



Ready for production ML? Here are the 4 pillars to build production ML systems
ML Platforms & MLOps Components. RAG:RAG: What problems does it solve, and how is it integrated into LLM-powered applications

Decoding ML Notes
This week’s topics:
Using an ML Platform is critical to integrating MLOps into your project
The 4 pillars to build production ML systems
RAG: What problems does it solve, and how is it integrated into LLM-powered applications?
Using an ML Platform is critical to integrating MLOps into your project
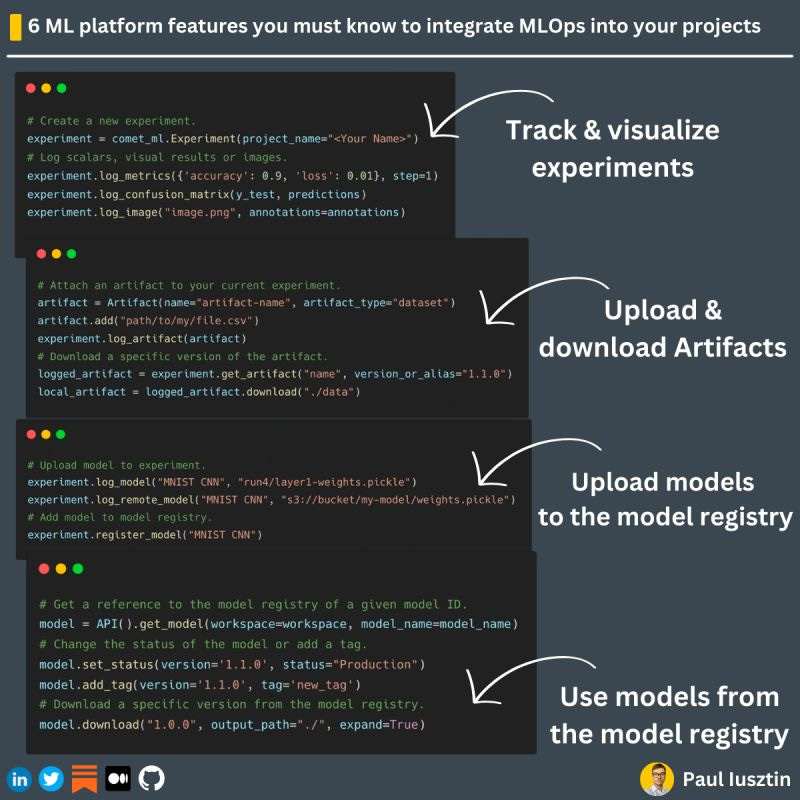
Here are 6 ML platform features you must know & use ↓
...and let's use Comet ML as a concrete example.
#𝟭. 𝗘𝘅𝗽𝗲𝗿𝗶𝗺𝗲𝗻𝘁 𝗧𝗿𝗮𝗰𝗸𝗶𝗻𝗴
In your ML development phase, you generate lots of experiments.
Tracking and comparing the metrics between them is crucial in finding the optimal model & hyperparameters.
#𝟮. 𝗠𝗲𝘁𝗮𝗱𝗮𝘁𝗮 𝗦𝘁𝗼𝗿𝗲
Its primary purpose is reproducibility.
To know how a model from a specific experiment was generated, you must know:
- the version of the code
- version of the dataset
- hyperparameters/config
- total compute
... and more
#𝟯. 𝗩𝗶𝘀𝘂𝗮𝗹𝗶𝘀𝗮𝘁𝗶𝗼𝗻𝘀
Most of the time, along with the scalar metrics, you must log visual results, such as:
- images
- videos
- prompts
- t-SNE graphs
- 3D point clouds
... and more
#4. 𝐀𝐫𝐭𝐢𝐟𝐚𝐜𝐭𝐬
The most powerful feature out of them all.
An artifact is a versioned object that acts as an input or output for your job.
Everything can be an artifact (data, model, code), but the most common case is for your data.
