



Stop Building AI Agents
Here’s what you should build instead

Paul: Today, the scene is owned by Hugo, a brilliant mind who advises and teaches teams building LLM-powered systems, including engineers from Netflix, Meta, and the U.S. Air Force.
He runs a course on the LLM software development lifecycle, focusing on everything from retrieval and evaluation to agent design, and all the intermediate steps in between.
Enough talking, I’ll let him dig into today’s controversial topic: “Stop building AI agents”. ↓🎙️
P.S. I agree with him. 🤫
Hugo: I've taught and advised dozens of teams building LLM-powered systems. There's a common pattern I keep seeing, and honestly, it's frustrating.
Everyone reaches for agents first. They set up memory systems. They add routing logic. They create tool definitions and character backstories. It feels powerful and it feels like progress.
Until everything breaks. And when things go wrong (which they always do), nobody can figure out why.
Was it the agent forgetting its task? Is the wrong tool getting selected? Too many moving parts to debug? Is the whole system fundamentally brittle?
I learned this the hard way. Six months ago, I built a "research crew" with CrewAI: three agents, five tools, perfect coordination on paper. But in practice? The researcher ignored the web scraper, the summarizer forgot to use the citation tool And the coordinator gave up entirely when processing longer documents. It was a beautiful plan falling apart in spectacular ways.
This flowchart came from one of my lessons after debugging countless broken agent systems. Notice that tiny box at the end? That's how rarely you actually need agents. Yet everyone starts there.

This post is about what I learned from those failures, including how to avoid them entirely.
The patterns I'll walk through are inspired by Anthropic's Building Effective Agents post. But these aren't theory. This is real code, real failures, and real decisions I've made while teaching these systems. Every example here comes from actual projects I've built or debugged.
You'll discover why agents aren't the answer (most of the time). And more importantly, you'll learn what to build instead.
What You'll Learn:
Why agents are usually not the right first step
Five LLM workflow patterns that solve most problems
When agents are the right tool and how to build them safely
🔗 All examples come from this GitHub notebook
Don't Start with Agents
Everyone thinks agents are where you start. It's not their fault: frameworks make it seem easy, demo videos are exciting, and tech Twitter loves the hype.
But here's what I learned after building that CrewAI research crew: most agent systems break down from too much complexity, not too little.
In my demo, I had three agents working together:
A researcher agent that could browse web pages
A summarizer agent with access to citation tools
A coordinator agent that managed task delegation
Pretty standard stuff, right? Except in practice:
The researcher ignored the web scraper 70% of the time
The summarizer completely forgot to use citations when processing long documents
The coordinator threw up its hands when tasks weren't clearly defined
So wait: “What exactly is an agent?” To answer that, we need to look at 4 characteristics of LLM systems.
Memory: Let the LLM remember past interactions
Information Retrieval: Add RAG for context
Tool Usage: Give the LLM access to functions and APIs
Workflow Control: The LLM output controls which tools are used and when
^ This makes an agent

When people say "agent," they mean that last step: the LLM output controls the workflow. Most people skip straight to letting the LLM control the workflow without realizing that simpler patterns often work better. Using an agent means handing control to the LLM. But unless your task is so dynamic that its flow can’t be defined upfront, that kind of freedom usually hurts more than it helps. Most of the time, simpler workflows with humans in charge still outperform full-blown agents.
I've debugged this exact pattern with dozens of teams:
We have multiple tasks that need automation
Agents seem like the obvious solution
We build complex systems with roles and memory
Everything breaks because coordination is harder than we thought
We realize simpler patterns would have worked better
🔎 Takeaway: Start with simpler workflows like chaining or routing unless you know you need memory, delegation, and planning.
Workflow patterns you should use
These five patterns come from Anthropic's taxonomy – implemented, tested, and demoed in my notebook:
(1) Prompt Chaining
Use case: “Writing personalized outreach emails based on LinkedIn profiles.”
You want to reach out to people at companies you’re interested in. Start by extracting structured data from a LinkedIn profile (name, role, company), then generate a tailored outreach email to start a conversation.
