



PI #008: Your Data Validation Guide in Under 3 Minutes
A wise man said: data validation shouldn't be hard & you should validate everything!

Hello there, I am Paul Iusztin, and within this newsletter, I will deliver,
your weekly piece of MLE & MLOps wisdom straight to your inbox 🔥
This week we will cover:
How to use GE to validate your data
Why you should consider validating your data in multiple points of your pipeline
#1. How to use GE to validate your data
Data validation shouldn't be hard.
Here is your data validation guide in under 2 minutes 👇
Data validation ensures the integrity and quality of your data ingested automatically into your ML system.
Thus, implementing your data validation layer is crucial in any successful ML system.
.
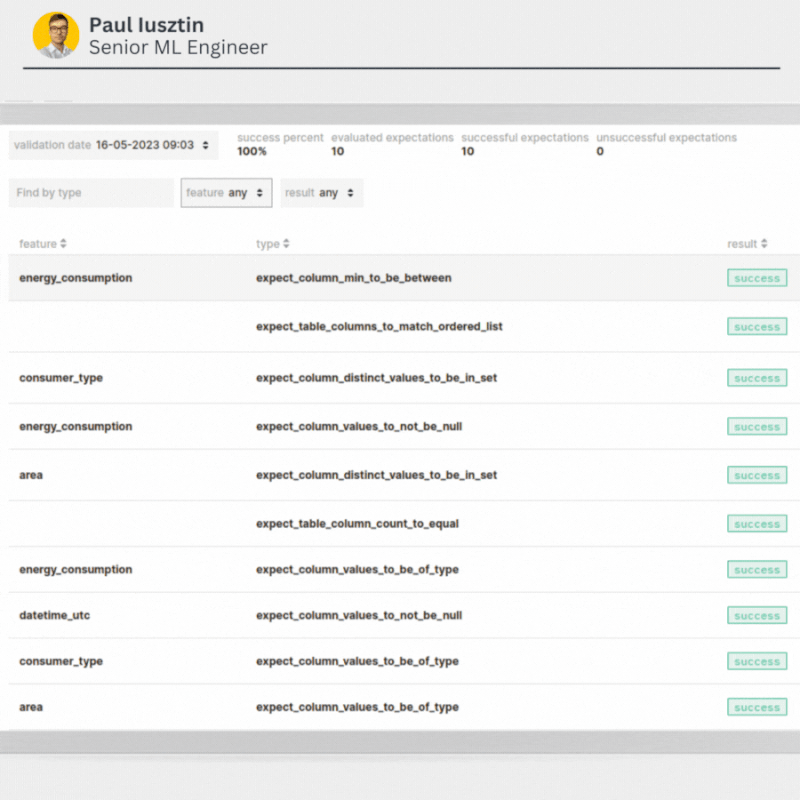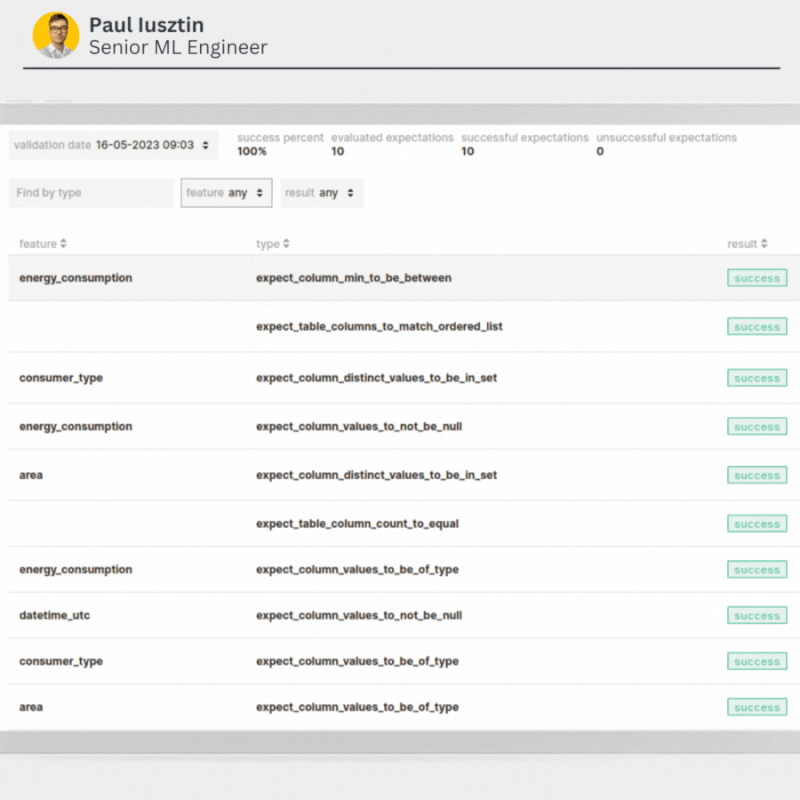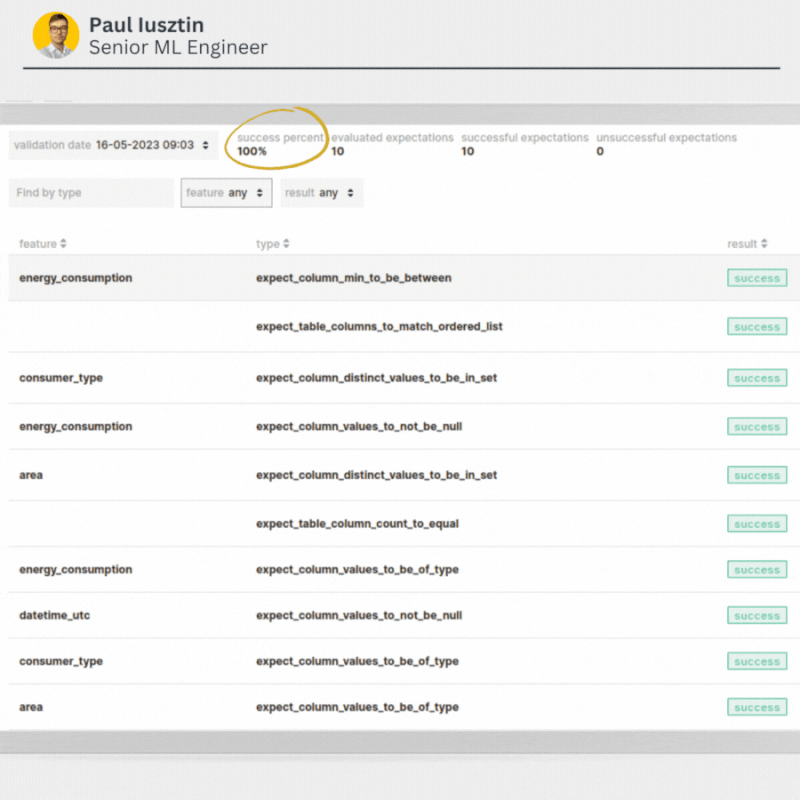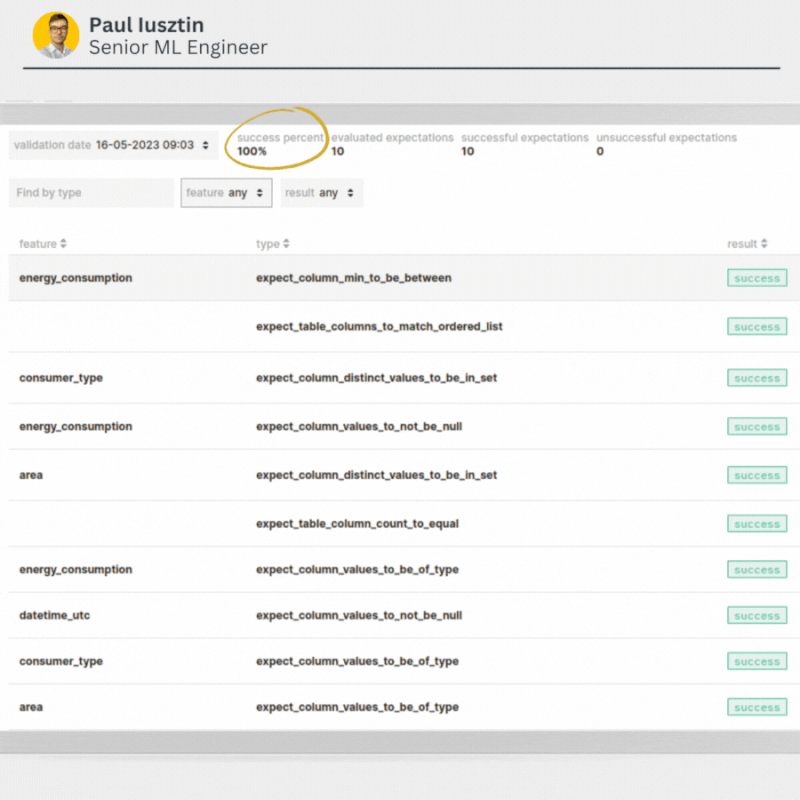
🧘🏼♂️ Great Expectations make everything straightforward.
Using GE, you must stack multiple ExpectationConfiguration objects, where each object checks a single rule/feature.
For example:
ExpectationConfiguration(
expectation_type="expect_column_distinct_values_to_be_in_set",
kwargs={"column": "area", "value_set": (0, 1, 2)}
), checks if the "area" feature contains only values equal to 0, 1 or 2.
The most common checks you have to do are for the following:
- the schema of the table;
- the type of each column;
- the values of each column: an interval for continuous variables or an expected set for discrete variables;
- null values.
.
