



ML serving 101: Core architectures
Choose the right architecture for your AI/ML app

In this article, you'll learn:
The 4 fundamental requirements for deploying ML models: throughput, latency, data, and infrastructure.
Balancing trade-offs between low latency and high throughput to optimize user experience.
The fundamentals of the 3 core ML serving architectures: online real-time inference, asynchronous inference, and offline batch transform
Key considerations for choosing between these ML serving methods.
Excited? Let’s go!
🤔 Criteria for choosing ML deployment types
The first step in deploying ML models is understanding the four requirements of every ML application: throughput, latency, data, and infrastructure.
Understanding them and their interaction is essential. When designing the deployment architecture for your models, there is always a trade-off between the four that will directly impact the user’s experience. For example, should your model deployment be optimized for low latency or high throughput?
Throughput and latency
Throughput refers to the number of inference requests a system can process in a given period. It is typically measured in requests per second (RPS). Throughput is crucial when deploying ML models when you expect to process many requests. It ensures the system can handle many requests efficiently without becoming a bottleneck.
High throughput often requires scalable and robust infrastructure, such as machines or clusters with multiple high-end GPUs.
Latency is the time it takes for a system to process a single inference request from when it is received until the result is returned. Latency is critical in real-time applications where quick response times are essential, such as in live user interactions, fraud detection, or any system requiring immediate feedback. For example, the average latency of OpenAI’s API is the average response time from when a user sends a request, and the service provides a result that is accessible within your application.
The latency is the sum of the network I/O, serialization and deserialization, and the LLM’s inference time. Meanwhile, the throughput is the average number of requests the API processes and serves a second.
Low-latency systems require optimized and often more costly infrastructure, such as faster processors, lower network latency, and possibly edge computing to reduce the distance data needs to travel.
A lower latency translates to higher throughput when the service processes one query simultaneously. For example, if the service takes 100 ms to process requests, this translates to a throughput of 10 requests per second. If the latency reaches 10 ms per request, the throughput rises to 100 requests per second.
However, to complicate things, most ML applications adopt a batching strategy to simultaneously pass multiple data samples to the model. In this case, a lower latency can translate into lower throughput; in other words, a higher latency maps to a higher throughput.
For example, if you process 20 batched requests in 100 ms, the latency is 100 ms, while the throughput is 200 requests per second. If you process 60 requests in 200 ms, the latency is 200 ms, while the throughput rises to 300 requests per second. Thus, even when batching requests at serving time, it’s essential to consider the minimum latency accepted for a good user experience.
Data
As we know, data is everywhere in an ML system. But when talking about model serving, we mostly care about the model’s input and output. This includes the format, volume, and complexity of the processed data. Data is the foundation of the inference process. The characteristics of the data, such as its size and type, determine how the system needs to be configured and optimized for efficient processing.
The type and size of the data directly impact latency and throughput, as more complex or extensive data can take longer to process.
For example, designing a model that takes input structured data and outputs a probability differs entirely from an LLM that takes input text (or even images) and outputs an array of characters.
Infrastructure
Infrastructure refers to the underlying hardware, software, networking, and system architecture that supports the deployment and operation of the ML models. The infrastructure provides the necessary resources for deploying, scaling, and maintaining ML models. It includes computing resources, memory, storage, networking components, and the software stack:
For high throughput, the systems require scalable infrastructure to manage large data volumes and high request rates, possibly through parallel processing, distributed systems, and high-end GPUs.
Infrastructure must be optimized to reduce processing time to achieve low latency, such as using faster CPUs, GPUs, or specialized hardware. While optimizing your system for low latency while batching your requests, you often have to sacrifice high throughput in favor of lower latency, resulting in your hardware not being utilized at total capacity. As you process fewer requests per second, it results in idle computing, which increases the overall cost of processing a request. Thus, picking the suitable machine for your requirements is critical in optimizing costs.
It is crucial to design infrastructure to meet specific data requirements. This includes selecting storage solutions for large datasets and implementing fast retrieval mechanisms to ensure efficient data access.
