

Deploy scalable TikTok-like recommenders
Ship to the real world an H&M recommender using KServe

The fourth lesson of the “Hands-on H&M Real-Time Personalized Recommender” open-source course — a free course that will teach you how to build and deploy a real-time personalized recommender for H&M fashion articles using the 4-stage recommender architecture, the two-tower model design and the Hopsworks AI Lakehouse.
Lessons:
Lesson 1: Building a TikTok-like recommender
Lesson 2: Feature pipelines for TikTok-like recommenders
Lesson 3: Training pipelines for TikTok-like recommenders
Lesson 4: Deploy scalable TikTok-like recommenders
Lesson 5: Using LLMs to build TikTok-like recommenders
🔗 Learn more about the course and its outline.

Lesson 4: Deploy scalable TikTok-like recommenders
This lesson will wrap up our H&M personalized recommender project by implementing and deploying the inference pipelines of our ML system, as illustrated in Figure 1.
Serving ML models is one of the most complex steps when it comes to AI/ML in production, as you have to put all the pieces together into a unified system while considering:
throughput/latency requirements
infrastructure costs
data and model access
training-serving skew
As we started this project with production in mind by using the Hopsworks AI Lakehouse, we can easily bypass most of these issues, such as:
the query and ranking models are accessed from the model registry;
the customer and H&M article features are accessed from the feature store using the offline and online stores depending on throughput/latency requirements;
the features are accessed from a single source of truth (feature store), solving the training-serving skew.
Estimating infrastructure costs in a PoC is more complicated. Still, we will leverage a Kubernetes cluster managed by Hopsworks, which uses KServe to scale up and down our real-time personalized recommender depending on traffic.
Thus, in this lesson, you will learn how to:
Architect offline and online inference pipelines using MLOps best practices.
Implement offline and online pipelines for an H&M real-time personalized recommender.
Deploy the online inference pipeline using the KServe engine.
Test the H&M personalized recommender from a Streamlit app.
Deploy the offline ML pipelines using GitHub Actions.
Table of Contents:
Understanding the architecture of the inference pipelines
Building the offline candidate embedding inference pipeline
Implementing the online query service
Implementing the online ranking service
Deploying the online inference pipelines using KServe
Testing the H&M real-time personalized recommender
Deploying the offline ML pipelines using GitHub Actions
1 - Understanding the architecture of the inference pipelines
Before going into the implementation details, we want to explain the serving strategy of our inference pipelines. We have one offline and one online inference pipeline.
Here is a quick refresher on inference pipelines [2].
Let’s understand the difference between the two in our personalized recommender.
Online vs. offline inference pipelines in recommenders
The inference pipeline is split into 2 main processes to optimize for real-time recommendations.
The offline pipeline runs in batch mode, optimized for high throughput. It embeds all the candidate items from our database using the candidate articles encoder (trained using the two-tower network).
The offline pipeline runs once to backfill our H&M articles collection. It should then run again whenever a new article is added to our collection or the two-tower network is retrained (which changes our embedding space).

The online inference pipeline is deployed as a real-time service optimized for low latency. It will run on each client request, serving e-commerce personalized recommendations to each client.

Now, let’s zoom in on each pipeline.
Offline inference pipeline
The offline pipeline loads the article candidate encoder from the Hopsworks model registry and a reference to the retrieval feature view from the Hopsworks feature store.
Leveraging the feature view, it feeds in all the necessary features to the encoder, avoiding any potential training-serving skew.

Ultimately, it saves the candidate embeddings into a new feature group that supports a vector index for semantic search between the H&M fashion items and the user query. We flag the feature group as online to be optimized for low latency requirements.
We create a feature view from the feature group to expose the embedding vector index to the online inference pipeline.
Important! Behind-the-scenes insights
Labeling components in ML systems is hard!
For example, we labeled the candidate embeddings pipeline an “inference pipeline” because we examined its inputs: a trained model from the model registry and input features from the feature store.
However, based on Jim Downling’s feedback (CEO of Hopsworks), a way to consistently label your pipelines is based on the ML artifact/asset they produce.
