


I hope that the title has already made you curious.
Today’s article is about how we should -at least try- to understand complex concepts, get into details, and not be scared about possible errors.
Deploying Large Language Models (LLMs) can become complicated, especially when considering approaches such as AWS Sagemaker with Huggingface DLC, AWS Sagemaker with native AWS containers, or direct deployment on EC2 instances.
This week’s topics:
The Real Challenges in the AWS Sagemaker Production-Ready Environment
Sagemaker inference endpoint components
Hands-on code of multi-replica endpoints deployment Mistral-7b-v0.1
Cleaning Sagemaker Resources
Now that I’ve spoiled you with 4 titanic subjects, let’s talk about how the deployment process of Large Language Models(LLMs) may seem extremely simple.
In practice, we can choose between 2 methods:
To deploy our docker images to cloud providers like AWS and try to manage the entire deployment process with EC2
AWS Sagemaker with HuggingFace dockers
The process of deployment is presented like this: choose what LLM you want to deploy, create an endpoint configuration, create a model, create an endpoint, and voilà! You have a model running in the AWS Sagemaker ecosystem, which can be invoked via a URL.
The truth is…It is not that straightforward.
Now you know, this is what we will discuss in today’s newsletter: decode the complex task of deploying a private LLM via AWS Sagemaker and Huggingface, ready to scale to thousands of users.
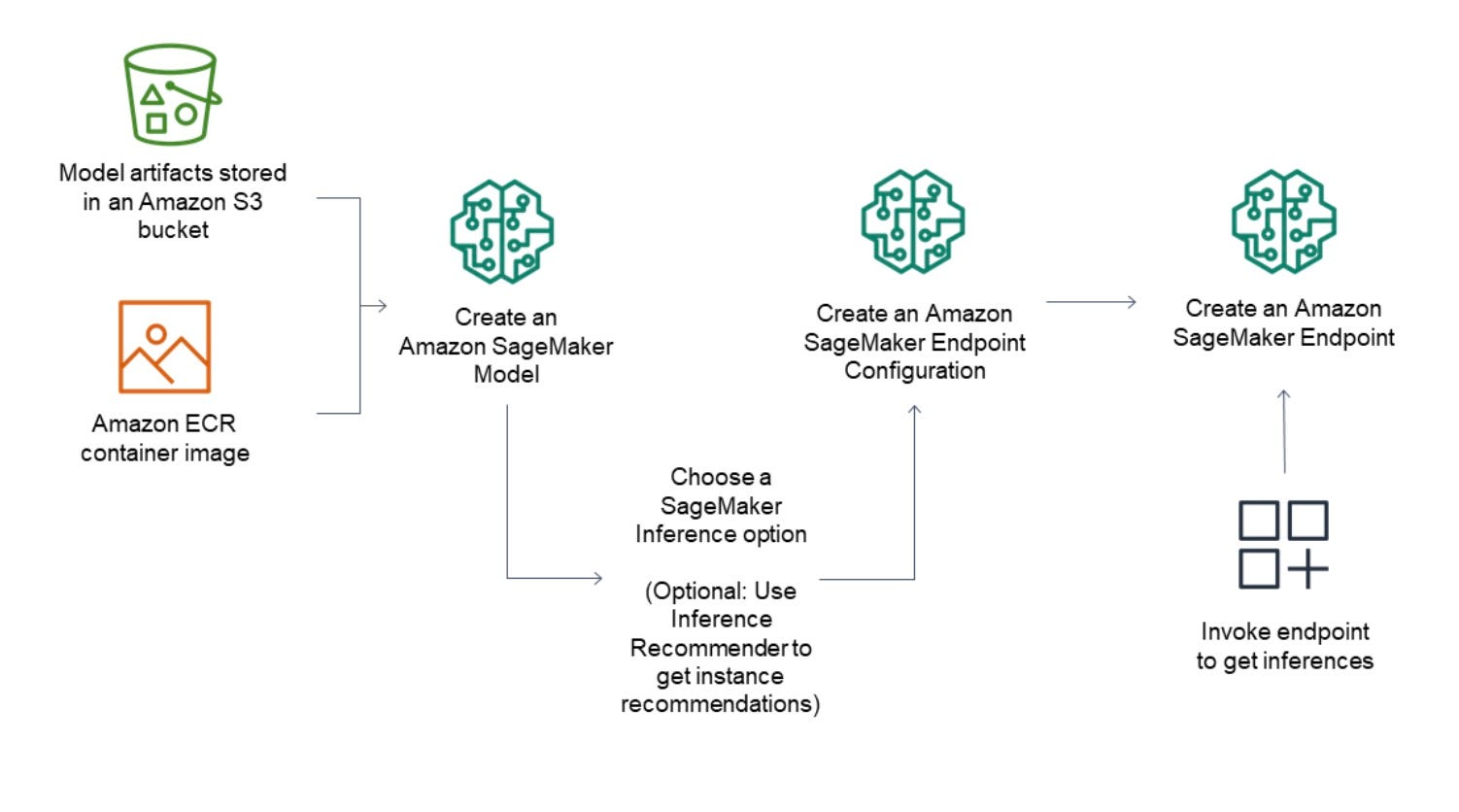
1. The Real Challenges in Aws Sagemaker Production-Ready Environment
At this year's re: Invent (2023), a significant announcement for Amazon SageMaker was the introduction of the new Hardware Requirements object for its endpoints.