Here are 3 simple steps:
Turn raw LinkedIn profile text into structured data (e.g., name, title, company):
linkedin_data = extract_structured_data(raw_profile)Add relevant company context for personalization (e.g., mission, open roles):
company_context = enrich_with_context(linkedin_data)Generate a personalized outreach email using the structured profile + company context:
email = generate_outreach_email(linkedin_data, company_context)Guidelines:
✅ Use when: Tasks flow sequentially
⚠️ Failure mode: Chain breaks if one step fails
💡 Simple to debug, predictable flow
(2) Parallelization
Use case: Extracting structured data from profiles
Now that chaining works, you want to process many profiles at once and speed up the processing. Split each profile into parts — like education, work history, and skills, then run extract_structured_data() in parallel.
Here are 2 simple steps:
Define tasks to extract key profile fields in parallel:
tasks = [
extract_work_history(profile), # Pull out work experience details
extract_skills(profile), # Identify listed skills
extract_education(profile) # Parse education background
]Run all tasks concurrently and gather results:
results = await asyncio.gather(*tasks)Guidelines:
✅ Use when: Independent tasks run faster concurrently
⚠️ Failure mode: Race conditions, timeout issues
💡 Great for data extraction across multiple sources
(3) Routing
Use case: LLM classifies the input and sends it to a specialized workflow
Say you’re building a support tool that handles product questions, billing issues, and refund requests. Routing logic classifies each message and sends it to the right workflow. If it’s unclear, fall back to a generic handler.
Here are 2 simple steps:
Choose a handler based on profile type:
if profile_type == "executive":
handler = executive_handler() # Use specialized logic for executives
elif profile_type == "recruiter":
handler = recruiter_handler() # Use recruiter-specific processing
else:
handler = default_handler() # Fallback for unknown or generic profilesProcess the profile with the selected handler:
result = handler.process(profile)Guidelines:
✅ Use when: Different inputs need different handling
⚠️ Failure mode: Edge cases fall through routes
💡 Add catch-all routes for unknowns
(4) Orchestrator-Worker
Use case: LLM breaks down the task into 1 or more dynamic steps
You’re generating outbound emails. The orchestrator classifies the target company as tech or non-tech, then delegates to a specialized worker that crafts the message for that context.
Here are 2 simple steps:
Use LLM to classify the profile as tech or non-tech:
industry = llm_classify(profile_text)Route to the appropriate worker based on classification:
if industry == "tech":
email = tech_worker(profile_text, email_routes)
else:
email = non_tech_worker(profile_text, email_routes)The orchestrator-worker pattern separates decision-making from execution:
The orchestrator controls the flow: its output controls what needs to happen and in what order
The workers carry out those steps: they handle specific tasks delegated to them
At first glance, this might resemble routing: a classifier picks a path, then a handler runs. But in routing, control is handed off entirely. In this example, the orchestrator retains control: it initiates the classification, selects the worker, and manages the flow from start to finish.
This is a minimal version of the orchestrator-worker pattern:
The orchestrator controls the flow, making decisions and coordinating subtasks
The workers carry out the specialized steps based on those decisions
You can scale this up with multiple workers, sequential steps, or aggregation logic (and I encourage you to! If you do so, make a PR to the repository), but the core structure stays the same.
Guidelines:
✅ Use when: Tasks need specialized handling
⚠️ Failure mode: Orchestrator delegates subtasks poorly or breaks down the task incorrectly
💡 Keep orchestrator logic simple and explicit
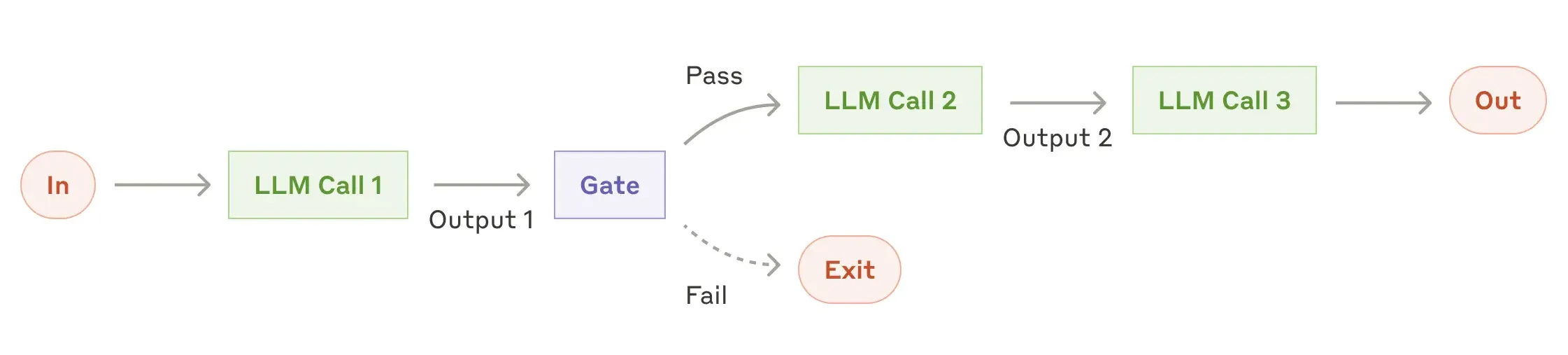
(5) Evaluator-Optimizer
Use case: Refining outreach emails to better match your criteria

You’ve got an email generator running, but want to improve tone, structure, or alignment. Add an evaluator that scores each message and, If it doesn’t pass, send it back to the generator with feedback and loop until it meets your bar.
