



The ultimate MLOps tool
6 steps to build your AWS infrastructure that will work for 90% of your projects. How to build a real-time news search engine

Decoding ML Notes
Based on your feedback from last week’s poll, we will post exclusively on Saturdays starting now.
Enjoy today’s article 🤗
This week’s topics:
The ultimate MLOps tool
6 steps to build your AWS infrastructure that will work for 90% of your projects
How to build a real-time news search engine
The ultimate MLOps tool
I tested this 𝗼𝗿𝗰𝗵𝗲𝘀𝘁𝗿𝗮𝘁𝗼𝗿 𝘁𝗼𝗼𝗹 for my 𝗠𝗟 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲𝘀 and 𝗹𝗼𝘃𝗲𝗱 𝗶𝘁! It is the 𝘂𝗹𝘁𝗶𝗺𝗮𝘁𝗲 𝗠𝗟𝗢𝗽𝘀 𝘁𝗼𝗼𝗹 to glue everything together for 𝗿𝗲𝗽𝗿𝗼𝗱𝘂𝗰𝗶𝗯𝗶𝗹𝗶𝘁𝘆 and 𝗰𝗼𝗻𝘁𝗶𝗻𝘂𝗼𝘂𝘀 𝘁𝗿𝗮𝗶𝗻𝗶𝗻𝗴.
In the past months, I have tested most of the top orchestrator tools out there: Airflow, Prefect, Argo, Kubeflow, Metaflow...
You name it!
𝗕𝘂𝘁 𝗼𝗻𝗲 𝘀𝘁𝗼𝗼𝗱 𝗼𝘂𝘁 𝘁𝗼 𝗺𝗲.
I am talking about ZenML!
𝗪𝗵𝘆?
They realized they don't have to compete with tools such as Airflow or AWS in the orchestrators and MLOps race, but join them!
Instead of being yet another orchestrator tool, they have built an 𝗮𝗯𝘀𝘁𝗿𝗮𝗰𝘁 𝗹𝗮𝘆𝗲𝗿 𝗼𝗻 𝘁𝗼𝗽 𝗼𝗳 𝘁𝗵𝗲 𝗠𝗟𝗢𝗽𝘀 𝗲𝗰𝗼𝘀𝘆𝘀𝘁𝗲𝗺:
- experiment trackers & model registries (e.g., Weights & Biases, Comet)
- orchestrators (e.g., Apache Airflow, Kubeflow)
- container registries for your Docker images
- model deployers (Hugging Face , BentoML, Seldon)
They wrote a clever wrapper that integrated the whole MLOps ecosystem!
𝘈𝘭𝘴𝘰, 𝘪𝘯𝘵𝘦𝘨𝘳𝘢𝘵𝘪𝘯𝘨 𝘪𝘵 𝘪𝘯𝘵𝘰 𝘺𝘰𝘶𝘳 𝘗𝘺𝘵𝘩𝘰𝘯 𝘤𝘰𝘥𝘦 𝘪𝘴 𝘯𝘰𝘵 𝘪𝘯𝘵𝘳𝘶𝘴𝘪𝘷𝘦.
As long your code is modular (which should be anyway), you have to annotate your DAG:
- steps with "Stephen S."
- entry point with james wang
𝘈𝘴 𝘺𝘰𝘶 𝘤𝘢𝘯 𝘴𝘦𝘦 𝘪𝘯 𝘵𝘩𝘦 𝘤𝘰𝘥𝘦 𝘴𝘯𝘪𝘱𝘱𝘦𝘵𝘴 𝘣𝘦𝘭𝘰𝘸 ↓

.

𝗧𝗵𝗲𝘆 𝗮𝗹𝘀𝗼 𝗽𝗿𝗼𝘃𝗶𝗱𝗲 𝘁𝗵𝗲 𝗰𝗼𝗻𝗰𝗲𝗽𝘁 𝗼𝗳 𝗮 "𝘀𝘁𝗮𝗰𝗸".