This feature enables detailed control over the deployment's computing resources, including the minimum requirements for CPU, GPU, memory, and the number of replicas.
It enhances the ability to fine-tune the performance and cost-effectiveness of models by aligning computing resources with the model's needs.
Additionally, it facilitates the deployment of multiple large language models (LLMs) on a single instance. Before this update, deploying multiple instances or LLMs on a single endpoint was not feasible, which could restrict the maximum throughput of models not limited by computing resources, such as deploying a single Mistral 7B model on g5.12xlarge instances.
But let’s back to the foundation of deploying an AI model on the cloud. What are the basic questions we need to ask ourselves before trying some new complicated models?
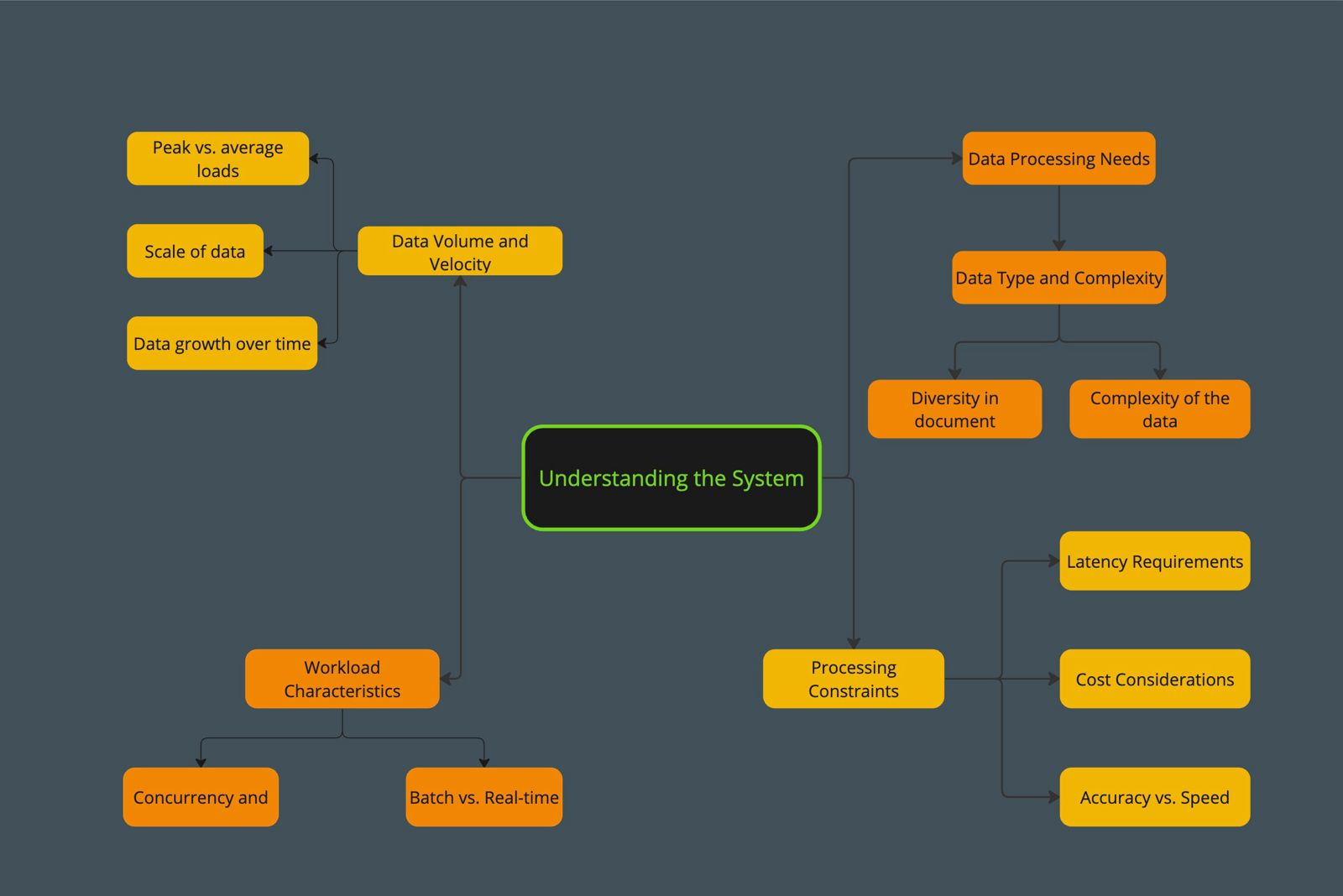
Understanding the System: Key Considerations
To truly understand the system's requirements and constraints, it's essential to go deeper into several critical areas:
Data Processing Needs
Data Type and Complexity: Beyond just identifying the data as document data, consider the diversity in document formats (e.g., PDF, Word, text) and the complexity of the data (e.g., languages, domains, embedded images). This affects preprocessing needs and the choice of model.
Data Volume and Velocity: Understanding the scale (e.g., 2 million documents/day) is just the start. Consider peak vs. average loads and data growth over time. This influences infrastructure scalability and cost management strategies.
Workload Characteristics
Batch vs. Real-time Processing: Determine whether the system processes data in real-time or in batches. Real-time systems require low-latency responses, impacting how you configure the SageMaker endpoint (e.g., instance types, auto-scaling).
Concurrency and Parallelism: Assess how many requests the system must handle simultaneously. This affects the decision on the number of instances and the type of instances (e.g., compute-optimized vs. memory-optimized).
Processing Constraints and Requirements
Latency Requirements: Specify the acceptable response time for your system. Low-latency requirements might necessitate more powerful computing resources or optimizing your model for faster inference.
