

CDC: Enabling Event-Driven Architectures
Transforming Data Streams: The Core of Event-Driven Architectures

→ the 3rd out of 11 lessons of the LLM Twin free course
What is your LLM Twin? It is an AI character that writes like yourself by incorporating your style, personality, and voice into an LLM.
Decoding ML Newsletter is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.

Why is this course different?
By finishing the “LLM Twin: Building Your Production-Ready AI Replica” free course, you will learn how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices.
Why should you care? 🫵
→ No more isolated scripts or Notebooks! Learn production ML by building and deploying an end-to-end production-grade LLM system.
More details on what you will learn within the LLM Twin course, here 👈
Latest Lessons of the LLM Twin Course
Lesson 1: An End-to-End Framework for Production-Ready LLM Systems by Building Your LLM Twin
LLM Twin Concept: Explaining what an LLM twin is and how it will function as a unique AI character.
3-Pipeline Architecture: Discuss the structure and benefits of this architectural approach.
System Design for LLM Twin: Diving into each component of the LLM twin's system design: Data Collection Pipeline, Feature Pipeline, Training Pipeline Inference Pipeline
Lesson 2: The importance of Data Pipeline in the era of Generative AI
Data collection process -> Medium, Github, Substack & Linkedin crawlers
ETL pipelines -> data is cleaned and normalized
ODM (Object Document Mapping ) -> a technique that maps between an object model in an application and a document database
NoSQL Database (MongoDB)
Tracks data changes, logs them, and queues messages for real-time system updates.
The clean data is stored in a NoSQL database.
Are you ready to build your AI replica? 🫢
Let’s start with Lesson 3 ↓↓↓
Lesson 3: Change Data Capture: Enabling Event-Driven Architectures
We have changes everywhere. Linkedin, Medium, Github, and Substack can be updated every day.
To have a Digital Twin up to date, we need synchronized data.
What is synchronized data?
Synchronized data is data that is consistent and up-to-date across all systems and platforms it resides on or interacts with. It is the result of making sure that any change made in one dataset is immediately reflected in all other datasets that need to share that information.
CDC’s primary purpose is to identify and capture changes made to database data, such as insertions, updates, and deletions.
It then logs these events and sends them to a message queue, like RabbitMQ. This allows other system parts to react to the data changes in real-time by reading from the queue, ensuring that all application parts are up-to-date.
In this lesson, we will learn how to synchronize a data pipeline and a feature pipeline by using the CDC pattern.

Table of Contents
CDC pattern — Overview
CDC pattern —Digital Twin Architecture Use Case
CDC with MongoDB
Hands-on CDC: Mongo+RabbitMQ
CDC on AWS
Conclusion
1. CDC pattern — Overview
Change Data Capture (CDC) is a technique for tracking changes in a database, capturing insertions, updates, and deletions. It's essential for real-time data syncing, creating efficient data pipelines, minimizing the impact on the source system, and enabling event-driven architectures.
CDC addresses consistency issues in distributed systems by separating database updates from messaging processes, ensuring system integrity even in case of application or network failures.
Additionally, CDC reduces database load by reading changes from an operation log instead of directly querying the database.