Here are 2 simple steps:
Generate an initial email from the profile:
content = generate_email(profile)Loop until the email passes the evaluator or hits a retry limit:
while True:
score = evaluate_email(content)
if score.overall > 0.8 or score.iterations > 3:
break
content = optimize_email(content, score.feedback)Guidelines:
✅ Use when: Output quality matters more than speed
⚠️ Failure mode: Infinite optimization loops
💡 Set clear stop conditions
🔎 Takeaway: Most use cases don't need agents. They need better workflow structure.
When to Use Agents (If You Really Have To)
Agents shine when you have a sharp human in the loop. Here's my hot take: agents excel at unstable workflows where human oversight can catch and correct mistakes.
When agents actually work well:
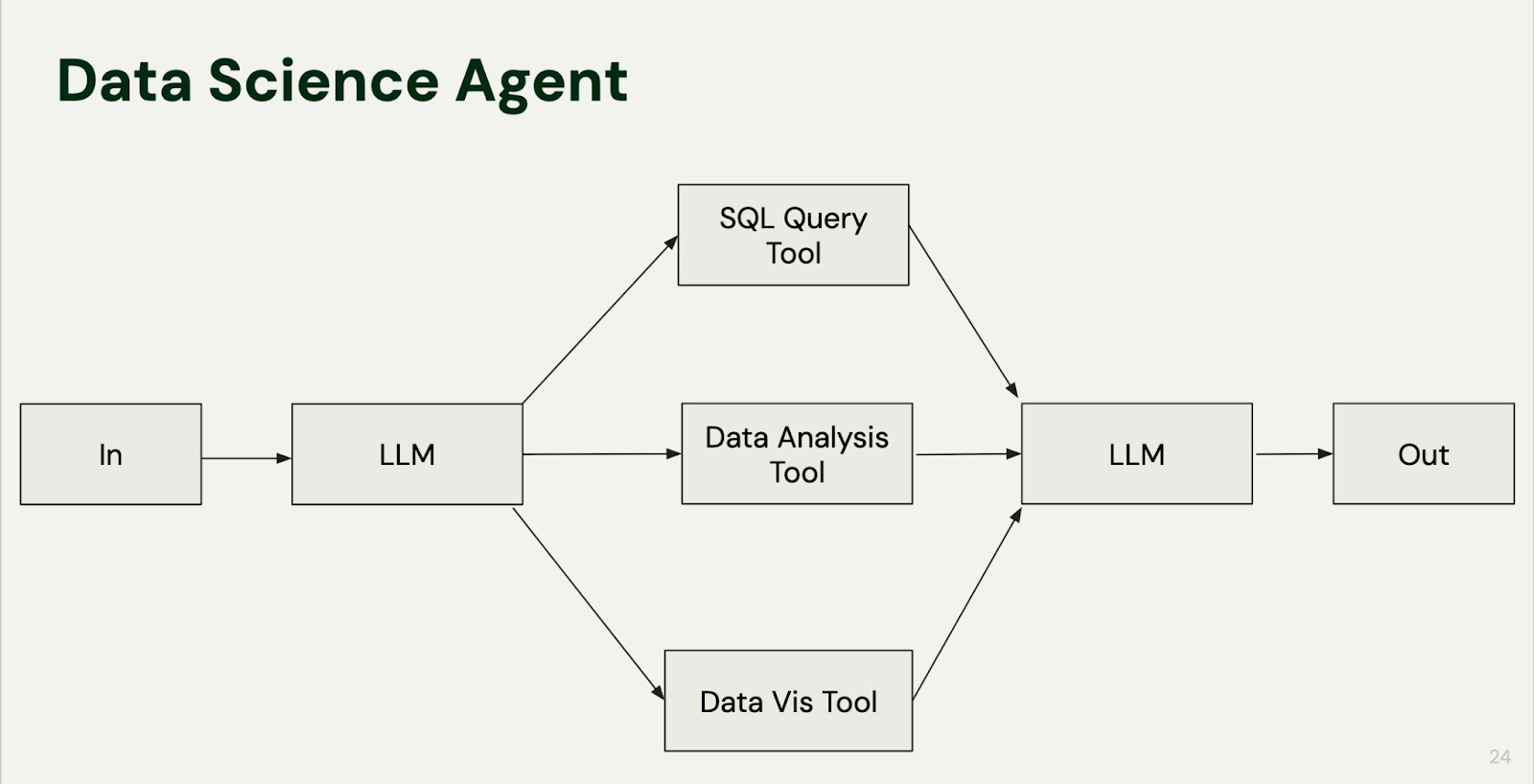
Example 1: Data Science Assistant
An agent that writes SQL queries, generates visualizations, and suggests analyses. You're there to evaluate results and fix logical errors. The agent's creativity in exploring data beats rigid workflows.
To build something like this, you’d give the LLM access to tools like run_sql_query(), plot_data(), and summarize_insights(). The agent routes between them based on the user’s request — for example, writing a query, running it, visualizing the result, and generating a narrative summary. Then, it feeds the result of each tool call back into another LLM request with its memory context. We walk through a live example of this pattern in our Building with LLMs course.
Example 2: Creative Writing Partner
