

Feature pipelines for TikTok-like recommenders
Feature engineering for a H&M real-time personalized recommender

The second lesson of the “Hands-On Real-time Personalized Recommender” open-source course — a free course that will teach you how to build and deploy a production-ready real-time personalized recommender for H&M articles using the four-stage recsys architecture, the two-tower model design and the Hopsworks AI Lakehouse.
Lessons:
Lesson 1: Building a TikTok-like recommender
Lesson 2: Feature pipelines for TikTok-like recommenders
Lesson 3: Training pipelines for TikTok-like recommenders
Lesson 4: Deploy scalable TikTok-like recommenders
Lesson 5: Using LLMs to build TikTok-like recommenders
🔗 Learn more about the course and its outline.

Lesson 2: Feature pipelines for TikTok-like recommenders
In this lesson, we’ll explore the feature pipeline that forms the backbone of a real-time personalized recommender using the H&M retail dataset.
Our primary focus will be on the steps involved in creating and managing features, which are essential for training effective machine learning models.
By the end of this lesson, you will have a thorough understanding of how to:
present and process the H&M dataset,
engineer features for both the retrieval and ranking models,
create and manage Hopsworks Feature Groups for efficient ML workflow,
lay the groundwork for future steps, such as integrating streaming pipelines to enable real-time data processing and recommendations.
💻 Explore all the lessons and the code in our freely available GitHub repository.

We need to set up the environment to start building the feature pipeline.
The following code initializes the notebook environment, checks if it’s running locally or in Google Colab, and configures the Python path to import custom modules.
import sys
from pathlib import Path
def is_google_colab() -> bool:
if "google.colab" in str(get_ipython()):
return True
return False
def clone_repository() -> None:
!git clone https://github.com/decodingml/hands-on-recommender-system.git
%cd hands-on-recommender-system/
def install_dependencies() -> None:
!pip install --upgrade uv
!uv pip install --all-extras --system --requirement pyproject.toml
if is_google_colab():
clone_repository()
install_dependencies()
root_dir = str(Path().absolute())
print("⛳️ Google Colab environment")
else:
root_dir = str(Path().absolute().parent)
print("⛳️ Local environment")
# Add the root directory to the PYTHONPATH
if root_dir not in sys.path:
print(f"Adding the following directory to the PYTHONPATH: {root_dir}")
sys.path.append(root_dir)🔗 Full code here → Github
Table of Contents
1 - The H&M dataset
2 - Feature engineering
3 - Creating Feature Groups in Hopsworks
4 - Next steps: Implementing a streaming data pipeline
5 - Running the feature pipeline
1 - The H&M dataset
Before diving into feature engineering, let’s first take a closer look at the H&M Fashion Recommendation dataset.
The dataset consists of three main tables: articles, customers, and transactions.
Below is how you can extract and inspect the data:
from recsys.raw_data_sources import h_and_m as h_and_m_raw_data
# Extract articles data
articles_df = h_and_m_raw_data.extract_articles_df()
print(articles_df.shape)
articles_df.head()
# Extract customers data
customers_df = h_and_m_raw_data.extract_customers_df()
print(customers_df.shape)
customers_df.head()
# Extract transactions data
transactions_df = h_and_m_raw_data.extract_transactions_df()
print(transactions_df.shape)
transactions_df.head()🔗 Full code here → Github
This is what the data looks like:
1 - Customers Table
Customer ID: A unique identifier for each customer.
Age: Provides demographic information, which can help predict age-related purchasing behavior.
Membership status: Indicates whether a customer is a member, which may impact buying patterns and preferences.
Fashion news frequency: Reflect how often customers receive fashion news, hinting at their engagement level.
Club member status: Show if the customer is an active club member, which can affect loyalty and purchase frequency.
FN (fashion news score): A numeric score reflecting customer's engagement with fashion-related content.
2 - Articles Table
Article ID: A unique identifier for each product.
Product group: Categorizes products into groups like dresses, tops, or shoes.
Color: Describes each product's color, which is important for visual similarity recommendations.
Department: Indicates the department to which the article belongs, providing context for the type of products.
Product type: A more detailed classification within product groups.
Product code: A unique identifier for each product variant.
Index code: Represents product indexes, useful for segmenting similar items within the same category.
3 - Transactions Table
Transaction ID: A unique identifier for each transaction.
