



ML Engineers, don't sleep on these tools!
Do you validate your data models correctly? Rust's speed and Python's flexibility in one single tool and the best way to handle complex configs in ML applications.

Decoding ML Notes
This week’s topics:
Use the full power of Pydantic to validate your data models!
A stream processor as Fast as RUST and as flexible as Python!
The Bonnie & Clyde of ML Configurations
Use the full power of Pydantic to validate your data models!
There have been multiple instances where I've had pipelines raise exceptions or crash silently due to edge cases when parsing payloads.
I used to do these validations poorly and repetitively until I started to use Pydantic to structure data and payload templates.
Let's consider a NewsArticle model I've used in one of my projects, to validate payloads from a real-time news streaming API, and let’s check what Pydantic offers in such a use-case:
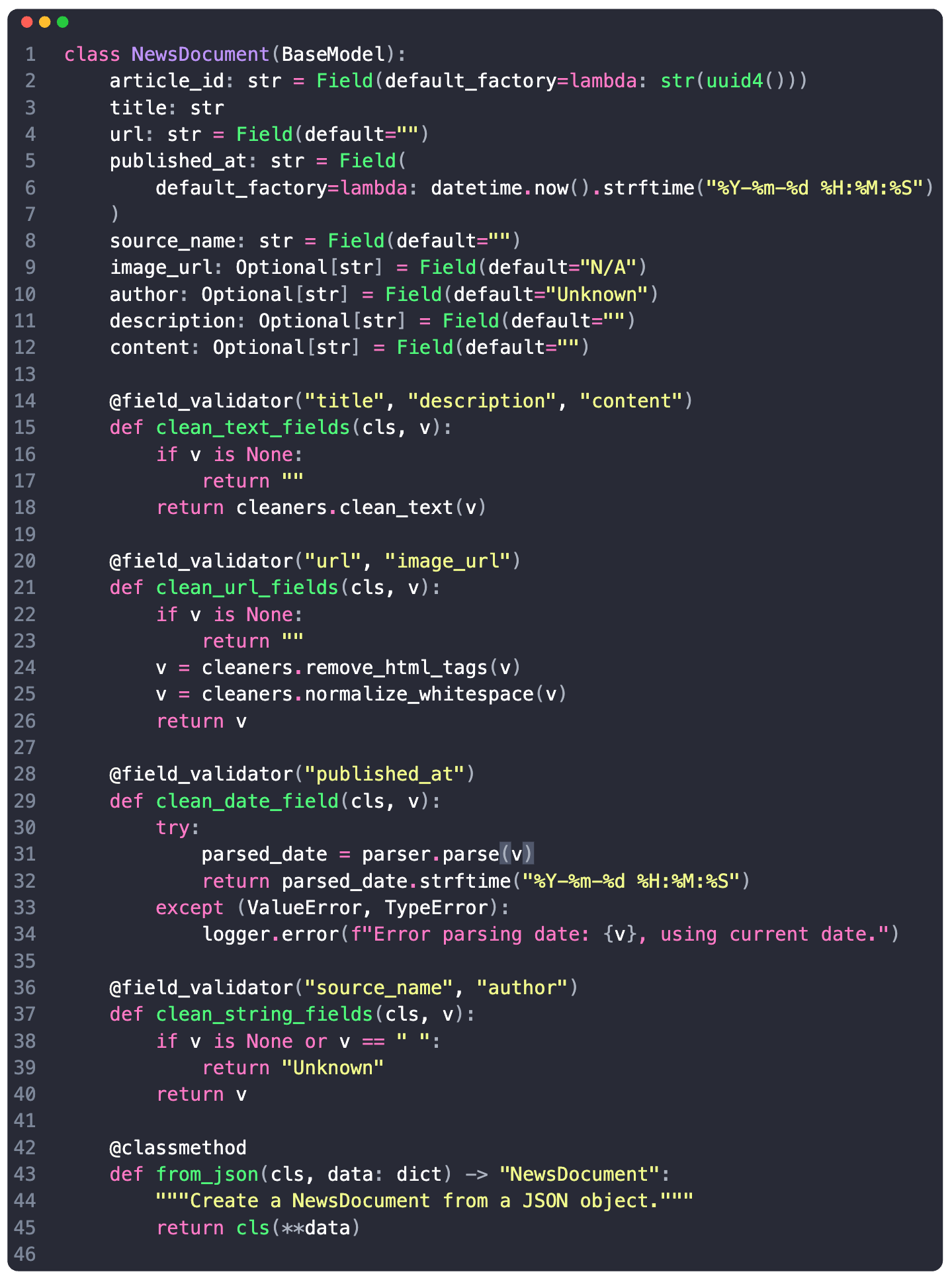
→ 𝗧𝘆𝗽𝗲 𝗦𝗮𝗳𝗲𝘁𝘆 𝗮𝗻𝗱 𝗔𝘂𝘁𝗼𝗺𝗮𝘁𝗶𝗰 𝗖𝗼𝗻𝘃𝗲𝗿𝘀𝗶𝗼𝗻
Pydantic ensures that the data conforms to expected types, performing automatic type conversion where possible. This is key in catching type-related errors early in the data pipeline.
