

Fix your messy ML configs in your Python projects
2024 MLOps learning roadmap. Python syntax sugar that will help you write cleaner code.

Decoding ML Notes
This week our main focus will be a classic.
We will discuss Python.
More concretely how to write cleaner code and applications in Python. 🔥
Is that even possible? 💀
This week’s topics:
My favorite way to implement a configuration layer in Python
Some Python syntax sugar that will help you write cleaner code
2024 MLOps learning roadmap
Since creating content, I learned one crucial thing: "𝘌𝘷𝘦𝘳𝘺𝘣𝘰𝘥𝘺 𝘭𝘪𝘬𝘦𝘴 𝘵𝘰 𝘳𝘦𝘢𝘥 𝘢𝘯𝘥 𝘭𝘦𝘢𝘳𝘯 𝘥𝘪𝘧𝘧𝘦𝘳𝘦𝘯𝘵𝘭𝘺."
Do you prefer to read content on Medium?
Then, you are in luck.
Decoding ML is also on Medium.
Substack vs. Medium?
On Medium, we plan to post more extended and detailed content, while on Substack, we will write on the same topics but in a shorter and more concentrated manner.
If you want more code and less talking…
Check out our Medium publication 👀
↓↓↓
➔ 🔗 Decoding ML Medium publication

My favorite way to implement a configuration layer in Python
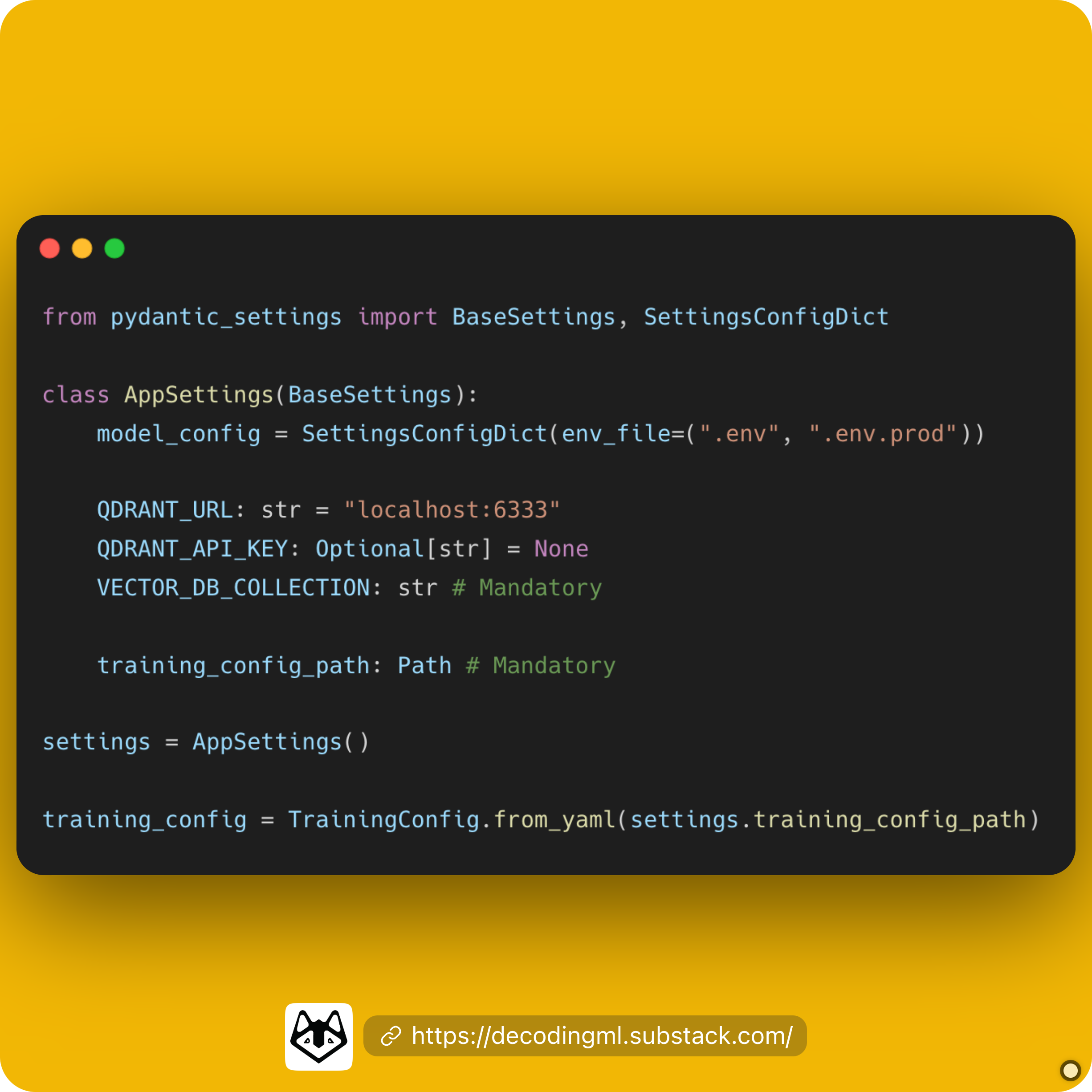
This is my favorite way to 𝗶𝗺𝗽𝗹𝗲𝗺𝗲𝗻𝘁 a 𝗰𝗼𝗻𝗳𝗶𝗴𝘂𝗿𝗮𝘁𝗶𝗼𝗻/𝘀𝗲𝘁𝘁𝗶𝗻𝗴𝘀 𝘀𝘆𝘀𝘁𝗲𝗺 in 𝗣𝘆𝘁𝗵𝗼𝗻 for all my apps ↓
The core is based on 𝘱𝘺𝘥𝘢𝘯𝘵𝘪𝘤, a data validation library for Python.