Customer ID: Links the transaction to a specific customer.
Article ID: Links the transaction to a specific product.
Price: Reflect the transaction amount, which helps analyze spending habits.
Sales channel: Shows whether the purchase was made online or in-store.
Timestamp: Records the exact time of the transaction, useful for time-based analysis.
🔗 Full code here → Github
Tables Relationships
The tables are connected through unique identifiers like customer and article IDs. These connections are crucial for making the most of the H&M dataset:
Customer to Transactions: By associating customer IDs with transaction data, we can create behavioral features like purchase frequency, recency, and total spending, which provide insights into customer activity and preferences.
Articles to Transactions: Linking article IDs to transaction records helps us analyze product popularity, identify trends, and understand customer preferences for different types of products.
Cross-Table Analysis: Combining data from multiple tables allows us to perform advanced feature engineering. For example, we can track seasonal product trends or segment customers based on purchasing behavior, enabling more personalized recommendations.
Table relationships provide a clearer picture of how customers interact with products, which helps improve the accuracy of the recommendation model in suggesting relevant items.
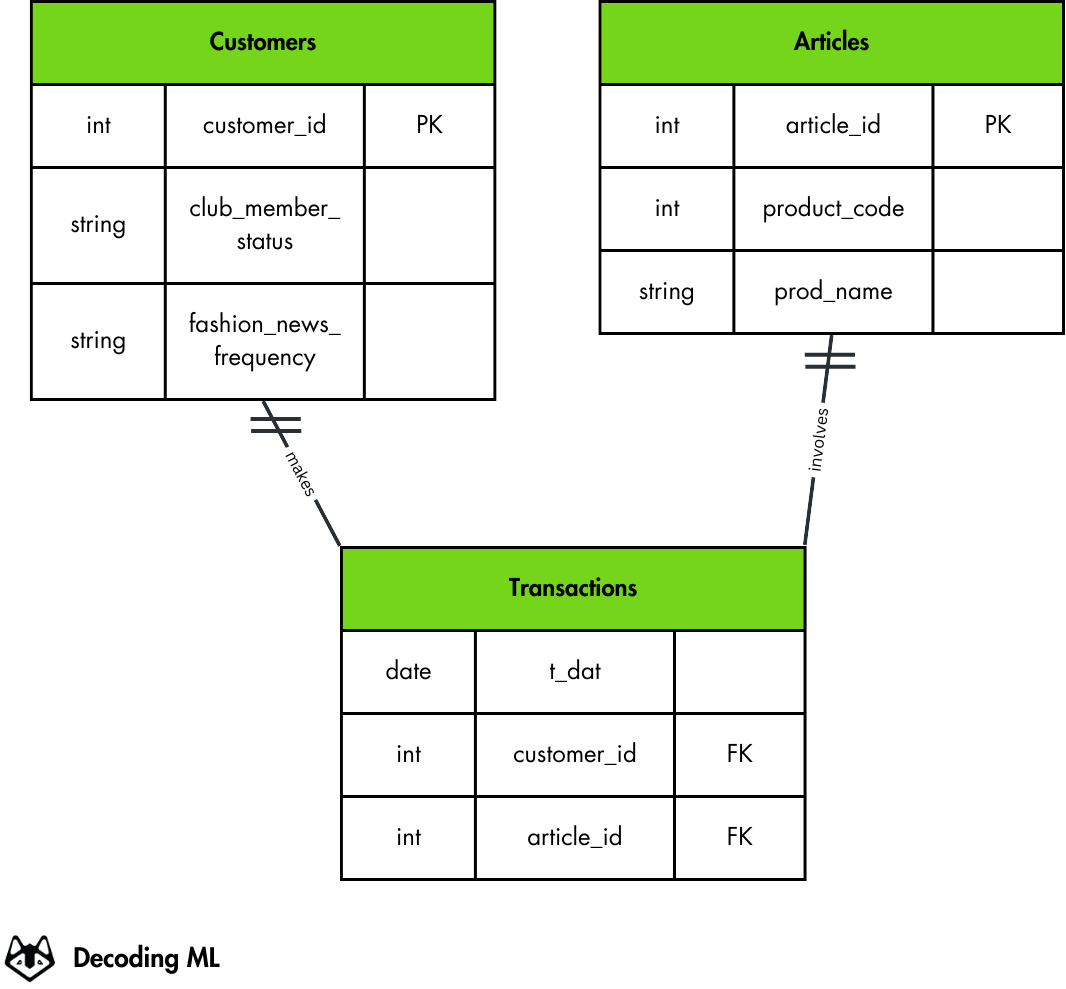
The Customers table contains customer data, including unique customer IDs (Primary Key), membership status, and fashion news preferences.
