



Your model takes too long to do inference?
Compiling ML models. Running models in C++/Java/C#. Fastest Inference Engine out there.

Decoding ML Notes
Hey everyone, Happy Saturday!
We're sharing "DML Notes" every week.
This series offers quick summaries, helpful hints, and advice about Machine Learning & MLOps engineering in a short and easy-to-understand format.
Every Saturday, "DML Notes" will bring you a concise, easy-to-digest roundup of the most significant concepts and practices in MLE, GenAI, Deep Learning, and MLOps.
We aim to craft this series to enhance your understanding and keep you updated while respecting your time (2-3 minutes) and curiosity.
💬 Introducing DML Chat 💬
After DML Notes, the DML Chat is the second add-on that we’re excited about.
Our vision for it is to be a place where we can get in touch with you and answer all of your questions regarding the articles we’re posting, and the challenges you’re facing.
Apart from that, we’ll post short prompts, thoughts, the updates that come our way and you can jump into the discussion right away.
We’ll only allow subscribers who support our writing to initiate conversations as a measure of time management on our part.
Don’t worry, you can still follow the threads and learn from our awesome articles.😉The DML Team
This week’s topics:
TorchScript: How PyTorch models can be compiled for faster inference.
ONNXRuntime: Run optimized models in C++/Java/C#
TensorRT: Fastest framework to run Deep Learning / LLM models out there.
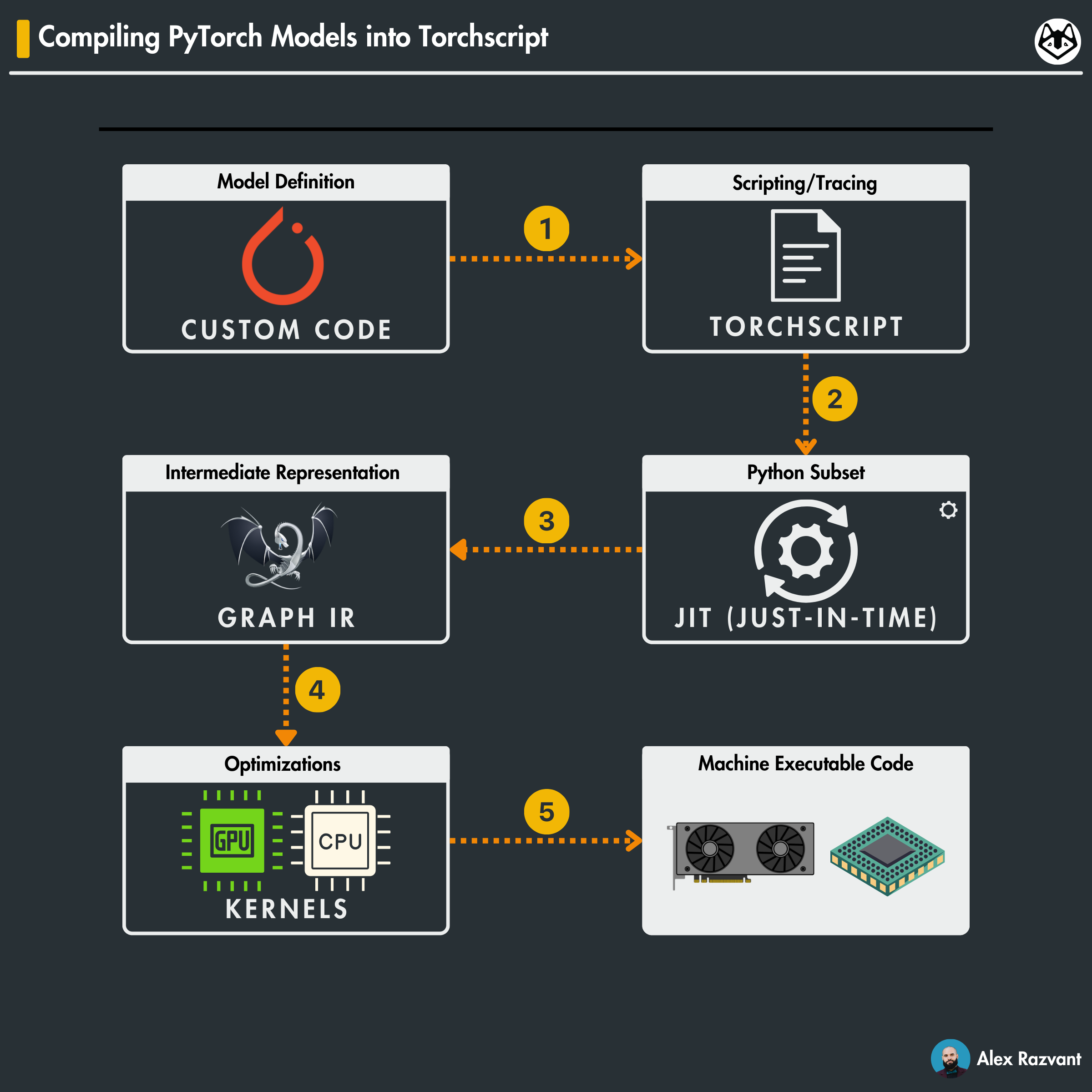
TorchScript: How PyTorch models can be compiled for faster inference.