Wrapping your assets around an artifact ensures reproducibility and shareability.
For example, you wrap your features into an artifact (e.g., features:3.1.2), which you can consume and share across multiple ML environments (development or continuous training).
Using an artifact to wrap your data allows you to quickly respond to questions such as "What data have I used to generate the model?" and "What Version?"
#5. 𝐌𝐨𝐝𝐞𝐥 𝐑𝐞𝐠𝐢𝐬𝐭𝐫𝐲
The model registry is the ultimate way to version your models and make them accessible to all your services.
For example, your continuous training pipeline will log the weights as an artifact into the model registry after it trains the model.
You label this model as "v:1.1.5:staging" and prepare it for testing. If the tests pass, mark it as "v:1.1.0:production" and trigger the CI/CD pipeline to deploy it to production.
#6. 𝐖𝐞𝐛𝐡𝐨𝐨𝐤𝐬
Webhooks lets you integrate the Comet model registry with your CI/CD pipeline.
For example, when the model status changes from "Staging" to "Production," a POST request triggers a GitHub Actions workflow to deploy your new model.
↳🔗 Check out Comet to learn more
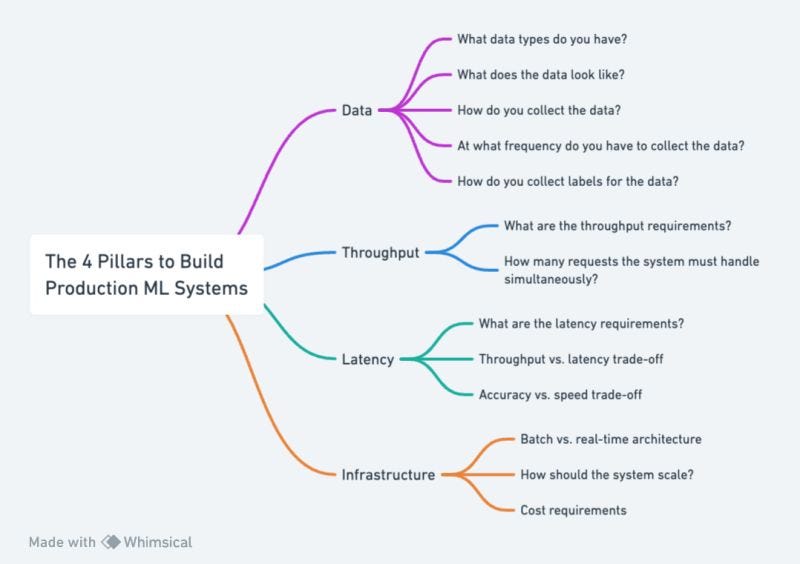
The 4 pillars to build production ML systems
Before building a production-ready system, it is critical to consider a set of questions that will later determine the nature of your ML system architecture.
𝘏𝘦𝘳𝘦 𝘢𝘳𝘦 𝘵𝘩𝘦 4 𝘱𝘪𝘭𝘭𝘢𝘳𝘴 𝘵𝘩𝘢𝘵 𝘺𝘰𝘶 𝘢𝘭𝘸𝘢𝘺𝘴 𝘩𝘢𝘷𝘦 𝘵𝘰 𝘤𝘰𝘯𝘴𝘪𝘥𝘦𝘳 𝘣𝘦𝘧𝘰𝘳𝘦 𝘥𝘦𝘴𝘪𝘨𝘯𝘪𝘯𝘨 𝘢𝘯𝘺 𝘴𝘺𝘴𝘵𝘦𝘮 ↓
➔ 𝗗𝗮𝘁𝗮
- What data types do you have? (e.g., tabular data, images, text, etc.)
- What does the data look like? (e.g., for text data, is it in a single language or multiple?)
- How do you collect the data?
- At what frequency do you have to collect the data?
