



DML: How to deploy Deep Learning Models at Scale, with a few clicks/enters.
All you need to know about NVIDIA Triton Inference Server, the whats, the hows and the whys plus some meme references.

Welcome to Decoding ML 👋🏼
The one place where we will help you decode complex topics about ML & MLOps one week at a time 🔥
Howdy,
You might be wondering why 2 Alex’es have joined Decoding ML - the answer is that Paul promised us both an RTX4090 each after we wrote our first post :).
Just kidding, we both love what Paul has built and the awesome actionable insights he shared along the way and the fact that we’ve joined forces to bring you premium tips and solutions to your MLE & MLOps challenges denotes our pleasure in working together.
This post is longer than Call of Duty 2023's Campaign :) , but please stay tuned as I prepare a series on this topic to walk you through everything you need to know and do in order to handle model deployments in Deep Learning Systems using Triton Inference Server.
This is Part I of Deploying Deep Learning Systems: Enjoy
The topic of today is,
NVIDIA Triton Inference Server - a solution I’ve been using professionally to deploy and manage computer vision at scale to handle multiple concurrent inference requests.
Let’s outline the topics we’ll go over through:
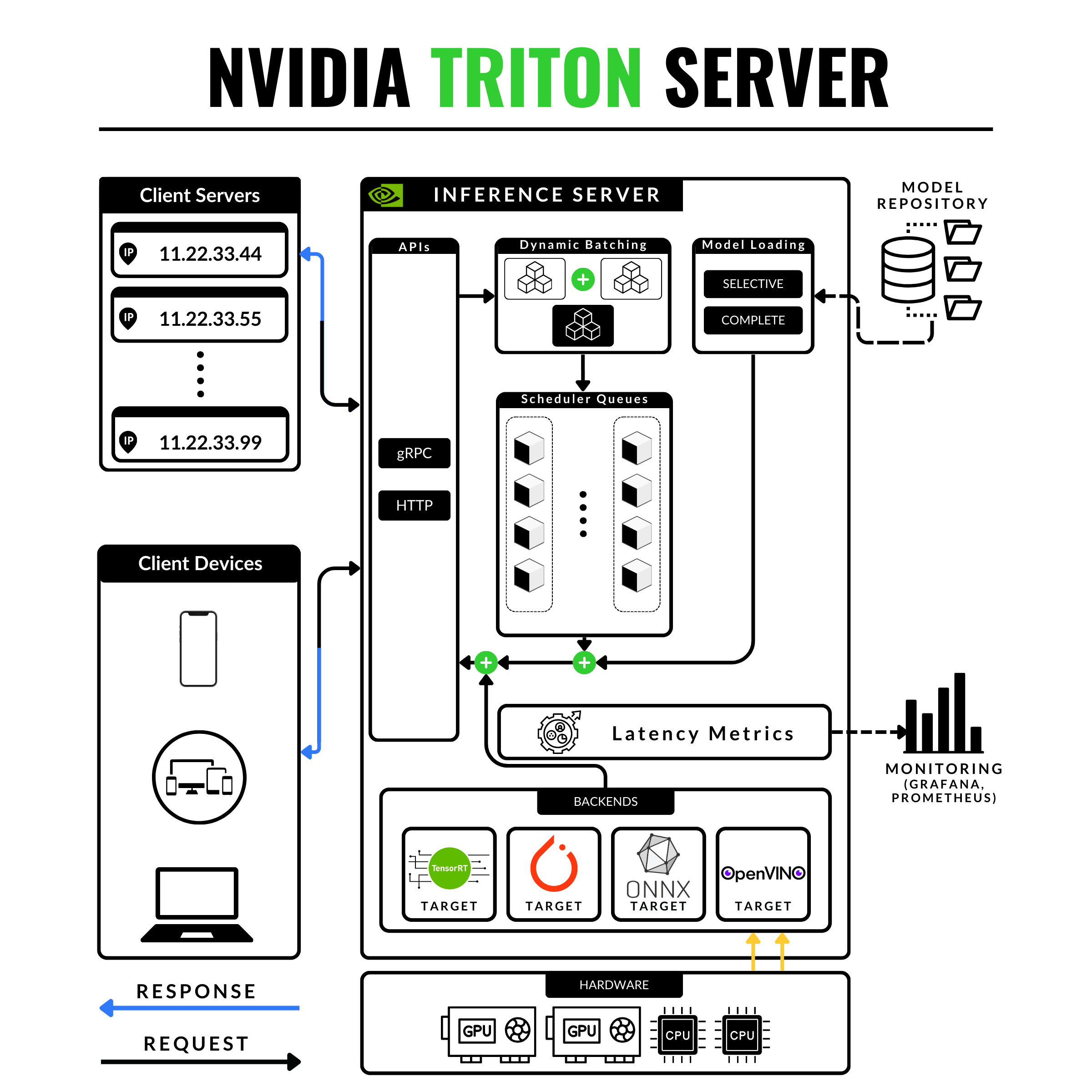
What is NVIDIA Triton Inference Server (T.I.S)?