An agent brainstorming headlines, editing copy, and suggesting structures. The human judges quality and redirects when needed. Agents excel at ideation with human judgment.
Example 3: Code Refactoring Assistant
Proposing design patterns, catching edge cases, and suggesting optimizations. The developer reviews and approves changes. Agents spot patterns humans miss.
When NOT to use agents
Enterprise Automation
Building stable, reliable software? Don't use agents. You can't have an LLM deciding critical workflows in production. Use orchestrator patterns instead.
High-Stakes Decisions
Financial transactions, medical diagnoses, and legal compliance – these need deterministic logic, not LLM guesswork.
Back to my CrewAI research crew: the agents kept forgetting goals and skipping tools. Here's what I learned:
Failure Point #1: Agents assumed they had context that they didn’t
Problem: Long documents caused the summarizer to forget citations entirely
What I'd do now: Use explicit memory systems, not just role prompts
Failure Point #2: Agents failed to select the right tools
Problem: The researcher ignored the web scraper in favor of a general search
What I'd do now: Constrain choices with explicit tool menus
Failure Point #3: Agents did not handle coordination well
Problem: The coordinator gave up when tasks weren't clearly scoped
What I'd do now: Build explicit handoff protocols, not free-form delegation
🔎 Takeaway: If you're building agents, treat them like full software systems. Don't skip observability.
