

Mastering ML Configurations by leveraging OmegaConf and Hydra
If you’ve ever been tangled in the web of configurations for your ML projects - here's a solution!

The bigger the ML projects get - the harder it gets to keep it organized.
Juggling datasets, architectures, or various sets of hyperparameters you’ll feel like trying to keep a bunch of hyperactive cats in a basket.
That's where the magic of proper configuration management comes in.
Configuration files are present in every stage of your ML pipelines:
In Data Pipelines - stages, versions, and streaming sources.
In Training pipelines - model architectures, experiment tracking params, or hyper-parameters search conditions.
In Model Optimisation pipelines - precision, hardware targets (CPU/GPU/Edge), or model formats (ONNX, OpenVINO).
In Model Serving pipelines - API endpoints, inference engines, lineage parameters, and more.
Consider all of the above plus what you might have for your ML application code.
Managing complex configurations is a must-have rather than a nice-to-have.
Table of Contents:
What is OmegaConf?
How to leverage flexibility with Hydra
4 use cases for ML Engineers
1. What is OmegaConf?
As a hierarchical configuration system, think of OmegaConf as a Swiss Army knife for your project's settings.
It allows you to create, manipulate, and retrieve config data in a structured and clean manner.
Install via: pip install omegaconfHere are some highlights:
Hierarchy - define configurations in a tree-like structure.
Merging - combine configurations from multiple sources at runtime.
Type Safety - ensures that your configurations adhere to predefined types.
Obj Notation Access - accessing configuration values is as simple as using “x.y”
Support for Missing Values - define placeholders for missing values
Further, let’s go through some basic examples of what OmegaConf offers.
Config Merging
Basic files structure
my_awesome_llm/ │ ├── conf/ │ ├── dataset.yaml │ ├── model.yaml │ └── evaluation.yaml │ └── playground.pyDefining configuration files
# dataset.yaml dataset: name: "custom_dataset_v1.0" path: "/datasets/custom/v1.0" split: "test" preprocessing: - "remove_special_characters" - "lowercase"# model.yaml model: name: "meta-llama/Llama-2-7b" type: "transformer" task: "text-generation" temperature: 0.7 max_length: 512 top_p: 0.9 fine_tune: True# evaluation.yaml evaluation: metrics: - "diversity" - "fluency" diversity_measure: "distinct_ngrams" fluency_measure: "perplexity" sample_size: 100Loading configs with OmegaConf

How about type-checking?
OmegaConf supports type-checking and validation through structured configurations, which are Python classes decorated with @dataclass.
Enforcing type safety is particularly useful for maintaining the integrity of configurations in complex applications.
Considering the .yaml files from above, here’s the dataclass representation:
from dataclasses import dataclass, field
from typing import List, Union
@dataclass
class PreprocessingConfig:
steps: List[str] = field(default_factory=list)
@dataclass
class DatasetConfig:
name: str
path: str
split: str
preprocessing: PreprocessingConfig
@dataclass
class ModelConfig:
name: str
type: str
task: str
temperature: float
max_length: int
top_p: float
fine_tune: bool
@dataclass
class EvaluationConfig:
metrics: List[str]
diversity_measure: str
fluency_measure: str
sample_size: intNow we can load the configs and map them against our static-typed dataclasses to validate fields.
If there’s any mismatch between the .yaml and defined @dataclass, OmegaConf will yield ValidationErrors at runtime.

As an ML engineer, here are a few good use cases where type-checking your ML configurations might be recommended.
Hyperparameter Tuning
Values for batch size, learning rate, and number of layers or layer blocks must be of explicit type and within expected ranges to prevent runtime errors.
Model Configurations
Ensure the model configuration matches the expected structure and correct layer types.
Data Processing
When considering data pipelines, pre-processing, or post-processing steps one must ensure the correct data types and ranges for split ratios, channel format, and feature names.
Deployment Configurations
Ensure configurations for serving instances respect a specified format, number of replicas, IPs, memory limits, or timeout settings.
Further, let’s dive in and see how we can leverage the power of OmegaConf using Hydra.
2. Leverage flexibility with Hydra
Hydra is a tool built on top of OmegaConf and was designed for elegantly configuring applications.
It allows for handling multifaceted configuration scenarios, dynamic creation, and overriding of configurations at runtime.
Install via: pip install hydra-coreHere are some highlights:
Easy integration with CLI - override parameters when running from CLI.
Multi-run and sweeps - run multiple configuration files without code changes.
Config versioning - version configs via version_base parameter.
Now, let’s go through an example of using Hydra:
Defining config files
my_awesome_llm/ │ ├── conf/ │ ├── dataset.yaml │ ├── model.yaml │ └── evaluation.yaml │ └── config.yaml │ └── playground.pyAs you might observe, apart from the existing configs from above, we’ve added config.yaml.
Here’s the implementation:# config.yaml defaults: - dataset: dataset.yaml - model: model.yaml - evaluation: evaluation.yamlHere, we’ve mapped the .yaml files with custom keys, data ←→ dataset.yaml, model←→model.yaml and eval←→evaluation.yaml.
Using Hydra to load the config

