


The MLOps and GenAI World Conference (Sponsored)
The MLOps and GenaI World Conference is the place to be for the latest in MLOps & GenAI.

Here are some unique talks from the event:
- "Everything you need to know about fine-tuning" by Maxime Labonne from Liquid
- "Generative AI infrastructure at Lyft" by Konstantin Gizdarski from Lyft
- "Scaling vector DB usage without breaking the bank: Quantization and adaptive retrieval" by Zain Hasan from Weaviate
+40 other talks and workshops from people working at companies leading the GenAI and MLOps space, such as Modal Labs, Hugging Face, Grammarly, Mistral AI, MongoDB, AutoGPT and Netflix.
The conference will be hosted in Austin, Texas, starting November 7th. You can also follow it virtually!
This tutorial covers the diffusion process, walks you through training and inference, and showcases the latest use cases and advancements in Diffusion Models.
Could diffusion models be the next revolution in AI, or are they just the latest hype?
To find out, let’s break down what diffusion models are, how they work, and why they’re gaining so much attention in the AI community — so you can see for yourself if they’re truly worth the buzz.
By the end of this article, you’ll be equipped to:
Set up and train Unconditioned Image Generation Models
Understand the core concepts of the Diffusion Process
Explore real use cases and the latest advances in Diffusion Models
But before we dive into the technical details, let’s explore some real-world applications that showcase the true potential of diffusion models.
Imagine creating lifelike art from just a few words—that’s exactly what diffusion models do. For artists in fast-paced fields like film and gaming, these models are a game-changer, as they provide a quick starting point for their projects.

But how about taking it to the next level and animating these designs? Diffusion models aren’t just limited to static images; they’re also paving the way for rapid animation development.
After an artist creates a visual concept, tools like OpenAI’s Sora can generate frame-by-frame transitions, turning static images into animated sequences:
These are only a few real use cases of diffusion models, but their utility extends even further across various generative tasks:
Unconditional Image Generation: This task creates diverse images from pure noise, based entirely on the model's learned patterns.
Text-to-Image: By transforming text descriptions into visuals, this allows concepts to be quickly visualized from simple prompts.
Image-to-Image: This modifies existing images by applying styles or enhancing quality, perfect for style transfer or photo editing.
Inpainting: It fills in missing parts of an image, making it ideal for restoration and photo repair.
Text or Image-to-Video: This generates animated videos from text or images, useful for storytelling and media production.
Depth-to-Image: It creates detailed visuals based on depth maps, great for 3D effects in gaming and virtual reality.
Now that we've seen how versatile and powerful diffusion models are across various tasks, it's easy to see why they deserve our attention.
With a clear view of their real-world applications, let's dive deeper into understanding how they work.
Table of Contents
Introduction to Diffusion Models
The Diffusion Process
Training & Inference
Most Recent Advances
1. Introduction to Diffusion Models
Diffusion models have emerged as a compelling new approach in the world of generative AI, rapidly gaining attention for their ability to create high-quality images, animations, and even synthetic data.
But what exactly are diffusion models, and what makes them stand out in an already crowded field?
What They Are
At their core, diffusion models are probabilistic models that transform random noise into coherent data through a series of iterative steps. By reversing a gradual noising process, these models can generate realistic images, fill in missing data, and even convert text descriptions into visuals.
Why They Matter
Diffusion models can bring unique advantages over GANs and VAEs, which makes them a powerful alternative in generative AI:
High-Quality, Diverse Samples: Diffusion models produce realistic images with a broad range of variations, excelling in both detail and diversity.
Consistent Response to Input Changes: Diffusion models deliver stable, predictable outputs even when initial data varies, ensuring controlled and reliable results across different input scenarios.
Check out an overview on how they compare with GANs and VAEs:

2. The Diffusion Process
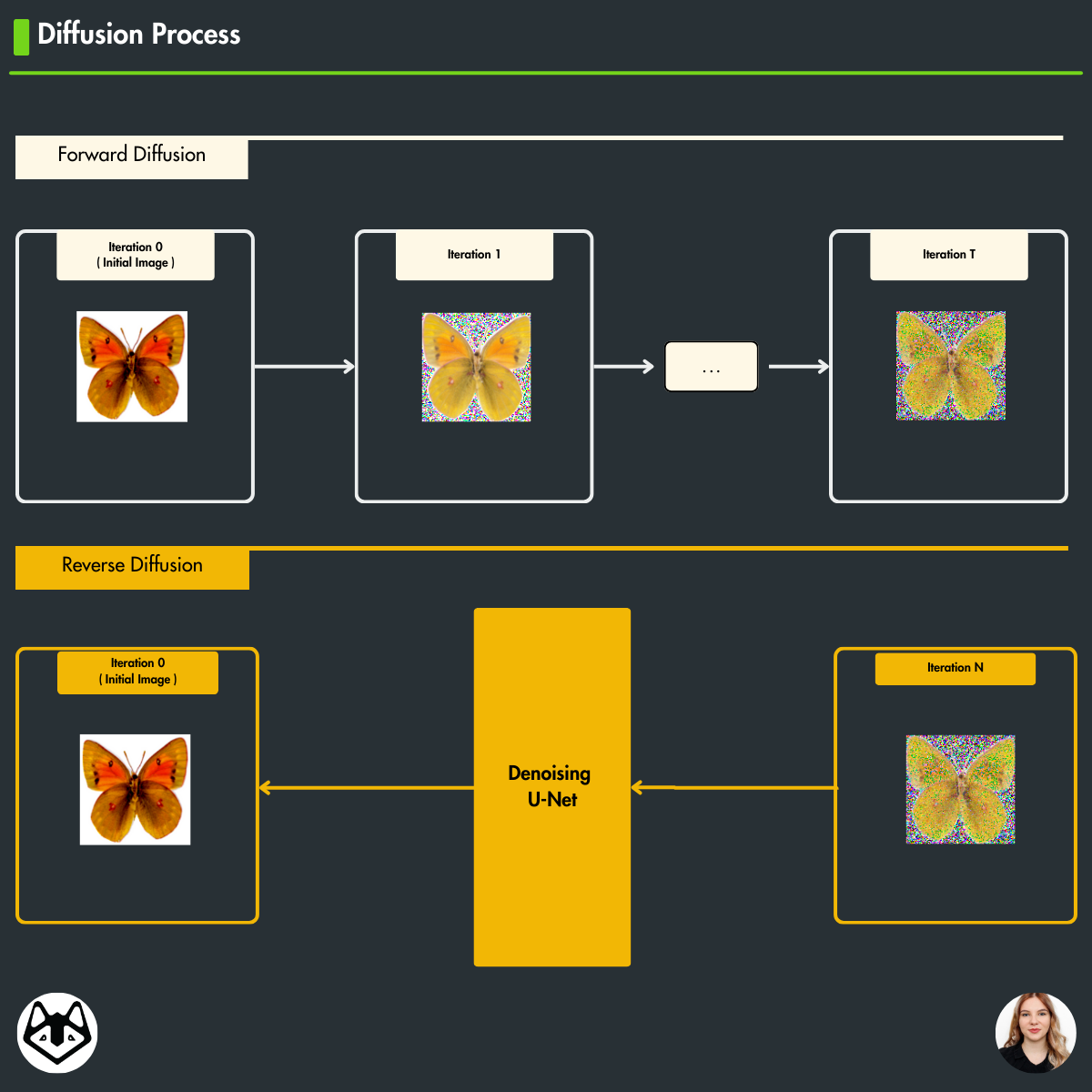
The core of diffusion models lies in their two-phase process: forward diffusion and backward diffusion.
Forward Diffusion: This phase involves adding noise to an image over several steps, gradually transforming it into random noise. Each step slightly distorts the original image, and by the end, it becomes almost unrecognizable.
Backward Diffusion: In this phase, the model uses a U-Net architecture to progressively remove noise, restoring the image from its noisy state back to a clear form. This is the generation stage where new, coherent images are created through step-by-step refinement.
Note: This explains the basic architecture of traditional diffusion models using a U-Net. We’ll later explore how this can be improved (hint: Transformers!) to further optimize feature extraction, representation, and image reconstruction.

