



The Role of Feature Stores in Fine-Tuning LLMs
From raw data to instruction dataset

→ the 6th out of 11 lessons of the LLM Twin free course
Why is this course different?
By finishing the “LLM Twin: Building Your Production-Ready AI Replica” free course, you will learn how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices.
Why should you care? 🫵
→ No more isolated scripts or Notebooks! Learn production ML by building and deploying an end-to-end production-grade LLM system.
More details on what you will learn within the LLM Twin course, here 👈
Latest Lessons of the LLM Twin Course
Lesson 3: CDC: Enabling Event-Driven Architectures
→ Change Data Capture (CDC), MongoDB Watcher, RabbitMQ queue
Lesson 4: Python Streaming Pipelines for Fine-tuning LLMs and RAG - in Real-Time!
→ Feature pipeline, Bytewax streaming engine, Pydantic models, The dispatcher layer
Lesson 5: The 4 Advanced RAG Algorithms You Must Know to Implement
→ RAG System, Qdrant, Query Expansion, Self Query, Filtered vector search
Lesson 6: The Role of Feature Stores in Fine-Tuning LLMs
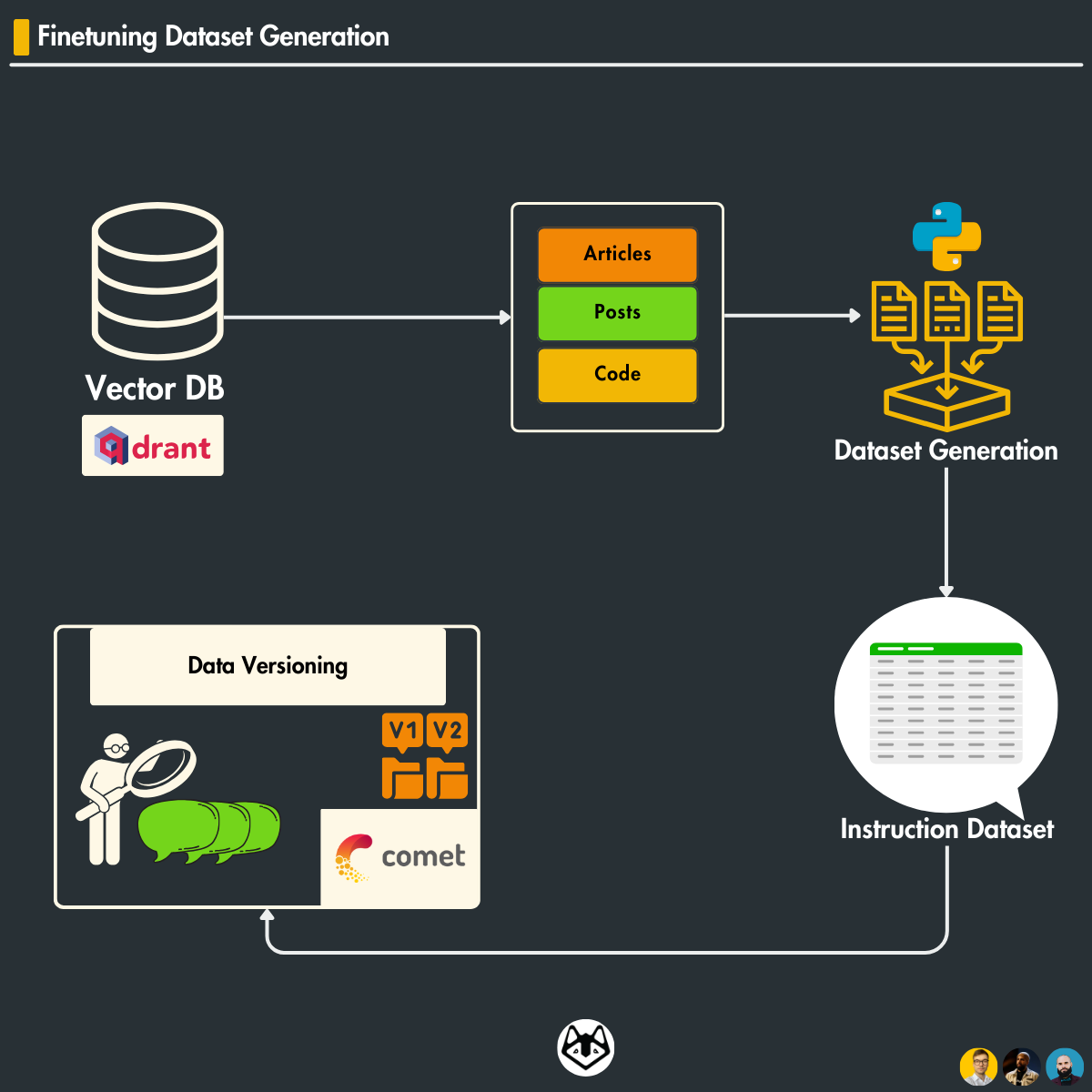
In Lesson 4, we showed you how to clean, chunk, embed, and load social media data to a Qdrant vector DB (the ingestion part of RAG).