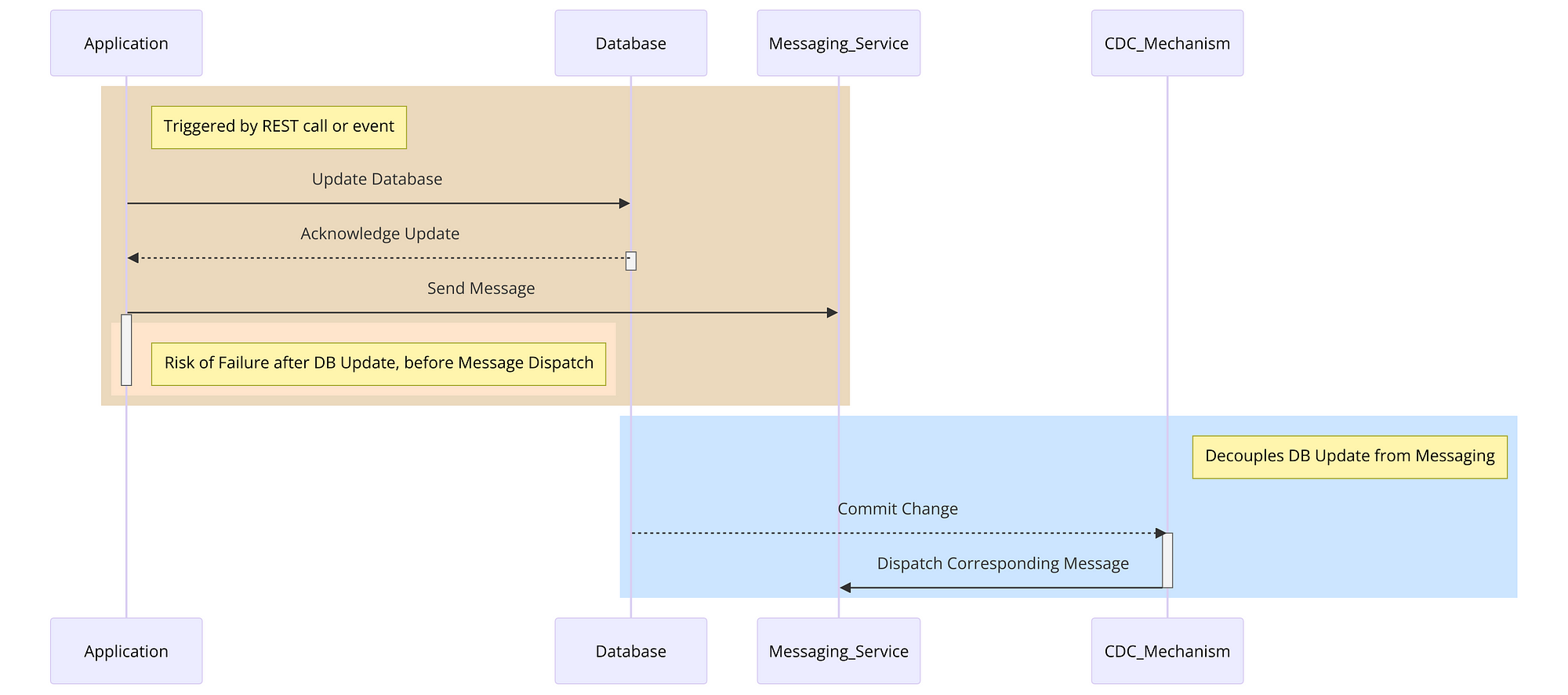
Summary of diagram:
Application Triggered: The diagram begins with an application that is triggered by a REST call or an event.
Update Database: The application first updates the database. This is shown as a communication from the ‘Application’ to the ‘Database’.
Database Acknowledges: The database acknowledges the update back to the application.
Send Message Attempt: Next, the application tries to send a message through the messaging service (like Kafka). This is where the risk of failure is highlighted — if the application fails after updating the database but before successfully sending the message, it results in inconsistency.
CDC Mechanism: To resolve this, the CDC mechanism comes into play. It decouples the database update from the messaging.
Database Commit Triggering CDC: Any committed change in the database is automatically captured by the CDC mechanism.
CDC Dispatches Message: Finally, the CDC mechanism ensures that the corresponding message is sent to the messaging service. This maintains consistency across the system, even if the application encounters issues after updating the database.
2. CDC pattern —Digital Twin Architecture Use Case
The Digital Twin Architecture is respecting ‘the 3-pipeline architecture’ pattern:
the feature pipeline
the training pipeline
the inference pipeline
The CDC pattern ensures consistency in this architecture by detecting changes at the data pipeline's entry. It monitors insertions, updates, and deletions in a NoSQL database after data collection from platforms like Medium and LinkedIn.
These changes are then processed in real-time by the Feature Pipeline and stored in a Vector DB for use in applications like machine learning and search algorithms.
3. CDC with MongoDB
MongoDB's change streams changed data response by providing real-time detection and processing of database changes.
This feature allows immediate updating of data, like LinkedIn post edits, in a feature store such as Qdrant.
