



DML: How to build a PyTorch - TensorRT pipeline for YOLO Object Detection Models!
Practical tutorial on how to automate targeted GPU optimizations for YOLOv5,YOLOv8 models.

This is Part II of Deploying Deep Learning Systems
Howdy,
Here’s the topic of today:
Building a pipeline for YOLO model-to-target optimization.
I’ve been working with Computer Vision systems for a while now and there were a few instances where me and my team had missed our release schedule due to wrongly approaching the “automation” aspect of the process we have to do.
For context, our product had to run in real-time or as close to real-time as possible, and model optimizations to ONNX and TensorRT formats became trivial - one problem, though, I was doing this manually at first because I thought I could handle it and it’s no big deal - I was wrong.
Time and time again, I wasted hours and worked overtime to find out and fix the correct version sets between CUDA, CUDNN, TensorRT, and ONNX to match the client’s hardware - a real pain.
Table of Contents:
Here’s what we’ll learn today:
What problems does this pipeline help solve?
How it works?
What’s the scalability aspect of it?
Summary
#1 What problems does this pipeline help solve?
When working with multiple Deep Learning models on Edge Deployments, the process of versioning and lineaging between training experiments and deployed models can indeed grow in complexity.
As a rule of thumb - processes like these, which are at risk of either package versioning, model versioning, or any other bug inflicted by outdated code - should be automated.
From my own experience, I was spending hours to ensure model conversion with each release because I had to configure and remember the steps each time I did it.
Here’s a summary of the problems it solves:
A centralized way of handling conversions with a single point of failure
Can be extended to include multiple types of models
A single pipeline that does the entire flow - can be abstracted and run on multiple hardware at once
Ensures the same environment across devices
Can be included as a stage in the CI/CD pipeline
#2 How does it work?
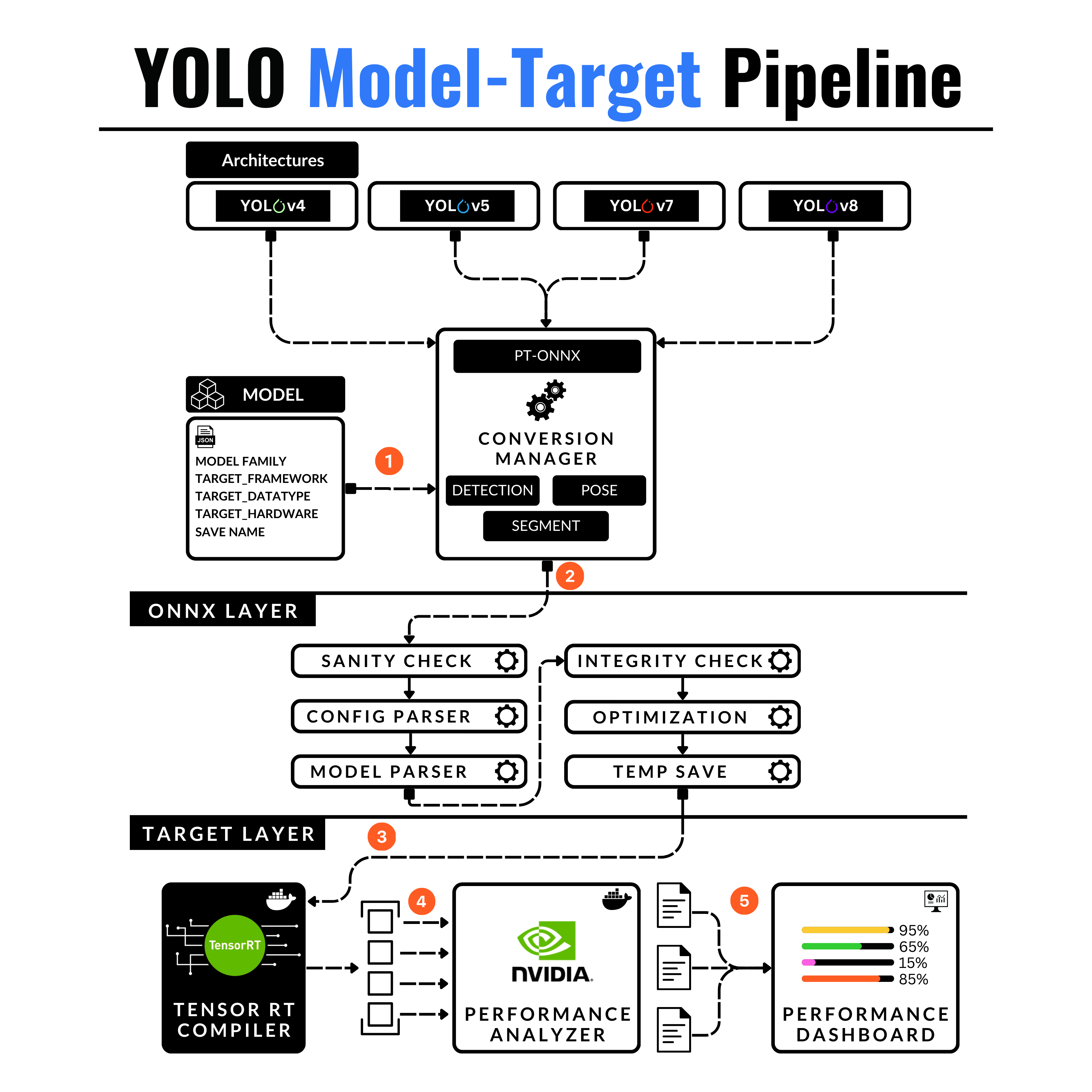
Let’s go over it, layer by layer in a top-bottom fashion:
Architectures
The YOLO model architectures are slightly different between versions. Version 4, 5, and 8 are provided/implemented as part of the Ultralytics package and Yolov7 is a standalone repository maintained by WongKinYiu. In this implementation, I’ll be focusing on Yolov5 and Yolov8 versions and present them as integrated submodules into the conversion pipeline we’re building.