Thus, if we look at its outputs, embeddings written to a feature group are used as features in downstream pipelines… We should have labeled it as a “feature pipeline.”
Engineers constantly struggle with labeling components in software systems.
However, consistency across the system is essential. That’s why Jim’s approach of labeling each pipeline according to the ML asset it produces is intuitive and a strong strategy to consider!
Online inference pipeline
The online inference pipeline implements the 4-stage architecture, which we kept talking about throughout this course.
The problem with real-time recommenders is that you must narrow from millions to dozens of item candidates in less than a second while the items are personalized to the user.
The 4-stage recommender architecture solves that!

Here is a quick reminder of the 4 stages we have to implement:
Stage 1: Take the
customer_idand other input features, such as the current date, compute the customer embedding using the Customer Query Model and query the Hopsworks vector DB for similar candidate items — Reduce a corpus of millions of items to ~hundreds.Stage 2: Takes the candidate items and applies various filters, such as removing items already seen or purchased using a Bloom filter.
Stage 3: During ranking, we load more features from Hopsworks' feature store describing the item and the user's relationship: "(item candidate, customer)." This is feasible as only a few hundred items are being scored, compared to the millions scored in candidate generation. The ranking model can use a boosting tree, such as XGBoost or CatBoost, a neural network or even an LLM.
Stage 4: We order the items based on the ranking score plus other optional business logic. The highest-scoring items are presented to the user and ranked by their score — Redice the ~hundreds of candidates of items to ~dozens.
All these recommendations are computed in near real-time (in milliseconds).
More on the 4 stage architecture in the first lesson:

Serving real-time recommendations using Hopsworks Serverless and KServe
We will deploy the online inference pipeline to Hopsworks Serverless, which uses KServe under the hood to serve the models.
What is KServe? It’s a runtime engine designed to serve predictive and generative ML models on Kubernetes clusters. It streamlines the complexities of autoscaling, networking, health checks, and server configuration, offering advanced serving features such as GPU autoscaling, scaling to zero, and canary rollouts for your ML deployments. 🔗 More on KServe [3]

Leveraging KServe, we will deploy two different services:
The query encoder service
The ranking service
Why?
We deploy them as two services because each has its model and environment. Thus, following KServe’s best practices, we will wrap each model into its own Predictor, which can be scaled and optimized independently.
The Transformer component is used to preprocess and postprocess the results from the Predictor (aka the model).
…and no! It has nothing to do with LLM — Transformer architectures. Not anything revolves around LLMs!
The KServe flow will be as follows:
The client calls the query service and sends its ID and transaction date.
The query service preprocesses the request within the Transformer (such as calling the feature store to get the client’s features based on its ID).
The query service calls the customer encoder Predictor.
The query service calls the ranking service, passing the query embedding.
The ranking service preprocesses the request within its Transformer, calls the ranking model and post-processes the recommendations.
The ranking service sends the results to the query service, which then sends the results back to the client.
Let’s dig into the code to see how this works in practice while using Hopsworks AI Lakehouse to power the ML system.
2 - Building the offline candidate embedding inference pipeline
The first step is to run our offline candidate embedding inference pipeline (in batch mode) to populate our Hopsworks vector index with all our H&M article embeddings.