In Lesson 6, we will focus on building a dataset ready for fine-tuning for a specific task: content writing.
We will focus on how to use the cleaned data from Qdrant and create an instruction dataset ready for finetuning.
We will show you how to implement MLOPs best practices for data versioning using Comet ML.
1. Understand the data
Fine-tuning is the process of taking a pre-trained LLM and adapting it to a specific task or domain.
One important aspect of fine-tuning is dataset preparation.
Remember the quote from 2018: “garbage in, garbage out.”
The quality of your dataset directly impacts how well your fine-tuned model will perform.
Why Data Matters?
Let’s explore why a well-prepared, high-quality dataset is essential for successful LLM fine-tuning:
Specificity is Key: LLMs like Mistral are trained on massive amounts of general text data. This gives them a broad understanding of language, but it doesn’t always align with the specific task you want the model to perform. A carefully curated dataset helps the model understand the nuances of your domain, vocabulary, and the types of outputs you expect.
Contextual Learning: High-quality datasets offer rich context that the LLM can use to learn patterns and relationships between words within your domain. This context enables the model to generate more relevant and accurate responses for your specific application.
Avoiding Bias: Unbalanced or poorly curated datasets can introduce biases into the LLM, impacting its performance and leading to unfair or undesirable results. A well-prepared dataset helps to mitigate these risks.
Understanding the Data Types
Our data consists of two primary types: posts and articles. Each type serves a different purpose and is structured to accommodate specific needs:
Posts: Typically shorter and more dynamic, posts are often user-generated content from social platforms or forums. They are characterized by varied formats and informal language and capture real-time user interactions and opinions.
Articles are more structured and content-rich, usually sourced from news outlets or blogs. Articles provide in-depth analysis or reporting and are formatted to include headings, subheadings, and multiple paragraphs, offering comprehensive information on specific topics.
Code: Sourced from repositories like GitHub, this data type encompasses scripts and programming snippets crucial for LLMs to learn and understand technical language
2. Feature Store
A feature store plays a critical role in machine learning workflows by:
Centralizing Data Management: It centralizes feature data, making it accessible and reusable across multiple machine learning models and projects.
Ensuring Consistency: Consistent feature calculation ensures that the same data preprocessing steps are applied in both training and prediction phases, reducing errors.
Improving Efficiency: By storing pre-computed features, it significantly speeds up the experimentation process, allowing for rapid testing of different models.
Scaling with Ease: As projects grow, a feature store can manage scaling of data operations efficiently, supporting larger datasets and more complex feature engineering tasks.
By leveraging a feature store like Qdrant, teams can enhance the reproducibility and scalability of their machine learning projects.
Qdrant can be utilized via its Docker implementation or through its managed cloud service. This flexibility allows you to choose an environment that best suits your project’s needs.
Environment Variables
To configure your environment for Qdrant, set the following variables:
Docker Variables
QDRANT_HOST: The hostname or IP address where your Qdrant server is running.QDRANT_PORT: The port on which Qdrant listens, typically6333for Docker setups.
Qdrant Cloud Variables
QDRANT_CLOUD_URL: The URL for accessing Qdrant Cloud services.QDRANT_APIKEY: The API key for authenticating with Qdrant Cloud.