Overview of the Diffusion Process
Beyond traditional diffusion models, the diffusion process can be adapted to suit specific data types and use cases:
Score-Based Models: Uses a score function to guide denoising by following gradients back to the original data distribution.
Latent Diffusion Models: Operate in a compressed space, reducing computational load, ideal for large-scale tasks.
Discrete Diffusion Models: Handle other types data which are discrete, adding noise by masking tokens, then denoising based on context—suitable for text and symbolic data.
Implicit Models: Model noise directly, skipping the noise adding steps to reduce computational cost and simplify training.
Evaluation Metrics
Diffusion models are assessed using the following standard metrics:
Frechet Inception Distance (FID): Compares generated and real image distributions, with lower scores meaning higher realism.
Inception Score (IS): Measures image quality and diversity, rewarding both realism and variety with a higher score.
Negative Log-Likelihood (NLL): Measures how well the model predicts the data's probability distribution, with lower scores indicating a closer match to the actual data and better reconstruction accuracy.
OpenAI also developed custom metrics for text-to-image tasks:
CLIP Score: This assesses how well the generated image matches the text prompt, with higher scores indicating better alignment and prompt understanding.
CLIP Directional Similarity: This measures consistency in image changes based on prompt adjustments, with higher scores reflecting accurate responses to input tweaks.
3. Training & Inference
3.1 Training Setup

At the core of training a diffusion model lie the noising and denoising steps. Let’s explore how to add noise to images using a scheduler:
noise = torch.randn(imgs.shape, device=imgs.device,dtype=imgs.dtype)
noisy_images = noise_scheduler.add_noise(imgs, noise, timesteps)Once the noise is added, we train the model by predicting the applied noise, calculating the loss, and backpropagating it to adjust the U-Net weights:
# predict the noise residual from the noisy images
noise_pred = model(noisy_images, timesteps, return_dict=False)[0]
loss = F.mse_loss(noise_pred, noise)
accelerator.backward(loss)
# gradient clipping and optimization step
accelerator.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
lr_scheduler.step()
# reset gradients for the next step
optimizer.zero_grad()Periodically, after a few epochs, we can evaluate the model by generating an image based on what it has learned during training:
generated_images = pipeline(
batch_size=config.eval_batch_size, generator=torch.Generator(device='cpu').manual_seed(config.seed),
).imagesAnd its quality can be measured by calculating the FID score:
fid_value = fid_score.calculate_fid_given_paths(
[reference_images_dir, generated_image_dir],
batch_size= config.eval_batch_size,
device=torch.device("cuda" if torch.cuda.is_available() else "cpu"), dims=2048,)Once the FID score reaches a low level and the image quality meets our expectations, we can upload the model to Hugging Face and run inference on it.
3.2 Inference Setup

Running inference on a Diffusion Model is quite straightforward and works similarly to other models hosted on Hugging Face. We simply load the diffusion model from the remote repository and call it:
pipeline = DDPMPipeline.from_pretrained(self.repo_name)
pipeline.to(self.device)
image = pipeline().images[0]Now, we can visualize the flower images generated using our model:

4. Latest Advances
Keeping up with rapid developments can be tough, so here’s a quick look at some cutting-edge diffusion models:
Diffusion Transformer (DiT) Models
Diffusion Transformers replace the traditional U-Net with a transformer-based architecture, capturing data relationships more accurately and improving output quality in complex scenes.
SORA: An example of a DiT model, SORA builds on DALL·E 3’s capabilities by transforming text into realistic video. It generates or extends videos up to a minute long and is expected to be publicly available soon.
Stable Diffusion 3: This iteration from Stability AI combines DiT with flow matching to improve image quality and responsiveness to prompts. It also includes safety features to ensure responsible usage, making it ideal for diverse applications.

Text-to-Image Generation with Stable Diffusion 3

Imagen 3
Google’s Imagen 3 takes photorealism to new heights with its latent diffusion approach. Now accessible on Google Gemini, Imagen 3 excels at interpreting detailed prompts, from text alignment to detailed textures, establishing itself as a leader in high-quality text-to-image generation.

Lumiere
Specializing in text-to-video, Lumiere uses a Space-Time U-Net to ensure smooth transitions and visual consistency. With capabilities in video stylization, inpainting, and more, it’s suited for creative storytelling and editing tasks, with further updates anticipated as the model evolves.

This post covered:
How the Diffusion Process works
Training & Inference for Unconditioned Image Generation
Practical Applications & The Latest Advancements in the field
Next steps
For more details on diffusion models, W&B, and Gradio, check out the full article:
To try out the code yourself, check out the complete code:
Images
If not otherwise stated, all images are created by the author.