Here is the implementation:
We connect to Hopsworks, our feature store and model registry platform. From there, we download our previously trained candidate model (within the two-tower network), which we'll use to generate item embeddings:
from recsys import features, hopsworks_integration
from recsys.config import settings
project, fs = hopsworks_integration.get_feature_store()
mr = project.get_model_registry()
candidate_model, candidate_features = (
hopsworks_integration.two_tower_serving.HopsworksCandidateModel.download(mr=mr)
)Next, we fetch our data using the retrieval feature view. The benefit of using a feature view is that the data already contains all the necessary features for our item embeddings. Thus, following the FTI architecture, no feature engineering is required at this point:
feature_view = fs.get_feature_view(
name="retrieval",
version=1,
)
train_df, val_df, test_df, _, _, _ = feature_view.train_validation_test_split(
validation_size=settings.TWO_TOWER_DATASET_VALIDATON_SPLIT_SIZE,
test_size=settings.TWO_TOWER_DATASET_TEST_SPLIT_SIZE,
description="Retrieval dataset splits",
)
The core step of the offline inference pipeline is to take the item features and the candidate model and compute all the embeddings in batch mode:
item_df = features.embeddings.preprocess(train_df, candidate_features)
embeddings_df = features.embeddings.embed(df=item_df, candidate_model=candidate_model)The preprocess() isn’t performing any feature engineering but just dropping any potential article duplicates:
item_df.drop_duplicates(subset="article_id", inplace=True)Within the
embed()function, we call the embedding model in batch mode while transforming the results into a Pandas DataFrame containing the article IDs and embeddings. The ID is critical in identifying the article after retrieving the candidates using semantic search:
def embed(df: pd.DataFrame, candidate_model) -> pd.DataFrame:
ds = tf.data.Dataset.from_tensor_slices({col: df[col] for col in df})
candidate_embeddings = ds.batch(2048).map(
lambda x: (x["article_id"], candidate_model(x))
)
all_article_ids = tf.concat([batch[0] for batch in candidate_embeddings], axis=0)
all_embeddings = tf.concat([batch[1] for batch in candidate_embeddings], axis=0)
all_article_ids = all_article_ids.numpy().astype(int).tolist()
all_embeddings = all_embeddings.numpy().tolist()
embeddings_df = pd.DataFrame(
{
"article_id": all_article_ids,
"embeddings": all_embeddings,
}
)
return embeddings_dfWe store these embeddings in Hopsworks by creating a dedicated feature group with an embedding index. By enabling online access, we ensure these embeddings will be readily available for our real-time recommendation service:
candidate_embeddings_fg = create_candidate_embeddings_feature_group(
fs=fs, df=embeddings_df, online_enabled=True
)
Ultimately, we create a feature view based on the embeddings feature group to expose the vector index to the online inference pipeline:
feature_view = create_candidate_embeddings_feature_view(
fs=fs, fg=candidate_embeddings_fg
)
Full Notebook and code are available on our GitHub.
3 - Implementing the online query service
Now that the vector index is populated with H&M fashion article candidate embeddings, we will focus on building our recommender online inference pipeline, which implements the 4-stage architecture.
We must implement a class following the Transformer interface, as we use KServe to deploy our query and ranking models.
The flow of the Transformer class is as follows:
Calls the
preprocess()method to prepare the data before feeding it to the model.Calls the deployed model (in our case, the Query encoder model)
Calls the
postprocess()method to process the data before returning it to the client.
Now, let’s dig into the implementation:
First, we define the Transformer class and get references to the ranking feature view (used to train the two-tower network) and the ranking KServe deployment. We need a reference to the ranking service as we have to pass it the query embedding to complete the steps from the 4-stage architecture:
from datetime import datetime
import hopsworks
import numpy as np
import pandas as pd
class Transformer(object):
def __init__(self) -> None:
project = hopsworks.login()
ms = project.get_model_serving()
fs = project.get_feature_store()
self.customer_fv = fs.get_feature_view(
name="customers",
version=1,
)
self.ranking_fv = fs.get_feature_view(name="ranking", version=1)
self.ranking_fv.init_batch_scoring(1)
# Retrieve the ranking deployment
self.ranking_server = ms.get_deployment("ranking")The preprocessing logic transforms raw API inputs into model-ready features. Note how we leveraged the Hopsworks feature view to ensure the features are consistent and computed the right way during inference to avoid the training-serving skew (for both static and on-demand features):
def preprocess(self, inputs):
customer_id = inputs["customer_id"]
transaction_date = inputs["transaction_date"]
month_of_purchase = datetime.fromisoformat(inputs.pop("transaction_date"))
# Real-time feature serving from the feature store
customer_features = self.customer_fv.get_feature_vector(
{"customer_id": customer_id},
return_type="pandas",
)
inputs["age"] = customer_features.age.values[0]
# Use the feature view for on-demand feature computation to avoid train-serving skew.
feature_vector = self.ranking_fv._batch_scoring_server.compute_on_demand_features(
feature_vectors=pd.DataFrame([inputs]),
request_parameters={"month": month_of_purchase}
).to_dict(orient="records")[0]
inputs["month_sin"] = feature_vector["month_sin"]
inputs["month_cos"] = feature_vector["month_cos"]
return {"instances": [inputs]}The postprocessing step is straightforward - it takes the model's raw predictions and uses our ranking server to generate the final ordered recommendations:
def postprocess(self, outputs):
return self.ranking_server.predict(inputs=outputs)Note that the KServe runtime within the Predictor component implicitly calls the Query encoder model. Still, we must explicitly upload the model when deploying our service, which we will show you later in this article.
