



Building a TikTok-like recommender
Scaling a personalized recommender to millions of items in real-time

The first lesson of the “Hands-on H&M Real-Time Personalized Recommender” open-source course — a free course that will teach you how to build and deploy a real-time personalized recommender for H&M fashion articles using the 4-stage recommender architecture, the two-tower model design and the Hopsworks AI Lakehouse.
Lessons:
Lesson 1: Building a TikTok-like recommender
Lesson 2: Feature pipelines for TikTok-like recommenders
Lesson 3: Training pipelines for TikTok-like recommenders
Lesson 4: Deploy scalable TikTok-like recommenders
Lesson 5: Using LLMs to build TikTok-like recommenders
🔗 Learn more about the course and its outline.
Lesson 1: Building a TikTok-like recommender
In this lesson, we will discuss the architecture of H&M's real-time personalized recommender. We will use a strategy similar to what TikTok employs for short videos, which will be applied to H&M retail items.
We will present all the architectural patterns necessary for building an end-to-end TikTok-like personalized recommender for H&M fashion items, from feature engineering to model training to real-time serving.
We will teach you how to use the 4-stage architecture to build a system that can handle recommendations from a catalog of millions of items.
We will also walk you through the two-tower model, a flexible neural network design that creates embeddings for users and items.
Ultimately, we will show you how to deploy the entire system using MLOps best practices by leveraging the feature/training/inference (FTI) architecture on top of Hopsworks AI Lakehouse.
By the end of this lesson, you will know what it takes to build a highly scalable and modular real-time personalized recommender on top of H&M data.
In future lessons, we will zoom into the details and code of each H&M real-time personalized recommender component.
💻 Explore all the lessons and the code in our freely available GitHub repository.
Table of Contents
A quick introduction to the H&M retail dataset
Core paradigms for personalized recommendations
Introducing the two-tower embedding model
Understanding the 4-stage recommender architecture
Applying the 4-stage architecture to our H&M use case
Presenting the feature/training/inference (FTI) architecture
Applying the FTI architecture to our retail use case
Deploying the offline ML pipelines using GitHub Actions
Quick demo of the H&M real-time personalized recommender
A quick introduction to the H&M retail dataset
The most standard use case for personalized recommendations is in retail, where you have customers, articles and transactions between the two.
The H&M Personalized Fashion Recommendations dataset [5], which we will use throughout this course, is a perfect example.
It contains the following CSV files:
articles.csv
customers.csv
transactions.csv
We will go deeper into each table in the next lesson when we will design the features.
When it comes to gathering custom data for personalized recommendations, the most challenging part is to get (or generate) meaningful interactions between a customer and an item, such as when a customer:
clicked on an item;
added an item to the cart;
bought an item.
Thus, we will leverage the transactions provided by the H&M dataset to train our models and present our use case.
But, to mimic a real-world scenario, we will gather new interactions from our PoC UI, which will influence the following predicted recommendations.
Core paradigms for personalized recommendations
When it comes to recommendations, you can choose between two core paradigms:
Content-based filtering: This approach recommends items by analyzing the features or characteristics of items a user has previously interacted with, then finding new items with similar features – for example, if a customer frequently buys floral dresses, the system would recommend other floral-patterned clothing items.
Collaborative filtering: This approach makes recommendations by identifying patterns in user-item interactions and finding similar users or items based on their behavior patterns. For instance, if customers who buy leather jackets also tend to buy black boots, the system would recommend black boots to new customers who purchase leather jackets.

Let’s see how we can apply these two paradigms using the two-tower model.
Introducing the two-tower embedding model
The first step in understanding how a neural network-based recommender works is to examine the architecture of the two-tower embedding model.
At its core, the two-tower model architecture aims to compute feature-rich embeddings for the customers and items in the same embedding space. Thus, when looking for recommendations for a customer, we can calculate the distance of the customer’s embeddings and the items to search for the most relevant item candidates [8].

