

SLM Fine-tuning: Top Results at 9.47% Cost
Speed up your MLOps learning experience. Build a feature pipeline for an H&M personalized recommender.

This week’s topics:
Looking to speed up your MLOps learning experience?
Fine-tuning SLMs for top-tier results at a fraction of the cost
Build a feature pipeline for an H&M personalized recommender
Looking to speed up your MLOps learning experience?
Looking to speed up your MLOps learning experience? listen up...
Here is an excellent live course you can't miss.
Enters > The 𝗘𝗻𝗱-𝘁𝗼-𝗲𝗻𝗱 𝗠𝗟𝗢𝗽𝘀 𝘄𝗶𝘁𝗵 𝗗𝗮𝘁𝗮𝗯𝗿𝗶𝗰𝗸𝘀 course
→ A live course on MLOps with Databricks that starts on the 27th of January.
The course is made and hosted by
and , the founders of .As their second iteration, it is already a bestseller on Maven with a 4.9 🌟 rating.

The No. 1 thing that makes this course stand out…
→ Even if they use Databricks, they will focus on the MLOps principles while applying them to Databricks, which is pure gold!
I have known them for over a year, and I can genuinely say they are exceptional engineers and teachers. A rare combination!
That's why this course will pack tons of value.
It will walk you through an MLOps noobie to a pro:
MLOps principles and components
Developing in Python: best software development principles
From a notebook to production-ready code
Databricks asset bundles (DAB)
MLflow experiment tracking & registering models in Unity Catalog
Git branching strategy & Databricks environments
Model serving architectures
Setting up model evaluation pipeline
Data/model drift detection and lakehouse monitoring
.
This course is for:
ML and DS people who want to get into or level up in MLOps.
MLEs and platform engineers who want to master Databricks.
.
Ready to level up your MLOps game?
→ Next cohort starts January 27th
→ Get 10% off with code: PAUL
→ 100% company reimbursement eligible
Fine-tuning SLMs for top-tier results at a fraction of the cost
Fine-tuning small language models (SLMs) can give you top-tier results on specialized tasks at a fraction of the cost. Here is a step-by-step tutorial ↓
Let's assume you want to use an LLM for specialized tasks such as classifying ticket requests or generating personalized emails from your private data.
A 𝗴𝗲𝗻𝗲𝗿𝗶𝗰 𝗹𝗮𝗿𝗴𝗲𝗿 𝗟𝗟𝗠, such as Mistral large (>70B parameters), can do the job, but 𝘁𝗵𝗲 𝗰𝗼𝘀𝘁𝘀 can quickly 𝗴𝗲𝘁 𝗼𝘂𝘁 𝗼𝗳 𝗵𝗮𝗻𝗱.
You can try directly using 𝘀𝗺𝗮𝗹𝗹𝗲𝗿 𝗟𝗟𝗠𝘀, such as Mistral 7B, 𝘁𝗼 𝗿𝗲𝗱𝘂𝗰𝗲 𝗰𝗼𝘀𝘁𝘀 on these specific tasks, but now the problem is their 𝗽𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝗻𝗰𝗲 𝗱𝗿𝗼𝗽𝘀 𝗱𝗿𝗮𝘀𝘁𝗶𝗰𝗮𝗹𝗹𝘆.
We encountered the accuracy vs. costs trade-off.
But we don't have to... we can 𝗴𝗲𝘁 𝘁𝗵𝗲 𝗯𝗲𝘀𝘁 𝗼𝗳 𝗯𝗼𝘁𝗵 𝘄𝗼𝗿𝗹𝗱𝘀.
𝗧𝗵𝗲 𝘀𝗼𝗹𝘂𝘁𝗶𝗼𝗻 is to fine-tune smaller LLMs to specialize them for your task to achieve good accuracy at low prices.
Using a fully managed platform like Aparajith M., you can easily fine-tune open-source LLMs and automate your business operations.
𝘏𝘦𝘳𝘦 𝘪𝘴 𝘢𝘯 𝘦𝘯𝘥-𝘵𝘰-𝘦𝘯𝘥 𝘴𝘰𝘭𝘶𝘵𝘪𝘰𝘯 𝘰𝘯 𝘩𝘰𝘸 𝘵𝘰 𝘥𝘰 𝘪𝘵 𝘶𝘴𝘪𝘯𝘨 𝘬𝘯𝘰𝘸𝘭𝘦𝘥𝘨𝘦 𝘥𝘪𝘴𝘵𝘪𝘭𝘭𝘢𝘵𝘪𝘰𝘯 𝘸𝘪𝘵𝘩 𝘚𝘯𝘰𝘸𝘧𝘭𝘢𝘬𝘦:
1. Ingest raw data, such as PDFs, emails or user profiles, into a Snowflake table.
2. Clean the data into a different Snowflake table (schedule the data pipelines for data freshness).
3. Create a training instruct dataset by computing the labels (only once) using a larger LLM (mistral-large, Llama 3 70B) on Snowflake Cortex.
4. Using the instruct dataset, fine-tune the smaller LLM (mistral or Llama 7B) and store it in Snowflake's model registry. You can kick off serverless fine-tuning jobs on Cortex through their no-code interface or SQL.
The fine-tuned LLM is available for inference. For example:
5. Load the fine-tuned LLM as a serverless service using Snowflake Cortex. The LLM has fresh features as input available from the clean data collection.
6. Use it in a Streamlit app integrated into Snowflake.
7. Use it in a batch pipeline to process ticket requests or emails on a schedule.
8. The results are saved in Snowflake and consumed through a dashboard or by emailing the users.