Accuracy vs. Speed Trade-off: Decide on the balance between inference accuracy and speed. Higher accuracy models may be slower and more resource-intensive, impacting your deployment strategy.
Cost Considerations: Budget constraints will influence your choice of instance types, the number of instances, and the use of spot instances. Cost optimization strategies, like using multi-model endpoints or scheduling auto-scaling based on load, become crucial.
Scalability and Flexibility
Scaling Strategy: Plan for scaling both the infrastructure and the model. AWS SageMaker's auto-scaling and the new Hardware Requirements object allow for dynamic adjustment based on workload.
Flexibility for Future Expansion: Consider how easily new models or updated versions can be deployed without significant downtime or reconfiguration. This includes the ability to test models in production via A/B testing or shadow testing.

A framework of understanding a system
2. Sagemaker inference endpoint components
In this article, we explore using the SageMaker SDK and the ResourceRequirements object to effectively deploy Mistral 7B, enhancing both throughput and cost efficiency on Amazon SageMaker using a g5.12xlarge instance.
The g5.12xlarge instance, equipped with 4x NVIDIA A10G GPUs, enables us to deploy multiple replicas of Mistral 7B on a single machine.
Moreover, the flexibility of this method allows for the deployment of multiple models on a single instance—for instance, combining 2x Llama 7B with 2x Mistral 7B.
Leveraging the Hugging Face LLM Deep Learning Container (DLC), a specially designed Inference Container, simplifies the deployment of LLMs within a secure and managed ecosystem.
This DLC is driven by Text Generation Inference (TGI), a scalable and optimized framework for efficiently deploying and serving Large Language Models.
From my understanding, every Sagemaker inference deployment must be composed of the following elements:
Sagemaker Endpoint: An endpoint is a scalable and secure API that SageMaker hosts to enable real-time predictions from deployed models. It's essentially the interface through which applications interact with your model.