For example, we mostly care about optimizing throughput for offline training, while for online inference, we generally care about latency.
With this in mind, before picking a specific deployment type, you should ask yourself questions such as:
What are the throughput requirements? You should make this decision based on the throughput’s required minimum, average, and maximum statistics.
How many requests the system must handle simultaneously? (1, 10, 1k, 1 million, etc.)
What are the latency requirements? (1 millisecond, 10 milliseconds, 1 second, etc.)
How should the system scale? For example, we should look at the CPU workload, number of requests, queue size, data size, or a combination of them.
What are the cost requirements?
With what data do we work with? For example, do we work with images, text, or tabular data?
What is the size of the data we work with? (100 MB, 1 GB, 10 GB)
Deeply thinking about these questions directly impacts the user experience of your application, which ultimately makes the difference between a successful product and not. Even if you ship a mind-blowing model, if the user needs to wait too long for a response or it often crashes, the user will switch your production to something less accurate that works reliably.
For example, in a 2016 study, Google found that 53% of visits are abandoned if a mobile site takes longer than three seconds to load: https://www.thinkwithgoogle.com/consumer-insights/consumer-trends/mobile-site-load-time-statistics/.
Let’s move on to the three deployment architectures we can leverage to serve our models.
💪 Understanding inference deployment types
As illustrated in Figure 1, you can choose from three fundamental deployment types when serving models:
Online real-time inference
Asynchronous inference
Offline batch transform
When selecting one design over the other, there is a trade-off between latency, throughput, and costs. You must consider how the data is accessed and the infrastructure you are working with. Another criterion you have to consider is how the user will interact with the model.
For example, will the user use it directly, like a chatbot, or will it be hidden within your system, like a classifier that checks if an input (or output) is safe?
You have to consider the freshness of the predictions as well. For example, serving your model in offline batch mode might be easier to implement if, in your use case, it is OK to consume delayed predictions. Otherwise, you have to serve your model in real-time, which is more infrastructure-demanding. Also, you have to consider the traffic of your application.
Ask yourself questions such as, “Will the application be constantly used, or will there be spikes in traffic and then flatten out?”
With that in mind, let’s explore the three major ML deployment types.
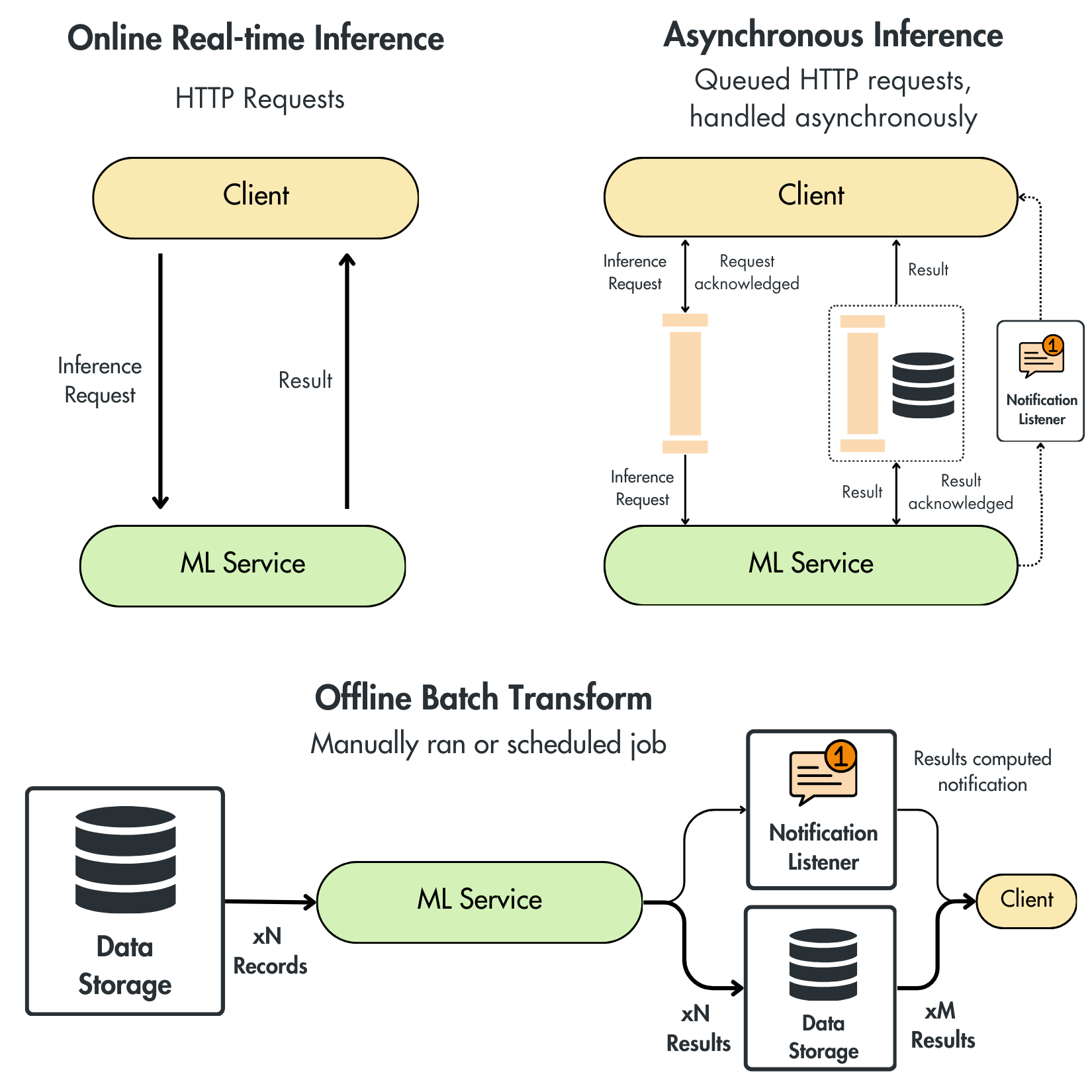
