

How to ensure your models are fail-safe in production?
Effectively monitor model serving stacks at scale, extracting key insights from their behaviour under large loads.

Even before deploying an ML system, engineers require accurate insights on how it will perform under load, both locally and at scale to identify bottlenecks and unexpected behaviors that might pop up.
I’ve encountered this myself as I’ve tested and deployed a Computer Vision solution, only to see that the regular processing time jumped from 𝘂𝗻𝗱𝗲𝗿 𝟱 𝗵𝗼𝘂𝗿𝘀 to process 24 hours of video, 𝘁𝗼 𝟴 𝗵𝗼𝘂𝗿𝘀 in the pre-production/validation environment.
In this article, I’ll cover a pipeline for efficient monitoring of your ML models deployed within NVIDIA’s Triton Inference Server.

Here’s what we’ll learn today:
How to set up a performance monitoring pipeline
Containers
Configuration Files
Docker Compose
Metrics scrapping configuration
Adding the Prometheus targets
Adding the Grafana datasource
Health check scrapping targets
Creating dashboards
Add Grafana Panels for GPU/Triton metrics.
Table of Contents
Preparing docker-compose file
Metrics scrapping configuration
Creating dashboards
Visualizations
#1. Docker Compose Monitoring
Let’s start by explaining what each service is doing and then by preparing the docker-compose to encapsulate and run all these services. We have the following:
cAdvisor which scrapes RAM/CPU usage per container
Triton Inference Server which serves ML models and yields GPU-specific metrics.
Prometheus which is the binding between the metrics generators and the consumer.
Grafana which is the consumer endpoint for visualization.

Let’s inspect the docker-compose-monitoring.yaml file.
# cat docker-compose-monitoring.yaml
version: '3.4'
services:
prometheus:
image: prom/prometheus:latest
ports:
- "${PROMETHEUS_PORT}:${PROMETHEUS_PORT}"
container_name: prometheus
restart: always
volumes:
- "${MONITORING_CONFIGURATIONS}/prometheus.monitoring.yml:/etc/prometheus/prometheus.monitoring.yml"
- /var/run/docker.sock:/var/run/docker.sock:ro
command:
- "--config.file=/etc/prometheus/prometheus.monitoring.yml"
- "--enable-feature=expand-external-labels"
depends_on:
- cadvisor
networks:
monitor-net:
ipv4_address: ${PROM_IP}
grafana:
image: grafana/grafana-enterprise:8.2.0
container_name: grafana
ports:
- "${GRAFANA_PORT}:${GRAFANA_PORT}"
volumes:
- ${MONITORING_CONFIGURATIONS}/datasources:/etc/grafana/provisioning/datasources
environment:
- GF_SECURITY_ADMIN_PASSWORD=${GRAFANA_PWD}
- GF_SECURITY_ADMIN_USER=${GRAFANA_USER}
networks:
monitor-net:
ipv4_address: ${GRAFANA_IP}
cadvisor:
image: gcr.io/cadvisor/cadvisor:latest
container_name: cadvisor
restart: always
ports:
- "${CADVISOR_PORT}:${CADVISOR_PORT}"
volumes:
- "/etc/localtime:/etc/localtime:ro"
- "/etc/timezone:/etc/timezone:ro"
- "/:/rootfs:ro"
- "/var/run:/var/run:rw"
- "/sys:/sys:ro"
- "/var/lib/docker:/var/lib/docker:ro"
networks:
monitor-net:
ipv4_address: ${CADVISOR_IP}
triton_server:
container_name: tis2109
image: nvcr.io/nvidia/tritonserver:21.09-py3
privileged: true
ports:
- "8002:8002"
deploy:
resources:
reservations:
devices:
- driver: nvidia
capabilities: [gpu]
volumes:
- ${TRITON_MODELS_REPOSITORY}:/models
command: ["tritonserver","--model-repository=/models", "--strict-model-config=false"]
networks:
monitor-net:
ipv4_address: ${TRITON_IP}
networks:
monitor-net:
driver: bridge
internal: false
ipam:
driver: default
config:
- subnet: ${SUBNET}
gateway: ${GATEWAY}
As you may observe, in this compose file we have a few ${VAR} which are masked. These are set automatically from within a .env file such that this flow follows the best practices on local development and CI/CD pipelines.
Now let’s see what’s in the .env file:
# == Monitoring vars ==
PROMETHEUS_PORT=9090
GRAFANA_PORT=3000
CADVISOR_PORT=8080
MONITORING_CONFIGURATIONS=<path_to_your_configuration_files>
# == Credentials ==
GRAFANA_PWD=admin
GRAFANA_USER=admin
# == TIS vars ==
TRITON_MODELS_REPOSITORY=<path_to_your_triton_model_repository>
# == Underlying network ==
SUBNET=172.17.0.0/16
GATEWAY=172.17.0.1
# == Subnet IP's ==
TRITON_IP=172.17.0.3
CADVISOR_IP=172.17.0.4
PROM_IP=172.17.0.5
GRAFANA_IP=172.72.0.6Pretty much all variables are set, but here are the key 2 we need to take a look at:
MONITORING_CONFIGURATIONS
This one should point to a folder where you have this structure
.__ monitoring
| |_ datasources
| | |_ datasources.yml
| |_ prometheus.monitoring.ymlTRITON_MODEL_REPOSITORY
The structure of your model repository should look like this:
model_repository
└── prod_client1_encoder
└── 1
└──resnet50.engine
└── config.pbtxtIf you’re not familiar with NVIDIA Triton Inference Server, no problem.
I have covered it 0-100 in this article:

