

Retrieval-Augmented Generation (RAG) Fundamentals First
Mastering the basics of RAG still beats advanced techniques

To build successful and complex RAG applications, you must first deeply understand the fundamentals behind them. In this article, we will learn why we use RAG and how to design the architecture of your RAG layer.
Retrieval-augmented generation (RAG) enhances the accuracy and reliability of generative AI models with information fetched from external sources. It is a technique complementary to the internal knowledge of the LLMs. Before going into the details, let’s understand what RAG stands for:
Retrieval: search for relevant data;
Augmented: add the data as context to the prompt;
Generation: use the augmented prompt with an LLM for generation.
Any LLM is bound to understand the data it was trained on, sometimes called parameterized knowledge. Thus, even if the LLM can perfectly answer what happened in the past, it won’t have access to the newest data or any other external sources on which it wasn’t trained.
Let’s take the most powerful model from OpenAI as an example, which in the summer of 2024 is GPT-4o. The model is trained on data up to Oct 2023. Thus, if we ask what happened during the 2020 pandemic, it can be answered perfectly due to its parametrized knowledge. However, it will not know the answer if we ask about the 2024 soccer EURO cup results due to its bounded parametrized knowledge. Another scenario is that it will start confidently hallucinating and provide a faulty answer.
RAG overcomes these two limitations of LLMs. It provides access to external or latest data and prevents hallucinations, enhancing generative AI models’ accuracy and reliability.
Why use RAG?
We briefly explained the importance of using RAG in generative AI applications above. Now, we will dig deeper into the “why”. Next, we will focus on what a naïve RAG framework looks like.
For now, to get an intuition about RAG, you have to know that when using RAG, we inject the necessary information into the prompt to answer the initial user question. After, we pass the augmented prompt to the LLM for the final answer. Now the LLM will use the additional context to answer the user question.
There are two fundamental problems that RAG solves:
1. Hallucinations
2. Old or private information
Hallucinations
If a chatbot without RAG is asked a question about something it wasn’t trained on, there are big changes that will give you a confident answer about something that isn’t true. Let’s take the 2024 soccer EURO Cup as an example. If the model is trained up to Oct 2023 and we ask something about the tournament, it will most likely come up with some random answer that is hard to differentiate from reality.
Even if the LLM doesn’t hallucinate all the time, it raises the concern of trust in its answers. Thus, we have to ask ourselves: “When can we trust the LLM’s answers?” and “How can we evaluate if the answers are correct?”
By introducing RAG, we will enforce the LLM to always answer solely based on the introduced context. The LLM will act as the reasoning engine, while the additional information added through RAG will act as the single source of truth for the generated answer.
By doing so, we can quickly evaluate if the LLM’s answer is based on the external data or not.
Old information
Any LLM is trained or fine-tuned on a subset of the total world knowledge dataset. This is due to three main issues:
Private data: You cannot train your model on data you don’t own or have the right to use.
New data: New data is generated every second. Thus, you would have to constantly train your LLM to keep up.
Costs: Training or fine-tuning an LLM is an extremely costly operation. Hence, it is not feasible to do it on an hourly or daily basis.
RAG solved these issues, as you no longer have to constantly fine-tune your LLM on new data (or even private data). Directly injecting the necessary data to respond to user questions into the prompts that are fed to the LLM is enough to generate correct and valuable answers.
The vanilla RAG framework
Every RAG system is similar at its roots. We will first focus on understanding RAG in its simplest form. Later, we will gradually introduce more advanced RAG techniques to improve the system’s accuracy.
A RAG system is composed of three main modules independent of each other:
Ingestion pipeline: A batch or streaming pipeline used to populate the vector DB.
Retrieval pipeline: A module that queries the vector DB and retrieves relevant entries to the user’s input.
Generation pipeline: The layer that uses the retrieved data to augment the prompt and an LLM to generate answers.
As these three components are classes or services of their own, we will dig into each separately.
But how are these three modules connected? Here is a very simplistic overview:
On the backend side, the ingestion pipeline runs on a schedule or constantly to populate the vector DB with external data.
On the client side, the user asks a question.
The question is passed to the retrieval module, which pre-processes the user’s input and queries the vector DB.
The generation pipelines use a prompt template, user input, and retrieved context to create the prompt.
The prompt is passed to an LLM to generate the answer.
The answer is shown to the user.