Conversion Manager
This is the core logic of the pipeline, it will contain all the pipeline stages starting with the PyTorch (.pt) model up to the TensorRT (.engine) build. We will process the model_config, gather info about the GPU and other metrics, compose the Engine name, and trigger the Docker container to convert the ONNX to TensorRT.
ONNX Layer
Here, we will parse the config and select which version of YOLO’s PyTorch to ONNX we would to run the conversion with.
Target Layer
Here, we will handle the ONNX to TensorRT conversion automatically and then generate the model configuration such that it can be loaded and served directly with Triton Inference Server.
Further, let’s go over the entry point of this pipeline - the blueprint_config.json we would use to set the paths, conversion parameters, and model-name metadata.
A majority of these parameters are used to define the saved-engine name. This is a best practice I’ve found to work really well in storing and naming models when handling multiple versions.
Here’s the format:
{CLIENT_NAME}_{PROJECT}_MODELS_[TASK]_{MODEL_NAME}_{TRT_VERSION}_{GPU}_{DATA_TYPE}_{VERSION}
# >blueprint_config.json
{
"tritonserver_version": "21.09",
"model_family": "yolo-m",
"model_release": 8,
"weights": "",
"imgsz": [640, 640],
"device": "0",
"dtype": "fp16",
"dynamic": false,
"nms": true,
"simplify": true,
"opset": 14,
"client": "firstclient",
"project": "demo",
"task": "objectdetection",
"version": "1.0"
}
After conversion, we would obtain the following model ready to be loaded with Triton Inference Server:
FIRSTCLIENT_DEMO_MODELS_OBJECTDETECTION_YOLOV8M_8003_RTX4080_FP16_1.0Walkthrough
Folder structure
conversion_manager/ └── object_detectors/ └── @yolov5 └── @yolov8 └── helpers.py └── model_info.py └── pt2trt.py └── requirements.txt └── blueprint_config.json └── MakefileSubmodules
We would create an object_detectors folder that will contain the pipeline for conversion. This approach allows us to further scale this pipeline to other model_tasks (e.g. Foundation Models, LLM, etc).
Scripts
The Python scripts will cover the following tasks:
helpers.py - methods to validate the config.json, check the model integrity by inspecting the INPUT/OUTPUT layer shapes, import and use the correct pt2onnx method based on the YOLO model version.
model_info.py - here, we would handle the automatic model config generation to be able to import this model in TritonServer. Will contain methods to get the GPU name and cuda_capability, model data type (FP16, INT8), and model layer names.
pt2trt.py - Central execution point of the pipeline. Imports utilities from both helpers and model_info and constructs the pipeline flow.
More specifically:Load and parse blueprint_config.json
Establish the correct versions of the Engine Target (Triton Server)
Given the model version (v5, v8) select the correct pt2onnx exporter flow.
Convert the model and check the ONNX integrity
Trigger the ONNX-TensorRT stage
Will start the TensorRT container.
Will copy the .onnx model to the container’s workspace.