The two-tower model architecture trains two neural networks in parallel:
The customer query encoder transforms customer features into a dense embedding vector.
The item candidates encoder transforms item features into dense embeddings in the same vector space as the customer embeddings.
Both encoders can process various types of features:
Customer encoder: demographic information, historical behavior, contextual features
Item encoder: tags, description, rating
This introduces a content-based paradigm. Similar items and customers will be clustered together if enough features are used.
A key distinction from traditional architectures is that the two-tower model processes user and item features separately. This makes it highly efficient for large-scale retrieval since item embeddings can be pre-computed and stored in an approximate nearest neighbor (ANN) index or database (also known as vector databases).
Using the dot product as a score for the loss function, where we expect a 1 when a customer interacts with an item and a 0 when there is no interaction, we indirectly use the cosine distance, which forces the two embeddings to be in the same vector space.
cos distance = dot product with normalized vectors
Using a dot product as a score for the loss function introduces a collaborative filtering paradigm because it captures customer-item interaction patterns. Customers with similar behaviors and items accessed in the same pattern will be clustered.
Thus, depending on how many features you use for the items and customers, the two-tower model can be only a collaborative filtering algorithm (if only the IDs are used) or both if there is enough signal in the provided features.
We will dig into the architecture of the two encoders and how they are trained in Lesson 3, explaining the training pipeline.
Let’s intuitively understand how these two models are used in the 4-stage recommender architecture.
Understanding the 4-stage recommender architecture
The 4-stage recommender architecture is the standard for building scalable, real-time personalized recommenders based on various data types and use cases.
It’s used and proposed by giants such as Nvidia [7] and YouTube [2].
In the 4-stage recsys architecture, the data flows in two ways:
An offline pipeline that computes the candidate embeddings and loads them to a vector index or database. This pipeline usually runs in batch mode.
An online pipeline that computes the actual recommendations for a customer. This pipeline can run in batch, async, real-time or streaming mode, depending on the type of application you build.
Computing the item candidate embeddings offline allows us to make recommendations from a large corpus (millions) of items while still being confident that the small number of recommended items is personalized and engaging for the user.
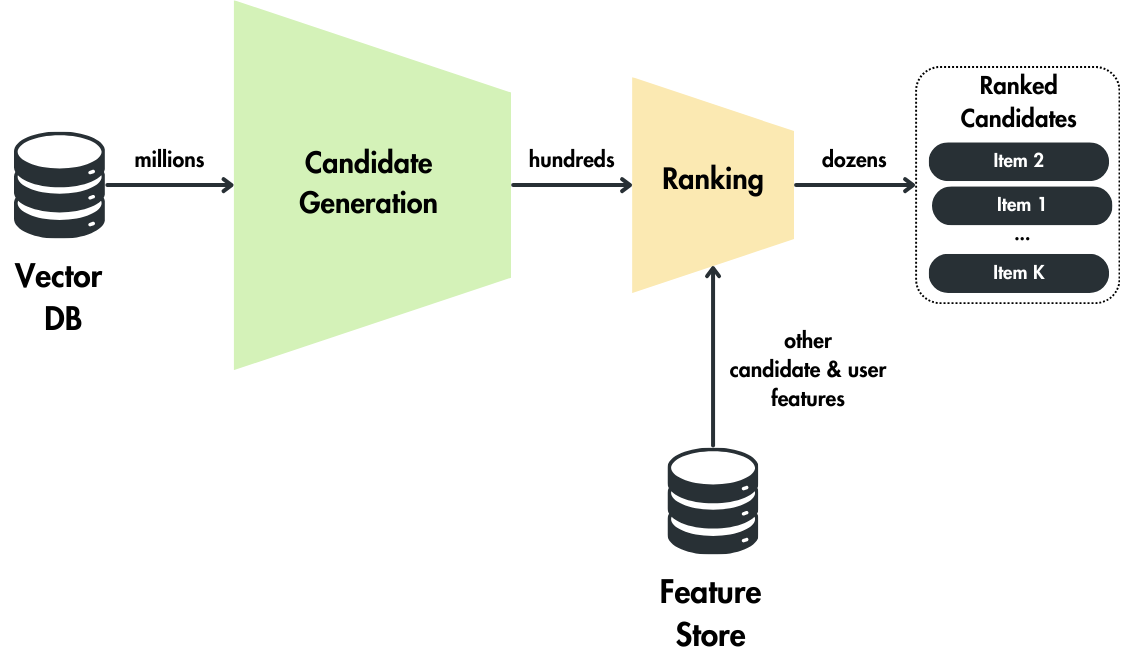
The offline pipeline leverages the Items Candidate Encoder Model (trained using the Two Tower model) to compute embeddings for all the items in our database. It loads the item embeddings and their metadata, such as the ID, into an approximate nearest neighbor (ANN) index optimized for low-latency retrieval. The ANN indexes come in two flavors:
vector index (e.g., ScaNN, Faiss);
vector database (e.g., Hopsworks, Qdrant, MongoDB).
By decoupling the item embedding creation from the actual recommendation, we can drastically speed up the recommendation for each customer as:
Everything we want to find (recommend) is precomputed when customers access our application.
We can optimize the offline and online pipelines differently for better latency, lower costs, required throughput, etc.
The online pipeline is split into 4-stages (as the name suggests), starting with the user’s requests and ending with the recommendations.