This allows you to configure multiple tools and infrastructure sets your pipeline can run on.
𝘍𝘰𝘳 𝘦𝘹𝘢𝘮𝘱𝘭𝘦:
- 𝘢 𝘭𝘰𝘤𝘢𝘭 𝘴𝘵𝘢𝘤𝘬: that uses a local orchestrator, artifact store, and compute for quick testing (so you don't have to set up other dependencies)
- 𝘢𝘯 𝘈𝘞𝘚 𝘴𝘵𝘢𝘤𝘬: that uses AWS SageMaker Orchestrator, Comet, and Seldon

As I am still learning ZenML, this was just an intro post to share my excitement.
I plan to integrate it into Decoding ML's LLM twin open-source project and share the process with you!
.
𝗠𝗲𝗮𝗻𝘄𝗵𝗶𝗹𝗲, 𝗰𝗼𝗻𝘀𝗶𝗱𝗲𝗿 𝗰𝗵𝗲𝗰𝗸𝗶𝗻𝗴 𝗼𝘂𝘁 𝘁𝗵𝗲𝗶𝗿 𝘀𝘁𝗮𝗿𝘁𝗲𝗿 𝗴𝘂𝗶𝗱𝗲 ↓
🔗 𝘚𝘵𝘢𝘳𝘵𝘦𝘥 𝘨𝘶𝘪𝘥𝘦: https://lnkd.in/dPzXHvjH
6 steps to build your AWS infrastructure that will work for 90% of your projects
𝟲 𝘀𝘁𝗲𝗽𝘀 to 𝗯𝘂𝗶𝗹𝗱 your 𝗔𝗪𝗦 𝗶𝗻𝗳𝗿𝗮𝘀𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 (using 𝗜𝗮𝗖) and a 𝗖𝗜/𝗖𝗗 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲 that will 𝘄𝗼𝗿𝗸 for 𝟵𝟬% of your 𝗽𝗿𝗼𝗷𝗲𝗰𝘁𝘀 ↓
We will use the data collection pipeline from our free digital twin course as an example, but it can easily be extrapolated to most of your projects.
𝘍𝘪𝘳𝘴𝘵, 𝘭𝘦𝘵'𝘴 𝘴𝘦𝘦 𝘸𝘩𝘢𝘵 𝘪𝘴 𝘪𝘯 𝘰𝘶𝘳 𝘵𝘰𝘰𝘭𝘣𝘦𝘭𝘵:
- Docker
- AWS ECR
- AWS Lambda
- MongoDB
- Pulumni
- GitHub Actions
𝘚𝘦𝘤𝘰𝘯𝘥𝘭𝘺, 𝘭𝘦𝘵'𝘴 𝘲𝘶𝘪𝘤𝘬𝘭𝘺 𝘶𝘯𝘥𝘦𝘳𝘴𝘵𝘢𝘯𝘥 𝘸𝘩𝘢𝘵 𝘵𝘩𝘦 𝘥𝘢𝘵𝘢 𝘤𝘰𝘭𝘭𝘦𝘤𝘵𝘪𝘰𝘯 𝘱𝘪𝘱𝘦𝘭𝘪𝘯𝘦 𝘪𝘴 𝘥𝘰𝘪𝘯𝘨
It automates your digital data collection from LinkedIn, Medium, Substack, and GitHub. The normalized data will be loaded into MongoDB.