More precisely, on their 𝘉𝘢𝘴𝘦𝘚𝘦𝘵𝘵𝘪𝘯𝘨𝘴 class.
𝗪𝗵𝘆 𝘂𝘀𝗲 𝘁𝗵𝗲 𝗽𝘆𝗱𝗮𝗻𝘁𝗶𝗰 𝗕𝗮𝘀𝗲𝗦𝗲𝘁𝘁𝗶𝗻𝗴𝘀 𝗰𝗹𝗮𝘀𝘀?
- you can quickly load values from .𝘦𝘯𝘷 files (or even 𝘑𝘚𝘖𝘕 or 𝘠𝘈𝘔𝘓)
- add default values for the configuration of your application
- the MOST IMPORTANT one → It validates the type of the loaded variables. Thus, you will always be ensured you use the correct variables to configure your system.
𝗛𝗼𝘄 𝗱𝗼 𝘆𝗼𝘂 𝗶𝗺𝗽𝗹𝗲𝗺𝗲𝗻𝘁 𝗶𝘁?
It is pretty straightforward.
You subclass the 𝘉𝘢𝘴𝘦𝘚𝘦𝘵𝘵𝘪𝘯𝘨𝘴 class and define all your settings at the class level.
It is similar to a Python 𝘥𝘢𝘵𝘢𝘤𝘭𝘢𝘴𝘴 but with an extra layer of data validation and factory methods.
If you assign a value to the variable, it makes it optional.
If you leave it empty, providing it in your .𝙚𝙣𝙫 file is mandatory.
𝗛𝗼𝘄 𝗱𝗼 𝘆𝗼𝘂 𝗶𝗻𝘁𝗲𝗴𝗿𝗮𝘁𝗲 𝗶𝘁 𝘄𝗶𝘁𝗵 𝘆𝗼𝘂𝗿 𝗠𝗟 𝗰𝗼𝗱𝗲?
You often have a training configuration file (or inference) into a JSON or YAML file (I prefer YAML files as they are easier to read).
You shouldn't pollute your 𝘱𝘺𝘥𝘢𝘯𝘵𝘪𝘤 settings class with all the hyperparameters related to the module (as they are a lot, A LOT).
Also, to isolate the application & ML settings, the easiest way is to add the 𝘵𝘳𝘢𝘪𝘯𝘪𝘯𝘨_𝘤𝘰𝘯𝘧𝘪𝘨_𝘱𝘢𝘵𝘩 in your settings and use a 𝘛𝘳𝘢𝘪𝘯𝘪𝘯𝘨𝘊𝘰𝘯𝘧𝘪𝘨 class to load it independently.
Doing so lets you leverage your favorite way (probably the one you already have in your ML code) of loading a config file for the ML configuration: plain YAML or JSON files, hydra, or other fancier methods.
Another plus is that you can't hardcode the path anywhere on your system. That is a nightmare when you start using git with multiple people.
What do you say? Would you start using the 𝘱𝘺𝘥𝘢𝘯𝘵𝘪𝘤 𝘉𝘢𝘴𝘦𝘚𝘦𝘵𝘵𝘪𝘯𝘨𝘴 class in your ML applications?
