



Architect scalable and cost-effective LLM & RAG inference pipelines
Design, build and deploy RAG inference pipeline using LLMOps best practices.

→ the 9th out of 11 lessons of the LLM Twin free course
Why is this course different?
By finishing the “LLM Twin: Building Your Production-Ready AI Replica” free course, you will learn how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices.
Why should you care? 🫵
→ No more isolated scripts or Notebooks! Learn production ML by building and deploying an end-to-end production-grade LLM system.
More details on what you will learn within the LLM Twin course, here 👈
Latest Lessons of the LLM Twin Course
Lesson 6: The Role of Feature Stores in Fine-Tuning LLMs
→ Custom Dataset Generation, Artifact Versioning, GPT3.5-Turbo Distillation, Qdrant
Lesson 7: How to fine-tune LLMs on custom datasets at Scale using Qwak and CometML
→QLoRA, PEFT, Fine-tuning Mistral-7b-Instruct on custom dataset, Qwak, Comet ML
Lesson 8: Best practices when evaluating fine-tuned LLM models
→ LLM Evaluation techniques: Does and don’ts, Quantitive and manual LLM evaluation techniques
Lesson 9: Architect scalable and cost-effective LLM & RAG inference pipelines
In Lesson 9, we will focus on implementing and deploying the inference pipeline of the LLM twin system.
First, we will design and implement a scalable LLM & RAG inference pipeline based on microservices, separating the ML and business logic into two layers.
Secondly, we will use Comet ML to integrate a prompt monitoring service to capture all input prompts and LLM answers for further debugging and analysis.
Ultimately, we will deploy the inference pipeline to Qwak and make the LLM twin service available worldwide.
→ Context from previous lessons. What you must know.
This lesson is part of a more extensive series in which we learn to build an end-to-end LLM system using LLMOps best practices.
If you haven’t read the whole series, for this one to make sense, you have to know that we have a:
Qdrant vector DB populated with digital data (posts, articles, and code snippets)
vector DB retrieval module to do advanced RAG
fine-tuned open-source LLM available in a model registry from Comet ML
→ In this lesson, we will focus on gluing everything together into a scalable inference pipeline and deploying it to the cloud.
Table of Contents
The architecture of the inference pipeline
The training vs. the inference pipeline
The RAG business module
The LLM microservice
Prompt monitoring
Deploying and running the inference pipeline
Conclusion
1. The architecture of the inference pipeline
Our inference pipeline contains the following core elements:
a fine-tuned LLM
a RAG module
a monitoring service
Let’s see how to hook these into a scalable and modular system.
The interface of the inference pipeline
As we follow the feature/training/inference (FTI) pipeline architecture, the communication between the 3 core components is clear.
Our LLM inference pipeline needs 2 things:
a fine-tuned LLM: pulled from the model registry
features for RAG: pulled from a vector DB (which we modeled as a logical feature store)
This perfectly aligns with the FTI architecture.
→ If you are unfamiliar with the FTI pipeline architecture, we recommend you review Lesson 1’s section on the 3-pipeline architecture.
Monolithic vs. microservice inference pipelines
Usually, the inference steps can be split into 2 big layers:
the LLM service: where the actual inference is being done
the business service: domain-specific logic
We can design our inference pipeline in 2 ways.
Option 1: Monolithic LLM & business service
In a monolithic scenario, we implement everything into a single service.