Hydra Example
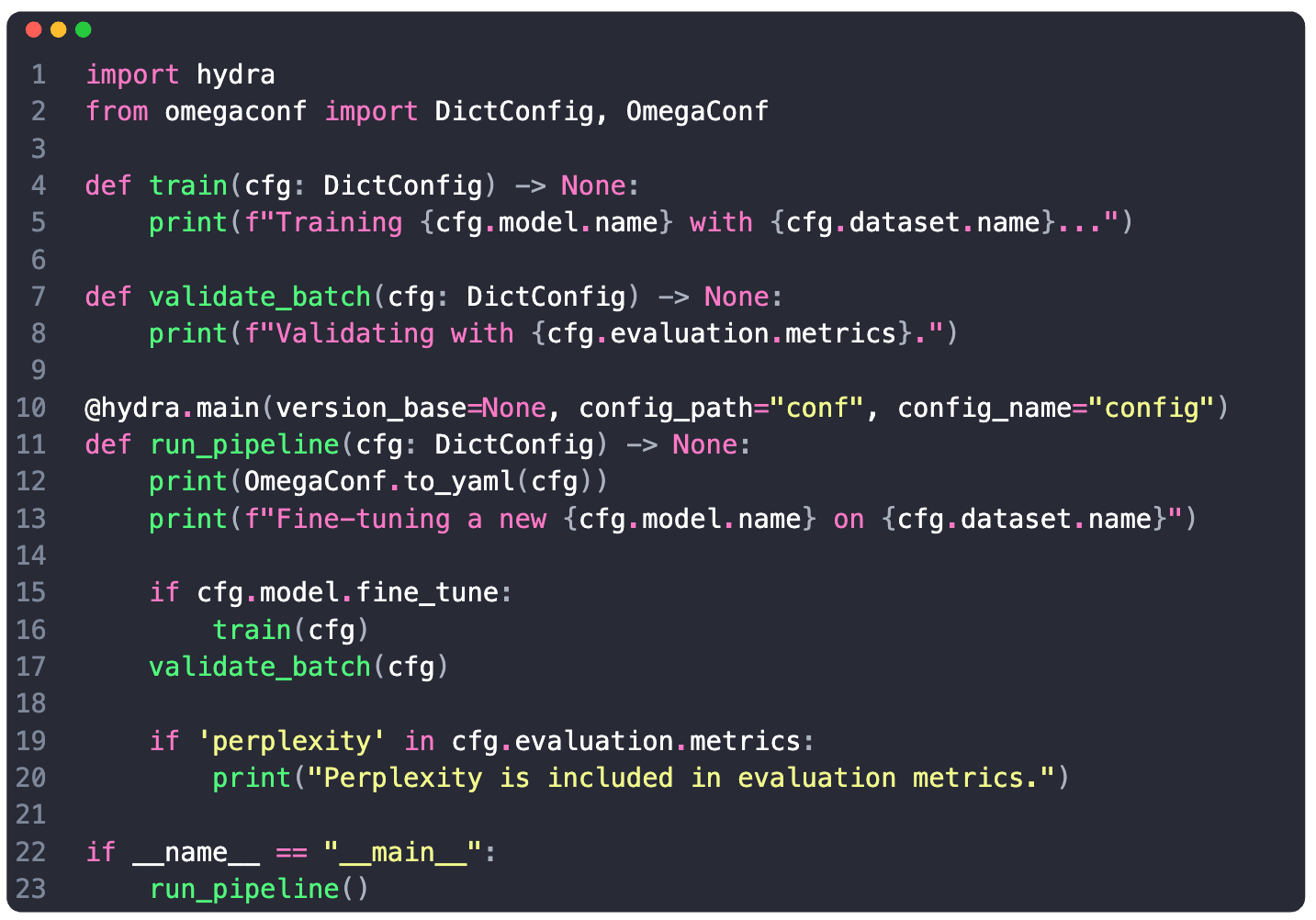
Once we’ve set the mappings (key to config) in config.yaml and then loaded this config with Hydra we get a merged configuration from which we can access sub-configs via point notation.
How about a multi-run?
Hydra has this cool feature of multi-runs, meaning one can pass a range of values for specific parameters within the configuration, and it handles the runs automatically.
Let’s assume we have a training script and we want to run multiple experiments, each with its dataset.
Here’s how to do it:
python train.py -m dataset.name=custom_v1.0,dataset_v1.5,filter_v1.0This will trigger and run the train.py and output this:
[2024-03-20 11:54:18,655][HYDRA] Launching 3 jobs locally
[2024-03-20 11:54:18,655][HYDRA] #0 : dataset.name=custom_v1.0
Training meta-llama/Llama-2-7b with custom_v1.0
Validating wit ['diversity', 'fluency']
[2024-03-20 11:54:18,693][HYDRA] #1 : dataset.name=dataset_v1.5
Training meta-llama/Llama-2-7b with dataset_v1.5
Validating wit ['diversity', 'fluency']
[2024-03-20 11:54:18,745][HYDRA] #2 : dataset.name=filter_v1.0
Training meta-llama/Llama-2-7b with filter_v1.0
Validating wit ['diversity', 'fluency']3. Real use cases for ML Engineers
Here are a few recommendations of when to employ the advantages of using OmegaConf and Hydra over other tools:
Multi-run for training jobs on different datasets or metrics
Hyperparameter tuning sweeps by specifying ranges
Cross-validation workflows
A/B testing separate model architectures
Ending Notes
We’ve learned to use OmegaConf to structure and organize configuration files for ML projects.
We’ve used Hydra to exemplify the flow by dynamically changing parameters from CLI and spawning multiple runs without altering the codebase.
These two add-ons for structuring your config files on your ML workflows should make a notable difference when your project grows in complexity. One big advantage for ML applications is that OmegaConf and Hydra offer a solid base for building, versioning, and managing various configuration use cases.