



RAG done right - Legal AI search case study
3 real-world lessons to make RAG work (Retrieval-Augmented Generation)


Guest post from the ai-aflat.ro team, the AI Assistant for Romanian Laws.
We have developed and launched ai-aflat, the AI Assistant for Romanian Laws, which you can try out at ai-aflat.ro. Do your legal research through intuitive conversation and find the laws that are relevant to you.
Through our development process, we have gathered practical insights into building a semantic search/RAG infrastructure for legal that works in production and serves hundreds of clients.
In this article, we want to share the real-world lessons that made our RAG system work to build an AI search engine for legal documents, from structuring the data to selecting the optimal parameters and providing real-time feedback.
Table of Contents:
Saas: Search as a Service
Is your Knowledge Base fit for Search?
Chunking - what is the atomic unit of Knowledge?
The “size” of information
1. SaaS - Search as a Service
Search sees a new paradigm: Semantic Search, a method which relies on the actual meaning of the content. In a nutshell, it allows users to search by a simple description, without the need for domain-specific jargon, because the focus is on the overall context of the question and its answer rather than keywords or filters.
We identified a potential use-case for this method in the legal domain, where there is a huge gap between the general public and the source of information. That’s because the public thinks in terms of practical scenarios, while the law is formulated in terms of abstract definitions. The solution is an architecture that leverages an AI Assistant connected to a Semantic Search Engine.
This architecture is known as Retrieval-Augmented Generation (RAG), because the AI Assistant generates the response based on the information the search engine retrieves, thus making sure that there is rigorous control over the contents of the answer.
While a traditional search would also work, the semantic-based method is a much better fit, because it allows the full context to be passed into the engine for a more nuanced understanding of it. But how does that actually work?
Apart from the AI models that can generate text as a response to other text, there are also models trained to transform a given text into a special representation.
Think about this special representation as a sequence of colors. But there’s a catch: these colors are not random; two similar texts will have two matching sequences of colors. Like for example, two descriptions of the same thing. Or… a question about finance and its corresponding Fiscal Code article.

Now, by processing an entire database of texts with this model, we obtain all their corresponding representations - by the way, they are called embeddings. And we can search this database by comparing our query with all the samples and identifying the most similar ones.
2. Is your Knowledge Base fit for Search?
Analysis of Romanian Legislation
The first step when assembling the Knowledge Base is whether the AI model is actually able to capture the nuances of the source information. In the case of our app, the first concern is whether the model will be able to distinguish between the types and domains of legislation.
Let’s recap on how we are processing the information in order to build the semantic search engine. We use an AI model to transform all the laws and articles into embeddings, which are representations that allow us to measure similarity between texts. Because of this we can plot these representations and study the pairwise similarity before moving on to building the actual search engine.
This serves to empirically test properties that we already know and expect. We expect that representations of articles of the same code are similar to each other. In the plot this similarity is shown directly by the spatial position of each point on the plot. Each point represents a law article and other points that are close to the article's point represent texts that should be similar to it. Let’s see what patterns show up.
Imagine the embeddings plot as a large party. People talking about the same things will group together. Discussions that are niche and focused will tend to separate from the rest, in concentrated groups. Discussions about general topics spark up everywhere, but are not as densely-packed. Socialites mingle together, jumping from one subject to the next.