The Articles table stores product details like article IDs (Primary Key), product codes, and product names.
The Transactions table links customers and articles through purchases, with fields for the transaction date, customer ID (Foreign Key), and article ID (Foreign Key).
The double-line notations between tables indicate one-to-many relationships: each customer can make multiple transactions, and each transaction can involve multiple articles.
2 - Feature engineering
The feature pipeline takes as input raw data and outputs features and labels used for training and inference.
📚 Read more about feature pipelines and their integration into ML systems [6].
Creating effective features for both retrieval and ranking models is the foundation of a successful recommendation system.
Feature engineering for the two-tower model
The two-tower retrieval model's primary objective is to learn user and item embeddings that capture interaction patterns between customers and articles.
We use the transactions table as our source of ground truth - each purchase represents a positive interaction between a customer and an article.
This is the foundation for training the model to maximize similarity between embeddings for actual interactions (positive pairs).
The notebook imports necessary libraries and modules for feature computation.
This snippet lists the default settings used throughout the notebook, such as model IDs, learning rates, and batch sizes.
It is helpful for understanding the configuration of the feature pipeline and models.
pprint(dict(settings))
🔗 Full code here → Github
Training objective
The goal of the two-tower retrieval model is to use a minimal, strong feature set that is highly predictive but does not introduce unnecessary complexity.
The model aims to maximize the similarity between customer and article embeddings for purchased items while minimizing similarity for non-purchased items.
This objective is achieved using a loss function such as cross-entropy loss for sampled softmax, or contrastive loss. The embeddings are then optimized for nearest-neighbor search, which enables efficient filtering in downstream recommendation tasks.

Feature selection
The two-tower retrieval model intentionally uses a minimal set of strong features to learn robust embeddings:
Query features - used by the
QueryTower(the customer encoder from the two-tower model):customer_id: A categorical feature that uniquely identifies each user. This is the backbone of user embeddings.
age: A numerical feature that can capture demographical patterns.
month_sin and month_cos: Numerical features that encode cyclic patterns (e.g., seasonality) in user behavior.
Candidate features - used by the
ItemTower(the H&M fashion articles encoder from the two-tower model):article_id: A categorical feature that uniquely identifies each item. This is the backbone of item embeddings.
garment_group_name: A categorical feature that captures high-level categories (e.g., "T-Shirts", "Dresses") to provide additional context about the item.
index_group_name: A categorical feature that captures broader item groupings (e.g., "Menswear", "Womenswear") to provide further context.
These features are passed through their respective towers to generate the query (user) and item embeddings, which are then used to compute similarities during retrieval.
The limited feature set is optimized for the retrieval stage, focusing on quickly identifying candidate items through an approximate nearest neighbor (ANN) search.
This aligns with the four-stage recommender system architecture, ensuring efficient and scalable item retrieval.
This snippet computes features for articles, such as product descriptions and metadata, and displays their structure.
articles_df = compute_features_articles(articles_df)
articles_df.shape
articles_df.head(3)
compute_features_articles() takes the articles dataframe and transforms it into a dataset with 27 features across 105,542 articles.
import polars as pl
def compute_features_articles(df: pl.DataFrame) -> pl.DataFrame:
df = df.with_columns(
[
get_article_id(df).alias("article_id"),
create_prod_name_length(df).alias("prod_name_length"),
pl.struct(df.columns)
.map_elements(create_article_description)
.alias("article_description"),
]
)
# Add full image URLs.
df = df.with_columns(image_url=pl.col("article_id").map_elements(get_image_url))
# Drop columns with null values
df = df.select([col for col in df.columns if not df[col].is_null().any()])
# Remove 'detail_desc' column
columns_to_drop = ["detail_desc", "detail_desc_length"]
existing_columns = df.columns
columns_to_keep = [col for col in existing_columns if col not in columns_to_drop]
return df.select(columns_to_keep)One standard approach when manipulating text before feeding it into a model is to embed it. This solves the curse of dimensionality or information loss from solutions such as one-hot encoding or hashing.
