

Your RAG is wrong: Here's how to fix it
The blueprint to advanced RAG (Retrieval-Augmented Generation)

The vanilla RAG framework doesn’t address many fundamental aspects that impact the quality of the retrieval and answer generation, such as:
Are the retrieved documents relevant to the user’s question?
Is the retrieved context enough to answer the user’s question?
Is there any redundant information that only adds noise to the augmented prompt?
Does the latency of the retrieval step match our requirements?
What do we do if we can’t generate a valid answer using the retrieved information?
We've got you covered if you are unfamiliar with the vanilla RAG framework. ↓

From the questions above, we can draw two conclusions.
The first one is that we need a robust evaluation module for our RAG system that can quantify and measure the quality of the retrieved data and generate answers relative to the user’s question.
The second conclusion is that we must improve our RAG framework to address the retrieval limitations directly in the algorithm. These improvements are known as advanced RAG.
This article will focus on the second conclusion, answering the question: “How can I optimize an RAG system?”.
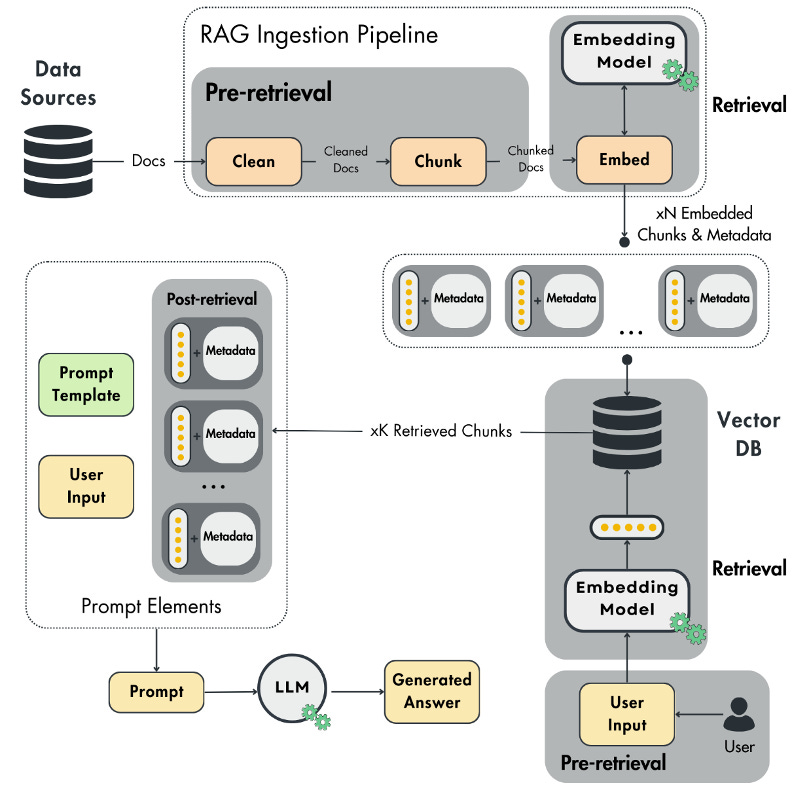
The vanilla RAG design can be optimized at three different stages:
Pre-retrieval: This stage focuses on structuring and preprocessing your data for data indexing and query optimizations.
Retrieval: This stage revolves around improving the embedding models and metadata filtering to improve the vector search step.
Post-retrieval: This stage mainly targets different ways to filter out noise from the retrieved documents and compress the prompt before feeding it to an LLM for answer generation.
1. Pre-retrieval
The pre-retrieval steps are performed in two different ways:
Data indexing: It is part of the RAG ingestion pipeline. It is mainly implemented within the cleaning or chunking modules to preprocess the data for better indexing.
Query optimization: The algorithm is performed directly on the user’s query before embedding it and retrieving the chunks from the vector DB.
As we index our data using embeddings that semantically represent the content of a chunked document, most of the data indexing techniques focus on better preprocessing and structuring the data to improve retrieval efficiency.
Here are a few popular methods for optimizing data indexing.
1. Sliding window
The sliding window technique introduces overlap between text chunks, ensuring that important context near chunk boundaries is retained, which enhances retrieval accuracy.
This is particularly beneficial in domains like legal documents, scientific papers, customer support logs, and medical records, where critical information often spans multiple sections.
The embedding is computed on the chunk along with the overlapping portion. Hence, the sliding window improves the system’s ability to retrieve relevant and coherent information by maintaining context across boundaries.
2. Enhancing data granularity
This involves data cleaning techniques like removing irrelevant details, verifying factual accuracy, and updating outdated information. A clean and accurate dataset allows for sharper retrieval.
3. Metadata
Adding metadata tags like dates, URLs, external IDs, or chapter markers helps filter results efficiently during retrieval.
4. Optimizing index structures
It is based on different data index methods, such as various chunk sizes and multi-indexing strategies.
5. Small-to-big
The algorithm decouples the chunks used for retrieval and the context used in the prompt for the final answer generation.
The algorithm uses a small sequence of text to compute the embedding while preserving the sequence itself and a wider window around it in the metadata. Thus, using smaller chunks enhances the retrieval’s accuracy, while the larger context adds more contextual information to the LLM.
The intuition behind this is that if we use the whole text for computing the embedding, we might introduce too much noise, or the text could contain multiple topics, which results in a poor overall semantic representation of the embedding.
On the query optimization side, we can leverage techniques such as query routing, query rewriting, and query expansion to refine the retrieved information for the LLM further.
1. Query routing
Based on the user’s input, we might have to interact with different categories of data and query each category differently.
Query rooting is used to decide what action to take based on the user’s input, similar to if/else statements. Still, the decisions are made solely using natural language instead of logical statements.
As illustrated in Figure 2, let’s assume that, based on the user’s input, to do RAG, we can retrieve additional context from a vector DB using vector search queries, a standard SQL DB by translating the user query to an SQL command, or the internet by leveraging REST API calls.
The query router can also detect whether a context is required, helping us avoid making redundant calls to external data storage. Also, a query router can pick the best prompt template for a given input.
The routing usually uses an LLM to decide what route to take or embeddings by picking the path with the most similar vectors.
To summarize, query routing is identical to an if/else statement but much more versatile as it works directly with natural language.