Pros:
easy to implement
easy to maintain
Cons:
harder to scale horizontally based on the specific requirements of each component
harder to split the work between multiple teams
not being able to use different tech stacks for the two services
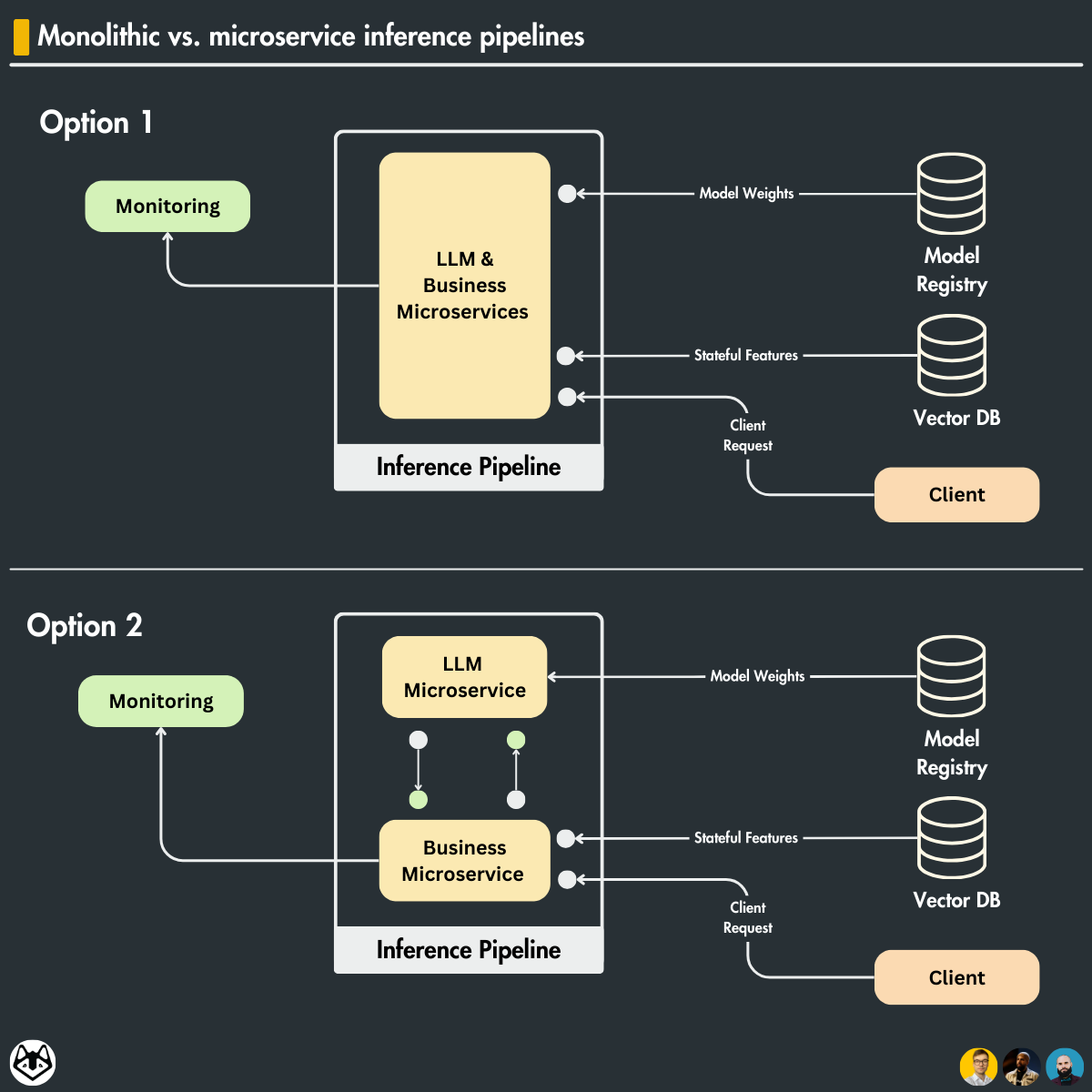
Option 2: Different LLM & business microservices
The LLM and business services are implemented as two different components that communicate with each other through the network, using protocols such as REST or gRPC.
Pros:
each component can scale horizontally individually
each component can use the best tech stack at hand
Cons:
harder to deploy
harder to maintain
Let’s focus on the “each component can scale individually” part, as this is the most significant benefit of the pattern. Usually, LLM and business services require different types of computing. For example, an LLM service depends heavily on GPUs, while the business layer can do the job only with a CPU.
Microservice architecture of the LLM twin inference pipeline
Let’s understand how we applied the microservice pattern to our concrete LLM twin inference pipeline.