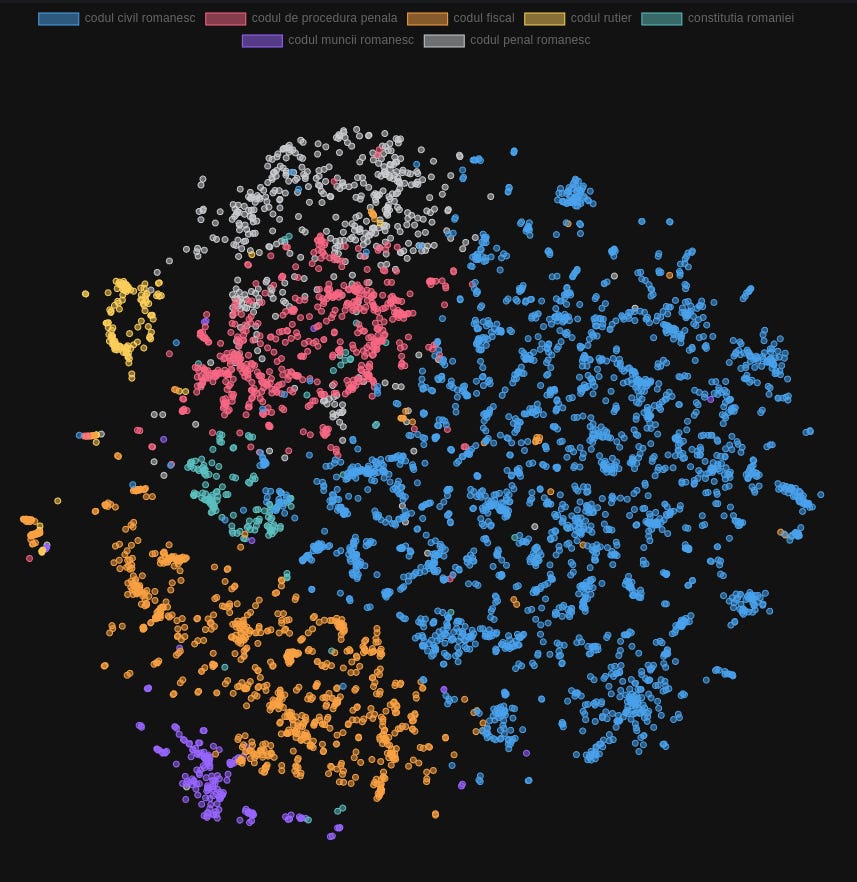
Observation 1: Clusters
We see that the points form clusters according to the logical structure. Groups are coherent to the grouping of the articles in the legislation codes. This is a very good sign since there was no guarantee that the AI model would necessarily be able to correctly capture the nuanced differences and similarities between the samples.
We have no control on how the model generates the embeddings and what it deems more important. Samples might be similar by one criteria and completely unrelated by other criteria.
For example, the model might focus more on style, prioritizing similarities between the tone of the text rather than the differences in topic. This can be highly destructive for a search engine.
Imagine that if in this database we’d also add the English versions of the texts, we might discover that we obtain two main clusters, split by language, rather than the 7 clusters, split by topic.
Observation 2: Relationships between clusters
Remarkably, we see that various clusters show some interesting relationships to each other. For example the samples from the Penal Code (gray) are mixed with the ones from the Penal Procedure (red), without a clear delimiter.
This is because they do indeed share a great deal of similarity, as the Code represents the absolute law, while the Procedure tells us how it should be applied. Therefore it is to be expected that the semantic analysis of the AI model that generates the embeddings sees them as inter-twined in terms of topic and meaning. This does not happen with the other neighboring clusters, such as the Civil Code (blue), for example.
Interestingly enough, the Civil Code (blue) samples are the most spread out, probably explained by the fact that it covers such a wide range of situations. Any non-violent conflict between citizens is ruled by the Civil Code, from inheritance to the rights between neighbours. So, indeed, the variability of texts gives us a less dense cluster.
On the other hand, the Traffic laws (yellow) show a very distinctive group from the rest of the samples. The Labour code (purple), too, looks compact. Both these groups refer to much more specific scenarios and therefore, inner-group similarity is high and they easily form distinct clusters. Funny enough, at the center of all of them sits the Constitution (turquoise), although this is probably an artifact of the algorithm (see Note).
Note: This visual analysis is not a rigorous one. These relationships must be studied in terms of average similarity values across the clusters. The visual representation usually accounts for no more than 10% of the variability in the original data.
Remember that embeddings have more than 1500 dimensions and we try to represent them in no more than 3. Indeed, we use algorithms to make this representation as high fidelity as possible (in this case we used tsne) but this limit must be kept in mind. For the purpose of this article we focused on a more intuitive approach, therefore we focused on visual cues.
Credits: The plot was generated with Qdrant, a very useful tool that helped us tremendously
3. Chunking - what is the atomic unit of knowledge?
Identifying the chunks in which you can split an entire legislation base
A practical question is this: how do you feed an entire database of information into a Search Infrastructure?
The first answer: you have to split it into smaller chunks. This chunk should contain all the information you’d need to provide an answer about a particular topic. In the case of our app, it would seem natural to consider each one law to be one chunk. Seems straight-forward… but wait.