2. Query rewriting
Sometimes, the user’s initial query might not perfectly align with how your data is structured. Query rewriting tackles this by reformulating the question to match the indexed information better.
This can involve techniques like:
Paraphrasing: Rephrasing the user’s query while preserving its meaning (e.g., “What are the causes of climate change?” could be rewritten as “Factors contributing to global warming”).
Synonym substitution: Replacing less common words with synonyms to broaden the search scope (e.g., “ joyful” could be rewritten as “happy”).
Sub-queries: For longer queries, we can break them down into multiple shorter and more focused sub-queries. This can help the retrieval stage identify relevant documents more precisely.
3. Hypothetical document embeddings (HyDE)
This technique involves having an LLM create a hypothetical response to the query. Then, both the original query and the LLM’s response are fed into the retrieval stage.
4. Query expansion
This approach aims to enrich the user’s question by adding additional terms or concepts, resulting in different perspectives of the same initial question. For example, when searching for “disease,” you can leverage synonyms and related terms associated with the original query words and also include “illnesses” or “ailments.”
5. Self-query
The core idea is to map unstructured queries into structured ones. An LLM identifies key entities, events, and relationships within the input text. These identities are used as filtering parameters to reduce the vector search space (e.g., identify cities within the query, for example, “Paris,” and add it to your filter to reduce your vector search space).
Both data indexing and query optimization pre-retrieval optimization techniques depend highly on your data type, structure, and source. Thus, as with any data processing pipeline, no method always works, as every use case has its own particularities and gotchas.
Optimizing your pre-retrieval RAG layer is experimental. Thus, what is essential is to try multiple methods (such as the ones enumerated in this section), reiterate, and observe what works best.
2. Retrieval
The retrieval step can be optimized in two fundamental ways:
Improving the embedding models used in the RAG ingestion pipeline to encode the chunked documents and, at inference time, transform the user’s input.
Leveraging the DB’s filter and search features. This step will be used solely at inference time when you have to retrieve the most similar chunks based on user input.
Both strategies are aligned with our ultimate goal: to enhance the vector search step by leveraging the semantic similarity between the query and the indexed data.
When improving the embedding models, you usually have to fine-tune the pre-trained embedding models to tailor them to specific jargon and nuances of your domain, especially for areas with evolving terminology or rare terms.
Instead of fine-tuning the embedding model, you can leverage instructor models, such as instructor-xl, to guide the embedding generation process with an instruction/prompt aimed at your domain. Tailoring your embedding network to your data using such a model can be a good option, as fine-tuning a model consumes more computing and human resources.
In the code snippet below, you can see an example of an Instructor model that embeds article titles about AI:
from InstructorEmbedding import INSTRUCTOR
model = INSTRUCTOR(“hkunlp/instructor-base”)
sentence = “RAG Fundamentals First”
instruction = “Represent the title of an article about AI:”
embeddings = model.encode([[instruction, sentence]])
print(embeddings.shape) # noqa
# Output: (1, 768)On the other side of the spectrum, here is how you can improve your retrieval by leveraging classic filter and search DB features.
Hybrid search
This is a vector and keyword-based search blend.
Keyword-based search excels at identifying documents containing specific keywords. When your task demands pinpoint accuracy, and the retrieved information must include exact keyword matches, hybrid search shines. Vector search, while powerful, can sometimes struggle with finding exact matches, but it excels at finding more general semantic similarities.
You leverage both keyword matching and semantic similarities by combining the two methods. You have a parameter, usually called alpha, that controls the weight between the two methods. The algorithm has two independent searches, which are later normalized and unified.
Filtered vector search
This type of search leverages the metadata index to filter for specific keywords within the metadata. It differs from a hybrid search in that you retrieve the data once using only the vector index and perform the filtering step before or after the vector search to reduce your search space.
In practice, you usually start with filtered vector or hybrid search on the retrieval side, as they are fairly quick to implement. This approach gives you the flexibility to adjust your strategy based on performance.
If the results are unexpected, you can always fine-tune your embedding model.
3. Post-retrieval
The post-retrieval optimizations are solely performed on the retrieved data to ensure that the LLM’s performance is not compromised by issues such as limited context windows or noisy data.
This is because the retrieved context can sometimes be too large or contain irrelevant information, both of which can distract the LLM.
Two popular methods performed at the post-retrieval step are the following.
Prompt compression
Eliminate unnecessary details while keeping the essence of the data.
Re-ranking
Use a cross-encoder ML model to give a matching score between the user’s input and every retrieved chunk.