Please check this article to learn how to obtain these variables:
We will use the client from from db/qdrant module:
from qdrant_client import QdrantClient
from qdrant_client.http.exceptions import UnexpectedResponse
from qdrant_client.http.models import Batch, Distance, VectorParams
import logger_utils
from settings import settings
logger = logger_utils.get_logger(__name__)
class QdrantDatabaseConnector:
_instance: QdrantClient = None
def __init__(self):
if self._instance is None:
try:
if settings.USE_QDRANT_CLOUD:
self._instance = QdrantClient(
url=settings.QDRANT_CLOUD_URL,
api_key=settings.QDRANT_APIKEY,
)
else:
self._instance = QdrantClient(
host=settings.QDRANT_DATABASE_HOST,
port=settings.QDRANT_DATABASE_PORT,
)
except UnexpectedResponse:
logger.exception(
"Couldn't connect to the database.",
host=settings.QDRANT_DATABASE_HOST,
port=settings.QDRANT_DATABASE_PORT,
)
raise
def get_collection(self, collection_name: str):
return self._instance.get_collection(collection_name=collection_name)
def create_non_vector_collection(self, collection_name: str):
self._instance.create_collection(collection_name=collection_name, vectors_config={})
def create_vector_collection(self, collection_name: str):
self._instance.create_collection(
collection_name=collection_name,
vectors_config=VectorParams(size=settings.EMBEDDING_SIZE, distance=Distance.COSINE),
)
def write_data(self, collection_name: str, points: Batch):
try:
self._instance.upsert(collection_name=collection_name, points=points)
except Exception:
logger.exception("An error occurred while inserting data.")
raise
def scroll(self, collection_name: str, limit: int):
return self._instance.scroll(collection_name=collection_name, limit=limit)
def close(self):
if self._instance:
self._instance.close()
logger.info("Connected to database has been closed.")
connection = QdrantDatabaseConnector()To easily fetch data from a Qdrant database, you can utilize the Python function fetch_all_cleaned_content. This function demonstrates how to efficiently retrieve a list of cleaned content from a specified collection:
from db.qdrant import connection as client
def fetch_all_cleaned_content(self, collection_name: str) -> list:
all_cleaned_contents = []
scroll_response = client.scroll(collection_name=collection_name, limit=10000)
points = scroll_response[0]
for point in points:
cleaned_content = point.payload["cleaned_content"]
if cleaned_content:
all_cleaned_contents.append(cleaned_content)
return all_cleaned_contentsInitialize the Scroll: Start by scrolling through the database using the
scrollmethod, which can fetch large amounts of data. Specify the collection name and set a limit to manage data volume effectively.Access Points: Retrieve points from the initial scroll response. Each point contains payloads where the actual data is stored.
Extract Data: Loop through the points to extract the
cleaned_contentfrom each payload. This content is checked for existence before being added to the results list.Return Results: The function returns a list containing all the cleaned content extracted from the database, making the process straightforward and manageable.
3. Finetuning Dataset
Overcoming the Data Bottleneck in Language Model Fine-tuning
Fine-tuning language models like Mistral-7B for specific tasks, such as content generation, often requires a substantial amount of carefully curated data. Manually creating these datasets is not only labor-intensive but also introduces the risk of human error.
Streamlining the Process with Instruction Datasets
Instruction datasets offer a more efficient and reliable alternative. These datasets provide structured guidance, steering the language model towards the desired task with greater precision.
Leveraging LLMs for Dataset Creation
While instruction datasets can be built manually or extracted from existing sources, harnessing the power of large language models (LLMs) like OpenAI's GPT-3.5-turbo presents a particularly attractive option, especially when faced with time and budget constraints. LLMs can automate the generation of high-quality instructions, significantly accelerating the dataset creation process.
Toy Example: Qdrant Data
To demonstrate the practicality of this approach, let's examine a sample data point from Qdrant, a vector database. By analyzing this data point, we can gain insights into how instructions can be derived and used to populate our instruction dataset.