We have only implemented Step 1 of the 4-stage architecture so far. The rest will be in the ranking service.
The complete
Transformerclass is available on our GitHub.
4 - Implementing the online ranking service
The last piece of our online inference pipeline is the ranking service, which communicates directly with the query service, as we saw in its postprocess() method.
As with the Query encoder, we have to implement the Transformer interface:
We initialize all the required features to perform the rest of the steps from the 4-stage architecture. One powerful feature of Hopsworks is that it allows us to automatically grab the feature view (along with its version) on which the ranking model was trained, eliminating another training-serving skew scenario:
class Transformer(object):
def __init__(self):
# Connect to Hopsworks
project = hopsworks.login()
self.fs = project.get_feature_store()
# Get feature views and groups
self.transactions_fg = self.fs.get_feature_group("transactions", 1)
self.articles_fv = self.fs.get_feature_view("articles", 1)
self.customer_fv = self.fs.get_feature_view("customers", 1)
self.candidate_index = self.fs.get_feature_view("candidate_embeddings", 1)
# Initialize serving
self.customer_fv.init_serving(1)
# Get ranking model and features
mr = project.get_model_registry()
model = mr.get_model(name="ranking_model", version=1)
self.ranking_fv = model.get_feature_view(init=False)
self.ranking_fv.init_batch_scoring(1)The preprocessing stage is where the real magic happens. When a request comes in, we first retrieve candidate items using vector similarity search based on the customer's query embedding, computed by the Query KServe service. We then filter out items the customer has already purchased by checking the transactions feature group, which is part of Stage 2:
def preprocess(self, inputs):
customer_id = inputs["instances"][0]["customer_id"]
# Get and filter candidates
neighbors = self.candidate_index.find_neighbors(
inputs["query_emb"],
k=100,
)
neighbors = [neighbor[0] for neighbor in neighbors]
already_bought_items_ids = (
self.transactions_fg.select("article_id")
.filter(self.transactions_fg.customer_id==customer_id)
.read(dataframe_type="pandas").values.reshape(-1).tolist()
)
item_id_list = [
str(item_id)
for item_id in neighbors
if str(item_id) not in already_bought_items_ids
]Next, we move on to Stage 3, where we enrich our candidates with features from the articles and customer feature views. We combine article features, customer demographics, and temporal features (month sine/cosine) to create a richer feature spectrum leveraged by the ranking model to understand better how relevant an H&M item is to the user:
# Get article and customer features
articles_data = [
self.articles_fv.get_feature_vector({"article_id": item_id})
for item_id in item_id_list
]
articles_df = pd.DataFrame(data=articles_data, columns=self.articles_features)
customer_features = self.customer_fv.get_feature_vector(
{"customer_id": customer_id},
return_type="pandas",
)
# Combine all features
ranking_model_inputs = item_id_df.merge(articles_df, on="article_id", how="inner")
ranking_model_inputs["age"] = customer_features.age.values[0]
ranking_model_inputs["month_sin"] = inputs["month_sin"]
ranking_model_inputs["month_cos"] = inputs["month_cos"]Finally, after the ranking model scores the candidates, we move to Stage 4 and sort the articles, representing our final ordered recommendations. This is our final step, providing a ranked list of personalized product recommendations to the user:
def postprocess(self, outputs):
ranking = list(zip(outputs["scores"], outputs["article_ids"]))
ranking.sort(reverse=True)
return {"ranking": ranking}The complete
Transformerclass is available on our GitHub.
As before, the ranking model is implicitly called between the preprocess() and postprocess() methods. But there is a catch…
As we use CatBoost as our ranking module, KServe doesn’t know how to load it out-of-the-box, as it happened for the Tenforflow/Keras Query encoder.