How does Triton Inference Server works?
Installation & Sample Project (Quick 10min test)
Recap & Next
What is NVIDIA Triton Inference Server (T.I.S)
It started as a part of the NVIDIA Deep Learning SDK to help developers encapsulate their models on the NVIDIA software kit. It further branched out and was called TensorRT Server which focused on serving models optimized as TensorRT engines and further became NVIDIA Triton Inference Server - a powerful tool designed for deploying models in production environments.
If you want multiple frameworks - it supports TensorRT, TensorFlow GraphDef, TensorFlow SavedModel, ONNX, PyTorch TorchScript) and even vanilla Python scripts or C++ applications.
If you want to build pipelines - it supports ensembles of models to chain one or more models each possible using a different framework.
If you want performance observability out of the box - it automatically provides metrics on :8002 port in Prometheus data format which includes GPU utilization, server throughput, latency, and many more.
If you want auto-scaling - you can control gpu_clusters and model_replicas from within the model configuration files.
If you want API support - it offers Python, C++, Java HTTP.
If you want different protocols: it offers gRPC on port:8001 for high-frequency inference requests and HTTP on port:8000 for low/moderate request loads.
If you want to support A/B testing at ease - you can load multiple model versions under the same deployment on the same target format (TensorRT, ONNX, etc)

How does Triton Inference Server work?
We’ll go over:
Workflow Overview
How to set up the model-repository
How the IN/OUT requests are processed
How does request-batching work
Workflow Overview
Client instances are sending inference requests to the server.
Requests are batched as specified by the configuration
Requests are scheduled to be processed
The model is loaded from the model-repository
Inference on batch
Unpacking batch and sending responses back to clients.
How to set up the model-repository
A model repository is a storage location (local folder, storage blob) that contains the configured models as separate sub-folders. Here’s the blueprint of a configured model.
model_repository
└── prod_client1_encoder
└── 1
└──resnet50.engine
└── 2
└──resnet50.engine
└── config.pbtxtIn this structure, we have a model called “prod_client1_encoder” with two deployed versions (1,2) - both versions are TensorRT engines. Under the same model folder, we have a “config.pbtxt” (protobuf text) which describes the model configuration.
## config.pbtxt
name: "prod_client1_encoder" # Name of the model
platform: "tensorrt_plan" # Framework the model is in
max_batch_size: 0 # Model handles 1 request/a time
input [ # Defining input layer conf
{
name: "input_tensor" # Input tensor name
data_type: TYPE_FP32 # Expected input datatype
format: FORMAT_NHWC # Expected tensor format
dims: [ 224, 224, 3 ] # Input tensor dims
}
]
output [ # Defining output layer conf
{
name: "output_tensor" # Output tensor name
data_type: TYPE_FP32 # Output tensor datatype
dims: [ 1000 ] # Output tensor dims
}
]
default_model_name="resnet50.engine"How the IN/OUT requests are processed
Being based on a client-server model, the workflow goes like this:
Client packs the input data (image, text, audio).
Client specifies which model to use (by name and version)
Client sends the inference request to the server via either HTTP or gRPC.
Server receives a request and places it in a queue as Triton is designed to handle multiple requests simultaneously.
Server retrieves the specified model from the model repository and performs inference.
Server sends the response back to the client using the same protocol gRPC or HTTP.
Client receives the response and extracts the result tensor() → numpy().