Usage: Once deployed, an application can make HTTP requests to the endpoint to receive real-time predictions.
Sagemaker Model: In SageMaker, a model is an artifact that results from training an algorithm. It contains the information necessary to make predictions, including the weights and computation logic.
Usage: You can create multiple models and use them in different configurations or for different types of predictions
Sagemaker Configuration: This configuration specifies the hardware and software setup needed to host the model. It defines the resources required for the endpoint, such as the type and number of ML compute instances.
Usage: Endpoint configurations are used when creating or updating an endpoint. They allow for flexibility in deployment and scalability of the hosted models.
Sagemaker Inference Component: In SageMaker, the hosting object allows for seamless model deployment to endpoints, where you define the model, its endpoint, and resource management strategies in the inference settings. You can deploy multiple models to an endpoint, each with its resource configuration. Once deployed, models are easily accessible via the InvokeEndpoint API, streamlining the process and ensuring efficient resource use.
Behind the scenes, Huggingface, under their llm.deploy method creates all the above components:
2024-02-14 20:52:58,689 - INFO - Starting deployment using Sagemaker Huggingface Strategy...
2024-02-14 20:52:58,915 - INFO - Endpoint configuration 'dev-v1-llm-endpoint' does not exist.
2024-02-14 20:52:58,915 - INFO - Endpoint configuration dev-v1-llm-endpoint does not exist.
2024-02-14 20:52:59,130 - INFO - Endpoint dev-v1-llm-endpoint does not exist. Creating...
2024-02-14 20:52:59,979 - INFO - Creating model with name: huggingface-pytorch-tgi-inference-2024-02-14-18-52-59-976
2024-02-14 20:53:00,630 - INFO - Creating endpoint-config with name dev-v1-llm-endpoint
2024-02-14 21:00:38,645 - INFO - Creating inference component with name huggingface-pytorch-tgi-inference-2024-02-14-19-1707937238-ef61 for endpoint dev-v1-llm-endpoint
3. Hands-on code of multi-replica endpoints deployment Mistral-7b-v0.1
SageMaker's multi-model endpoints offer a dynamic and efficient way to manage and serve multiple models.
SageMaker dynamically manages model lifecycles on multi-model endpoints, loading models on demand.
Invocation process:
Routes request to an instance.
Downloads the model from S3 to instance storage.
Loads the model into the container's memory (CPU or GPU-based).
Faster invocation for models already in memory; no need to re-download or load.
SageMaker routes additional requests to other instances if one is overloaded, downloading and loading the model there if not already present.
Manages memory by unloading unused models to free up space for new ones. Unloaded models stay on storage for later access without re-downloading.
Models can be added or removed by managing them in the S3 bucket without updating the endpoint.
Note on updates: Initial requests may see higher latencies as SageMaker adapts, but frequently used models will eventually experience lower latencies. Less used models may have cold start latencies.

Step 1: Configure Hardware requirements per replica
Below is an example configuration for Mistral 7B. We will use the new feature from Sagemaker, ResourceRequirements to define how many replicas want and how much memory is allocated.
config.py
import json
from sagemaker.compute_resource_requirements.resource_requirements import (
ResourceRequirements,
)
model_resource_config = ResourceRequirements(
requests={
"copies": 4, # Number of replicas
"num_accelerators": 1, # Number of GPUs
"num_cpus": 8, # Number of CPU cores 96 // num_replica - more for management
"memory": 5 * 1024, # Minimum memory in MB 1152 // num_replica - more for management
},
)
hugging_face_deploy_config = {
"HF_MODEL_ID": settings.HF_MODEL_ID,
"SM_NUM_GPUS": json.dumps(settings.SM_NUM_GPUS), # Number of GPU used per replica
"MAX_INPUT_LENGTH": json.dumps(settings.MAX_INPUT_LENGTH), # Max length of input text
"MAX_TOTAL_TOKENS": json.dumps(settings.MAX_TOTAL_TOKENS), # Max length of the generation (including input text)
"MAX_BATCH_TOTAL_TOKENS": json.dumps(settings.MAX_BATCH_TOTAL_TOKENS),
"HUGGING_FACE_HUB_TOKEN": settings.HUGGING_FACE_HUB_TOKEN,
}
Step 2: Prepare a Deployment Service Class
The DeploymentService class is designed to facilitate the deployment of machine learning models, particularly HuggingFace models, to AWS SageMaker. It encapsulates the process into simpler methods, handling resource management, logging, and the deployment process.