Data Point:
{
"author_id": "2",
"cleaned_content": "Do you want to learn to build hands-on LLM systems using good LLMOps practices? A new Medium series is coming up for the Hands-on LLMs course\n.\nBy finishing the Hands-On LLMs free course, you will learn how to use the 3-pipeline architecture & LLMOps good practices to design, build, and deploy a real-time financial advisor powered by LLMs & vector DBs.\nWe will primarily focus on the engineering & MLOps aspects.\nThus, by the end of this series, you will know how to build & deploy a real ML system, not some isolated code in Notebooks.\nThere are 3 components you will learn to build during the course:\n- a real-time streaming pipeline\n- a fine-tuning pipeline\n- an inference pipeline\n.\nWe have already released the code and video lessons of the Hands-on LLM course.\nBut we are excited to announce an 8-lesson Medium series that will dive deep into the code and explain everything step-by-step.\nWe have already released the first lesson of the series \nThe LLMs kit: Build a production-ready real-time financial advisor system using streaming pipelines, RAG, and LLMOps: \n[URL]\n In Lesson 1, you will learn how to design a financial assistant using the 3-pipeline architecture (also known as the FTI architecture), powered by:\n- LLMs\n- vector DBs\n- a streaming engine\n- LLMOps\n.\n The rest of the articles will be released by the end of January 2024.\nFollow us on Medium's Decoding ML publication to get notified when we publish the other lessons: \n[URL]\nhashtag\n#\nmachinelearning\nhashtag\n#\nmlops\nhashtag\n#\ndatascience",
"platform": "linkedin",
"type": "posts"
}By analyzing content from sources like Qdrant, we can extract valuable insights and craft instructions for GPT-3.5-turbo. For example, we might instruct it to:
"Write a LinkedIn post promoting a new educational course on building LLM systems with a focus on LLMOps."
"Write a LinkedIn post explaining the benefits of using LLMs and vector databases in real-time financial advising."
Generating the Instruction Dataset
By feeding these instructions, along with the corresponding content, into GPT-3.5-turbo, we can generate a dataset of instruction-output pairs specifically tailored for fine-tuning Mistral-7B for content generation.
Practical Demonstration
Imagine that we want to go from this ↓
{
"author_id": "2",
"cleaned_content": "Do you want to learn to build hands-on LLM systems using good LLMOps practices? A new Medium series is coming up for the ...",
},
{
"author_id": "2",
"cleaned_content": "RAG systems are far from perfect This free course teaches you how to improve your RAG system.\nI recently finished ...",
}to this ↓
[
{
"instruction": "Share the announcement of the upcoming Medium series on building hands-on LLM systems using good LLMOps practices, focusing on the 3-pipeline architecture and real-time financial advisor development. Follow the Decoding ML publication on Medium for notifications on future lessons.",
"content": "Do you want to learn to build hands-on LLM systems using good LLMOps practices? ..."
},
{
"instruction": "Promote the free course 'Advanced Retrieval for AI with Chroma' from DeepLearning.AI that aims to improve RAG systems and takes only 1 hour to complete...",
"content": "RAG systems are far from perfect This free course teaches you how to improve your RAG system.\nI recently finished the Advanced Retrieval for AI with Chroma free course ..."
},In order to use an LLM to generate the instruction dataset you must go through next steps:
Step 1: Set Up Data Points
First, let’s define a sample set of data points. These represent different content pieces from which we want to generate LinkedIn post instructions.
{
"author_id": "2",
"cleaned_content": "Do you want to learn to build hands-on LLM systems...
"platform": "linkedin",
"type": "posts"
},
{
"author_id": "2",
"cleaned_content": "RAG systems are far from perfect ...,
"platform": "linkedin",
"type": "posts"
}Step 2: Formating the points
We’ll use the DataFormatter class to format these data points into a structured prompt for the LLM. Here’s how you would use the class to prepare the content:
data_type = "posts"
USER_PROMPT = (
f"I will give you batches of contents of {data_type}. Please generate me exactly 1 instruction for each of them. The {data_type} text "
f"for which you have to generate the instructions is under Content number x lines. Please structure the answer in json format,"
f"ready to be loaded by json.loads(), a list of objects only with fields called instruction and content. For the content field, copy the number of the content only!."