The following snippet generates embeddings for article descriptions using a pre-trained SentenceTransformer model.
device = (
"cuda" if torch.cuda.is_available()
else "mps" if torch.backends.mps.is_available()
else "cpu"
)
logger.info(f"Loading '{settings.FEATURES_EMBEDDING_MODEL_ID}' embedding model to {device=}")
# Load the embedding model
model = SentenceTransformer(settings.FEATURES_EMBEDDING_MODEL_ID, device=device)
# Generate embeddings for articles
articles_df = generate_embeddings_for_dataframe(
articles_df, "article_description", model, batch_size=128
)🔗 Full code here → Github
Features engineering for the Ranking model
The ranking model has a more complex objective: accurately predicting the likelihood of purchase for each retrieved item.
This model uses a combination of query and item features, along with labels, to predict the likelihood of interaction between users and items.
This feature set is designed to provide rich contextual and descriptive information, enabling the model to rank items effectively.
Generate features for customers:
Training objective
The model is trained to predict purchase probability, with actual purchases (from the Transactions table) serving as positive labels (1) and non-purchases as negative labels (0).
This binary classification objective helps order retrieved items by their likelihood of purchase.

Feature selection
Query Features - identical to those used in the Retrieval Model to encode the customer
Item Features - used to represent the articles in the dataset. These features describe the products' attributes and help the model understand item properties and relationships:
article_id: A categorical feature that uniquely identifies each item, forming the foundation of item representation.
product_type_name: A categorical feature that describes the specific type of product (e.g., "T-Shirts", "Dresses"), providing detailed item-level granularity.
product_group_name: A categorical feature for higher-level grouping of items, useful for capturing broader category trends.
graphical_appearance_name: A categorical feature representing the visual style of the item (e.g., "Solid", "Striped").
colour_group_name: A categorical feature that captures the color group of the item (e.g., "Black", "Blue").
perceived_colour_value_name: A categorical feature describing the brightness or value of the item's color (e.g., "Light", "Dark").
perceived_colour_master_name: A categorical feature representing the master color of the item (e.g., "Red", "Green"), providing additional color-related information.
department_name: A categorical feature denoting the department to which the item belongs (e.g., "Menswear", "Womenswear").
index_name: A categorical feature representing broader categories, providing a high-level grouping of items.
index_group_name: A categorical feature that groups items into overarching divisions (e.g., "Divided", "H&M Ladies").
section_name: A categorical feature describing the specific section within the store or catalog.
garment_group_name: A categorical feature that captures high-level garment categories (e.g., "Jackets", "Trousers"), helping the model generalize across similar items.
Label - A binary feature used for supervised learning
`1` indicates a positive pair (customer purchased the item).
`0` indicates a negative pair (customer did not purchase the item, randomly sampled).
This approach is designed for the ranking stage of the recommender system, where the focus shifts from generating candidates to fine-tuning recommendations with higher precision.
By incorporating both query and item features, the model ensures that recommendations are relevant and personalized.
Constructing the final ranking dataset
The ranking dataset is the final dataset used to train the scoring/ranking model in the recommendation pipeline.
It is computed by combining query (customer) features, item (article) features, and the interactions (transactions) between them.
The compute_ranking_dataset() combines the different features from the Feature Groups:
`trans_fg`: The transactions Feature Group, which provides the labels (`1` for positive pairs and `0` for negative pairs) and additional interaction-based features (e.g., recency, frequency).
`articles_fg`: The articles Feature Group, which contains the engineered item features (e.g., product type, color, department, etc.).
`customers_fg`: The customers Feature Group, which contains customer features (e.g., age, membership status, purchase behavior).
The resulting ranking dataset includes:
Customer Features: From `customers_fg`, representing the query.
Item Features: From `articles_fg`, representing the candidate items.
Interaction Features: From `trans_fg`, such as purchase frequency or recency, which capture behavioral signals.
Label: A binary label (`1` for purchased items, `0` for negative samples).
The result is a dataset where each row represents a customer-item pair, with the features and label indicating whether the customer interacted with the item.
In practice, this looks like this:
ranking_df = compute_ranking_dataset(
trans_fg,
articles_fg,
customers_fg,
)
ranking_df.shapeNegative sampling for the ranking dataset
The ranking dataset includes both positive and negative samples.