Pytorch, by default runs in 𝗘𝗮𝗴𝗲𝗿 𝗠𝗼𝗱𝗲 with the AutoGrad, and the Python Interpreter can be plugged in quite easily to debug and iterate fast - but the inference mode is quite slow to be considered for production, this task is usually abstracted and 𝗵𝗮𝗻𝗱𝗹𝗲𝗱 𝗯𝘆 𝗮𝗻 𝗶𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲 𝗲𝗻𝗴𝗶𝗻𝗲 𝗼𝗿 𝗲𝘅𝗲𝗰𝘂𝘁𝗲𝗱 𝗱𝗶𝗿𝗲𝗰𝘁𝗹𝘆 𝗶𝗻 𝗖++.
Here’s the method of compiling a PyTorch model using 𝙏𝙤𝙧𝙘𝙝𝙎𝙘𝙧𝙞𝙥𝙩 + 𝙅𝙄𝙏 𝙘𝙤𝙢𝙥𝙞𝙡𝙚𝙧 𝙨𝙩𝙖𝙘𝙠.
𝙀𝙫𝙖𝙡𝙪𝙖𝙩𝙞𝙤𝙣 𝙈𝙤𝙙𝙚
This is a plain PyTorch model definition, the one we’re all familiar with, with .𝙚𝙫𝙖𝙡() mode set. Evaluation mode turns off AutoGrad computation, Dropout, and modifies Normalisation Layers.𝘾𝙤𝙣𝙫𝙚𝙧𝙩𝙞𝙣𝙜 𝙩𝙤 𝙏𝙤𝙧𝙘𝙝𝙎𝙘𝙧𝙞𝙥𝙩
Using the compiler stack, this can be done in two ways, by using either the scripting module or the tracing module.
Via 𝙨𝙘𝙧𝙞𝙥𝙩𝙞𝙣𝙜, you’re translating model code directly into TorchScript.
Via 𝙩𝙧𝙖𝙘𝙞𝙣𝙜, the tensor operations flow from the AutoGrad is recorded in a “𝗴𝗿𝗮𝗽𝗵”.𝙄𝙣𝙩𝙚𝙧𝙢𝙚𝙙𝙞𝙖𝙩𝙚 𝙍𝙚𝙥𝙧𝙚𝙨𝙚𝙣𝙩𝙖𝙩𝙞𝙤𝙣 (𝙄𝙍)
The TorchScript model is now in a language-agnostic format, detailing the computation graph for optimization to be consumed by the JIT.
The IR-generated code is statically typed and verbose such that it defines each instruction performed, much like Assembly code.𝙊𝙥𝙩𝙞𝙢𝙞𝙯𝙖𝙩𝙞𝙤𝙣𝙨
At this stage, the generated IR Graph is optimized through different tactics: - Constants folding - Removing redundancies - Considering specific kernels for the targeted hardware (GPU, TPU, CPU)𝙎𝙚𝙧𝙞𝙖𝙡𝙞𝙯𝙖𝙩𝙞𝙤𝙣
The last step is compilation and saving the model, such that you can de-serialize it in C++, define a tensor, populate it, feed-forward it, and process the outputs.
