

The Importance of Data Pipelines in the Era of Generative AI
From unstructured data crawling to structured valuable data

→ the 2nd out of 11 lessons of the LLM Twin free course
What is your LLM Twin? It is an AI character that writes like yourself by incorporating your style, personality, and voice into an LLM.

Why is this course different?
By finishing the “LLM Twin: Building Your Production-Ready AI Replica” free course, you will learn how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices.
Why should you care? 🫵
→ No more isolated scripts or Notebooks! Learn production ML by building and deploying an end-to-end production-grade LLM system.
More details on what you will learn within the LLM Twin course, here 👈
Latest Lessons of the LLM Twin Course
Lesson 1: An End-to-End Framework for Production-Ready LLM Systems by Building Your LLM Twin
LLM Twin Concept: Explaining what an LLM twin is and how it will function as a unique AI character.
3-Pipeline Architecture: Discuss the structure and benefits of this architectural approach.
System Design for LLM Twin: Diving into each component of the LLM twin's system design: Data Collection Pipeline, Feature Pipeline, Training Pipeline Inference Pipeline
Are you ready to build your AI replica? 🫢
Let’s start with Lesson 2 ↓↓↓
Lesson 2: The Importance of Data Pipelines in the Era of Generative AI
We have data everywhere. Linkedin, Medium, Github, Substack, and many other platforms.
To be able to build your Digital Twin, you need data.
Not all types of data, but organized, clean, and normalized data.
In this lesson we will learn how to think and build a data pipeline by aggregating data from:
Medium
Linkedin
Github
Substack
We will present all our architectural decisions regarding the design of the data collection pipeline for social media data and why separating raw data and feature data is essential.