Online real-time inference
In real-time inference, we have a simple architecture based on a server that can be accessed through HTTP requests. The most popular options are to implement a REST API or gRPC server. The REST API is more accessible but slower, using JSON to pass data between the client and server. This approach is usually taken when serving models outside your internal network to the broader public. For example, OpenAI’s API implements a REST API protocol.
On the other hand, implementing a gRPC makes your ML server faster, though it may reduce its flexibility and general applicability. You have to implement protobuf schemas in your client application, which are more tedious to work with than JSON structures. The benefit, however, is that protobuf objects can be compiled into bites, making the network transfers much faster. Thus, this protocol is often adopted for internal services within the same ML system.
Using the real-time inference approach, the client sends an HTTP request to the ML service, which immediately processes the request and returns the result in the same response. This synchronous interaction means the client waits for the result before moving on.
To make this work efficiently, the infrastructure must support low-latency, highly responsive ML services, often deployed on fast, scalable servers. Load balancing is crucial to evenly distribute incoming traffic evenly, while autoscaling ensures the system can handle varying loads. High availability is also essential to keeping the service operational at all times.
For example, this architecture is often present when interacting with LLMs, as when sending a request to a chatbot or API (powered by LLMs), you expend the predictions right ahead. LLM services, such as ChatGPT or Claude, often use WebSockets to stream each token individually to the end user, making the interaction more responsive. Other famous examples are AI services such as embedding or reranking models used for retrieval-augmented generation (RAG) or online recommendation engines in platforms like TikTok.
The simplicity of real-time inference, with its direct client-server interaction, makes it an attractive option for applications that require immediate responses, like chatbots or real-time recommendations. However, this approach can be challenging to scale and may lead to underutilized resources during low-traffic periods.
Asynchronous inference
In asynchronous inference, the client sends a request to the ML service, which acknowledges the request and places it in a queue for processing. Unlike real-time inference, the client doesn’t wait for an immediate response. Instead, the ML service processes the request asynchronously. This requires a robust infrastructure that queues the messages to be processed by the ML service later on.