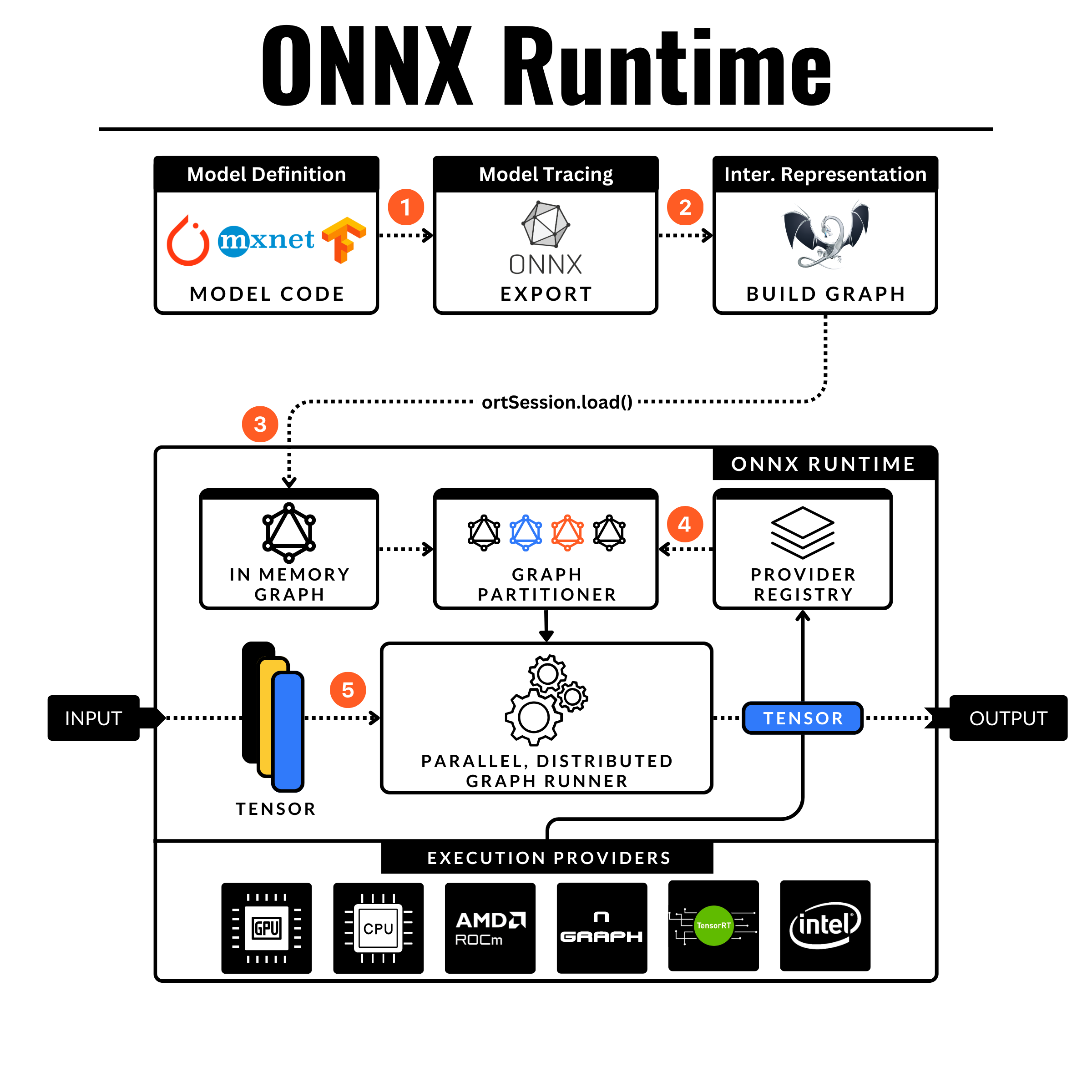
ONNXRuntime: Run optimized models in C++/Java/C#
ONNX Runtime is an open-source project that provides a performance-focused engine for ONNX (Open Neural Network Exchange) models. It enables models trained in various frameworks to be converted to the ONNX format and then efficiently run.
ONNX is a standard format to represent neural networks, the key stays in its IR (intermediate representation) format which is a “close-to-hardware” representation of the network such that other frameworks (PyTorch, TensorFlow, Caffe) can interop with it.
Here’s what happens under the hood:
𝗦𝗼𝘂𝗿𝗰𝗲 𝘁𝗼 𝗢𝗡𝗡𝗫
Assign .eval() mode, define in/out tensor names and shapes run onnx.export().𝗖𝗼𝗺𝗽𝘂𝘁𝗮𝘁𝗶𝗼𝗻𝗮𝗹 𝗚𝗿𝗮𝗽𝗵
On the forward pass, tensor operations are recorded.
A computational graph is constructed and the w + params are tied to their respective graph operations.
Then, they are converted to and mapped to ONNX operations.