How does request-batching work
Request Gathering: multiple clients send requests for inference.
Dynamic Batching: the server accumulates incoming inference requests while it waits for a short time window (batching window) that is configurable in config.
Processing Batch: the server sends the batched requests to the model for inference.
Response to Clients: the server disassembles the responses and sends the individual results back to the respective clients.
Installation & Sample Project (Quick 10min test)
Prerequisites
# Create project directory mkdir triton_sample_project # Create model_repository directory mkdir triton_sample_project/model_repo # Create blueprint for a model in model-repository mkdir triton_sample_project/model_repo/mobilenet mkdir triton_sample_project/model_repo/mobilenet/1 touch triton_sample_project/model_repo/mobilenet/config.pbtxtInstall python package
*You can also install specific protocols e.g tritonclient[grcp], tritonclient[http]*
pip install tritonclient, tritonclient[http]
Download a model
*MobileNet - Popular Image Classification Network*wget -O mobilenetv2-12.onnx https://github.com/onnx/models/raw/main/validated/vision/classification/mobilenet/model/mobilenetv2-12.onnx?download= mv mobilenetv2-12.onnx triton_sample_project/model_repo/mobilenet/1/mobilenetv2.onnxPrepare the model repository
*I have extracted input/output layer info, by viewing onnx model in Netron*
*Go to netron.app, load .onnx, check first and last layer*vim triton_sample_project/model_repo/mobilenet/config.pbtxt ---- ## config.pbtxt name: "mobile_net" platform: "onnxruntime_onnx" max_batch_size: 0 input [ { name: "input" data_type: TYPE_FP32 dims: [ 1, 3, 224, 224 ] } ] output [ { name: "output" data_type: TYPE_FP32 dims: [-1, 1000] } ] default_model_filename:"mobilenet.onnx"Prepare the .env file
touch triton_sample_project/.env # vim .env HTTP_P=8000:8000 GRPC_P=8001:8001 PROM_P=8002:8002 IMAGE=nvcr.io/nvidia/tritonserver:22.04-py3 MODEL_REPOSITORY=./model_repoHow to start it as a docker container
*It will download tritonserver-22.04-py3 image which is 11GB*
# LOAD .env source .env # [OPTIONAL] CLEANUP PREVIOUS CONTAINERS docker rm sample-tis-22.04 # START THE CONTAINER docker run --gpus 0 -d -p $HTTP_P -p $GRPC_P -p $PROM_P \ -v${MODEL_REPOSITORY}:/models \ --name sample-tis-22.04 $IMAGE tritonserver \ --model-repository=$MODELS[Optional] How to start it as a service in docker-compose
*I prefer this method better, it offers better control over active containers*# vim triton_sample_project/docker-compose.sample-tis.yml version: '3.4' services: triton_server: container_name: sample-tis-22.04 image: $IMAGE privileged: true ports: - $HTTP_P - $GRPC_P - $PROM_P deploy: resources: reservations: devices: - driver: nvidia capabilities: [gpu] volumes: - ${MODEL_REPOSITORY}:/models command: ["tritonserver", "--model-repository=/models"]# START compose service docker compose -f docker-compose.sample-tis.yml up -dInspect the server status