Stage 1
This stage aims to process a large (>100M elements up to millions) corpus of candidate items and retrieve a relevant subset (~hundreds) of items for downstream ranking and filtering tasks.
The candidate generation step only provides broad personalization via collaborative filtering. Similarities are expressed in coarse features such as item and customer IDs.
The pipeline takes a customer_id and other input features, such as the current date, computes the customer embedding using the Customer Query Model (trained using the Two Tower model), and queries the vector DB for similar candidate items.
Using the customer’s embedding, the vector DB (or index) scans the entire corpus and reduces it to xN potential candidates (~hundreds).
Stage 2
Stage 2 takes the N candidate items and applies various filters, such as removing items already seen or purchased.
The core idea is to filter out unnecessary candidates before proceeding to the most expensive operations from Stage 3. The filtering is often done using a Bloom filter, a space-efficient probabilistic data structure used to test whether an element is a set member (such as seen or purchased items).
After this stage, we are left with only xM item candidates.
Stage 3
Stage 3 takes the xM item candidates and prepares them for ranking. An algorithm that provides a score for each “(item candidate, customer)” tuple based on how relevant that item is to a particular customer.
During ranking, we can access more features describing the item and the user’s relationship, as only a few hundred items are being scored rather than the millions scored in candidate generation.
The ranking step is slower as we enhance the items and customers with multiple features. We usually use a feature store to query all the necessary features.
Thus, extra I/O overhead is added by querying the feature store, and the ranking algorithm is slower as it works with more data.
The ranking model can use a boosting tree, such as XGBoost or CatBoost, a neural network or even an LLM.
Presenting a few “best” recommendations in a list requires a fine-level representation to distinguish relative importance among the candidate items. The ranking network accomplishes this task by assigning a score to each item using a rich set of features describing the item and user.
Stage 4
After the ranking model scores each “(item candidate, customer)” tuple, we must order the items based on the ranking score plus other optional business logic.
The highest-scoring items are presented to the user and ranked by their score.
If the items candidate list is too extensive for our use case, we could further cut it to xK item candidates.
It is critical to order the items based on relevance. Having the most personalized candidates at the top increases the customer's probability of clicking on them.
For example, you want your No. 1 movie or playlist always to be the first thing when you open Netflix, YouTube or Spotify. You don’t want to explore too much until you find it.
By the end of Stage 4, we will have xK relevant and personalized items that we can display in our application as needed.
Let’s apply it to our H&M use case to understand how this works fully.
Applying the 4-stage architecture to our H&M use case
If we understand how the two-tower model and 4-stage architecture work, applying it to our H&M use case is very intuitive.
First, let’s understand who the “customers” and “items” are in our use case.
The customers are the users looking to buy items on the H&M site or application.
The items are the fashion items sold by H&M, such as clothes, socks, shoes, etc.
Thus, we must show the customers fashion items they are most likely to buy.
For example, if he searched for T-shirts, most likely we should recommend T-shirts. Our recsys should pick up on that.