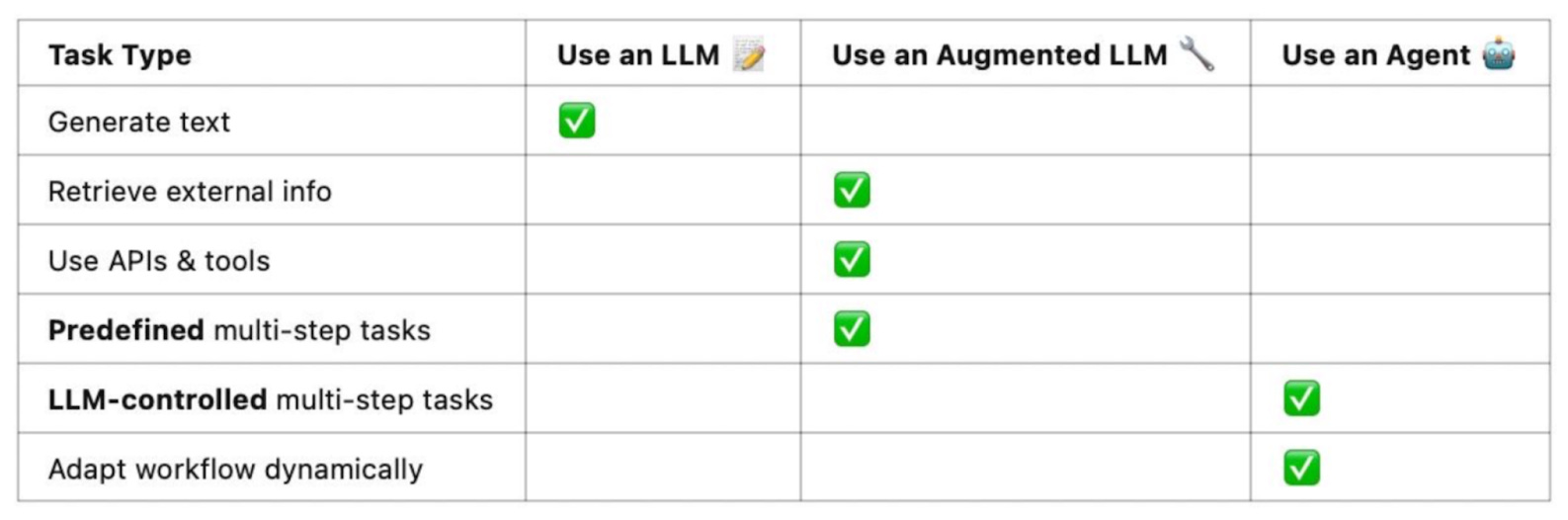
TL;DR
❌ Agents are overhyped and overused
🔁 Most cases need simple patterns, not agents
🤝 Agents excel in human-in-the-loop scenarios
⚠️ Don't use agents for stable enterprise systems
🧪 Build with observability and explicit control
Agents are overhyped and often overused. In most real-world applications, simple patterns and direct API calls work better than complex agent frameworks. Agents do have a role—in particular, they shine in human-in-the-loop scenarios where oversight and flexibility are needed. But for stable enterprise systems, they introduce unnecessary complexity and risk. Instead, aim to build with strong observability, clear evaluation loops, and explicit control.
Want to go deeper? I teach a course on the entire LLM software development lifecycle (use code PAULxMAVEN for $100 off), covering everything from retrieval and evaluation to observability, agents, and production workflows. It’s designed for engineers and teams who want to move fast without getting stuck in proof of concept purgatory.

If you’d like a taste of the full course, I’ve put together a free 10-part email series on building LLM-powered apps. It walks through practical strategies for escaping proof-of-concept purgatory: one clear, focused email at a time.

Copyrights: The article was originally published in collaboration with
on - original article.Images
If not otherwise stated, all images are created by the author.
 | A guest post by
|
Thanks for contributing to Decoding ML with this fantastic article, Hugo!
Great article, Hugo! I won’t hide it that I didn’t agree with everything what I was seeing in it, and had to re-read several times. For, all the workflow patterns of avoiding agent…are actually part of agent. You see, I come from “old” AI agents school (Peter Norvig, Stuart Russel et al) that assumes internal loop while having all the actuator, workflow, reasoning, sensors, all with continuous evaluations etc embedded.
Then this struck me “When people say "agent," they mean that last step: the LLM output controls the workflow. Most people skip straight to letting the LLM control the workflow without realizing that simpler patterns often work better.”
Ah, ok. If “most people”:
- can’t differentiate deterministic tasks from non-deterministic tasks
- have no clue that in true dynamic systems (including dynamic “workflow”) in order to achieve equilibrium you need to spawn millions of tasks/sub-agents to hope for actionable convergence, which is subject to energy conservation
- LLMs are nowhere close energy efficient
then, we are dealing with basic illiteracy these days. Btw Anthropic isn’t helping either by mindlessly promoting swarms of agents (hierarchical or not) as a hammer for every solution.
Thx for thought provoking post! 🙏