Thus, similar to the Transformer interface, we must implement the Predictor interface explicitly defining how the model is loaded and called. This interface is much more straightforward as we must implement a single predict() method. Let’s take a look:
Define the class and the
__init__method, where we load the CatBoost model:
class Predict(object):
def __init__(self):
self.model = joblib.load(os.environ["MODEL_FILES_PATH"] + "/ranking_model.pkl")The core prediction logic happens in the
predict()method, which is called by KServe's inference service. First, we extract the ranking features and article IDs from the input payload. Our transformer component previously prepared these features:
def predict(self, inputs):
features = inputs[0].pop("ranking_features")
article_ids = inputs[0].pop("article_ids")The final step is where the actual ranking happens. We use our loaded model to predict probabilities for each candidate article, focusing on the positive class scores. The scores are paired with their corresponding article IDs in the response:
scores = self.model.predict_proba(features).tolist()
scores = np.asarray(scores)[:,1].tolist()
return {
"scores": scores,
"article_ids": article_ids,
}The predictor integrates with KServe's inference pipeline alongside the transformer component that handles feature preprocessing. This setup allows us to serve real-time recommendations through a scalable Kubernetes infrastructure.
The complete
Predictclass is available on our GitHub.
5 - Deploying the online inference pipelines using KServe
Now that we have our fine-tuned models and Transformer & Predict classes in place, the last step is to ship them to a Kubernetes cluster managed by Hopsworks Serverless using KServe.
Hopsworks makes this easy. Let’s see how it works:
Let's start with our environment setup and Hopsworks connection:
import warnings
warnings.filterwarnings("ignore")
from loguru import logger
from recsys import hopsworks_integration
project, fs = hopsworks_integration.get_feature_store()We first deploy our ranking model to Hopsworks Serveless, leveraging our custom
HopsworksRankingModelPython class.
ranking_deployment = ranking_serving.HopsworksRankingModel.deploy(project)
ranking_deployment.start()Behind the scenes, the deployment method uploads the necessary transformer and predictor scripts to Hopsworks, selects the best-ranking model from the model registry based on the F-score metric, and configures a KServe transformer for preprocessing.
Initially, we configure the deployment with zero instances, autoscaling based on demand. We want to let the demo run 24/7. Thus, we can save tons on costs by setting the instances to 0 when there is no traffic. Hopsworks serverless takes care of autoscaling out-of-the-box:
from hsml.transformer import Transformer
from recsys.config import settings
class HopsworksRankingModel:
deployment_name = "ranking"
... # Other methods
@classmethod
def deploy(cls, project):
mr = project.get_model_registry()
dataset_api = project.get_dataset_api()
ranking_model = mr.get_best_model(
name="ranking_model",
metric="fscore",
direction="max",
)
# Copy transformer file into Hopsworks File System
uploaded_file_path = dataset_api.upload(
str(settings.RECSYS_DIR / "inference" / "ranking_transformer.py"),
"Resources",
overwrite=True,
)
transformer_script_path = os.path.join(
"/Projects", # Root directory for projects in Hopsworks
project.name,
uploaded_file_path,
)
# Upload predictor file to Hopsworks
uploaded_file_path = dataset_api.upload(
str(settings.RECSYS_DIR / "inference" / "ranking_predictor.py"),
"Resources",
overwrite=True,
)
predictor_script_path = os.path.join(
"/Projects",
project.name,
uploaded_file_path,
)
ranking_transformer = Transformer(
script_file=transformer_script_path,
resources={"num_instances": 0},
)
# Deploy ranking model
ranking_deployment = ranking_model.deploy(
name=cls.deployment_name,
description="Deployment that search for item candidates and scores them based on customer metadata",
script_file=predictor_script_path,
resources={"num_instances": 0},
transformer=ranking_transformer,
)
return ranking_deploymentThe complete class code is available on GitHub.