Some Python syntax sugar that will help you write cleaner code
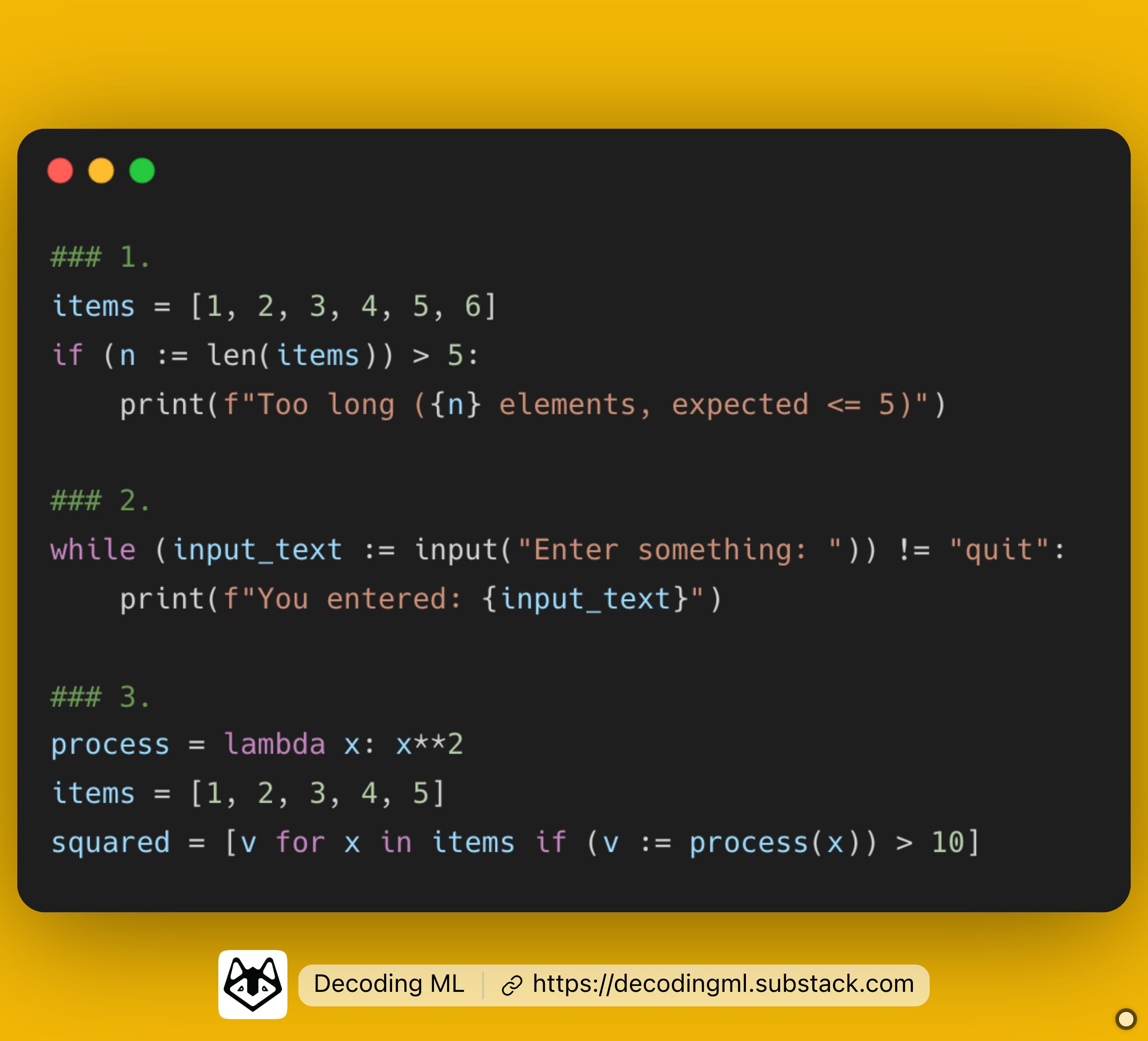
Here is some 𝗣𝘆𝘁𝗵𝗼𝗻 𝘀𝘆𝗻𝘁𝗮𝘅 𝘀𝘂𝗴𝗮𝗿 that will help you 𝘄𝗿𝗶𝘁𝗲 𝗰𝗹𝗲𝗮𝗻𝗲𝗿 𝗰𝗼𝗱𝗲 ↓
I am talking about the 𝘸𝘢𝘭𝘳𝘶𝘴 𝘰𝘱𝘦𝘳𝘢𝘵𝘰𝘳 denoted by the `:=` symbol.
It was introduced in Python 3.8, but I rarely see it used.
Thus, as a "clean code" freak, I wanted to dedicate a post to it.