As explained in the sections above, we have the following components:
A business microservice
An LLM microservice
A prompt monitoring microservice
The business microservice is implemented as a Python module that:
contains the advanced RAG logic, which calls the vector DB and GPT-4 API for advanced RAG operations;
calls the LLM microservice through a REST API using the prompt computed utilizing the user’s query and retrieved context
sends the prompt and the answer generated by the LLM to the prompt monitoring microservice.
As you can see, the business microservice is light. It glues all the domain steps together and delegates the computation to other services.
The end goal of the business layer is to act as an interface for the end client. In our case, as we will ship the business layer as a Python module, the client will be a Streamlit application.
However, you can quickly wrap the Python module with FastAPI and expose it as a REST API to make it accessible from the cloud.
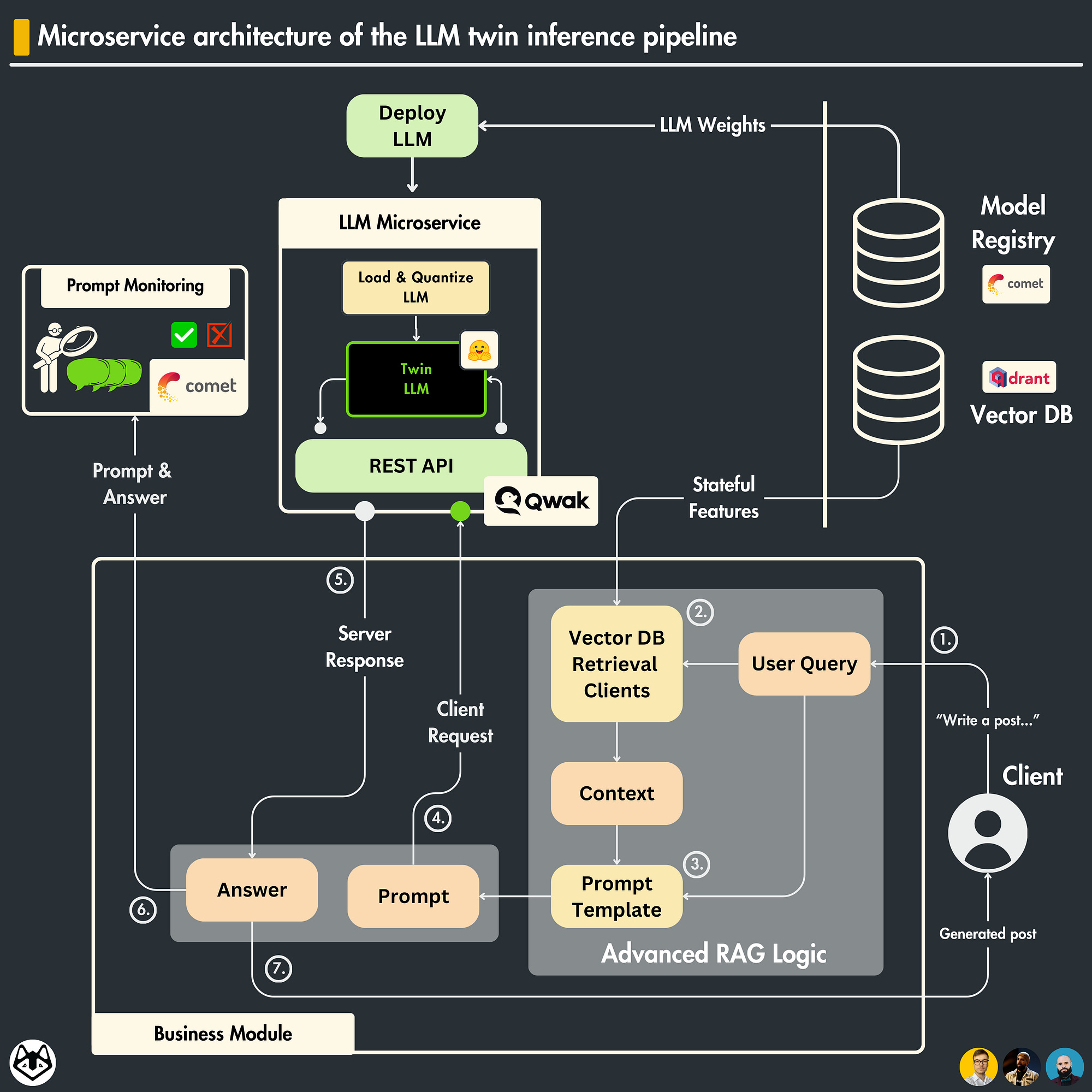
The LLM microservice is deployed on Qwak. This component is wholly niched on hosting and calling the LLM. It runs on powerful GPU-enabled machines.