Secondly, let’s look at a concrete flow of recommending H&M articles:
While a customer surfs the H&M app, we send its ID and date to the recsys inference pipeline.
The customer query model computes the customer’s embedding based on the two features from 1.
As the customer’s embedding is in the same vector space as the H&M fashion items, we leverage a Hopsworks vector index to retrieve a coarse list of relevant articles.
Next, we filtered out all the items the customer already clicked on or bought.
We enhance the fashion articles and customer with a more extensive list of features from our Hopsworks feature views.
We use a CatBoost model to rank the remaining fashion items relative to the customer.
We sort the articles based on the relevance score and show them to the customer.
But what is Hopsworks?
It’s an AI Lakehouse that will help us ship the recsys to production.
It provides the following capabilities:
Feature store: Store, version, and access the features required for training (offline, high throughput) and inference (online, low latencies). More on feature stores [11].
Model registry: Store, version, and access the models (candidate encoder, query encoder, ranking model).
Serving layer: Host the inference pipeline containing the 4 steps to make real-time predictions.
Given this, we can store our features in Hopsworks, make them available for training and inference, and deploy our models to production by leveraging their model registry and serving layer.
Click here to find out more about Hopsworks - The AI Lakehouse.
Let’s quickly present the FTI architecture and, in more detail, how we used Hopsworks to ship our recsys app.
Presenting the feature/training/inference (FTI) architecture
The pattern suggests that any ML system can be boiled down to these three pipelines: feature, training, and inference.
Jim Dowling, CEO and Co-Founder of Hopsworks introduced the pattern to simplify building production ML systems [3, 4].
The feature pipelines take raw data as input and output features and labels to train our model(s).
The training pipeline takes the features and labels from the feature stored as input and outputs our trained model(s).
The inference pipeline inputs the features & labels from the feature store and the trained model(s) from the model registry. With these two, predictions can be easily made in either batch or real-time mode.
To conclude, the most important thing you must remember about the FTI pipelines is their interface:
The feature pipeline takes in data and outputs features & labels saved to the feature store.
The training pipelines query the features store for features & labels and output a model to the model registry.
The inference pipeline uses the features from the feature store and the model from the model registry to make predictions.
It doesn’t matter how complex your ML system gets. These interfaces will remain the same.
There is a lot more to the FTI architecture. Consider reading this article [6] for a quick introduction or a more in-depth series on scaling ML pipelines using MLOps best practices, starting here [12].
Applying the FTI architecture to our retail use case
The final step in understanding the architecture of the H&M recsys is presenting how we can apply the FTI pattern to it.
This pattern will help us move from Notebooks to production by deploying our offline ML pipelines and serving the inference pipeline in real time (with the 4-stage logic).
The ML pipelines (feature, training, embeddings, inference) will be implemented in Python. Meanwhile, we will leverage the Hopsworks AI Lakehouse for storage and deployment.
Let’s see how we can do that by zooming in each pipeline independently.
The feature pipeline transforms raw H&M data (usually stored in a data warehouse) into features stored in Hopsworks feature groups.
We will detail the features and what a feature group is in Lesson 2. For now, you have to know that a feature group is similar to a table in a database, where we group related features (e.g., customers, articles, transactions, etc.). More on feature groups [9].

The training pipeline inputs the features from various Hopsworks feature views, trains the two-tower and ranking models, and saves them in the Hopsworks model registry.
Remember that the two-tower model trains two models in parallel: the items candidate and query encoders. Thus, we save them independently in the model registry, as we will use them at different times.
A feature view is a virtual table for read-only operations (training, inference). It is created based on multiple features picked from multiple feature groups. Doing so allows you to create virtual tables with the exact features you need for training (offline mode) or inference (online mode). More on feature views [10].
The embeddings inference pipeline (offline) loads the candidate model from the model registry and fashion items from the retrieval feature view, computes the embeddings, and loads them to the candidate embeddings Hopsworks vector index (also a feature group).
Notice how the embedding pipeline follows the interface of the inference pipeline proposed by the FTI architecture.
This is because the inference logic is split into offline and online pipelines, as discussed in the 4-stage recsys architecture section.
This highlights that the FTI pipelines are not only three pipelines but a mindmap for modeling your system, which usually contains many more components.
Ultimately, the real-time inference pipeline (online) loads the query retrieval and ranking models from the model registry and their associated features from the Hopsworks feature view.
This pipeline is deployed on Hopsworks AI Lakehouse as a real-time API called from the front end through HTTP requests.
The real-time inference pipeline wraps the 4-stage recsys logic, which serves as the final personalized recommendation for the customer.
We will provide more details about the serving infrastructure in Lesson 4.
The feature, training, and embedding inference pipelines run offline. Thus, we can leverage other tools to run them based on different triggers to update the features, models, and item candidates.
One option is GitHub Actions.
Deploying the offline ML pipelines using GitHub Actions
Following the FTI architecture, the ML pipelines are completely decoupled and can be run as independent components if we respect a particular order.
Thus, together with Hopsworks as an AI lakehouse, we can quickly ship the ML pipelines to GitHub Actions, which can run on a:
manual trigger;
schedule;
after merging a new feature branch in the main branch (or staging).