- How do you collect labels for the data? (crucial for how you plan to evaluate and monitor the model in production)
➔ 𝗧𝗵𝗿𝗼𝘂𝗴𝗵𝗽𝘂𝘁
- What are the throughput requirements? You must know at least the throughput's minimum, average, and maximum statistics.
- How many requests the system must handle simultaneously? (1, 10, 1k, 1 million, etc.)
➔ 𝗟𝗮𝘁𝗲𝗻𝗰𝘆
- What are the latency requirements? (1 millisecond, 10 milliseconds, 1 second, etc.)
- Throughput vs. latency trade-off
- Accuracy vs. speed trade-off
➔ 𝗜𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲
- Batch vs. real-time architecture (closely related to the throughput vs. latency trade-off)
- How should the system scale? (e.g., based on CPU workload, # of requests, queue size, data size, etc.)
- Cost requirements
.
Do you see how we shifted the focus from model performance towards how it is integrated into a more extensive system?
When building production-ready ML, the model's accuracy is no longer the holy grail but a bullet point in a grander scheme.
.
𝗧𝗼 𝘀𝘂𝗺𝗺𝗮𝗿𝗶𝘇𝗲, the 4 pillars to keep in mind before designing an ML architecture are:
- Data
- Throughput
- Latency
- Infrastructure
RAG: What problems does it solve, and how is it integrated into LLM-powered applications?
Let's find out ↓
RAG is a popular strategy when building LLMs to add external data to your prompt.
=== 𝗣𝗿𝗼𝗯𝗹𝗲𝗺 ===
Working with LLMs has 3 main issues:
1. The world moves fast
LLMs learn an internal knowledge base. However, the issue is that its knowledge is limited to its training dataset.
The world moves fast. New data flows on the internet every second. Thus, the model's knowledge base can quickly become obsolete.
One solution is to fine-tune the model every minute or day...
If you have some billions to spend around, go for it.
2. Hallucinations
An LLM is full of testosterone and likes to be blindly confident.
Even if the answer looks 100% legit, you can never fully trust it.