The prometheus.monitoring.yml is where we will add the targets (containers) we wish to get metrics from.
The datasources.yml is where we’ll add the Prometheus as a source for Grafana dashboards, such that it will appear when you open Grafana Web.
#2 Metrics scrapping configuration
Let’s go ahead and configure the Prometheus targets. We’ll write in the prometheus.monitoring.yml file.
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['172.17.0.5:9090']
- job_name: 'triton-server'
static_configs:
- targets: ['172.72.0.3:8002']
- job_name: 'cadvisor'
static_configs:
- targets: ['172.72.0.4:8080']
We have 3 targets:
prometheus - if you’re asking why? This is a best practice for healthy monitoring because with thousands of metrics - we might get bottlenecks and it’s useful to know the resource usage of Prometheus itself.
triton-server - this one is crucial, as it’s at the core of this deep learning stack as it serves and manages our ML models. Triton has an incorporated Prometheus endpoint on port 8002 which offers various metrics across the inference process.
cAdvisor - to get CPU/RAM usage across containers in this deployment.
With all these configured, we can start the composer and inspect for any issues.
Let’s start the containers.
docker compose -f docker-compose-monitoring.yaml upLet’s inspect Prometheus targets:
Go to your web browser and insert the full Prometheus URL (IP:9090).
Go to Status → Targets
Check if each target from the scrapping config is healthy (green).


Once we verified these, we could go ahead and create our dashboard in Grafana.
#3 Creating dashboards
In order to access the Grafana WebUi dashboard, open your browser and go to
`localhost:3000`, where 3000 is the port we’ve ran the Grafana container.
If you’re running this as part of a stack on a cloud deployment or a dedicated server, you can access the web-ui using the public IP of the machine.
If you’re prompted to a login page, just use `admin` on both username/password fields. Better security is indeed recommended, but this doesn’t fall within the scope of this article.
Once you’ve opened Grafana web-ui, we’ll have to do the following:
Point the datasource to our prometheus metrics scrapper endpoint
Create a new dashboard
Add charts to aggregate/visualize metrics we’re interested in.
#3.1 Prometheus DataSource
On the left panel, go to the gear icon (settings) and select DataSources.
You’ll be prompted to a view like this one below:

Click on “Add data source” and under the Time Series Databases select `Prometheus`. As you may have seen, Grafana supports many integrations for metrics scrapping - in this article we’ll use Prometheus.
You’ll be prompted to this, and here you’ll have to add the URL of your prometheus endpoint. In our docker-compose deployment we will use `http://prometheus:9090` following this template `http://container_name:container_port`
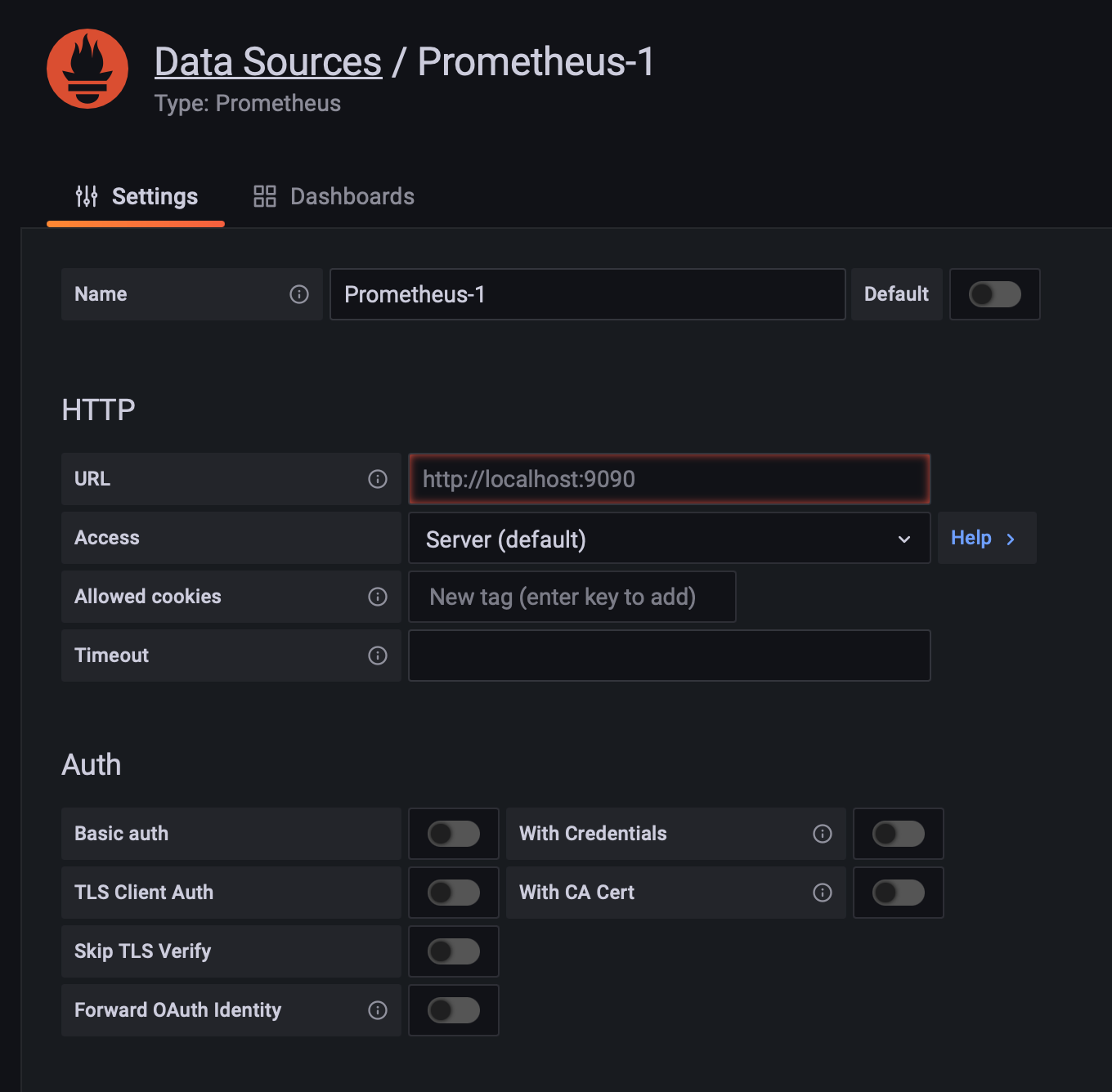
If you’ve reached this point, this section of adding the data source is complete. Let’s continue with creating a dashboard.
#3.2 Creating a Grafana Dashboard
On the left panel, go to the “+” sign and select `Dashboard`. You’ll be redirected to a new dashboard page with a pre-defined panel group. As we’re building everything from scratch, we’ll use only `Empty Panels` which we’ll set to display key metrics.
Here’s the blueprint we’ll follow for one example:
Add a query and define the `promql` (prometheus query language)
Configure visualisation type, graph style and legend.
Below is a view of an empty panel. Next we’ll go further and populate it.

This will be a `time-series` and we’ll display the time it took the Triton Inference server to perform an inference request. Here’s the query to compose that metric:
(irate(nv_inference_compute_infer_duration_us{job="triton-server"}[$__rate_interval]) / 1000) / irate(nv_inference_request_success{job="triton-server"}[$__rate_interval])Important:
Since we’ve decoupled the Inference from the actual application code, we have a client-server communication protocol. In this case, a complete inference request will consist of:
I/O input data from client → server
Inference on data
I/O output results from server → client
In this metric
nv_inference_compute_infer_duration_us, we measure only the inference on data step within the Triton Server.
Now, let’s unpack it:
nv_inference_compute_infer_duration_us
nv_inference_request_success - shows the number of successful requests marked by Triton Server.
We apply an iRate with an rate_interval to see the time progression of this report such that we monitor the inference_time dependency on the number of successful requests.
Below you can see how the query looks. You might also observe under Legend that we have `{{model}}-{{version}}`.
This will filter the chart’s legend to display the model + it’s deployment version within Triton Server.

As per configuring right panel settings, you could specify:
Chart Type - select either straight/curved/T-step lines
Metrics Range - select the metric (e.g milliseconds (ms)) and define low_range (e.g 0) and high_range (e.g 100ms)
Custom Text - to display as legend or other field.
#3.3 Complete Visualization
Based on the flow above, one could create the rest of the charts.
I could go over all of them, but it will extend this article a lot.
Below, you’ll find attached an example of what I’m using to study SLOs/SLIs/SLAs for the inference performance of the AI stack.
This also helps planning for a scaling strategy, either add multiple replicas of the model or scale-up to multiple machines running the Inference Serving framework.

If you don’t know about SLO/SLI/SLA terms, check them here:
https://www.atlassian.com/incident-management/kpis/sla-vs-slo-vs-sliSame for key-metrics to monitor your Triton Server Deployment here:
https://docs.nvidia.com/deeplearning/triton-inference-server/user-guide/docs/user_guide/metrics.htmlI’ll be covering these in the future, but for now - these resources will do.
Conclusion
In this article, we went over how to set up and build a performance monitoring stack for our ML Application and Model Serving Framework using Prometheus and Grafana.
We went over preparing the docker-compose file, deploying the stack, configuring sources, and creating dashboard panels.
Following this tutorial, you’ll be able to structure and deploy a monitoring pipeline for your ML application either in testing environments as a single deployment or as an aggregator dashboard (e.g in a cloud scenario setting) to combine multiple input sources and have a single dashboard consumer point from which you monitor the entire stack deployment.