The most important part of this class is the following code block:
huggingface_model = HuggingFaceModel(role=role_arn, image_uri=llm_image, env=config)
# Deploy or update the model based on the endpoint existence
huggingface_model.deploy(
instance_type=settings.GPU_INSTANCE_TYPE,
initial_instance_count=1,
endpoint_name=endpoint_name,
update_endpoint=update_endpoint,
resources=resources,
tags=[{"Key": "task", "Value": "model_task"}],
endpoint_type=endpoint_type,
)
The endpoint_type parameter is one of the most important parameters in this class. It can be:
EndpointType.MODEL_BASED - without inference-components
EndpointType.
INFERENCE_COMPONENT- with inference-component
To be able to scale the SageMaker endpoint to handle thousands of requests it’s mandatory to have EndpointType.INFERENCE_COMPONENT.
In our model_resource_config we have copies=4, which means 4 replicas of our endpoint. If we check the cloud watch logs group ‘aws/sagemaker/InferenceComponents/your-inference-component-name, you should see 4 log streams, which represent the replicas.
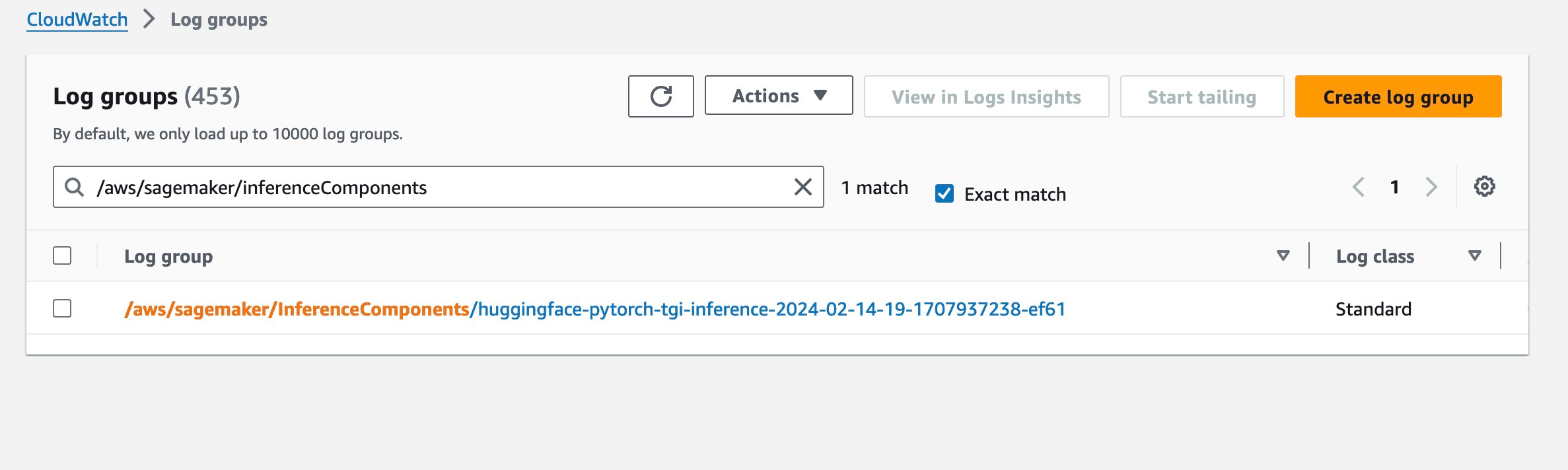
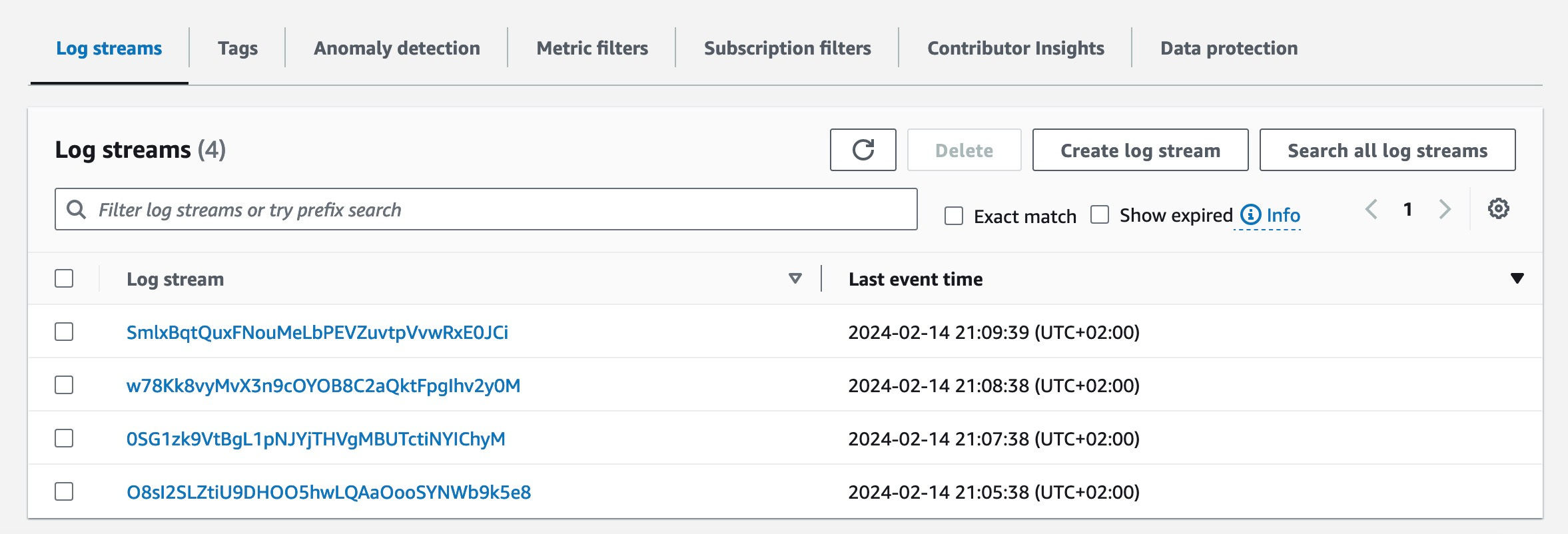
Create a DeploymentService class to be sure that you respect the SOLID principles:
class DeploymentService:
def __init__(self, resource_manager, logger=None):
"""
Initializes the DeploymentService with necessary dependencies.
:param resource_manager: Manages resources and configurations for deployments.
:param settings: Configuration settings for deployment.
:param logger: Optional logger for logging messages. If None, the standard logging module will be used.
"""
self.sagemaker_client = boto3.client("sagemaker")
self.resource_manager = resource_manager
self.settings = settings