This ensures the model learns to differentiate between relevant and irrelevant items:
Positive samples (Label = 1): derived from the transaction Feature Group (`trans_fg`), where a customer purchased a specific item.
Negative samples (Labels = 0): generated by randomly sampling items the customer did not purchase. These represent items the customer is less likely to interact with and help the model better understand what is irrelevant to the user.
# Inspect the label distribution in the ranking dataset
ranking_df.get_column("label").value_counts()Outputs:
label count
i32 u32
1 20377
0 203770Negative Samples are constrained to make them realistic, such as sampling items from the same category or department as the customer's purchases or including popular items the customer hasn’t interacted with, simulating plausible alternatives.
For example, if the customer purchased a "T-shirt," negative samples could include other "T-shirts” they didn't buy.
Negative samples are often balanced in proportion to positive ones. For every positive sample, we might add 1 to 5 negative ones. This prevents the model from favoring negative pairs, which are much more common in real-world data.
import polars as pl
def compute_ranking_dataset(trans_fg, articles_fg, customers_fg) -> pl.DataFrame:
... # More code
# Create positive pairs
positive_pairs = df.clone()
# Calculate number of negative pairs
n_neg = len(positive_pairs) * 10
# Create negative pairs DataFrame
article_ids = (df.select("article_id")
.unique()
.sample(n=n_neg, with_replacement=True, seed=2)
.get_column("article_id"))
customer_ids = (df.select("customer_id")
.sample(n=n_neg, with_replacement=True, seed=3)
.get_column("customer_id"))
other_features = (df.select(["age"])
.sample(n=n_neg, with_replacement=True, seed=4))
# Construct negative pairs
negative_pairs = pl.DataFrame({
"article_id": article_ids,
"customer_id": customer_ids,
"age": other_features.get_column("age"),
})
# Add labels
positive_pairs = positive_pairs.with_columns(pl.lit(1).alias("label"))
negative_pairs = negative_pairs.with_columns(pl.lit(0).alias("label"))
# Concatenate positive and negative pairs
ranking_df = pl.concat([
positive_pairs,
negative_pairs.select(positive_pairs.columns)
])
... More code
return ranking_df3 - Creating Feature Groups in Hopsworks
Once the ranking dataset is computed, it is uploaded to Hopsworks as a new Feature Group, with lineage information reflecting its dependencies on the parent Feature Groups (`articles_fg`, `customers_fg`, and `trans_fg`).
logger.info("Uploading 'ranking' Feature Group to Hopsworks.")
rank_fg = feature_store.create_ranking_feature_group(
fs,
df=ranking_df,
parents=[articles_fg, customers_fg, trans_fg],
online_enabled=False
)
logger.info("✅ Uploaded 'ranking' Feature Group to Hopsworks!!")This lineage ensures that any updates to the parent Feature Groups (e.g., new transactions or articles) can be propagated to the ranking dataset, keeping it up-to-date and consistent.
The Hopsworks Feature Store is a centralized repository for managing features.
The following shows how to authenticate and connect to the feature store:
from recsys import hopsworks_integration
# Connect to Hopsworks Feature Store
project, fs = hopsworks_integration.get_feature_store()🔗 Full code here → Github
Step 1: Define Feature Groups
Feature Groups are logical groupings of related features that can be used together in model training and inference.
For example:
1 - Customer Feature Group
Includes all customer-related features, such as demographic, behavioral, and engagement metrics.
Demographics: Age, gender, membership status.
Behavioral features: Purchase history, average spending, visit frequency.
Engagement metrics: Fashion news frequency, club membership status.
2 - Article Feature Group
It includes features related to articles (products), such as descriptive attributes, popularity metrics, and image features.
Descriptive attributes: Product group, color, department, product type, product code.
Popularity metrics: Number of purchases, ratings.
Image features: Visual embeddings derived from product images.
3 - Transaction Feature Group
Includes all transaction-related features, such as transactional details, interaction metrics, and contextual features.
Transactional attributes: Transaction ID, customer ID, article ID, price.
Interaction metrics: Recency and frequency of purchases.
Contextual features: Sales channel, timestamp of transaction.