→ 𝗖𝘂𝘀𝘁𝗼𝗺 𝗩𝗮𝗹𝗶𝗱𝗮𝘁𝗶𝗼𝗻 𝗟𝗼𝗴𝗶𝗰
One could add custom logic for field validation. In this example, fields needed different validation rules, and having custom cleaning methods targeting specific fields allows for generic parsing maintaining data quality and consistency.
→ 𝗦𝗶𝗺𝗽𝗹𝗶𝗳𝘆𝗶𝗻𝗴 𝗗𝗮𝘁𝗮 𝗣𝗮𝗿𝘀𝗶𝗻𝗴
Fields like publishedAt, which is a datetime type might require to be in a standardized format regardless of the input format.
→ 𝗙𝗹𝗲𝘅𝗶𝗯𝗶𝗹𝗶𝘁𝘆 𝗮𝗻𝗱 𝗘𝘅𝘁𝗲𝗻𝘀𝗶𝗯𝗶𝗹𝗶𝘁𝘆
Pydantic models can be easily extended with new fields or validation rules, making them highly adaptable to changing data requirements. BaseModel can be extended with class methods to serve as a bridge between different components of the data pipeline.
→ 𝗘𝗿𝗿𝗼𝗿 𝗛𝗮𝗻𝗱𝗹𝗶𝗻𝗴
One can log and handle errors gracefully, ensuring that data processing pipelines are robust and less prone to failure due to invalid data inputs.
Here’s why you should start using Python Pydantic:
• Type safety and automatic conversion prevent common type errors.
• Custom validators enforce data quality and consistency.
• Simplified data parsing for complex data types like dates.
• Flexibility to adapt to changing data requirements.
• Robust error-handling mechanisms for resilient data pipelines
A stream processor as Fast as RUST and as flexible as Python!

If you like honey, you’ll like this one - Bytewax!
Machine Learning, when done on siloed data is rarely of any use in a real-world project use case. To be able to develop accurate ML workflows, one requires continuous data on which the ML system can improve and adapt.
As a framework built on top of the Rust distributed processing engine and the flexibility of Python, Bytewax makes a considering difference as it simplifies any workflow where data can be distributed at the input and output.
I'm working mainly with vision/audio data, but I've had some use cases where I had to process data from streaming APIs on my professional/personal projects - and each time - I chose bytewax for that.
𝗛𝗲𝗿𝗲 𝗮𝗿𝗲 𝘀𝗼𝗺𝗲 𝗸𝗲𝘆 𝗱𝗲𝘁𝗮𝗶𝗹𝘀:
→ 𝗣𝘆𝘁𝗵𝗼𝗻𝗶𝗰 𝗘𝗮𝘀𝗲
Allows you to build and deploy dataflows with the familiarity of Python code.
→ 𝗕𝗹𝘂𝗲𝗽𝗿𝗶𝗻𝘁
Couples the stream and event processing capabilities of Flink, Spark, and Kafka Streams.
→ 𝗦𝘁𝗮𝘁𝗲𝗳𝘂𝗹 𝗦𝘁𝗿𝗲𝗮𝗺 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴
Allows you to maintain and manipulate state across data streams efficiently.