How does the LLM microservice work?
It loads the fine-tuned LLM twin model from Comet’s model registry [2].
It exposes a REST API that takes in prompts and outputs the generated answer.
When the REST API endpoint is called, it tokenizes the prompt, passes it to the LLM, decodes the generated tokens to a string and returns the answer.
That’s it!
The prompt monitoring microservice is based on Comet ML’s LLM dashboard. Here, we log all the prompts and generated answers into a centralized dashboard that allows us to evaluate, debug, and analyze the accuracy of the LLM.
2. The training vs. the inference pipeline
Along with the obvious reason that the training pipeline takes care of training while the inference pipeline takes care of inference (Duh!), there are some critical differences you have to understand.
The input of the pipeline & How the data is accessed
Do you remember our logical feature store based on the Qdrant vector DB and Comet ML artifacts? If not, consider checking out Lesson 6 for a refresher.
The core idea is that during training, the data is accessed from an offline data storage in batch mode, optimized for throughput and data lineage.
Our LLM twin architecture uses Comet ML artifacts to access, version, and track all our data.
The data is accessed in batches and fed to the training loop.
During inference, you need an online database optimized for low latency. As we directly query the Qdrant vector DB for RAG, that fits like a glove.
During inference, you don’t care about data versioning and lineage. You just want to access your features quickly for a good user experience.
The data comes directly from the user and is sent to the inference logic.
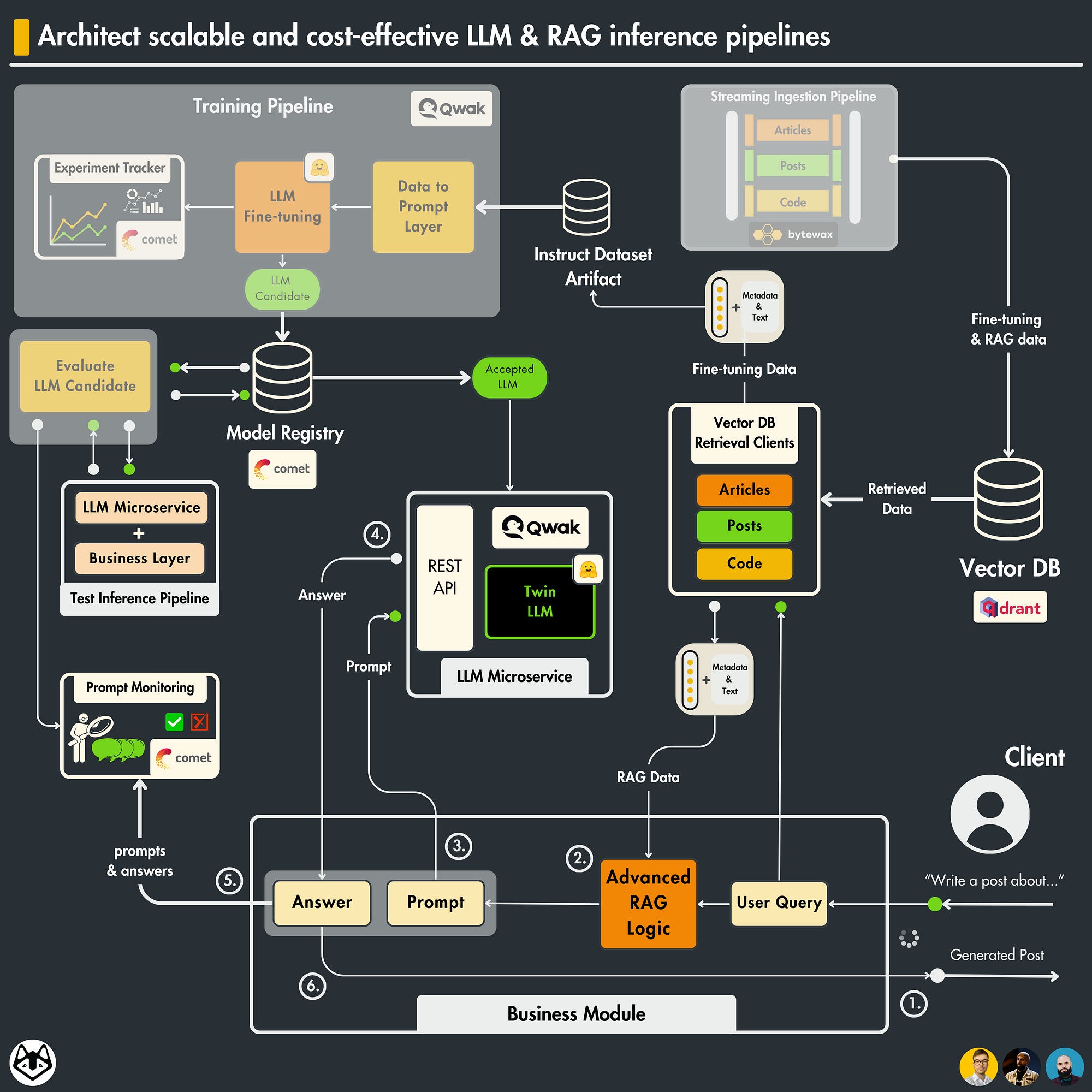
The output of the pipeline
The training pipeline’s final output is the trained weights stored in Comet’s model registry.
The inference pipeline’s final output is the predictions served directly to the user.
The infrastructure
The training pipeline requires more powerful machines with as many GPUs as possible.