𝘕𝘰𝘸, 𝘭𝘦𝘵'𝘴 𝘶𝘯𝘥𝘦𝘳𝘴𝘵𝘢𝘯𝘥 𝘩𝘰𝘸 𝘵𝘩𝘦 𝘈𝘞𝘚 𝘪𝘯𝘧𝘳𝘢𝘴𝘵𝘳𝘶𝘤𝘵𝘶𝘳𝘦 𝘢𝘯𝘥 𝘊𝘐/𝘊𝘋 𝘱𝘪𝘱𝘦𝘭𝘪𝘯𝘦 𝘸𝘰𝘳𝘬𝘴 ↓
1. We wrap the application's entry point with a `𝘩𝘢𝘯𝘥𝘭𝘦(𝘦𝘷𝘦𝘯𝘵, 𝘤𝘰𝘯𝘵𝘦𝘹𝘵: 𝘓𝘢𝘮𝘣𝘥𝘢𝘊𝘰𝘯𝘵𝘦𝘹𝘵)` function. The AWS Lambda serverless computing service will default to the `𝘩𝘢𝘯𝘥𝘭𝘦()` function.
2. Build a Docker image of your application inheriting the `𝘱𝘶𝘣𝘭𝘪𝘤.𝘦𝘤𝘳.𝘢𝘸𝘴/𝘭𝘢𝘮𝘣𝘥𝘢/𝘱𝘺𝘵𝘩𝘰𝘯:3.11` base Docker image
→ Now, you can quickly check your AWS Lambda function locally by making HTTP requests to your Docker container.
3. Use Pulumni IaC to create your AWS infrastructure programmatically:
- an ECR as your Docker registry
- an AWS Lambda service
- a MongoDB cluster
- the VPC for the whole infrastructure
4. Now that we have our Docker image and infrastructure, we can build our CI/CD pipeline using GitHub Actions. The first step is to build the Docker image inside the CI and push it to ECR when a new PR is merged into the main branch.