Ingestion pipeline
The RAG ingestion pipeline extracts raw documents from various data sources (e.g., data warehouse, data lake, web pages, etc.). Then, it cleans, chunks and embeds the documents. Ultimately, it loads the embedded chunks to a vector DB (or other similar vector storage).
Thus, the RAG ingestion pipeline is split again into the following:
The data extraction module gathers all necessary data from various sources such as databases, APIs, or web pages. This module is highly dependent on your data. It can be as easy as querying your data warehouse or something more complex, such as crawling Wikipedia.
A cleaning layer that standardizes and removes unwanted characters from the extracted data.
The chunking module splits the cleaned documents into smaller ones. As we want to pass the document’s content to an embedding model, this is necessary to ensure it doesn’t exceed the model’s input maximum size. Also, chunking is required to separate specific regions that are semantically related. For example, when chunking a book chapter, the most optimal way is to group similar paragraphs into the same chunk. By doing so, at the retrieval time, you will add only the essential data to the prompt.
The embedding component uses an embedding model to take the chunk’s content (text, images, audio, etc.) and project it into a dense vector packed with semantic value — more on embeddings in the Embeddings models section below.
The loading module takes the embedded chunks along with a metadata document. The metadata will contain essential information such as the embedded content, the URL to the source of the chunk, when the content was published on the web, etc. The embedding is used as an index to query similar chunks, while the metadata is used to access the information added to augment the prompt.
At this point, we have an RAG ingestion pipeline that takes raw documents as input, processes them, and populates a vector DB. The next step is to retrieve relevant data from the vector store correctly.
Retrieval pipeline
The retrieval components take the user’s input (text, image, audio, etc.), embed it, and query the vector DB for similar vectors to the user’s input.
The primary function of the retrieval step is to project the user’s input into the same vector space as the embeddings used as an index in the vector DB. This allows us to find the top K’s most similar entries by comparing the embeddings from the vector storage with the user’s input vector. These entries then serve as content to augment the prompt that is passed to the LLM to generate the answer.
You must use a distance metric to compare two vectors, such as the Euclidean or Manhattan distance. But the most popular one is the cosine distance [1], which is equal to 1 minus the cosine of the angle between two vectors as follows:
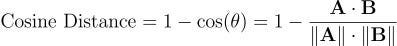
It ranges from -1 to 1, with a value of -1 when vectors A and B are in opposite directions, 0 if they are orthogonal and 1 if they point in the same direction.
Most of the time, the cosine distance works well in non-linear complex vector spaces. However, it is essential to notice that choosing the proper distance between two vectors depends on your data and the embedding model you use.
One critical factor to highlight is that the user’s input and embeddings must be in the same vector space. Otherwise, you cannot compute the distance between them. To do so, it is essential to pre-process the user input in the same way you processed the raw documents in the RAG ingestion pipeline. It means you must clean, chunk (if necessary), and embed the user’s input using the same functions, models, and hyperparameters. Similar to how you have to pre-process the data into features in the same way between training and inference, otherwise the inference will yield inaccurate results — a phenomenon also known as the training-serving skew.
Generation pipeline
The last step of the RAG system is to take the user’s input and the retrieved data, pass them to an LLM of your choice and generate the answer.
The final prompt results from a prompt template populated with the user’s query and retrieved context. You might have a single or multiple prompt templates depending on your application. Usually, all the prompt engineering is done at the prompt template level.
Each prompt template and LLM should be tracked and versioned using MLOps best practices. Thus, you always know that a given answer was generated by a specific version of the LLM and prompt template(s).
Conclusion
In this article, we have looked over the fundamentals of RAG.
First, we understood why RAG is so powerful and why many AI applications implement it, as it overcomes challenges such as hallucinations and outdated data.
Secondly, we examined the architecture of a naive RAG system, which consists of an ingestion, retrieval and generation pipeline.
This article was inspired by my latest book, “LLM Engineer’s Handbook.”
If you liked this article, consider supporting my work by buying my book and getting access to an end-to-end framework on how to engineer LLM & RAG applications, from data collection to fine-tuning, serving and LLMOps:

References
Literature
[1] Cosine similarity, Wikipedia
Images
If not otherwise stated, all images are created by the author.
Can you check my publication, and if it aligns with your goal, then we can collaborate? Please have a look:
https://hustlercoder.substack.com/