3. Lack of reference links
It is hard to trust the response of the LLM if we can't see the source of its decisions.
Especially for important decisions (e.g., health, financials)
=== 𝗦𝗼𝗹𝘂𝘁𝗶𝗼𝗻 ===
→ Surprize! It is RAG.
1. Avoid fine-tuning
Using RAG, you use the LLM as a reasoning engine and the external knowledge base as the main memory (e.g., vector DB).
The memory is volatile, so you can quickly introduce or remove data.
2. Avoid hallucinations
By forcing the LLM to answer solely based on the given context, the LLM will provide an answer as follows:
- use the external data to respond to the user's question if it contains the necessary insights
- "I don't know" if not
3. Add reference links
Using RAG, you can easily track the source of the data and highlight it to the user.
=== 𝗛𝗼𝘄 𝗱𝗼𝗲𝘀 𝗥𝗔𝗚 𝘄𝗼𝗿𝗸? ===
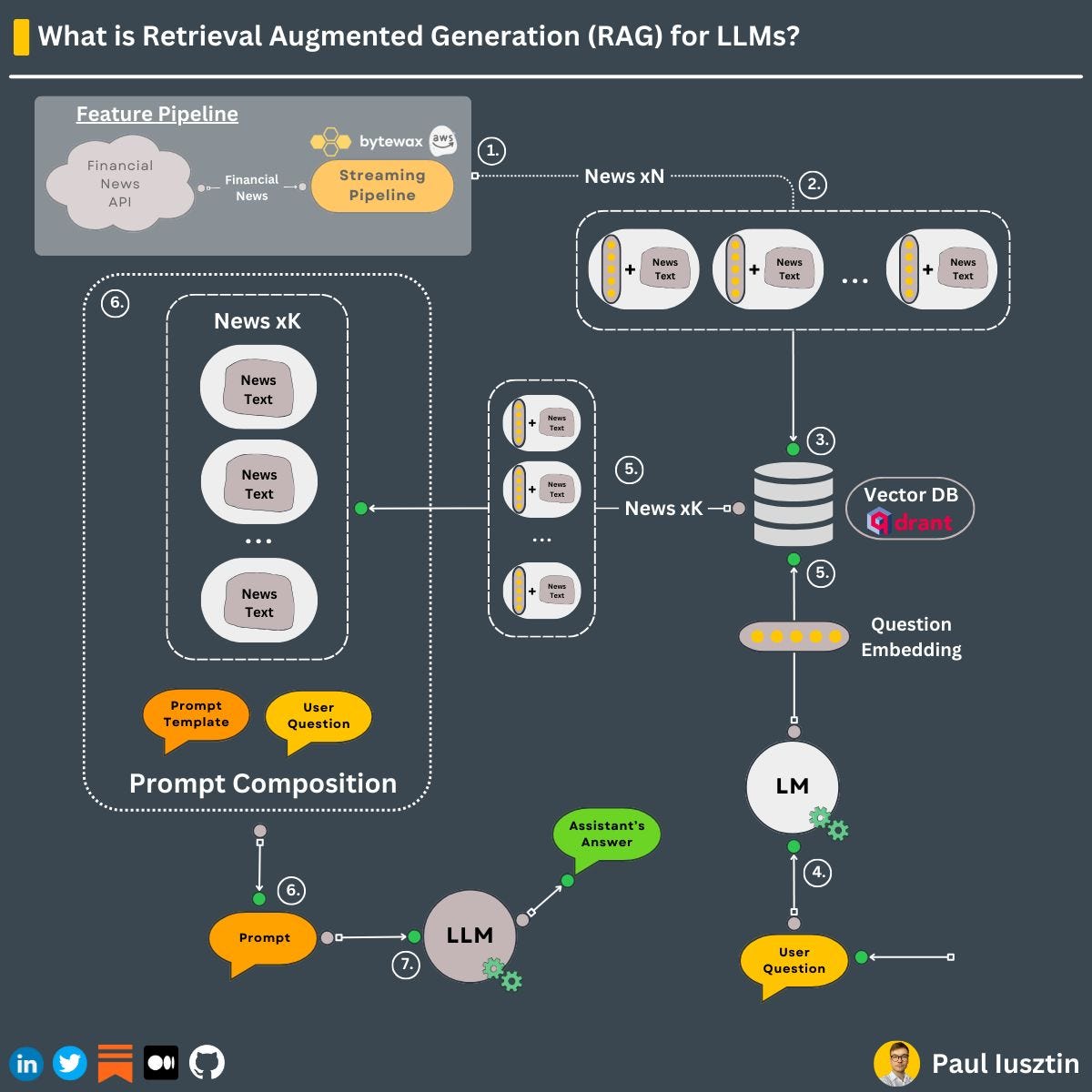
Let's say we want to use RAG to build a financial assistant.
𝘞𝘩𝘢𝘵 𝘥𝘰 𝘸𝘦 𝘯𝘦𝘦𝘥?
- a data source with historical and real-time financial news (e.g. Alpaca)
- a stream processing engine (eg. Bytewax)
- an encoder-only model for embedding the docs (e.g., pick one from `sentence-transformers`)
- a vector DB (e.g., Qdrant)
𝘏𝘰𝘸 𝘥𝘰𝘦𝘴 𝘪𝘵 𝘸𝘰𝘳𝘬?
↳ On the feature pipeline side:
1. using Bytewax, you ingest the financial news and clean them
2. you chunk the news documents and embed them
3. you insert the embedding of the docs along with their metadata (e.g., the initial text, source_url, etc.) to Qdrant
↳ On the inference pipeline side:
4. the user question is embedded (using the same embedding model)
5. using this embedding, you extract the top K most similar news documents from Qdrant
6. along with the user question, you inject the necessary metadata from the extracted top K documents into the prompt template (e.g., the text of documents & its source_url)
7. you pass the whole prompt to the LLM for the final answer
Excellent article Paul! Thank you so much for sharing 🙏