Why? During training, you batch your data and have to hold in memory all the gradients required for the optimization steps. Because of the optimization algorithm, the training is more compute-hungry than the inference.
Thus, more computing and VRAM result in bigger batches, which means less training time and more experiments.
If you run a batch pipeline, you will still pass batches to the model but don’t perform any optimization steps.
If you run a real-time pipeline, as we do in the LLM twin architecture, you pass a single sample to the model or do some dynamic batching to optimize your inference step.
Are there any overlaps?
Yes! This is where the training-serving skew comes in.
To avoid the training-serving skew, you must carefully apply the same preprocessing and postprocessing steps during training and inference.
3. The RAG business module
We will define the RAG business module under the LLMTwin class. The LLM twin logic is directly correlated with our business logic.
We don’t have to introduce the word “business” in the naming convention of the classes.
Let’s dig into the generate() method of the LLMTwin class, where we:
call the RAG module;
create the prompt using the prompt template, query and context;
call the LLM microservice;
log the prompt, prompt template, and answer to Comet ML’s prompt monitoring service.

Let’s look at how our LLM microservice is implemented using Qwak.
4. The LLM microservice
As the LLM microservice is deployed on Qwak, we must first inherit from the QwakModel class and implement some specific functions.
initialize_model(): where we load the fine-tuned model from the model registry at serving time
schema(): where we define the input and output schema
predict(): where we implement the actual inference logic
Note: The build() function contains all the training logic, such as loading the dataset, training the LLM, and pushing it to a Comet experiment. To see the full implementation, consider checking out Lesson 7, where we detailed the training pipeline.