Establish the onnx2tensorrt command with the given parameters
Run the onnx2tensorrt pipeline
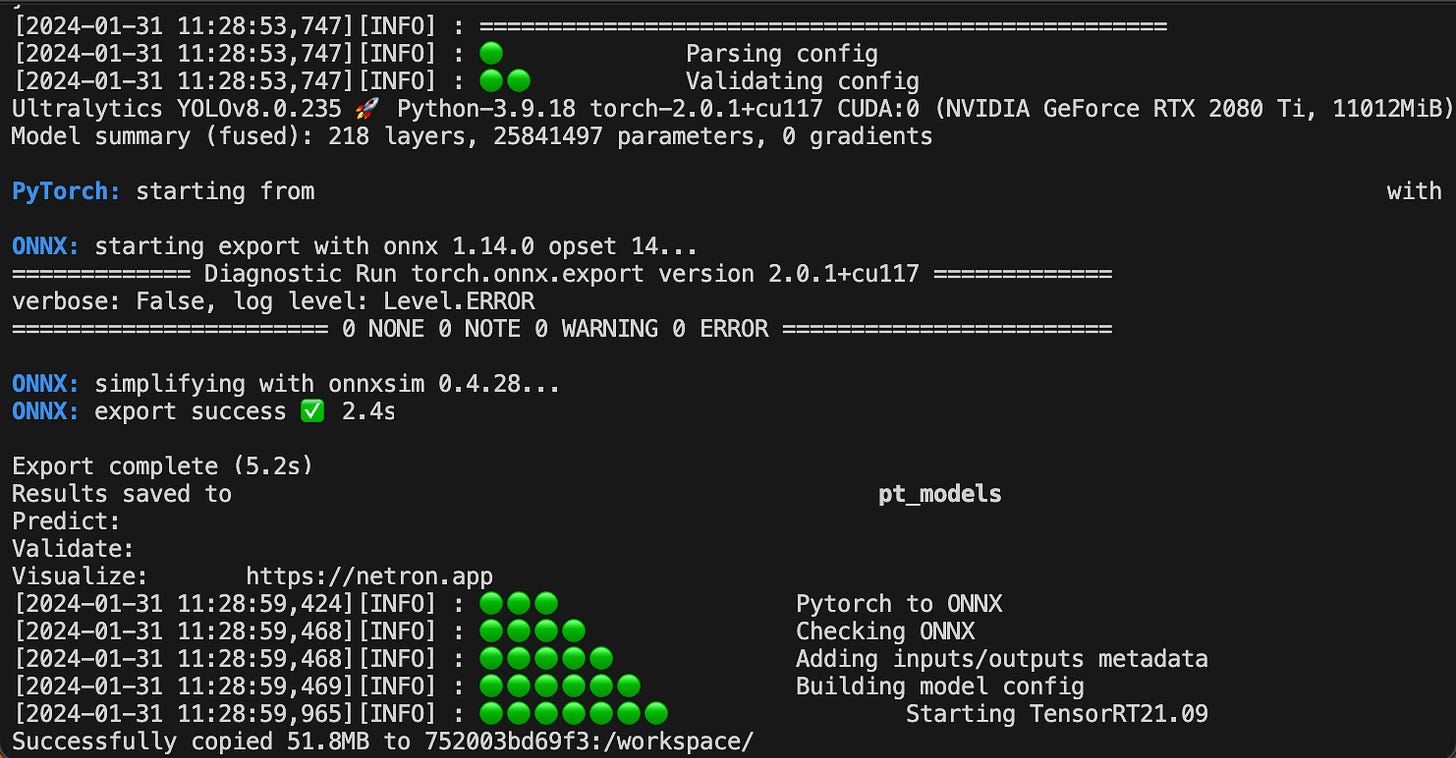
#3 What’s the scalability aspect of it?
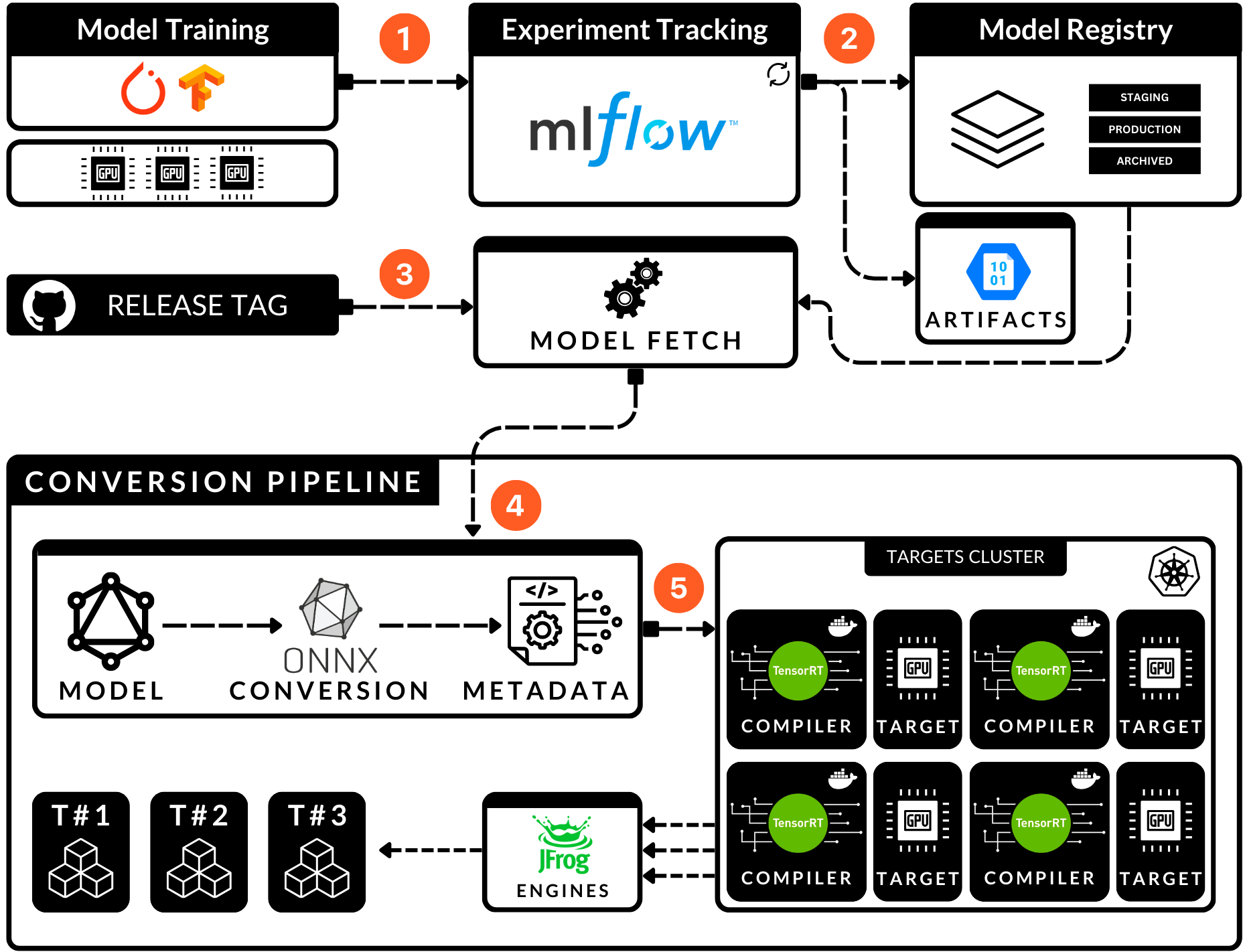
Since the pipeline is structured such that it is generic and keeps the same environment across multiple devices, we could scale it to a K8s cluster and have a single PyTorch (.pt) model be converted automatically to N different GPU targets (.engine).
Picture this flow:
We run model training asynchronous of the conversion pipeline
When we decide upon a new release of code + models - it can be triggered automatically.
It can automatically download the best model/models from the ModelRegistry
Replicate the conversion pipeline across an On-Prem cluster or Cloud cluster of different Machines
Run model conversion in parallel
Automatically store the generated .engines to a cloud blob or an Artifactory Store used for deployments to the client’s servers or edge-devices fleet.
#4 Summary
What we’ve learned today:
When working with Deep Learning models, optimizing these models is a crucial step.
If conversion is done manually, it is hard to replicate and keep the same environment across multiple targets.
Deep Learning Engineers should aim to automate the error-prone processes and ensure the same structure is kept.
A pipeline for converting .pt models to .engine targets is mandatory when working with multiple models at the same time.