Table of Contents
What is a data pipeline? The critical point in any AI project.
Data crawling. How to collect your data?
How do you store your data?
Cloud Infrastructure
Run everything
1. What is a data pipeline? The critical point in any AI project.
Data is the lifeblood of any successful AI project, and a well-engineered data pipeline is the key to harnessing its power.
This automated system acts as the engine, seamlessly moving data through various stages and transforming it from raw form into actionable insights.
But what exactly is a data pipeline, and why is it so critical?
A data pipeline is a series of automated steps that guide data on a purpose.
It starts with data collection, gathering information from diverse sources, such as LinkedIn, Medium, Substack, Github, etc.
The pipeline then tackles the raw data, performing cleaning and transformation.
This step removes inconsistencies and irrelevant information and transforms the data into a format suitable for analysis and ML models.
But why are data pipelines so crucial in AI projects? Here are some key reasons:
Efficiency and Automation: Manual data handling is slow and prone to errors. Pipelines automate the process, ensuring speed and accuracy, especially when dealing with massive data volumes.
Scalability: AI projects often grow in size and complexity. A well-designed pipeline can scale seamlessly, accommodating this growth without compromising performance.
2. Data crawling. How to collect your data?
The first step in building a database of relevant data is choosing our data sources. In this lesson, we will focus on four sources:
Linkedin
Medium
Github
Substack
Why do we choose 4 data sources? We need complexity and diversity in our data to build a powerful LLM twin. To obtain these characteristics, we will focus on building three collections of data:
Articles
Social Media Posts
Code
For the data crawling module, we will focus on two libraries:
BeautifulSoup: A Python library for parsing HTML and XML documents. It creates parse trees that help us extract the data quickly, but BeautifulSoup needs to fetch the web page for us. That’s why we need to use it alongside libraries like
requestsorSeleniumwhich can fetch the page for us.Selenium: A tool for automating web browsers. It’s used here to interact with web pages programmatically (like logging into LinkedIn, navigating through profiles, etc.). Selenium can work with various browsers, but this code configures it to work with Chrome. We created a base crawler class to respect the best software engineering practices.
As every platform is unique, we implemented a different Extract Transform Load (ETL) pipeline for each website.
However, the baseline steps are the same for each platform.
Thus, for each ETL pipeline, we can abstract away the following baseline steps:
log in using your credentials
use selenium to crawl your profile
use BeatifulSoup to parse the HTML
clean & normalize the extracted HTML
save the normalized (but still raw) data to Mongo DB
Important note: We are crawling only our data, as most platforms do not allow us to access other people’s data due to privacy issues. But this is perfect for us, as to build our LLM twin, we need only our own digital data.
3. How do you store your data?
Object Document Mapping (ODM) is a technique linking application object models with a document database, simplifying data storage and management.
It abstracts database interactions using specific model classes, like UserDocument and RepositoryDocument, to reflect and manage data structures in MongoDB effectively.
This approach benefits applications matching object-oriented programming styles, ensuring data consistency, validation, and easy retrieval in MongoDB.
class BaseDocument(BaseModel):
id: UUID4 = Field(default_factory=uuid.uuid4)
model_config = ConfigDict(from_attributes=True, populate_by_name=True)
@classmethod
def from_mongo(cls, data: dict):
"""Convert "_id" (str object) into "id" (UUID object)."""
def to_mongo(self, **kwargs) -> dict:
"""Convert "id" (UUID object) into "_id" (str object)."""
def save(self, **kwargs):
collection = _database[self._get_collection_name()]
@classmethod
def get_or_create(cls, **filter_options) -> Optional[str]:
collection = _database[cls._get_collection_name()]
@classmethod
def bulk_insert(cls, documents: List, **kwargs) -> Optional[List[str]]:
collection = _database[cls._get_collection_name()]
@classmethod
def _get_collection_name(cls):
if not hasattr(cls, "Settings") or not hasattr(cls.Settings, "name"):
raise ImproperlyConfigured(
"Document should define an Settings configuration class with the name of the collection."
)
return cls.Settings.name
class UserDocument(BaseDocument):
first_name: str
last_name: str
class Settings:
name = "users"
class RepositoryDocument(BaseDocument):
name: str
link: str
content: dict
owner_id: str = Field(alias="owner_id")
class Settings:
name = "repositories"
class PostDocument(BaseDocument):
platform: str
content: dict
author_id: str = Field(alias="author_id")
class Settings:
name = "posts"
class ArticleDocument(BaseDocument):
platform: str
link: str
content: dict
author_id: str = Field(alias="author_id")
class Settings:
name = "articles"4. Cloud Infrastructure
In this section, we will focus on how to constantly update our database with the most recent data from the 3 data sources.
Before diving into how to build the infrastructure of our data pipeline, I would like to show you how to “think” through the whole process before stepping into the details of AWS.
The first step in doing an infrastructure is to draw a high-level overview of my components.
So, the components of our data pipeline are:
Linkedin crawler
Medium crawler
Github crawler
Substack crawler
MongoDB (Data Collector)
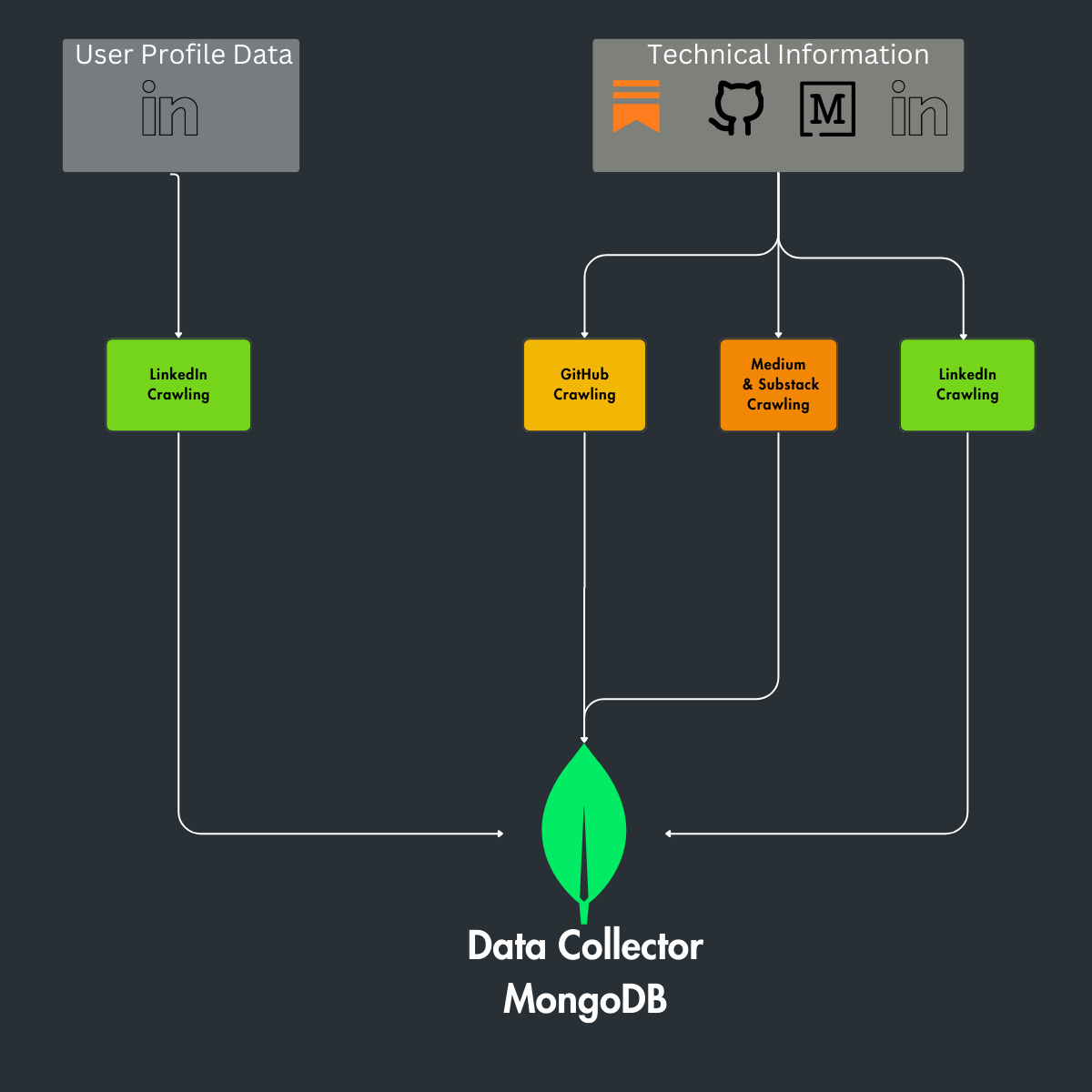
High-Level AWS Infrastructure [Image by the Author]