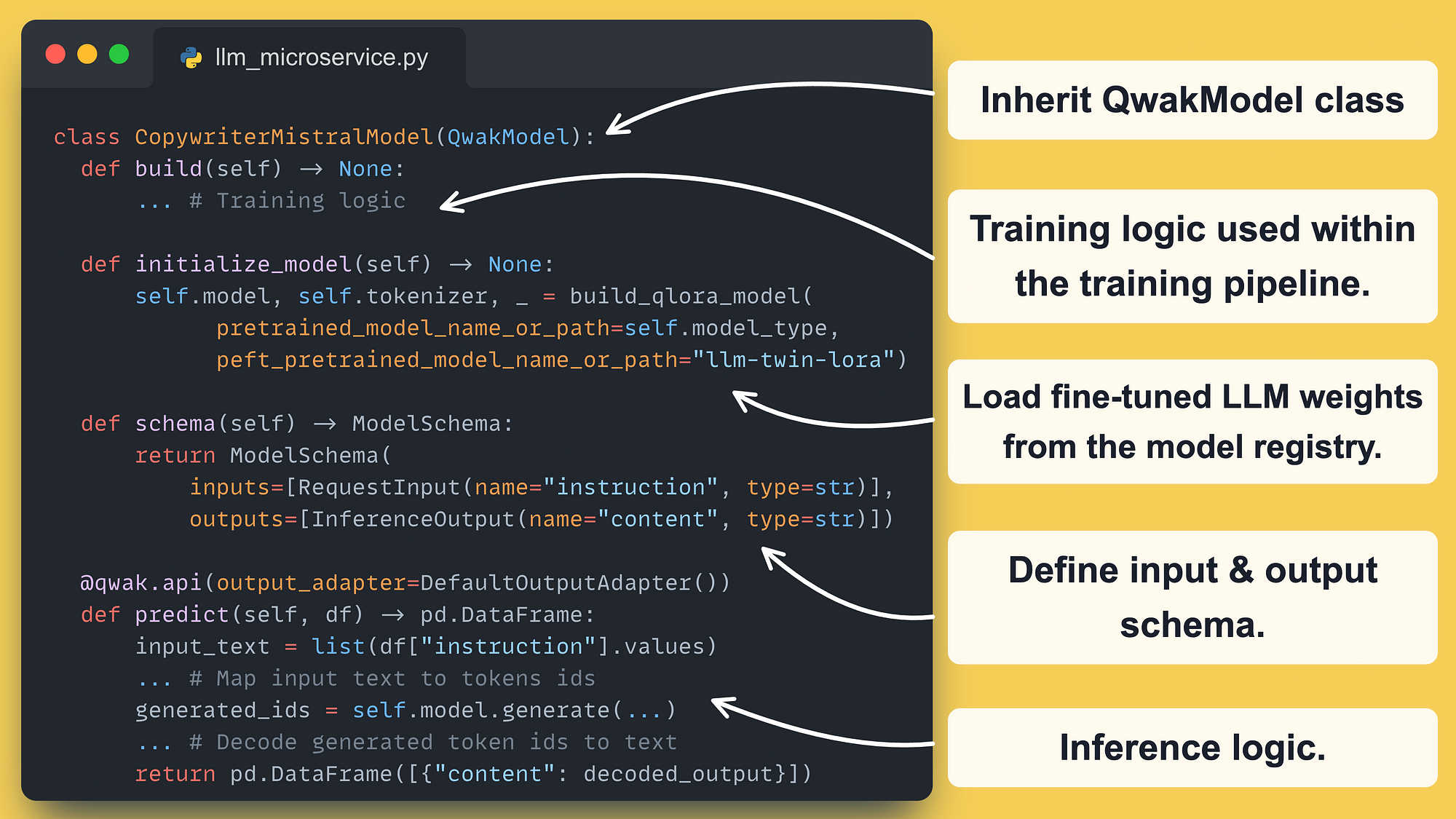
Let’s zoom into the implementation and the life cycle of the Qwak model.
The schema() method is used to define how the input and output of the predict() method look like. This will automatically validate the structure and type of the predict() method. For example, the LLM microservice will throw an error if the variable instruction is a JSON instead of a string.