5. On the CD part, we will take the fresh Docker image from ECR and deploy it to AWS Lambda.
6. Repeat the same logic with the Pulumni code → Add a CD GitHub Action that updates the infrastructure whenever the IaC changes.
With 𝘁𝗵𝗶𝘀 𝗳𝗹𝗼𝘄, you will do fine for 𝟵𝟬% of your 𝗽𝗿𝗼𝗷𝗲𝗰𝘁𝘀 🔥
.
𝘛𝘰 𝘴𝘶𝘮𝘮𝘢𝘳𝘪𝘻𝘦, 𝘵𝘩𝘦 𝘊𝘐/𝘊𝘋 𝘸𝘪𝘭𝘭 𝘭𝘰𝘰𝘬 𝘭𝘪𝘬𝘦 𝘵𝘩𝘪𝘴:
feature PR -> merged to main -> build Docker image -> push to ECR -> deploy to AWS Lambda

𝗪𝗮𝗻𝘁 𝘁𝗼 𝗿𝘂𝗻 𝘁𝗵𝗲 𝗰𝗼𝗱𝗲 𝘆𝗼𝘂𝗿𝘀𝗲𝗹𝗳?
Consider checking out 𝗟𝗲𝘀𝘀𝗼𝗻 𝟮 from the FREE 𝗟𝗟𝗠 𝗧𝘄𝗶𝗻 𝗰𝗼𝘂𝗿𝘀𝗲 hosted by:
🔗 The Importance of Data Pipelines in the Era of Generative AI
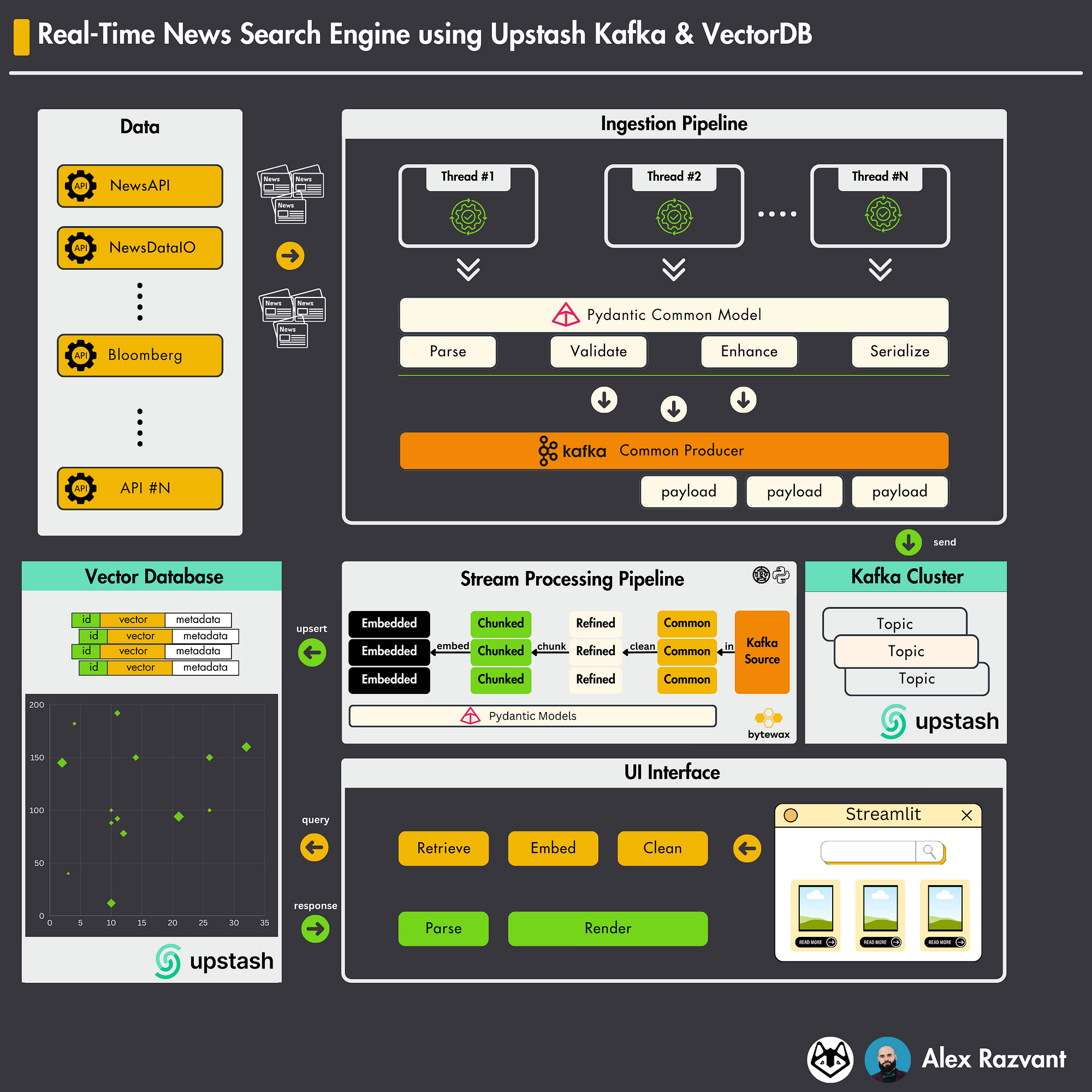
How to build a real-time news search engine
Decoding ML 𝗿𝗲𝗹𝗲𝗮𝘀𝗲𝗱 an 𝗮𝗿𝘁𝗶𝗰𝗹𝗲 & 𝗰𝗼𝗱𝗲 on building a 𝗥𝗲𝗮𝗹-𝘁𝗶𝗺𝗲 𝗡𝗲𝘄𝘀 𝗦𝗲𝗮𝗿𝗰𝗵 𝗘𝗻𝗴𝗶𝗻𝗲 using 𝗞𝗮𝗳𝗸𝗮, 𝗩𝗲𝗰𝘁𝗼𝗿 𝗗𝗕𝘀 and 𝘀𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 𝗲𝗻𝗴𝗶𝗻𝗲𝘀.
𝘌𝘷𝘦𝘳𝘺𝘵𝘩𝘪𝘯𝘨 𝘪𝘯 𝘗𝘺𝘵𝘩𝘰𝘯!
𝗧𝗵𝗲 𝗲𝗻𝗱 𝗴𝗼𝗮𝗹?