In our system, each data crawler is a Python file, with lambda functions representing these crawlers for seamless operation.
AWS Lambda, a serverless computing service, runs these functions without the need for server management. It's event-driven, scalable, and managed, making it ideal for handling tasks like data updates from platforms like LinkedIn or GitHub.
A 'handler' function in AWS Lambda is the key to deploying these crawlers. It acts as the trigger point for executing code based on specific events.
Next, we'll explore how to use this handler for effective deployment on AWS Lambda.
from aws_lambda_powertools import Logger
from aws_lambda_powertools.utilities.typing import LambdaContext
from crawlers import MediumCrawler, LinkedInCrawler, GithubCrawler
from dispatcher import CrawlerDispatcher
from documents import UserDocument
logger = Logger(service="decodingml/crawler")
_dispatcher = CrawlerDispatcher()
_dispatcher.register("medium", MediumCrawler)
_dispatcher.register("linkedin", LinkedInCrawler)
_dispatcher.register("github", GithubCrawler)
def handler(event, context: LambdaContext):
first_name, last_name = event.get('user').split(" ")
user = UserDocument.get_or_create(first_name=first_name, last_name=last_name)
link = event.get('link')
crawler = _dispatcher.get_crawler(link)
try:
crawler.extract(link=link, user=user)
return {"statusCode": 200, "body": "Articles processed successfully"}
except Exception as e:
return {"statusCode": 500, "body": f"An error occurred: {str(e)}"After you define what it means to transform your Python script into a valid AWS Lambda function, the next phase is to draw the diagram to understand the data flow and how the system will be triggered.

Each crawler function is tailored to its data source: fetching posts from LinkedIn, articles from Medium & Substack, and repository data from GitHub.
In order to trigger the lambda function, we have created a Python dispatcher, which is responsible for managing the crawlers for specific domains.
You can register crawlers for different domains and then use the get_crawler method to get the appropriate crawler for a given URL.
The lambda function can be triggered by invoking the function with a link payload.
aws lambda invoke \
--function-name crawler \
--cli-binary-format raw-in-base64-out \
--payload '{"user": "Paul Iuztin", "link": "https://github.com/iusztinpaul/hands-on-llms"}' \
response.jsonThe responsible crawler process its respective data and then pass it to the central Data Collector MongoDB.
The MongoDB component acts as a unified data store, collecting and managing the data harvested by the lambda functions.
This infrastructure is designed for efficient and scalable data extraction, transformation, and loading (ETL) from diverse sources into a single database.
5. Run everything
Cloud Deployment with GitHub Actions and AWS
In this final phase, we’ve established a streamlined deployment process using GitHub Actions. This setup automates the build and deployment of our entire system into AWS.
It’s a hands-off, efficient approach ensuring that every push to our .github folder triggers the necessary actions to maintain your system in the cloud.
You can delve into the specifics of our infrastructure-as-code (IaC) practices, particularly our use of Pulumi, in the ops folder within our GitHub repository.
This is a real-world example of modern DevOps practices, offering a peek into industry-standard methods for deploying and managing cloud infrastructure.
Local Testing and Running Options
We provide another alternative for those preferring a more hands-on approach or wishing to avoid cloud costs.
A detailed Makefile is included in our course materials, allowing you to configure and run the entire data pipeline locally effortlessly.
It’s especially useful for testing changes in a controlled environment or for those just starting with cloud services.
For an in-depth explanation and step-by-step instructions, please refer to the README in the GitHub repository.
Conclusion
This is the 2nd article of the LLM Twin: Building Your Production-Ready AI Replica free course.
In this article, we presented how to build a data pipeline and why it’s so important in an ML project:
🔻 Data collection process -> Medium, Github, Substack & Linkedin crawlers
🔻 ETL pipelines -> data is cleaned and normalized
🔻 ODM (Object Document Mapping ) -> a technique that maps between an object model in an application and a document database
🔻 NoSQL Database (MongoDB)
Tracks data changes, logs them, and queues messages for real-time system updates
The clean data is stored in a NoSQL database
🔗 Check out the code on GitHub [1] and support us with a ⭐️
This is how we can further help you 🫵
In the Decoding ML newsletter, we want to keep things short & sweet.
To dive deeper into all the concepts presented in this article…
Check out the full-fledged version of the article on our Medium publication.
↓↓↓