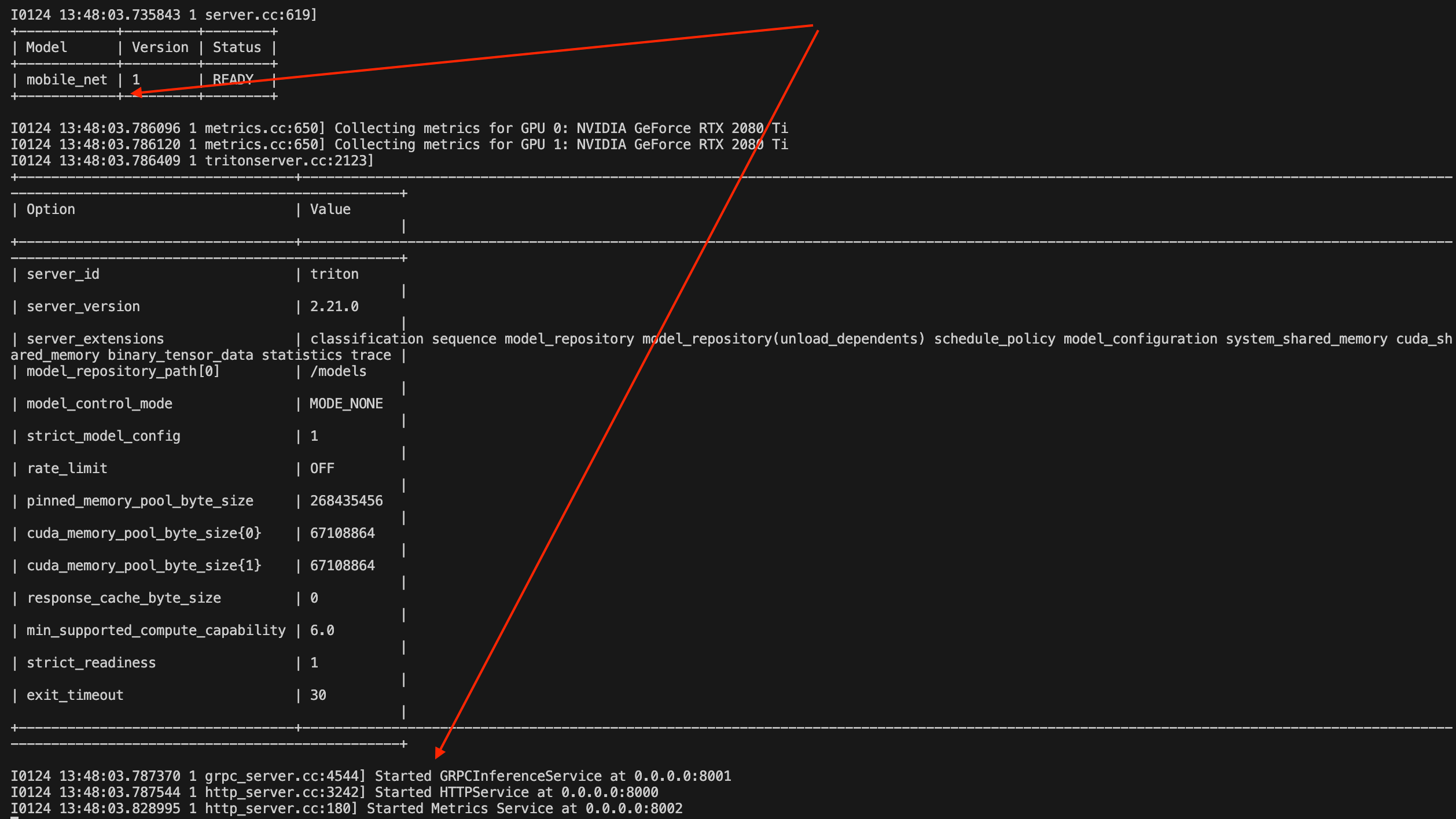
*One could also test the endpoints, but I prefer inspecting container logs"*# CHECK server status docker logs sample-tis-22.04 --tail 40
Download MobileNetV2 labels and a dummy image
# LABELS wget https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt # IMAGE curl https://www.healthyseasonalrecipes.com/wp-content/uploads/2019/12/greek-pizza-21-034.jpg > pizzaa.pngImplement Python client & Run Inference
*Connection, preprocess an image, inference request, and print outputs*
*You should copy the code blocks in this order*
Step 1: ImageNet image processing code block# touch triton_sample_project/playground.py import tritonclient.http as httpclient import numpy as np from PIL import Image from scipy.special import softmax def preprocess(image): def image_resize(image, min_len): image = Image.open(image) ratio = float(min_len) / min(image.size[0], image.size[1]) if image.size[0] > image.size[1]: new_size = (int(round(ratio * image.size[0])), min_len) else: new_size = (min_len, int(round(ratio * image.size[1]))) image = image.resize(new_size, Image.BILINEAR) return np.array(image) image = image_resize(image, 256) # Crop centered window 224x224 def crop_center(image, crop_w, crop_h): h, w, c = image.shape start_x = w // 2 - crop_w // 2 start_y = h // 2 - crop_h // 2 return image[start_y : start_y + crop_h, start_x : start_x + crop_w, :] image = crop_center(image, 224, 224) image = image.transpose(2, 0, 1) img_data = image.astype("float32") # normalize mean_vec = np.array([0.485, 0.456, 0.406]) stddev_vec = np.array([0.229, 0.224, 0.225]) norm_img_data = np.zeros(img_data.shape).astype("float32") for i in range(img_data.shape[0]): norm_img_data[i, :, :] = (img_data[i, :, :] / 255 - mean_vec[i]) / stddev_vec[i] norm_img_data = norm_img_data.reshape(1, 3, 224, 224).astype("float32") return norm_img_dataStep 2: Load labels and prepare the connection
with open("imagenet_classes.txt", "r") as f: categories = [s.strip() for s in f.readlines()] image_path = "./pizzaa.png" model_input_name = "input" model_output_name = "output" model_name = "mobile_net" model_vers = "1" server_url = "localhost:8000"Step 3: Send inference request
processed_image = preprocess(image_path) # == Populate a Triton HTTP request == client = httpclient.InferenceServerClient(url=server_url) input_data = httpclient.InferInput(model_input_name, processed_image.shape, "FP32") input_data.set_data_from_numpy(processed_image) request = client.infer(model_name, model_version=model_vers, inputs=[input_data]) # == Unpack output in numpy == output = request.as_numpy(model_output_name) output = np.squeeze(output) probabilities = softmax(output)Step 4: Parse and print results