f"Please do not add any extra characters and make sure it is a list with objects in valid json format!\n"
)
class DataFormatter:
@classmethod
def format_data(cls, data_points: list, is_example: bool, start_index: int) -> str:
pass
@classmethod
def format_batch(cls, context_msg: str, data_points: list, start_index: int) -> str:
pass
@classmethod
def format_prompt(cls, inference_posts: list, start_index: int):
pass
Output of the format_prompt function:
I will give you batches of contents of posts. Please generate me exactly 1 instruction for each of them. The posts text for which you have to generate the instructions is under Content number x lines. Please structure the answer in json format,ready to be loaded by json.loads(), a list of objects only with fields called instruction and content. For the content field, copy the number of the content only!.Please do not add any extra characters and make sure it is a list with objects in valid json format!
You must generate exactly a list of 1 json objects, using the contents provided under CONTENTS FOR GENERATION
CONTENTS FOR GENERATION:
Content number 0
Do you want to learn to build hands-on LLM systems using good LLMOps practices? A new Medium series is coming up for the Hands-on LLMs course
.
By finishing the Hands-On LLMs free course, you will learn how to use the 3-pipeline architecture & LLMOps good practices to design, build, and deploy a real-time financial advisor powered by LLMs & vector DBs.
We will primarily focus on the engineering & MLOps aspects.
Thus, by the end of this series, you will know how to build & deploy a real ML system, not some isolated code in Notebooks.
There are 3 components you will learn to build during the course:
- a real-time streaming pipeline
- a fine-tuning pipeline
- an inference pipelineStep 3: Automate finetuning data generation using the DatasetGenerator Class
To automate the generation of finetuning data, we desgined the DatasetGenerator class. This class is designed to streamline the process from fetching data to logging the training data into Comet ML.
The DatasetGenerator class is initialized with three components: a file handler for managing file I/O, an API communicator for interacting with the LLM, and a data formatter for preparing data:
Generating Finetuning Data
The generate_training_data method from DatasetGenerator class handles the full lifecycle of data generation:
def generate_training_data(self, collection_name: str, batch_size: int = 1):
all_contents = self.fetch_all_cleaned_content(collection_name)
response = []
for i in range(0, len(all_contents), batch_size):
batch = all_contents[i : i + batch_size]
initial_prompt = self.data_formatter.format_prompt(batch, i)
response += self.api_communicator.send_prompt(initial_prompt)
for j in range(i, i + batch_size):
response[j]["content"] = all_contents[j]
self.push_to_comet(response, collection_name)4. Data Versioning
In this section, we focus on a critical aspect of Machine Learning Operations (MLOps) — data versioning.
We’ll specifically look at how to implement this using Comet ML, a platform that facilitates experiment management and reproducibility in machine learning projects.
CometML is a cloud-based platform that provides tools for tracking, comparing, explaining, and optimizing machine learning experiments and models. It helps data scientists and teams better manage and collaborate on machine learning experiments.
Why Use CometML?
Artifact Management: Captures, versions, and manages data snapshots and models, maintaining data integrity and experiment lineage.
Experiment Tracking: Automatically tracks code, experiments, and results, enabling visual comparison of different runs and configurations.
Model Optimization: Tools to compare models side by side, analyze hyperparameters, and track performance across metrics.
Collaboration and Sharing: Share findings and models with colleagues or the ML community to enhance collaboration and knowledge transfer.
Reproducibility: Logs every detail of experiment setups to ensure reproducibility, simplifying debugging and iteration.
Why Choose CometML Over MLFlow?
User Interface: CometML offers a clean, intuitive experience for tracking experiments and models.
Collaboration Tools: Robust features facilitate team collaboration on machine learning projects.
Security: Comprehensive security features protect data and models, crucial for enterprises.
Scalability: Supports larger datasets and complex model training scenarios.
Detailed Tracking: Provides more detailed tracking and analysis of experiments compared to MLflow.
The Importance of Data Versioning in MLOps
Data versioning records multiple versions of datasets used in training machine learning models, which is crucial for several reasons:
Reproducibility: Ensures experiments can be replicated with the exact same data, validating and comparing models effectively.
Model Diagnostics and Auditing: Enables teams to revert to previous data states to identify issues when model performance changes unexpectedly.
Collaboration and Experimentation: Allows teams to experiment with different data versions without losing original setups, enhancing collaborative efforts.