When the results are ready, you can leverage multiple techniques to send them to the client. For example, depending on the size of the result, you can put it either in a different queue or an object storage dedicated to storing the results. The client can either adopt a polling mechanism that checks on a schedule if there are new results or adopt a push strategy and implement a notification system to inform the client when the results are ready.
Asynchronous inference uses resources more efficiently. It doesn’t have to process all the requests simultaneously but can define a maximum number of machines that run in parallel to process the messages. This is possible because the requests are stored in the queue until a machine can process them. Another huge benefit is that it can handle spikes in requests without any timeouts.
For example, let’s assume that on an e-shop site, we usually have 10 requests per second handled by two machines. Because of a promotion, many people started to visit the site, and the number of requests spiked to 100 requests per second. Instead of scaling the number of virtual machines (VMs) by 10, which can add drastic costs, the requests are queued, and the same two VMs can process them in their rhythm without any failures.
Another popular advantage for asynchronous architectures is when the requested job takes significant time to complete. For example, if the job takes over five minutes, you don’t want to block the client waiting for a response.
While asynchronous inference offers significant benefits, it does come with trade-offs. It introduces higher latency, making it less suitable for time-sensitive applications. Additionally, it adds complexity to the implementation and infrastructure. Depending on your design choices, this architecture type falls somewhere between online and offline, offering a balance of benefits and trade-offs.
For example, this is a robust design where you don’t care too much about the latency of the inference but want to optimize costs heavily. Thus, it is a popular choice for problems such as extracting keywords from documents, summarizing them using LLMs, or running deep-fake models on top of videos.
But suppose you carefully design the autoscaling system to process the requests from the queue at decent speeds. In that case, you can leverage this design for other use cases, such as online recommendations for e-commerce. In the end, it sums up how much computing power you are willing to pay to meet the expectations of your application.
Offline batch transform
Batch transform is about processing large volumes of data simultaneously, either on a schedule or triggered manually. In a batch transform architecture, the ML service pulls data from a storage system, processes it in a single operation, and then stores the results in storage. The storage system can be implemented as an object storage like AWS S3 or a data warehouse like GCP BigQuery.
Unlike the asynchronous inference architecture, a batch transform design is optimized for high throughput with permissive latency requirements. When real-time predictions are unnecessary, this approach can significantly reduce costs, as processing data in big batches is the most economical method. Moreover, the batch transform architecture is the simplest way to serve a model, accelerating development time.
The client pulls the results directly from data storage, decoupling its interaction with the ML service. Taking this approach, the client never has to wait for the ML service to process its input, but at the same time, it doesn’t have the flexibility to ask for new results at any time.
You can see the data storage, where the results are stored as a large cache, from where the client can take what is required. If you want to make your application more responsive, the client can be notified when the processing is complete and can retrieve the results.
Unfortunately, this approach will always introduce a delay between the time the predictions were computed and consumed. That’s why not all applications can leverage this design choice.
For example, if we implement a recommender system for a video streaming application, having a delay of one day for the predicted movies and TV shows might work because you don’t consume these products at a high frequency. But suppose you make a recommender system for a social media platform. In that case, delaying one day or even one hour is unacceptable, as you constantly want to provide fresh content to the user.
Batch transform shines in scenarios where high throughput is needed, like data analytics or periodic reporting. However, it’s unsuitable for real-time applications due to its high latency and requires careful planning and scheduling to manage large datasets effectively. That’s why it is an offline serving method.
Conclusion
To conclude, we examined four fundamental requirements for deploying ML models: throughput, latency, data, and infrastructure.
Then, we examined the three most common architectures for serving ML models. We started with online real-time inference, which serves clients when they request a prediction. Then, we looked at the asynchronous inference method, which sits between online and offline. Ultimately, we presented the offline batch transform, which is used to process large amounts of data and store them in data storage, from where the client later consumes them.
Our latest book, the LLM Engineer’s Handbook, inspired this article.
If you liked this article, consider supporting our work by buying our book and getting access to an end-to-end framework on how to engineer production LLM & RAG applications, from data collection to fine-tuning, serving and LLMOps:

Images
If not otherwise stated, all images are created by the author.