After you run your GE validation suit, you will get a success %.
Based on the success % you can make various decisions, such as:
🟢 == 100% - ingest the data without an alert
🟡 >=90% - ingest the data with an alert
🔴 <90% - drop the data with an error
P.S. Using GE + Hopsworks as your Feature Store makes everything even simpler 🔥
So remember...
GE makes implementing your data validation layer straightforward.
You have to check every feature for a given set of rules.
Based on the success % you have to take various actions.
#2. Why you should consider validating your data in multiple points of your pipeline
A wise man said: 𝘃𝗮𝗹𝗶𝗱𝗮𝘁𝗲 𝗲𝘃𝗲𝗿𝘆𝘁𝗵𝗶𝗻𝗴!
100% you heard that data validation is good...
but where should we validate the data? Everywhere!
That might be an overstatement, but let me explain.
When the outputs of an ML model are poor, there are 1000+ reasons why that happened.
But even if you know that the issue is data related...
Narrowing down to the actual function that messed up everything is extremely hard.
Thus, by adding data validation before & after:
- the ingestion ETL;
- the data engineering pipeline;
- the feature engineering pipeline;
you might add some redundancy, but this will make scanning for errors extremely easy.
.
Imagine that you would have a data validation check only after the FE pipeline. If that fails, you know it failed 𝘣𝘶𝘵 𝘥𝘰𝘯'𝘵 𝘬𝘯𝘰𝘸 𝘸𝘩𝘦𝘳𝘦 𝘪𝘵 𝘧𝘢𝘪𝘭𝘦𝘥.
If the system is small, that is not an issue, but imagine you have 100+ transformations spread across multiple teams...
🥲 Finding the right error might take you hours or even days.
💛 By adding multiple data validation points in your system, you can quickly answer to: "where the system failed".
Thus, by adding data validation in multiple, you automatically slice the pipeline making it easy to diagnose.
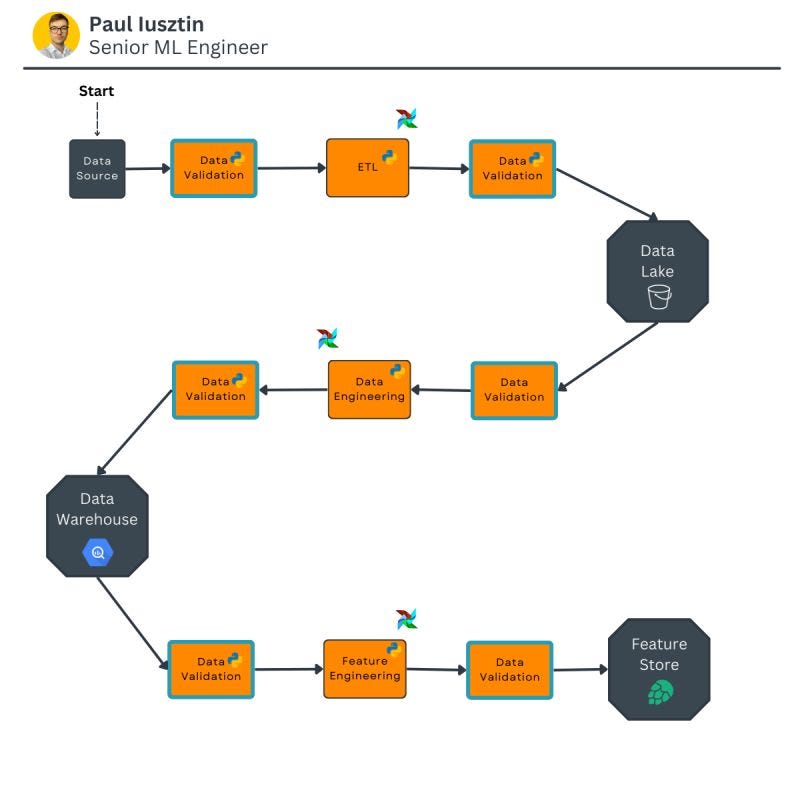
Note that this is just an example. Your data infrastructure might look different.
But the fundamental idea remains the same. Add data validation in all the essential points of your data pipelines to quickly slice and dice the upcoming errors.
👉 If you want a hands-on example of using GE to validate your data, check out my article: Ensuring Trustworthy ML Systems With Data Validation and Real-Time Monitoring.
These are this week’s tips & tricks about data validation.
See you next Thursday at 9:00 am CET.
Have a fantastic weekend!
Paul
Whenever you’re ready, here is how I can help you:
The Full Stack 7-Steps MLOps Framework: a 7-lesson FREE course that will walk you step-by-step through how to design, implement, train, deploy, and monitor an ML batch system using MLOps good practices. It contains the source code + 2.5 hours of reading & video materials on Medium.
Machine Learning & MLOps Blog: here, I approach in-depth topics about designing and productionizing ML systems using MLOps.