Because our models are small, we can use GitHub Actions for free computing. Thus, training them on a CPU is feasible.
Also, as GitHub Actions is well integrated with your code, with just a few lines of code, we can prepare the necessary Python environment, run the code, and chain the ML pipelines as a direct acyclic graph (DAG).
We will detail the implementation in Lesson 4.
Quick demo of the H&M real-time personalized recommender
To show an end-to-end PoC of our H&M real-time personalized recommender that is ready for production, we have used the following tech stack:
Hopsworks (serverless platform) offers a freemium plan to host our feature store, model registry, and real-time serving layer.
GitHub Actions to host and schedule our offline ML pipelines (as explained in the section above)
Streamlit to prototype a simple frontend to play around with the recommender. Also, we leverage Stream Cloud to host the frontend.
Will this cost me money? We will stick to the free tier for all these tools and platforms, allowing us to test the whole recsys series end-to-end at no cost.

To quickly test things out, follow the documentation from GitHub on how to set up Hopsworks, GitHub Actions, and Streamlit and run the entire recsys application.
Conclusion
This lesson taught us about the two-tower model, 4-stage recsys architecture, and the FTI pattern.
Then, we saw how to apply these patterns to our H&M use case.
In Lesson 2, we will start zooming in on the feature pipeline and Hopsworks, detailing the features we use for the two-tower and ranking models and the code.
💻 Explore all the lessons and the code in our freely available GitHub repository.
If you have questions or need clarification, feel free to ask. See you in the next session!
References
Literature
[1] Decodingml. (n.d.). GitHub - decodingml/personalized-recommender-course. GitHub. https://github.com/decodingml/personalized-recommender-course
[2] Covington, P., Adams, J., & Sargin, E. (n.d.). Deep Neural Networks for YouTube Recommendations. Google Research. https://static.googleusercontent.com/media/research.google.com/en//pubs/archive/45530.pdf
[3] Dowling, J. (2024a, August 5). Modularity and Composability for AI Systems with AI Pipelines and Shared Storage. Hopsworks. https://www.hopsworks.ai/post/modularity-and-composability-for-ai-systems-with-ai-pipelines-and-shared-storage
[4] Dowling, J. (2024b, November 1). From MLOps to ML Systems with Feature/Training/Inference Pipelines. Hopsworks. https://www.hopsworks.ai/post/mlops-to-ml-systems-with-fti-pipelines
[5] H&M personalized fashion recommendations. (n.d.). Kaggle. https://www.kaggle.com/competitions/h-and-m-personalized-fashion-recommendations
[6] Iusztin, P. (2024, August 10). Building ML system using the FTI architecture. Decoding ML Newsletter. https://decodingml.substack.com/p/building-ml-systems-the-right-way
[7] NVIDIA Merlin Recommender System Framework. (n.d.). NVIDIA Developer. https://developer.nvidia.com/merlin
[8] Wortz, J., & Totten, J. (2023, April 19). Tensorflow deep retrieval using Two Towers architecture. Google Cloud Blog. https://cloud.google.com/blog/products/ai-machine-learning/scaling-deep-retrieval-tensorflow-two-towers-architecture
[9] Hopsworks. (n.d.). Overview - HopsWorks documentation. https://docs.hopsworks.ai/latest/concepts/fs/feature_group/fg_overview/
[10] Hopsworks. (n.d.-b). Overview - HopsWorks documentation. https://docs.hopsworks.ai/latest/concepts/fs/feature_view/fv_overview/
[11] Hopsworks. (n.d.-a). What is a Feature Store: The Definitive Guide - Hopsworks. https://www.hopsworks.ai/dictionary/feature-store
[12] Hopsworks. (n.d.-b). What is a Machine Learning Pipeline? - Hopsworks. https://www.hopsworks.ai/dictionary/ml-pipeline
Images
If not otherwise stated, all images are created by the author.
Sponsors
Thank our sponsors for supporting our work!

Amazing introduction to the 4 stage design Paul! 💪
This was such a great resource, Thanks for all the hard work.