For testing the ranking deployment, we use a sample input that matches our transformer's expected format:
def get_top_recommendations(ranked_candidates, k=3):
return [candidate[-1] for candidate in ranked_candidates["ranking"][:k]]
test_ranking_input = [
{
"customer_id": "d327d0ad9e30085a436933dfbb7f77cf42e38447993a078ed35d93e3fd350ecf",
"month_sin": 1.2246467991473532e-16,
"query_emb": [0.214135289, 0.571055949, /* ... */],
"month_cos": -1.0,
}
]
ranked_candidates = ranking_deployment.predict(inputs=test_ranking_input)
recommendations = get_top_recommendations(ranked_candidates["predictions"], k=3)For the Query encoder model, we follow a similar strategy:
query_model_deployment = two_tower_serving.HopsworksQueryModel.deploy(project)
query_model_deployment.start()Under the hood, the deploy() method is similar to the one from the HopsworksRankingModel class:
from recsys.config import settings
from recsys.training.two_tower import ItemTower, QueryTower
class HopsworksQueryModel:
deployment_name = "query"
... # Other methods
@classmethod
def deploy(cls, project):
... # Similar code to the ranking model
query_model_deployment = query_model.deploy(
name=cls.deployment_name,
description="Deployment that generates query embeddings.",
resources={"num_instances": 0},
transformer=query_model_transformer,
)
return query_model_deploymentThe complete class code is available on GitHub.
Testing the query model requires only the
customer_idandtransaction_date, as the transformer handles taking all the required features from Hopsworks feature views, avoiding any state transfer between the client and ML service:
data = [
{
"customer_id": "d327d0ad9e30085a436933dfbb7f77cf42e38447993a078ed35d93e3fd350ecf",
"transaction_date": "2022-11-15T12:16:25.330916",
}
]
ranked_candidates = query_model_deployment.predict(inputs=data)
recommendations = get_top_recommendations(ranked_candidates["predictions"], k=3)Finally, we clean up our resources:
ranking_deployment.stop()
query_model_deployment.stop()After running the deployment steps, you should see them in Hopsworks Serverless, as Figure 10 illustrates under the Data Science → Deployments section.

The deployment logic is not dependent on Hopsworks.
Even if we used a managed version of Kubernetes + KServe on Hopsworks Serverless to deploy our inference pipelines, you could leverage the same code (Transformer and Predictor classes) and trained models on any other KServe infrastructure.