The model now is in 𝙊𝙉𝙉𝙓 𝙄𝙍 𝙖𝙨 𝙖 𝙜𝙧𝙖𝙥𝙝 𝙤𝙛 𝙋𝙧𝙤𝙩𝙤 𝙤𝙗𝙟𝙚𝙘𝙩𝙨.𝗢𝗡𝗡𝗫 𝗥𝘂𝗻𝘁𝗶𝗺𝗲 (𝗢𝗥𝗧)
Loading the .onnx, the proto graph is parsed and converted to in-memory representation.𝗚𝗿𝗮𝗽𝗵 𝗢𝗽𝘁𝗶𝗺𝗶𝘇𝗮𝘁𝗶𝗼𝗻𝘀
Given a selected execution provider (CUDA, CPU) the ORT applies a series of provider-independent optimizations.
These are divided into 3 levels:
→ L1 Basic (Nodes folding)
→ L2 Extended (GELU, MatMul Fusion)
→ L3 Layout (CPU only, NCHW to NCHWc)𝗣𝗮𝗿𝘁𝗶𝘁𝗶𝗼𝗻𝗶𝗻𝗴 𝘁𝗵𝗲 𝗚𝗿𝗮𝗽𝗵
This process splits the graph into a set of subgraphs based on the available Execution Providers.
Since ORT can run parallel/distributed sub-graphs, here's a performance boost.𝗔𝘀𝘀𝗶𝗴𝗻 𝗦𝘂𝗯𝗴𝗿𝗮𝗽𝗵𝘀 = Each subgraph is reduced to a single fused operator, using the provider's 𝘾𝙤𝙢𝙥𝙞𝙡𝙚() that wraps it as a custom operator, also called 𝙆𝙚𝙧𝙣𝙚𝙡. CPU is the default provider and is used as a fallback measure.
𝗜𝗻𝗳𝗲𝗿𝗲𝗻𝗰𝗲
The created engine can then be used for inference.
𝙏𝙝𝙚 𝙘𝙧𝙚𝙖𝙩𝙚𝙙 𝙠𝙚𝙧𝙣𝙚𝙡𝙨 𝙥𝙧𝙤𝙘𝙚𝙨𝙨 𝙩𝙝𝙚 𝙧𝙚𝙘𝙚𝙞𝙫𝙚𝙙 data according to the defined Graph order of subgraphs and yield the outputs that can be further processed.
TensorRT: Fastest inference framework for Deep Learning / LLMs out there.
TensorRT is NVIDIA's high-performance deep learning inference optimizer and runtime library for production environments.
It's designed to accelerate deep learning inference on NVIDIA GPUs, providing lower latency and higher throughput for deep learning applications.
Apart from specific hardware (e.g Groq LPUs) optimized for matmul in transformers, TensorRT provides fastest inference times on all Deep Learning model architectures, including Transformers and LLM’s.
Here’s what happens when converting a model from ONNX to a TensorRT engine:
Parsing:
The first step involves parsing the ONNX model file.
TensorRT's parser supports ONNX models and interprets the various layers, weights, and inputs defined in the ONNX format.
This step translates the high-level network definition into an internal representation that TensorRT can work with.Layer Fusion:
TensorRT performs layer fusion optimizations during this phase.
It combines multiple layers and operations into a single, more efficient kernel. This reduces the overhead of launching multiple kernels and improves the execution speed of the network.Precision Calibration:
TensorRT offers precision calibration to optimize model execution.
It can convert floating-point operations (like FP32) into lower precision operations (like FP16 or INT8) to increase inference speed.
During this step, TensorRT ensures that the precision reduction does not significantly impact the accuracy of the model.Kernel Autotuning:
TensorRT selects the most efficient algorithms and kernels for the target GPU architecture.
It evaluates various implementation strategies for each layer of the network on the specific hardware and selects the fastest option.Memory Optimization:
TensorRT optimizes memory usage by analyzing the network's graph to minimize memory footprint during inference.
It reuses memory between layers when possible and allocates memory efficiently for both weights and intermediate tensors.Serialization:
Once the model has been optimized, TensorRT serializes the optimized network into an engine file.
This engine file is a binary representation of the optimized model.
It can be loaded and executed on compatible NVIDIA GPUs for inference.Inference:
The final step is running inference with the TensorRT engine.
The application loads the serialized engine file, prepares the input data, and executes the model to obtain predictions.
TensorRT engines are designed for high-performance inference, significantly reducing latency and increasing throughput compared to running the original ONNX model directly.