Regulatory Compliance: Helps meet industry regulations by tracking data modifications and training environments.
Comet ML’s Artifacts
Version Control: Tracks changes and iterates on datasets and models efficiently.
Immutability: Ensures data integrity by making artifacts immutable once created.
Metadata and Tagging: Enhances searchability and organization with metadata and tags.
Alias Management: Simplifies workflow by assigning aliases to artifact versions.
External Storage: Integrates with solutions like Amazon S3 for scalable and secure data management.
The provided push_to_comet function is a key part of this process.
def push_to_comet(self, data: list, collection_name: str):
try:
logging.info(f"Starting to push data to Comet: {collection_name}")
# Assuming the settings module has been properly configured with the required attributes
experiment = Experiment(
api_key=settings.COMET_API_KEY,
project_name=settings.COMET_PROJECT,
workspace=settings.COMET_WORKSPACE,
)
file_name = f"{collection_name}.json"
logging.info(f"Writing data to file: {file_name}")
with open(file_name, "w") as f:
json.dump(data, f)
logging.info("Data written to file successfully")
artifact = Artifact(collection_name)
artifact.add(file_name)
logging.info(f"Artifact created and file added: {file_name}")
experiment.log_artifact(artifact)
experiment.end()
logging.info("Data pushed to Comet successfully and experiment ended")
except Exception as e:
logging.error(f"Failed to push data to Comet: {e}", exc_info=True)Breakdown of Function Components
Experiment Initialization: An experiment is created using the project settings. This ties all actions, like logging artifacts, to a specific experimental run.
Data Saving: Data is saved locally as a JSON file. This file format is versatile and widely used, making it a good choice for data interchange.
Artifact Creation and Logging: An artifact is a versioned object in Comet ML that can be associated with an experiment. By logging artifacts, you keep a record of all data versions used throughout the project lifecycle.
After running the script that invokes the push_to_comet function, Comet ML will update with new data artifacts, each representing a different dataset version. This is a crucial step in ensuring that all your data versions are logged and traceable within your MLOps environment.
What to Expect in Comet ML
Here is what you should see in Comet ML after successfully executing the script:
cleaned_articles: This artifact has 10 versions, indicating it has been updated or modified 10 times.
cleaned_posts: This artifact shows 3 versions, showing fewer updates compared to the articles.
Each version is timestamped and stored with a unique ID, allowing you to track changes over time or revert to previous versions if necessary.

A final version of your dataset, such as cleaned_articles.json, will be ready for fine-tuning.
This JSON file will include pairs of instructions and content:
Instructions: Generated by the LLM, guiding the model to perform specific tasks or understand particular contexts.
Content: Data crawled and processed through your pipeline.
This format ensures each dataset version is tracked and structured to enhance model performance through targeted fine-tuning.
…and you generated your fine-tuning dataset. Congratulations!
Conclusion
Congratulations!
Lesson 6 Recap:
Understanding Fine-Tuning Importance
Using an LLM to Generate Instructions: Learning to use a large language model (LLM) to create instructions for crawled data.
Retrieve Data from Qdrant:
Ensuring Dataset Quality: Recognizing the critical role of dataset quality in machine learning.
Data Versioning with CometML: Implementing data versioning using CometML to ensure reproducibility, aid in model diagnostics, and support regulatory compliance, which is essential for a robust and traceable MLOps workflow.
Next Week, in Lesson 7, you will learn how to use the generated dataset to finetune a Mistral-7b for content generation building and deploying the training pipeline to Qwak an AI serverless platform.
Next Steps
Step 1
This is just the short version of Lesson 6 on The Role of Feature Stores in Fine-Tuning LLMs
→ For…
The full implementation.
Discussion on detailed code
More on retrieval cleaned dataset from Qdrant
More on dataset versioning using Comet ML
Check out the full version of Lesson 6 on our Medium publication. It’s still FREE:
Step 2
→ Check out the LLM Twin GitHub repository and try it yourself 🫵
Nothing compares with getting your hands dirty and building it yourself!
Images
If not otherwise stated, all images are created by the author.
Muy buen material que permite escalar en conocimientos de LLM.
Muchas gracias