Full Notebook and code are available on our GitHub.
6 - Testing the H&M real-time personalized recommender
We are finally here: Where we can test our H&M real-time personalized recommender!
For testing the online inference pipeline, we wrote a simple Streamlit app that allows you to visualize the real-time recommendations for different users and generate new interactions to adapt future recommendations.
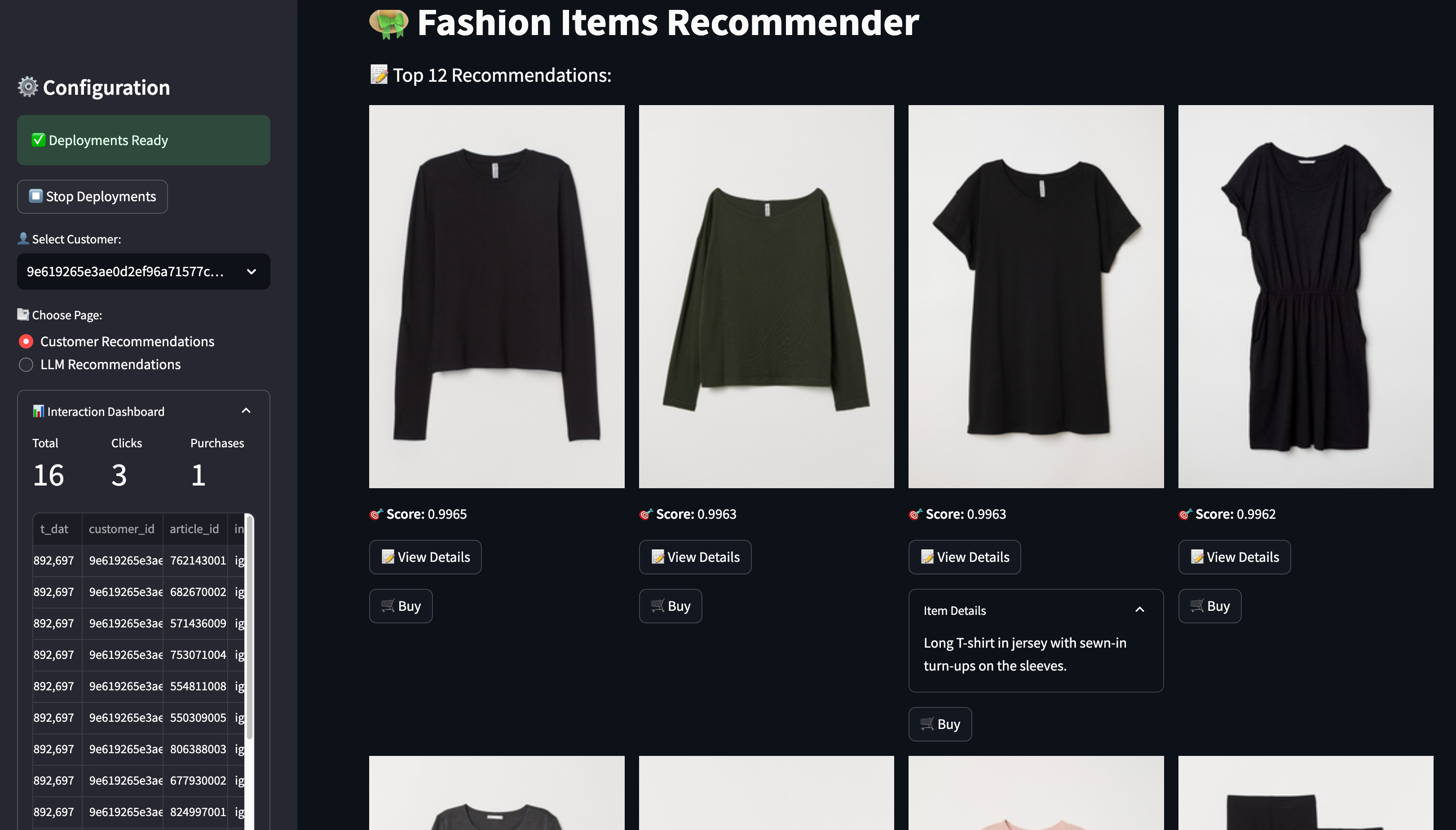
We won’t get into the Streamlit code, but under the hood, calling the real-time deployment through Hopsworks is as easy as:
project, fs = hopsworks_integration.get_feature_store()
ms = project.get_model_serving()
query_model_deployment = ms.get_deployment(
HopsworksQueryModel.deployment_name
)
query_model_deployment.start(await_running=180)
deployment_input = [
{
"customer_id": customer_id,
"transaction_date": formatted_timestamp}
]
prediction = query_model_deployment.predict(inputs=deployment_input)[
"predictions"
]["ranking"]Beautiful, right?
Everything else is Streamlit code!
Which you can find in our GitHub repository.
Running the code
Assuming you finalized the feature engineering and training steps explained in previous lessons, you can generate the embeddings by running:
make create-embeddingsView results in Hopsworks Serverless → Feature Store → Feature Groups
Then, you can create the deployments by running:
make create-deploymentsView results in Hopsworks Serverless → Data Science → Deployments
Ultimately, you can start the Streamlit app as follows — Accessible at `http://localhost:8501/`:
make start-ui🌐 We also deployed a live demo to play around with the H&M personalized recommender effortlessly: Live demo ←
The first time you interact with the demo, it will take a while to warm up the deployment from 0 to +1 instances. After that, the deployments will happen in real-time. This happens because we are in demo, 0-cost mode, scaling to 0 instances when there is no traffic.
Step-by-step-instructions
For the complete guide, access the GitHub documentation.
Step-by-step instructions for running the code:
In a local Notebook or Google Colab: access instructions
As a Python script from the CLI, access instructions
GitHub Actions: access instructions
Deploy the Streamlit app: access instructions
We recommend using GitHub Actions if you have a poor internet connection and keep getting timeout errors when loading data to Hopsworks. This happens because we push millions of items to Hopsworks.