The second thought: you soon realize that not all laws are created equal, at least not in terms of length. There are laws that fit in several paragraphs and others that have thousands of articles (the Civil Code, for example, is technically speaking just another law)
By inspecting the articles of various laws you discover that they don’t always share the same subject. So… maybe we should consider articles to be ‘the’ chunks?
There’s two catches for a chunk. It must at the same time:
a) fit inside the embedding model (OpenAI’s model has a limit of ~6k words)
b) fit into the model which generates the response (OpenAI’s GPT 4o has a limit of 30k words)
While the response generation doesn’t look like a problem, note that the model that generates the response should probably look at the top k most relevant chunks, in order to formulate a reliable response. Soo…
How to split a text into chunks
How often do you read a book and finish up a sentence just as you are finishing the page? How often do you need to turn the page in order to finish up the current sentence? Well, that’s exactly the main challenge of splitting your information into chunks.

You see, if you simply split a text into fixed-seized chunks based on the number of words alone, you have no guarantee that they will follow the splitting in terms of logical meaning. A chunk might cut-off mid-sentence without neither the first nor the latter making any sense on its own.
It’s clear that we somehow must make sure that a chunk makes sense on its own. After all, that is what is being fed into the LLM that generates the answer. We have to make sure that our chunk is the atomic unit of knowledge. Just as a famous quote can mean a different thing when taken out of context, we have to make sure that our system offers all the needed context.

This is a part of the Civil Code. We exemplified how chunking might look in a very unfortunate scenario, by highlighting them with different colors. Try to make sense of each individual chunk without looking at the others. This would be the result fo simply chunking our text not based on the content meaning but on the number of words.
Observation 1: Overlap
The simple solution to chunking that truncates context mid-sentence is to generate chunks with an overlap, so that we always have a chunk that contains the un-interrupted sentence in the focus point, like a lens that scans over an image.
But the quality of chunks might still suffer. Arbitrary cutoffs will affect the grammatical structure and this can impact the resulting embeddings in unpredictable ways.
Suppose that you have a chunk that starts with a question mark, cut out from the previous sentence. It has nothing to do with the current chunk. However, it might now seem that instead of a statement, the current chunk represents a question.
Take this example: “? Mark approves decision”.
If you saw it without any other question, what would you conclude? This is what the AI model sees.
Runaway characters from arbitrary chunk splitting can effectively act as prompt injections, drastically changing the meaning of the content.
Observation 2: Needle in the haystack
But why don’t we simply make bigger models that can handle longer texts? Then we wouldn’t have to split the text into chunks…
Another issue arises, and it’s called the needle in the haystack. The AI might not be very good at picking up the exact (rather concise) target information out of a vast volume of non-relevant noise.
This is why a however-large chunk will not cut it. We have to pick the smallest size as long as it is enough to capture all the information needed for the response. The search engine must point the LLM to the exact part where the needed context can be found, just as a teacher who shows a student the correct formula at the exact page in the book.
4. The “size” of information
Designing an optimal solution for the structure of Romanian legislation
It seems like the size of the chunks really boils down as the most debatable parameter. As we can easily agree that the ideal chunking is done not by arbitrary cutoffs, we still don’t have a definite answer for how much text should we place into one chunk? Should it be a paragraph, a page or an entire chapter?
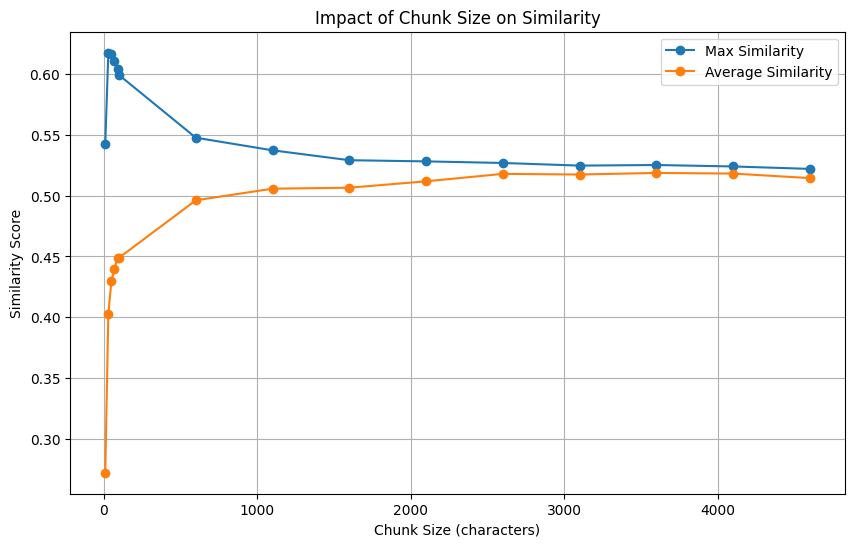
Here we have selected 360 question-answer pairs: a question and its corresponding relevant legislation. And then we chose various chunk sizes into which we split each respective legislation text and measured the similarity between the question and the resulting chunks.
