yourself, here is what you need:
Images
If not otherwise stated, all images are created by the author.
What about the context window? I mean how, will you handle 10000 posts?
I worked on a similar project about 9 months ago and encountered challenges with the Instaloader package due to Instagram's rate limits. My script got detected after roughly 200 requests. Have you found a workaround for this issue? I'd be interested in hearing about any solutions you've discovered.