The other Qwak-specific methods are called in the following order:
__init__() → when deploying the model
initialize_model() → when deploying the model
predict() → on every request to the LLM microservice
>>> Note that these methods are called only during serving time (and not during training).
Qwak exposes your model as a RESTful API, where the predict() method is called on each request.
Inside the prediction method, we perform the following steps:
map the input text to token IDs using the LLM-specific tokenizer
move the token IDs to the provided device (GPU or CPU)
pass the token IDs to the LLM and generate the answer
extract only the generated tokens from the generated_ids variable by slicing it using the shape of the input_ids
decode the generated_ids back to text
return the generated text
The final step is to look at Comet’s prompt monitoring service. ↓
5. Prompt monitoring
Comet makes prompt monitoring straightforward. There is just one API call where you connect to your project and workspace and send the following to a single function:
the prompt and LLM output
the prompt template and variables that created the final output
your custom metadata specific to your use case — here, you add information about the model, prompt token count, token generation costs, latency, etc.
class PromptMonitoringManager:
@classmethod
def log(
cls, prompt: str, output: str,
prompt_template: str | None = None,
prompt_template_variables: dict | None = None,
metadata: dict | None = None,
) -> None:
metadata = {
"model": settings.MODEL_TYPE,
**metadata,
} or {"model": settings.MODEL_TYPE}
comet_llm.log_prompt(
workspace=settings.COMET_WORKSPACE,
project=f"{settings.COMET_PROJECT}-monitoring",
api_key=settings.COMET_API_KEY,
prompt=prompt, prompt_template=prompt_template,
prompt_template_variables=prompt_template_variables,
output=output, metadata=metadata,
)This is how Comet ML’s prompt monitoring dashboard looks. Here, you can scroll through all the prompts that were ever sent to the LLM. ↓
You can click on any prompt and see everything we logged programmatically using the PromptMonitoringManager class.

Besides what we logged, adding various tags and the inference duration can be valuable.
6. Deploying and running the inference pipeline
We can deploy the LLM microservice using the following Qwak command:
qwak models deploy realtime \
--model-id "llm_twin" \
--instance "gpu.a10.2xl" \
--timeout 50000 \
--replicas 2 \
--server-workers 2We deployed two replicas of the LLM twin. Each replica has access to a machine with x1 A10 GPU. Also, each replica has two workers running on it.
🔗 More on Qwak instance types ←
Two replicas and two workers result in 4 microservices that run in parallel and can serve our users.
You can scale the deployment to more replicas if you need to serve more clients. Qwak provides autoscaling mechanisms triggered by listening to the consumption of GPU, CPU or RAM.
To conclude, you build the Qwak model once, and based on it, you can make multiple deployments with various strategies.
Conclusion
Congratulations! You are close to the end of the LLM twin series.
In Lesson 9 of the LLM twin course, you learned to build a scalable inference pipeline for serving LLMs and RAG systems.
First, you learned how to architect an inference pipeline by understanding the difference between monolithic and microservice architectures. We also highlighted the difference in designing the training and inference pipelines.
Secondly, we walked you through implementing the RAG business module and LLM twin microservice. Also, we showed you how to log all the prompts, answers, and metadata for Comet’s prompt monitoring service.
Ultimately, we showed you how to deploy and run the LLM twin inference pipeline on the Qwak AI platform.
In Lesson 10, we will show you how to evaluate the whole system by building an advanced RAG evaluation pipeline that analyzes the accuracy of the LLMs ’ answers relative to the query and context.
See you there! 🤗
🔗 Check out the code on GitHub [1] and support us with a ⭐️
Next Steps
Step 1
This is just the short version of Lesson 9 on architecting scalable and cost-effective LLM & RAG inference pipelines.
→ For…
The full implementation.
Full deep dive into the code.
More on the RAG, LLM and monitoring services.
Check out the full version of Lesson 9 on our Medium publication. It’s still FREE:
Step 2
→ Consider checking out the LLM Twin GitHub repository and try it yourself 🫵
Nothing compares with getting your hands dirty and doing it yourself!
Images
If not otherwise stated, all images are created by the author.