# == Format to TOP_K detections == top5_class_ids = np.argsort(probabilities)[-5:][::-1] # == Pretty print results == print("\nInference outputs (TOP5):") print("=========================") padding_str_width = 10 for class_id in top5_class_ids: score = probabilities[class_id] for class_id in top5_class_ids: score = probabilities[class_id] print( f"CLASS: [{categories[class_id]:<{padding_str_width}}]\t: SCORE [{score*100:.2f}%]" )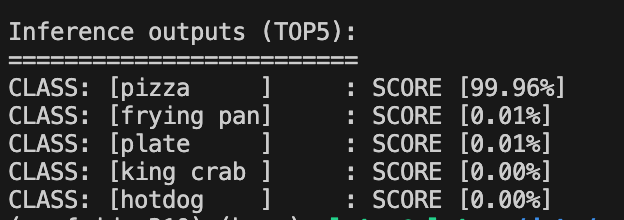
Step 5: Order and enjoy a pizza :)
Recap & Next
Finally, let’s recap what we’ve learned today:
Triton Inference Server is an easy-to-set-up, scalable, and fail-safe solution to deploy and monitor your Deep Learning Models in production.
It offers multiple optimized backends (frameworks) where you can run your models, including ONNX, TensorRT, OpenVino, Tensorflow, and PyTorch.
It offers HTTP and GRPC protocols for low and high inference loads.
It handles request batching smartly and dynamically, ensuring that each client gets back a response.
The interface between client & server is straightforward, and model configuration is handled automatically by specified parameters in config.pbtxt
I’ve used it in multiple projects to handle several parallel RTSP cameras (25/30FPS) with ease.
It integrates with Prometheus and Grafana for Monitoring at a few click’s distance.
What’s next?
I’m planning to cover the rest of the toolkit as this article only offers you around 30-40% of what Triton can do and I didn’t want to sway away from the topic and explain it all in a single shot.
In the next series of articles, I’ll show you gradually how to combine:
Triton Inference Server + GPU-aware TensorRT engine optimization
Model Monitoring Integration with Grafana in Depth
How to configure GPU instances and Replicas Triton can use.
How to deploy YOLOv8 Detection with Triton
How to build a MLOps model-to-target optimization pipeline
How to build and deploy a fully scalable Computer Vision project
As this is my first article on DecodingML’s Substack, I would really appreciate to receive feedback from you guys such that I can improve my writing style and target specific topics.
Thanks
That’s it for today 👾
If you’ve enjoyed it and have learned something new leave a comment - we’re reading all of them.
See you next Thursday at 9:00 a.m. CET.
Have a fantastic weekend!
Signed: Alex R. from the Decoding ML team
Great article!
1. How hard is adding a custom model on Triton?
2. Can the preprocessing be moved to the server side, not the client?
Great blog post 🚀