self.logger = logger if logger else logging.getLogger(__name__)def deploy(
self,
role_arn: str,
llm_image: str,
config: dict,
endpoint_name: str,
endpoint_config_name: str,
resources: Optional[dict] = None,
endpoint_type: enum.Enum = EndpointType.MODEL_BASED,
):
"""
Handles the deployment of a model to SageMaker, including checking and creating
configurations and endpoints as necessary.
:param role_arn: The ARN of the IAM role for SageMaker to access resources.
:param llm_image: URI of the Docker image in ECR for the HuggingFace model.
:param config: Configuration dictionary for the environment variables of the model.
:param endpoint_name: The name for the SageMaker endpoint.
:param endpoint_config_name: The name for the SageMaker endpoint configuration.
:param resources: Optional resources for the model deployment(used for multi model endpoints)
:param endpoint_type: can be EndpointType.MODEL_BASED (without inference component)
or EndpointType.INFERENCE_COMPONENT (with inference component)
"""
try:
# Check if the endpoint configuration exists
if self.resource_manager.endpoint_config_exists(endpoint_config_name=endpoint_config_name):
self.logger.info(
f"Endpoint configuration {endpoint_config_name} exists. Using existing configuration..."
)
else:
self.logger.info(f"Endpoint configuration{endpoint_config_name} does not exist.")
# Check if the endpoint already exists
try:
self.sagemaker_client.describe_endpoint(EndpointName=endpoint_name)
endpoint_exists = True
self.logger.info(f"Endpoint {endpoint_name} already exists. Updating...")
except self.sagemaker_client.exceptions.ClientError as e:
if "Could not find endpoint" in str(e):
endpoint_exists = False
self.logger.info(f"Endpoint {endpoint_name} does not exist. Creating...")