Observation 1: Small chunks introduce false-positives
If we look at the maximum similarity we might conclude that the smaller the chunks, the better.
But note that the same maximum will probably be achieved by any other sample in the database, thus introducing false-positives.
Why?
This small size of chunks means that we are basically matching individual words from our context, one at a time. Certainly, there must be one chunk that achieves a high similarity with the question, but this means nothing.
On average, most of the chunks have a very low similarity, even though we know that this context is the correct relevant match for our question. Similar to how we got one small bit that fit, there is no longer context to capture the nuances, so we’d expect that other samples will have just the same behavior.
Observation 2: Large chunks introduce false-negatives
Larger chunks score better on average due to broader context.
The maximum and the average values are close, meaning that the overall behavior is more stable, i.e., it does not boil down to luckily matching a single chunk. But as we saw earlier, the needle in the haystack problem means that nuances of the context also get diluted.
Observation 3: One size does not fit all
The problem of chunking has one key aspect: what you actually look for! In order to have chunks that contain all the needed context, we must know what is needed.
Let us continue on the analogy with the book. Imagine a regular crime novel.
Now, consider that a question about where one of the characters lives, easily finds its answer on a particular page where that information happens to be provided.
But what if we ask what was the motive of the murder?
We might only find the correct answer by evaluating the entire final chapter, not just one particular page (or even several).
Now consider that we ask “How did the main character evolve through the story?”
Well this information resides in the entire book and no sub-part of it is enough to provide the complete context.
That’s why designing the search engine must start with thinking of what the user will ask. So that we can chunk our information base in various ways, even have variable-length chunks, so that we capture both the detail-level and the overview-level. Because this translates to either chunks that span sentences or chunks that span longer corpuses.
One must also consider synthetic chunks, meaning texts generated by a LLM based on some parts of the original - summaries, question examples, etc. This may also alleviate the problem of finding the most compatible chunk content for the expected user questions.
Conclusion: the pitfall of generic solutions
As we saw, there is a long discussion about each and every parametrizable aspect of the solution. These arguments are not objectively correct or wrong as they are dependent on the specific use case.
This is the reason why a one-size-fits-all solution is arguably impossible to produce - a solution where we simply drag and drop a collection of documents into a pre-defined pipeline, hit enter, and then the magic happens by itself.
Surely enough, we’ll obtain a semantic search engine from this. But the question, as the technology grows in popularity, is not having a solution but having one that actually works.
Big thanks to our guests from ai-aflat.ro for contributing to Decoding ML with this fantastic article packed with real-world insights:
From ai-aflat: “Interested in AI tailored-fit solutions for your business?”
Let’s get in touch and discuss what AI solutions fit you.
ai-aflat is our showcase product here at Sapio AI. But our services cover a much wider range of expertise.
We are committed to delivering state-of-the-art technology that covers all the AI “senses”:
Computer Vision
Audio Processing
Voice Recognition
Natural Language
Additionally, we have a solid background in implementing and deploying services that connect to existing infrastructure.
Technology can elevate your workflows. We are here to help you with consulting, design and deployment for anything AI-related.
As we like to say at Sapio AI, we’re in the business of problem-solving.
If interested, contact Vlad ↓
Email: vlad.tudor@sapio.ro
Images
If not otherwise stated, all images are created by the author.
 |
|
 | A guest post by
|
These insights were so helpful! I have a legal product to build, and now I have a good idea of what might be the challenges and how I need to involve my stakeholders to build an effective semantic search engine. Thank you for this well-written article.