This strategy can easily be extrapolated to any tooling.
By using a fully managed platform such as Snowflake, you can reduce your dev time from months to days, as you have no more headaches to:
- ingest and store your data at scale
- transform your data into training datasets
- run fine-tuning and inference jobs
Build a feature pipeline for an H&M personalized recommender
We just released the second lesson of our Hands-on H&M Real-Time Personalized Recommender course on feature pipelines that leverage MLOps best practices.
In this lesson, written by
, we dive deeper into building a feature pipeline for real-time personalized recommendations that tailor H&M product suggestions for users based on the following:Their preferences
Their behaviors.
If you're a:
Data scientist
ML engineer
Passionate about recommender systems
This is your chance to get hands-on experience with a cutting-edge project.
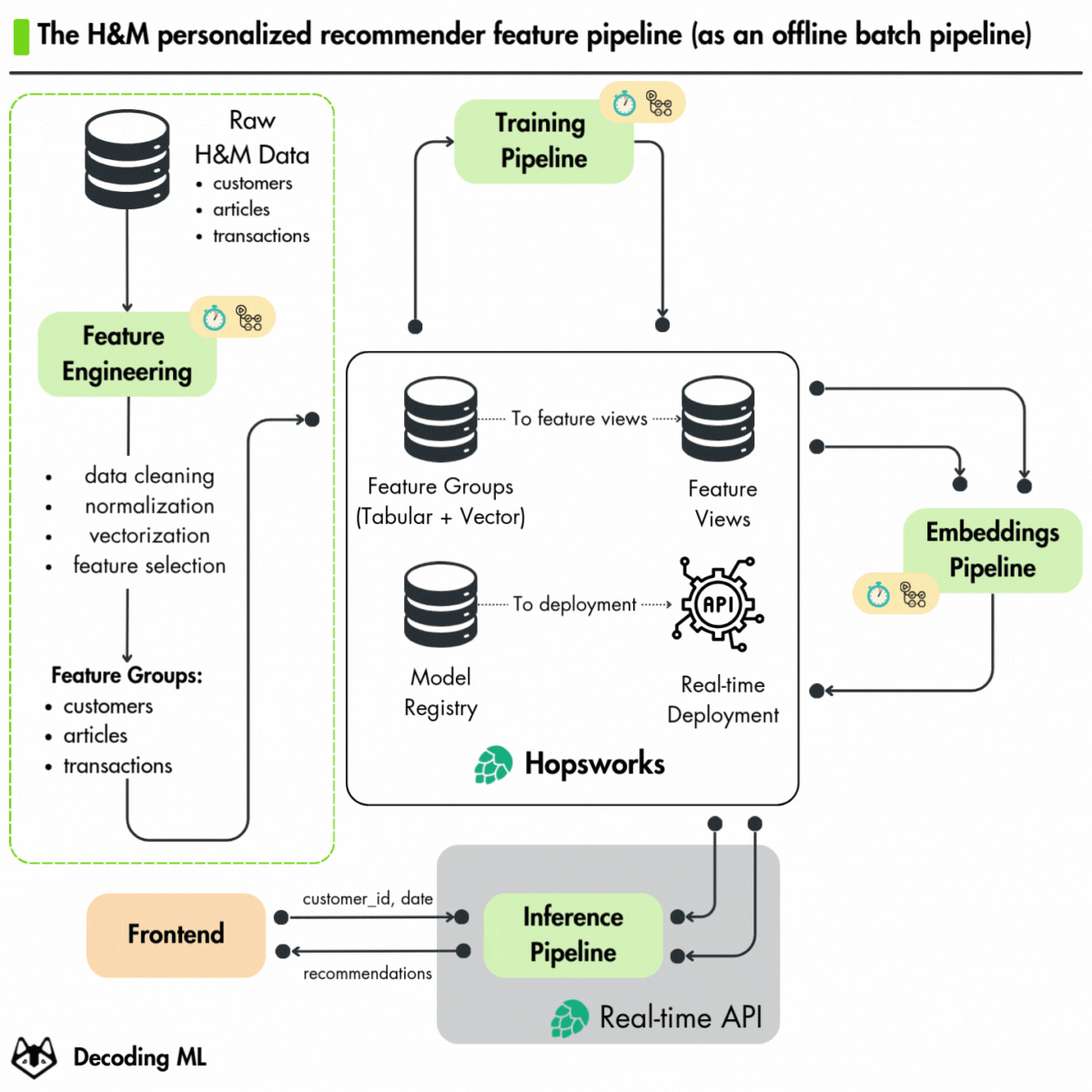
We used the Hopsworks AI Lakehouse to manage and operationalize the entire machine-learning lifecycle without worrying about infrastructure.
Here's what you’ll learn in Lesson 2:
process the H&M dataset into recsys features
engineer features for both the two-tower network and ranking models
Use Hopsworks Feature Groups for solving the training-serving skew
lay the groundwork for future steps, such as integrating streaming pipelines to enable real-time data processing and recommendations.
Get started with Lesson 2 ↓

Thank you
for this fantastic piece!Images
If not otherwise stated, all images are created by the author.