# Prepare and deploy the HuggingFace model
self.prepare_and_deploy_model(
role_arn=role_arn,
llm_image=llm_image,
config=config,
endpoint_name=endpoint_name,
update_endpoint=endpoint_exists,
resources=resources,
endpoint_type=endpoint_type,
)
self.logger.info(f"Successfully deployed/updated model to endpoint {endpoint_name}.")
except Exception as e:
self.logger.error(f"Failed to deploy model to SageMaker: {e}")
raisedef prepare_and_deploy_model(
self,
role_arn: str,
llm_image: str,
config: dict,
endpoint_name: str,
update_endpoint: bool,
resources: Optional[dict] = None,
endpoint_type: enum.Enum = EndpointType.MODEL_BASED,
):
"""
Prepares and deploys/updates the HuggingFace model on SageMaker.
:param role_arn: The ARN of the IAM role.
:param llm_image: The Docker image URI for the HuggingFace model.
:param config: Configuration settings for the model.
:param endpoint_name: The name of the endpoint.
:param update_endpoint: Boolean flag to update an existing endpoint.
:param resources: Optional resources for the model deployment(used for multi model endpoints)
:param endpoint_type: can be EndpointType.MODEL_BASED (without inference component)
or EndpointType.INFERENCE_COMPONENT (with inference component)
"""
huggingface_model = HuggingFaceModel(role=role_arn, image_uri=llm_image, env=config)
# Deploy or update the model based on the endpoint existence
huggingface_model.deploy(
instance_type=settings.GPU_INSTANCE_TYPE,
initial_instance_count=1,
endpoint_name=endpoint_name,
update_endpoint=update_endpoint,
resources=resources,
tags=[{"Key": "task", "Value": "model_task"}],
endpoint_type=endpoint_type,
)
4. Cleaning Sagemaker resources
To ensure the complete deletion of all SageMaker resources and avoid any unexpected costs, it's crucial to meticulously verify that every component has been successfully removed from your account.
def delete_sagemaker_resources(endpoint_name: str, model_name: str, endpoint_config_name: str) -> None:
"""Deletes the SageMaker resources for a given endpoint name."""
sagemaker_client = boto3.client("sagemaker")
logging.info(f"Delete Initialized for: {endpoint_name}")
try:
try:
inference_components = sagemaker_client.list_inference_components(EndpointNameEquals=endpoint_name)
for component in inference_components["InferenceComponents"]:
inference_component_name = component["InferenceComponentName"]
if component["InferenceComponentStatus"] == "InService":
sagemaker_client.delete_inference_component(InferenceComponentName=inference_component_name)
logging.info(f"Deleting inference components for: {endpoint_name}")
time.sleep(120)
logging.info(f"Deleted inference components for: {endpoint_name}")
except sagemaker_client.exceptions.ClientError as e:
logging.error(f"Error listing inference components: {e}")
raise
# Delete the endpoint
try:
sagemaker_client.delete_endpoint(EndpointName=endpoint_name)
except sagemaker_client.exceptions.ClientError as e:
logging.error(f"Error deleting endpoint: {e}")
# Delete the endpoint configuration
try:
sagemaker_client.delete_endpoint_config(EndpointConfigName=endpoint_config_name)
logging.info(f"Deleted endpoint configuration: {endpoint_config_name}")
except sagemaker_client.exceptions.ClientError as e:
logging.error(f"Error deleting endpoint configuration: {e}")
# Delete the model
try:
sagemaker_client.delete_model(ModelName=model_name)
logging.info(f"Deleted model: {model_name}")
except sagemaker_client.exceptions.ClientError as e:
logging.error(f"Error deleting model: {e}")
except Exception as e:
logging.error(f"Error in deleting SageMaker resources: {e}")
raise
In conclusion, deploying Large Language Models via AWS SageMaker involves intricate steps that require a deep understanding of system requirements and resource management.
Despite the complexities, mastering these processes enables efficient and scalable AI model deployment.
Next Thursday, I'll demonstrate real-time inference using the discussed deployment inference components.
Congrats on learning something new today!
Don’t hesitate to share your thoughts - we would love to hear them.
→ Remember, when ML looks encoded - we’ll help you decode it.
See you next Thursday at 9:00 am CET.
Have a fantastic weekend!
This really helps, Thank you