Unlike traditional methods that involve delays, change streams directly capture and relay changes to the data pipeline for quick processing.
Previously, applications used continuous polling or the complex method of tailing MongoDB's Oplog.
Change streams, however, are more efficient and user-friendly and built on the Oplog with a native API. They require a replica set environment and allow users to specify the type of changes to monitor, streamlining data synchronization and updating processes.
4. Hands-on CDC: Mongo + RabbitMQ
We are building the RabbitMQConnection class, a singleton structure, for establishing and managing connections to the RabbitMQ server.
class RabbitMQConnection:
"""Singleton class to manage RabbitMQ connection."""
_instance = None
def __new__(
cls, host: str = None, port: int = None, username: str = None, password: str = None, virtual_host: str = "/"
):
if not cls._instance:
cls._instance = super().__new__(cls)
return cls._instance
def __init__(
self,
host: str = None,
port: int = None,
username: str = None,
password: str = None,
virtual_host: str = "/",
fail_silently: bool = False,
**kwargs,
):
self.host = host or settings.RABBITMQ_HOST
self.port = port or settings.RABBITMQ_PORT
self.username = username or settings.RABBITMQ_DEFAULT_USERNAME
self.password = password or settings.RABBITMQ_DEFAULT_PASSWORD
self.virtual_host = virtual_host
self.fail_silently = fail_silently
self._connection = None
def __enter__(self):
self.connect()
return self
def __exit__(self, exc_type, exc_val, exc_tb):
self.close()
def connect(self):
try:
credentials = pika.PlainCredentials(self.username, self.password)
self._connection = pika.BlockingConnection(
pika.ConnectionParameters(
host=self.host, port=self.port, virtual_host=self.virtual_host, credentials=credentials
)
)
except pika.exceptions.AMQPConnectionError as e:
print("Failed to connect to RabbitMQ:", e)
if not self.fail_silently:
raise e
def is_connected(self) -> bool:
return self._connection is not None and self._connection.is_open
def get_channel(self):
if self.is_connected():
return self._connection.channel()
def close(self):
if self.is_connected():
self._connection.close()
self._connection = None
print("Closed RabbitMQ connection")Publishing to RabbitMQ: The publish_to_rabbitmq function is where the magic happens. It connects to RabbitMQ , ensures that the message delivery is confirmed for reliability, and then publishes the data. The data variable, which is expected to be a JSON string, represents the changes captured by MongoDB's CDC mechanism.
def publish_to_rabbitmq(queue_name: str, data: str):
"""Publish data to a RabbitMQ queue."""
try:
# Create an instance of RabbitMQConnection
rabbitmq_conn = RabbitMQConnection()
# Establish connection
with rabbitmq_conn:
channel = rabbitmq_conn.get_channel()
# Ensure the queue exists
channel.queue_declare(queue=queue_name, durable=True)
# Delivery confirmation
channel.confirm_delivery()
# Send data to the queue
channel.basic_publish(
exchange="",
routing_key=queue_name,
body=data,
properties=pika.BasicProperties(
delivery_mode=2, # make message persistent
),
)
print("Sent data to RabbitMQ:", data)
except pika.exceptions.UnroutableError:
print("Message could not be routed")
except Exception as e:
print(f"Error publishing to RabbitMQ: {e}")Setting Up MongoDB Connection: The script begins by establishing a connection to a MongoDB database using MongoDatabaseConnectorclass. This connection targets a specific database named scrabble.
mongo.py
from pymongo import MongoClient
from pymongo.errors import ConnectionFailure
from rag.settings import settings
class MongoDatabaseConnector:
_instance: MongoClient = None
def __new__(cls, *args, **kwargs):
if cls._instance is None:
try:
cls._instance = MongoClient(settings.MONGO_DATABASE_HOST)
except ConnectionFailure as e:
print(f"Couldn't connect to the database: {str(e)}")
raise
print(f"Connection to database with uri: {settings.MONGO_DATABASE_HOST} successful")
return cls._instance
def get_database(self):
return self._instance[settings.MONGO_DATABASE_NAME]
def close(self):
if self._instance:
self._instance.close()
print("Connected to database has been closed.")