Adding a feature group to Hopsworks:
from recsys.hopsworks_integration.feature_store import create_feature_group
# Create a feature group for article features
create_feature_group(
feature_store=fs,
feature_data=article_features_df,
feature_group_name="articles_features",
description="Features for articles in the H&M dataset"
)🔗 Full code here → Github
Step 2: Data ingestion
To ensure the data is appropriately structured and ready for model training and inference, the next step involves loading data from the H&M dataset into the respective Feature Groups in Hopsworks.
Here’s how it works:
1 - Data loading
Start by extracting data from the H&M source files, processing them into features and loading them into the correct Feature Groups.
2 - Data validation
After loading, check that the data is accurate and matches the expected structure.
Consistency checks: Verify the relationships between datasets are correct.
Data cleaning: Address any issues in the data, such as missing values, duplicates, or inconsistencies.
Luckily, Hopsworks supports integration with Great Expectations, adding a robust data validation layer during data loading.
Step 3: Versioning and metadata management
Versioning and metadata management are essential for keeping your Feature Groups organized and ensuring models can be reproduced.
The key steps are:
Version control: Track different versions of Feature Groups to ensure you can recreate and validate models using specific data versions. For example, if there are significant changes to the Customer Feature Group, create a new version to reflect those changes.
Metadata management: Document the details of each feature, including its definition, how it’s transformed, and any dependencies it has on other features.
rank_fg = fs.get_or_create_feature_group(
name="ranking",
version=1,
description="Derived feature group for ranking",
primary_key=["customer_id", "article_id"],
parents=[articles_fg, customers_fg, trans_fg],
online_enabled=online_enabled,
)
rank_fg.insert(df, write_options={"wait_for_job": True})
for desc in constants.ranking_feature_descriptions:
rank_fg.update_feature_description(desc["name"], desc["description"])Defining Feature Groups, managing data ingestion, and tracking versions and metadata ensure your features are organized, reusable, and reliable, making it easier to maintain and scale your ML workflows.
View results in Hopsworks Serverless: Feature Store → Feature Groups
The importance of Hopsworks Feature Groups
Hopsworks Feature Groups are key in making machine learning workflows more efficient and organized.
Here’s how they help:
1 - Centralized repository
Single source of truth: Feature Groups in Hopsworks provide a centralized place for all your feature data, ensuring everyone on your team uses the same, up-to-date data. This reduces the risk of inconsistencies and errors when different people use outdated or other datasets.
Easier management: Managing all features in one place becomes easier. Updating, querying, and maintaining the features is streamlined, leading to increased productivity and smoother workflows.
2- Feature reusability
Cross-model consistency: Features stored in Hopsworks can be used across different models and projects, ensuring consistency in their definition and application. This eliminates the need to re-engineer features each time, saving time and effort.
Faster development: Since you can reuse features, you don’t have to start from scratch. You can quickly leverage existing, well-defined features, speeding up the development and deployment of new models.
3 - Scalability
Optimized Performance: The platform ensures that queries and feature updates are performed quickly, even when dealing with large amounts of data. This is crucial for maintaining model performance in production.
4 - Versioning and lineage
Version control: Hopsworks provides version control for Feature Groups, so you can keep track of changes made to features over time. This helps reproducibility, as you can return to previous versions if needed.
Data lineage: Tracking data lineage lets you document how features are created and transformed. This adds transparency and helps you understand the relationships between features.
Read more on feature groups [4] and how to integrate them into ML systems.
4 - Next Steps: Implementing a streaming data pipeline
Imagine you’re running H&M’s online recommendation system, which delivers personalized product suggestions to millions of shoppers.
Currently, the system uses a static pipeline: embeddings for users and products are precomputed using a two-tower model and stored in an Approximate Nearest Neighbor (ANN) index.
When users interact with the site, similar products are retrieved, filtered (e.g., excluding seen or out-of-stock items), and ranked by a machine learning model.
While this approach works well offline, it struggles to adapt to real-time changes, such as shifts in user preferences or the launch of new products.
You must shift to a streaming data pipeline to make the recommendation system dynamic and responsive.

Step 1 - Integrating real-time data
The first step is to introduce real-time data streams into your pipeline. To begin, think about the types of events your system needs to handle:
User behavior: Real-time interactions such as clicks, purchases, and searches to keep up with evolving preferences.
Product updates: Stream data on new arrivals, price changes, and stock updates to ensure recommendations reflect the most up-to-date catalog.
Embedding updates: Continuously recalculate user and product embeddings to maintain the accuracy and relevance of the recommendation model.