𝗪𝗵𝗮𝘁 𝗱𝗼𝗲𝘀 𝘁𝗵𝗲 𝘄𝗮𝗹𝗿𝘂𝘀 𝗼𝗽𝗲𝗿𝗮𝘁𝗼𝗿 𝗱𝗼?
It's an assignment expression that allows you to assign and return a value in the same expression.
𝗪𝗵𝘆 𝘀𝗵𝗼𝘂𝗹𝗱 𝘆𝗼𝘂 𝘂𝘀𝗲 𝗶𝘁?
𝘊𝘰𝘯𝘤𝘪𝘴𝘦𝘯𝘦𝘴𝘴: It reduces the number of lines needed for variable assignment and checking, making code more concise.
𝘙𝘦𝘢𝘥𝘢𝘣𝘪𝘭𝘪𝘵𝘺: It can enhance readability by keeping related logic close, although this depends on the context and the reader's familiarity with exotic Python syntax.
𝙃𝙚𝙧𝙚 𝙖𝙧𝙚 𝙨𝙤𝙢𝙚 𝙚𝙭𝙖𝙢𝙥𝙡𝙚𝙨
↓↓↓
1. Using the walrus operator, you can directly assign the result of the 𝘭𝘦𝘯() function inside an if statement.
2. Avoid calling the same function twice in a while loop. The benefit is less code and makes everything more readable.
3. Another use case arises in list comprehensions where a value computed in a filtering condition is also needed in the expression body. Before the 𝘸𝘢𝘭𝘳𝘶𝘴 𝘰𝘱𝘦𝘳𝘢𝘵𝘰𝘳, if you had to apply a function to an item from a list and filter it based on some criteria, you had to refactor it to a standard for loop.
.
When writing clean code, the detail matters.
The details make the difference between a codebase that can be read like a book or one with 10 WTFs / seconds.
What do you think? Does the walrus operator make the Python code more readable and concise?
2024 MLOps learning roadmap
𝗪𝗮𝗻𝘁 to 𝗹𝗲𝗮𝗿𝗻 𝗠𝗟𝗢𝗽𝘀 but got stuck at the 100th tool you think you must know? Here is the 𝗠𝗟𝗢𝗽𝘀 𝗿𝗼𝗮𝗱𝗺𝗮𝗽 𝗳𝗼𝗿 𝟮𝟬𝟮𝟰 ↓
𝘔𝘓𝘖𝘱𝘴 𝘷𝘴. 𝘔𝘓 𝘦𝘯𝘨𝘪𝘯𝘦𝘦𝘳
In theory, MLEs focus on deploying models to production while MLOps engineers build the platform used by MLEs.
I think this is heavily dependent on the scale of the company. As the company gets smaller, these 2 roles start to overlap more.
This roadmap will teach you how to build such a platform, from programming skills to MLOps components and infrastructure as code.
.
Here is the MLOps roadmap for 2024 suggested by
𝟭. 𝗣𝗿𝗼𝗴𝗿𝗮𝗺𝗺𝗶𝗻𝗴
- Python & IDEs
- Bash basics & command line editors
𝟮. 𝗖𝗼𝗻𝘁𝗮𝗶𝗻𝗲𝗿𝗶𝘇𝗮𝘁𝗶𝗼𝗻 𝗮𝗻𝗱 𝗞𝘂𝗯𝗲𝗿𝗻𝗲𝘁𝗲𝘀
- Docker
- Kubernetes
𝟯. 𝗠𝗮𝗰𝗵𝗶𝗻𝗲 𝗹𝗲𝗮𝗿𝗻𝗶𝗻𝗴 𝗳𝘂𝗻𝗱𝗮𝗺𝗲𝗻𝘁𝗮𝗹𝘀
...until now we laid down the fundamentals. Now let's get into MLOps 🔥
𝟰. 𝗠𝗟𝗢𝗽𝘀 𝗽𝗿𝗶𝗻𝗰𝗶𝗽𝗹𝗲𝘀
- reproducible,
- testable, and
- evolvable ML-powered software
𝟱. 𝗠𝗟𝗢𝗽𝘀 𝗰𝗼𝗺𝗽𝗼𝗻𝗲𝗻𝘁𝘀
- Version control & CI/CD pipelines
- Orchestration
- Experiment tracking and model registries
- Data lineage and feature stores
- Model training & serving
- Monitoring & observability
𝟲. 𝗜𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 𝗮𝘀 𝗰𝗼𝗱𝗲
- Terraform

As a self-learner, I wish I had access to this step-by-step plan when I started learning MLOps.
Remember, you should pick up and tailor this roadmap at the level you are currently at.
Find more details about the roadmap in
➔ 🔗 MLOps roadmap 2024