If one uses NVIDIA Triton Inference Server to deploy and serve models to production environments - the presented pipeline could ensure that flow with ease.
The way it was structured, it can be run as a standalone step with Python or can be replicated and deployed to a K8S cluster with different GPUs.
It handles model saving automatically and can push to either Blob or Artifactory Store where the production models are kept.
If you’ve missed the “How to setup Triton Inference Server” article, you can check it here:

What’s next in the series?
In the next series of articles, I’ll show you gradually how to combine:
Triton Inference Server + GPU-aware TensorRT engine optimizationThis: How to build a MLOps model-to-target optimization pipeline
Model Monitoring Integration with Grafana in Depth
How to configure GPU instances and Replicas Triton can use.
How to deploy YOLOv8 Detection with Triton
How to build and deploy a fully scalable Computer Vision project
Congrats on learning something new today! 👾
Don’t hesitate to share your thoughts - we would love to hear them.
Remember, when ML looks encoded - we’ll help you decode it.
See you next Thursday at 9:00 a.m. CET.
Have a fantastic week!
Signed: Alex R. from the Decoding ML team
Where can I find the source code of this exercise to try this on y lab
Thanks a Lot Razvant. it would be really appreciate you also upload source code for your first blog
Triton Inference Server + GPU-aware TensorRT engine optimization so we can replicate this in our testing environment to get more hands-on it. I really enjoy following your blogs.