→ 𝗦𝗰𝗮𝗹𝗮𝗯𝗶𝗹𝗶𝘁𝘆
Allows you to distribute pipelines across multiple machines to handle large datasets without effort, thanks to the Timely Dataflow distributed computation system.
→ 𝗘𝘅𝘁𝗲𝗻𝘀𝗶𝗯𝗶𝗹𝗶𝘁𝘆
Not bound to any specific ecosystem, it allows you to connect to a diverse set of external systems or databases. Great for data-engineering workflows.
→ 𝗗𝗲𝗽𝗹𝗼𝘆𝗺𝗲𝗻𝘁
Local machine, cloud provider or k8s cluster - deploying is as straightforward as it can be. Using waxctl, one could easily set up a processing workflow on a k8s cluster.
→ 𝗢𝗽𝗲𝗿𝗮𝘁𝗼𝗿𝘀
Allows you to merge, join, and inspect data streams with ease at every step.
𝗛𝗲𝗿𝗲'𝘀 𝗮 𝗯𝗮𝘀𝗶𝗰 𝘄𝗼𝗿𝗸𝗳𝗹𝗼𝘄:
1. Define 2 input sources
2. Define processing steps for each stream
3. Merge streams
4. Inspect streams using `operators.inspect` at each stage
5. Define an output sink
The Bonnie & Clyde of ML Configurations
If you’ve ever been tangled in the web of configurations for your ML projects -
𝘆𝗼𝘂'𝗿𝗲 𝗻𝗼𝘁 𝗮𝗹𝗼𝗻𝗲.

Unlike conventional software engineering, 𝙈𝙇 𝙞𝙣𝙫𝙤𝙡𝙫𝙚𝙨 𝙧𝙚𝙥𝙚𝙩𝙞𝙩𝙞𝙫𝙚 𝙨𝙚𝙩𝙨 𝙤𝙛 𝙩𝙧𝙞𝙖𝙡𝙨 𝙖𝙣𝙙 𝙚𝙧𝙧𝙤𝙧𝙨, where each experiment builds on the last, gradually inching closer to the optimal solution. This unique detail of ML development underscores the necessity for flexible and easy management of complex configurations.
Here’s where OmegaConf and Hydra come into play:
Why use OmegaConf?
OmegaConf is a YAML-based hierarchical configuration system, making it versatile for managing settings.
𝙄𝙩 𝙨𝙪𝙥𝙥𝙤𝙧𝙩𝙨:
→ merging multiple configs from different sources (files, CLI argument, environment variables)
→ dynamic adjustments
→ enforcing types using dataclass structured representations
→ variable interpolation
𝗜𝗻𝘀𝘁𝗮𝗹𝗹: 𝘱𝘪𝘱 𝘪𝘯𝘴𝘵𝘢𝘭𝘭 𝘰𝘮𝘦𝘨𝘢𝘤𝘰𝘯𝘧
One straightforward use case here is having your Training and Hyperparameter Tuning flow in separate files, and merge them into a single config at runtime.
Why use Hydra?
Hydra is an open-source Python framework, built on top of OmegaConf, which takes configuration management to the next level in developing research and other complex applications.
𝙄𝙩 𝙨𝙪𝙥𝙥𝙤𝙧𝙩𝙨:
→ dynamic configuration generation
→ multi-run, one entry point - run with multiple configurations in parallel
→ overriding parameters with CLI arguments at runtime
→ dynamic object instantiation from the class name (e.g define the optimizer in yaml + its parameters and use Hydra to instantiate it directly)
𝗜𝗻𝘀𝘁𝗮𝗹𝗹: 𝘱𝘪𝘱 𝘪𝘯𝘴𝘵𝘢𝘭𝘭 𝘩𝘺𝘥𝘳𝘢-𝘤𝘰𝘳𝘦
One use case here would be starting multiple training experiments at once:
python train.py --multirun l_rate=[0.001, 0.1] batch_size=[4,32]Use these tools to:
merge multiple yaml configs into a single one
type-check configuration parameters
change parameters at runtime from CLI
organize configs in a tree-like structure
trigger multi-runs with different parameters, without changing the code