The retrieved items are sorted based on this score. Only the top N results are kept as the most relevant. As you can see in Figure 3, this works because the re-ranking model can find more complex relationships between the user input and some content than a simple similarity search.
However, we can’t apply this model at the initial retrieval step because it is costly. That is why a popular strategy is to retrieve the data using a similarity distance between the embeddings and refine the retrieved information using a re-raking model, as illustrated in Figure 4.

Conclusion
The abovementioned techniques are far from an exhaustive list of all potential solutions. We used them as examples to get an intuition on what you can (and should) optimize at each step in your RAG workflow.
The truth is that these techniques can vary tremendously by the type of data you work with. For example, if you work with multi-modal data such as text and images, most of the techniques from earlier won’t work as they are designed for text only.
To summarize, the primary goal of these optimizations is to enhance the RAG algorithm at three key stages: pre-retrieval, retrieval, and post-retrieval.
This involves preprocessing data for improved vector indexing, adjusting user queries for more accurate searches, enhancing the embedding model, utilizing classic filtering DB operations, and removing noisy data.
By keeping these goals in mind, you can optimize your RAG workflow for data processing and retrieval.
Our latest book, the LLM Engineer’s Handbook, inspired this article.
If you liked this article, consider supporting our work by buying our book and getting access to an end-to-end framework on how to engineer production LLM & RAG applications, from data collection to fine-tuning, serving and LLMOps:

Images
If not otherwise stated, all images are created by the author.
Very helpful article
Insightful 👏
Thanks for this!