Learn to build a production-ready semantic search engine for news that is synced in real-time with multiple news sources using:
- a streaming engine
- Kafka
- a vector DB.
𝗧𝗵𝗲 𝗽𝗿𝗼𝗯𝗹𝗲𝗺?
According to a research study by earthweb.com, the daily influx of news articles, both online and offline, is between 2 and 3 million.
How would you constantly sync these data sources with your vector DB to stay in sync with the outside world?
𝗧𝗵𝗲 𝘀𝗼𝗹𝘂𝘁𝗶𝗼𝗻!
→ Here is where the streaming pipeline kicks in.
As soon as a new data point is available, it is:
- ingested
- processed
- loaded to a vector DB
...in real-time by the streaming pipeline ←
.
𝘏𝘦𝘳𝘦 𝘪𝘴 𝘸𝘩𝘢𝘵 𝘺𝘰𝘶 𝘸𝘪𝘭𝘭 𝘭𝘦𝘢𝘳𝘯 𝘧𝘳𝘰𝘮 𝘵𝘩𝘦 𝘢𝘳𝘵𝘪𝘤𝘭𝘦 ↓
→ Set up your own Upstash 𝗞𝗮𝗳𝗸𝗮 & 𝗩𝗲𝗰𝘁𝗼𝗿 𝗗𝗕 𝗰𝗹𝘂𝘀𝘁𝗲𝗿𝘀
→ 𝗦𝘁𝗿𝘂𝗰𝘁𝘂𝗿𝗲 & 𝘃𝗮𝗹𝗶𝗱𝗮𝘁𝗲 your 𝗱𝗮𝘁𝗮 points using Pydantic
→ 𝗦𝗶𝗺𝘂𝗹𝗮𝘁𝗲 multiple 𝗞𝗮𝗳𝗸𝗮 𝗖𝗹𝗶𝗲𝗻𝘁𝘀 using 𝘛𝘩𝘳𝘦𝘢𝘥𝘗𝘰𝘰𝘭𝘌𝘹𝘦𝘤𝘶𝘵𝘰𝘳 & 𝘒𝘢𝘧𝘬𝘢𝘗𝘳𝘰𝘥𝘶𝘤𝘦𝘳
→ 𝗦𝘁𝗿𝗲𝗮𝗺 𝗽𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴 using Bytewax - learn to 𝗯𝘂𝗶𝗹𝗱 𝗮 𝗿𝗲𝗮𝗹-𝘁𝗶𝗺𝗲 𝗥𝗔𝗚 ingestion 𝗽𝗶𝗽𝗲𝗹𝗶𝗻𝗲
→ 𝗕𝗮𝘁𝗰𝗵-𝘂𝗽𝘀𝗲𝗿𝘁𝗶𝗻𝗴 𝗲𝗺𝗯𝗲𝗱𝗱𝗶𝗻𝗴𝘀 + 𝗺𝗲𝘁𝗮𝗱𝗮𝘁𝗮 to Upstash Vector DB
→ Build a 𝗤&𝗔 𝗨I using Streamlit
→ 𝗨𝗻𝗶𝘁 𝗧𝗲𝘀𝘁𝗶𝗻𝗴 - Yes, we even added unit testing!
𝗖𝘂𝗿𝗶𝗼𝘂𝘀 𝘁𝗼 𝗹𝗲𝘃𝗲𝗹 𝘂𝗽 𝘆𝗼𝘂𝗿 𝗣𝘆𝘁𝗵𝗼𝗻, 𝘀𝘁𝗿𝗲𝗮𝗺𝗶𝗻𝗴 & 𝗥𝗔𝗚 𝗴𝗮𝗺𝗲 🫵
Then, consider checking out 𝘵𝘩𝘦 𝘢𝘳𝘵𝘪𝘤𝘭𝘦 & 𝘤𝘰𝘥𝘦. Everything is free.
↓↓↓
🔗 [Article] How to build a real-time News Search Engine using Vector DBs
Images
If not otherwise stated, all images are created by the author.