Step 2: Updating the retrieval stage
In a static pipeline, retrieval depends on a precomputed ANN index that matches user and item embeddings based on similarity.
However, as embeddings evolve, keeping the retrieval process synchronized with these changes is crucial to maintain accuracy and relevance.
Hopsworks supports upgrading the ANN index. This simplifies embedding updates and keeps the retrieval process aligned with the latest embeddings.
Here’s how to upgrade the retrieval stage:
Upgrade the ANN index: Switch to a system capable of incremental updates, like FAISS, ScaNN, or Milvus. These libraries support real-time similarity searches and can instantly incorporate new and updated embeddings.
Stream embedding updates: Integrate a message broker like Kafka to feed updated embeddings into the system. As a user’s preferences change or new items are added, their corresponding embeddings should be updated in real-time.
Ensure freshness: Build a mechanism to prioritize the latest embeddings during similarity searches. This ensures that recommendations are always based on the most current user preferences and available content.
Step 3: Updating the filtering stage
After retrieving a list of candidate items, the next step is filtering out irrelevant or unsuitable options. In a static pipeline, filtering relies on precomputed data like whether a user has already watched a video or if it’s regionally available.
However, filtering needs to adapt instantly to new data for a real-time system.
Here’s how to update the filtering stage:
Track recent customer activity: Use a stream processing framework like Apache Flink or Kafka Streams to maintain a real-time record of customer interactions
Dynamic stock availability: Continuously update item availability based on real-time inventory data. If an item goes out of stock, it should be filtered immediately.
Personalized filters: Apply personalized rules in real-time, such as excluding items that don’t match a customer’s size, color preferences, or browsing history.
5 - Running the feature pipeline
First, you must create an account on Hopsworks’s Serverless platform. Both making an account and running our code are free.
Then you have 3 main options to run the feature pipeline:
In a local Notebook or Google Colab: access instructions
As a Python script from the CLI, access instructions
GitHub Actions: access instructions
View the results in Hopsworks Serverless: Feature Store → Feature Groups
We recommend using GitHub Actions if you have a poor internet connection and keep getting timeout errors when loading data to Hopsworks. This happens because we push millions of items to Hopsworks.
Conclusion
In this lesson, we covered the essential components of the feature pipeline, from understanding the H&M dataset to engineering features for both retrieval and ranking models.
We also introduced Hopsworks Feature Groups, emphasizing their importance in effectively organizing, managing, and reusing features.
Lastly, we covered the transition to a real-time streaming pipeline, which is crucial for making recommendation systems adaptive to evolving user behaviors.
With this foundation, you can manage and optimize features for high-performing machine learning systems that deliver personalized, high-impact user experiences.
In Lesson 3, we’ll dive into the training pipeline, focusing on training, evaluating, and managing retrieval and ranking models using the Hopsworks model registry.
💻 Explore all the lessons and the code in our freely available GitHub repository.
If you have questions or need clarification, feel free to ask. See you in the next session!
References
Literature
[1] Decodingml. (n.d.). GitHub - decodingml/personalized-recommender-course. GitHub. https://github.com/decodingml/personalized-recommender-course
[2] Zhang, S., Yao, L., Sun, A., & Tay, Y. (2019). Deep learning based recommender system: A survey and new perspectives. ACM Transactions on Information Systems, 37(1), Article 5. https://doi.org/10.1145/3285029
[3] Zheng, A., & Casari, A. (2018). Feature engineering for machine learning: Principles and techniques for data scientists. O'Reilly Media.
[4] Hopsworks. (n.d.). Overview - HopsWorks documentation. https://docs.hopsworks.ai/latest/concepts/fs/feature_group/fg_overview/
[5] Hopsworks. (n.d.-b). Overview - HopsWorks documentation. https://docs.hopsworks.ai/latest/concepts/fs/feature_view/fv_overview/
[6] Hopsworks. (n.d.). What is a Feature Pipeline? - Hopsworks. https://www.hopsworks.ai/dictionary/feature-pipeline
Images
If not otherwise stated, all images are created by the author.
Sponsors
Thank our sponsors for supporting our work!

Setting up the repo locally but having some issues, would hhave to take a look again
TypeError: Unable to convert function return value to a Python type! The signature was
() -> handle
All good 👍 here now, it was dependencies that needed to be resolved.