connection = MongoDatabaseConnector()Monitoring Changes with watch(): The core of the CDC pattern in MongoDB is realized through the watch method. Here, the script sets up a change stream to monitor for specific types of changes in the database. In this case, it's configured to listen for insert operations in any collection within the scrabble database.
changes = db.watch([{"$match": {"operationType": {"$in": ["insert"]}}}])
for change in changes:
data_type = change["ns"]["coll"]
entry_id = str(change["fullDocument"]["_id"]) # Convert ObjectId to string
change["fullDocument"].pop("_id")
change["fullDocument"]["type"] = data_type
change["fullDocument"]["entry_id"] = entry_id
# Use json_util to serialize the document
data = json.dumps(change["fullDocument"], default=json_util.default)
logging.info(f"Change detected and serialized: {data}")
# Send data to rabbitmq
publish_to_rabbitmq(queue_name="test_queue", data=data)
logging.info("Data published to RabbitMQ.")To test the code, check out the LLM Twin Course on GitHub, where you can quickly set up everything using our docker-compose.yaml and Makefile files.
5. CDC on AWS
The flow suggests a system where content from various platforms is crawled, processed, and stored in MongoDB. A CDC system running on Fargate captures any changes in the database and publishes messages about these changes to RabbitMQ.
Architecture Overview
Medium/Substack/Linkedin/Github URL Link: These are the sources of content. The system starts with URLs from these platforms.
Lambda Handler: This includes a Python Dispatcher and a Lambda Crawler which contains all types of crawlers. The Python Dispatcher is a component that decides which crawler to invoke based on the URL, while the Lambda Crawler is responsible for extracting the content from the provided URLs.
MongoDB: A NoSQL database used to store the crawled content.
CDC Fargate: This is a Change Data Capture (CDC) process running on AWS Fargate, which is a serverless compute engine for containers. CDC is used to capture and monitor changes in the database (like new articles added, or existing articles updated or deleted).
RabbitMQ: This is a message-broker software that receives messages about the changes from the CDC process and likely forwards these messages to other components in the system for further processing or notifying subscribers of the changes.

Cloud Deployment with GitHub Actions and AWS
In this final phase, we’ve established a streamlined deployment process using GitHub Actions. This setup automates the build and deployment of our entire system into AWS.
It’s a hands-off, efficient approach ensuring that every push to our .github folder triggers the necessary actions to maintain your system in the cloud.
In our GitHub repository it will be a .Readme file in which we will explain everything you need to setup your credentials and run everything.
You can delve into the specifics of our infrastructure-as-code (IaC) practices, particularly our use of Pulumi, in the ops folder within our GitHub repository.
This is a real-world example of modern DevOps practices, offering a peek into industry-standard methods for deploying and managing cloud infrastructure.
Conclusion
This is the 3rd article of the LLM Twin: Building Your Production-Ready AI Replica free course.
In this article, we presented Change Data Capture (CDC) as a key component for synchronizing data across various platforms, crucial for maintaining real-time data consistency in event-driven systems:
Integration with MongoDB and RabbitMQ: The lesson demonstrates how CDC, combined with MongoDB for data management and RabbitMQ for message brokering, creates a robust framework for real-time data processing.
Role of CDC in LLM Twin Architecture: It emphasizes CDC’s importance in the construction of an LLM Twin, ensuring data remains synchronized across the system, from data collection to feature extraction.
Practical Application and Implementation: Detailed instructions are provided on setting up and testing CDC in both local and cloud environments, offering hands-on experience in implementing these technologies.
🔻 NoSQL Database (MongoDB)
Tracks data changes, logs them, and queues messages for real-time system updates
The clean data is stored in a NoSQL database
🔗 Check out the code on GitHub [1] and support us with a ⭐️
This is how we can further help you 🫵
In the Decoding ML newsletter, we want to keep things short & sweet.
To dive deeper into all the concepts presented in this article…
Check out the full-fledged version of the article on our Medium publication.
↓↓↓
Thanks for these amazing articles!
How do you set up the CDC Fargate to get CDC events streaming? just run continuously?