7 - Deploying the offline ML pipelines using GitHub Actions
GitHub Actions is a great way to deploy offline ML pipelines that don’t require much computing power.
Why? When working with public repositories, they are free and can easily be integrated with your code.
As shown in Figure 12, we can easily chain multiple Python programs within a DAG. For example, after the features are successfully computed, we can leverage more complex relationships by running both training pipelines in parallel.

As we work with a static H&M dataset, we should run our offline ML pipelines only once to backfill our feature store, as our features, models and candidate embeddings don’t change. Still, in a real-world scenario, our data won’t be static, and we could easily leverage GitHub Actions to do continuous training once the code changes or new data is available.
Another massive benefit of using GitHub Actions is that it provides enterprise-level network access, saving you tons of headaches when working with medium to large datasets that can easily throw network errors on more unstable home Wi-Fis.
This can also happen in our H&M use case, where we work with millions of samples when loading the features to Hopsworks.
Now, let’s quickly dive into the GitHub Actions implementation:
We can run the pipeline automatically on a schedule (every 2 hours), on code changes, or manually through GitHub's UI. The pipeline takes approximately 1.5 hours to complete, which influenced these timing choices:
name: ML Pipelines
on:
# schedule: # Run pipelines every 2 hours
# - cron: '0 */2 * * *'
# push: # Run on every new commit to main
# branches:
# - main
workflow_dispatch: # Manual triggering
concurrency:
group: ${{ github.workflow }}-${{ github.ref }}
cancel-in-progress: trueThe pipeline begins with feature engineering:
jobs:
feature_engineering:
name: Compute Features
runs-on: ubuntu-latest
steps:
- name: Checkout repository
uses: actions/checkout@v3
- uses: ./.github/actions/setup
- name: Run pipeline
run: uv run ipython notebooks/1_fp_computing_features.ipynb
env:
HOPSWORKS_API_KEY: ${{ secrets.HOPSWORKS_API_KEY }}Once features are ready, the pipeline branches into parallel training jobs for two distinct models: the retrieval model and the ranking model:
train_retrieval:
needs: feature_engineering
name: Train Retrieval Model
# ... similar setup steps ...
train_ranking:
needs: feature_engineering
name: Train Ranking Model
# ... similar setup steps ...After the retrieval model training completes, we compute and index item embeddings:
computing_and_indexing_embeddings:
needs: train_retrieval
name: Compute Embeddings
# ... similar setup steps ...The final step creates the deployments:
create_deployments:
needs: computing_and_indexing_embeddings
name: Create Deployments
# ... similar setup steps ...As you can see, deploying and running our offline ML pipeline through GitHub Actions while leveraging free computing is easy.
See our GitHub Actions runs or the complete code.
Conclusion
Congratulations! After finishing this lesson, you created an end-to-end H&M real-time personalized recommender.
Within this lesson, you learned how to architect, implement and deploy offline and online inference pipelines using the Hopsworks AI Lakehouse.
Also, you’ve learned how to test the personalized recommender from a Streamlit app, highlighting how easy it is to leverage Hopsworks SDK for real-time ML deployments.
Ultimately, as a bonus, you’ve learned how to deploy and schedule all the offline ML pipelines using GitHub Actions.
Even if we finished the H&M personalized recommender, we are not done with the course yet!
In Lesson 5, we prepared something exciting: We will learn to enhance our H&M personalized recommender with LLMs.
💻 Explore all the lessons and the code in our freely available GitHub repository.
If you have questions or need clarification, feel free to ask. See you in the next session!
References
Literature
[1] Decodingml. (n.d.). GitHub - decodingml/personalized-recommender-course. GitHub. https://github.com/decodingml/personalized-recommender-course
[2] Hopsworks. (n.d.). What is an Inference Pipeline? - Hopsworks. https://www.hopsworks.ai/dictionary/inference-pipeline
[3] Hopsworks. (n.d.). What is Kserve? - Hopsworks. https://www.hopsworks.ai/dictionary/kserve
Images
If not otherwise stated, all images are created by the author.
Sponsors
Thank our sponsors for supporting our work!

Wonderful work there Paul, I did a quick read, am yet to go through the implementation the fun part for me. Kudos Paul