

Using LLMs to build TikTok-like recommenders
How LLMs transform classic recommender architectures

The fifth and final lesson of the “Hands-On Real-time Personalized Recommender” open-source course — a free course that will teach you how to build and deploy a production-ready real-time personalized recommender for H&M articles using the four-stage recsys architecture, the two-tower model design and the Hopsworks AI Lakehouse.
Lessons:
Lesson 1: Building a TikTok-like recommender
Lesson 2: Feature pipelines for TikTok-like recommenders
Lesson 3: Training pipelines for TikTok-like recommenders
Lesson 4: Deploy scalable TikTok-like recommenders
Lesson 5: Using LLMs to build TikTok-like recommenders
🔗 Learn more about the course and its outline.

Lesson 5: Using LLMs to build TikTok-like recommenders
In our previous lessons, we built and deployed a production-ready H&M personalized recommender using classical machine learning techniques.
We used a two-tower architecture for candidate generation and leveraged CatBoost for ranking, creating a scalable system for real-time recommendations.
Now, let’s enhance our recommender system by incorporating LLMs.
By the end of this lesson, you will learn how to:
Use LLMs for ranking in recommendation systems
Deploy the LLM-based ranking service using KServe
Use semantic search for personalized recommendations
Evaluate the effectiveness of LLMs for recommendations
Test our H&M LLM-powered personalized recommender system
💻 Explore all the lessons and the code in our freely available GitHub repository.
Why add LLMs to our recommender?
Traditional recommender systems face several limitations:
They struggle to capture nuanced user preferences that are better expressed in natural language
They require extensive training data and frequent retraining to adapt to new patterns
They can't explain their recommendations in a way humans can easily understand
LLMs offer a compelling solution to these challenges. They can:
Leverage semantic understanding to grasp products and user preferences
Process natural language queries to better understand user intent
Generate human-like explanations for recommendations
Adapt to new scenarios without explicit retraining
Upgrading our current architecture with LLMs
So far, our H&M recommender has relied on classical ML techniques:
Candidate generation using a two-tower neural network
Vector similarity search for retrieving relevant items
Final ranking using a CatBoost model
In this lesson, we'll explore two architectural enhancements:
LLM-based ranking: Replace our CatBoost ranker with an LLM to score and rank candidates based on context and natural language understanding. This allows us to incorporate product descriptions, user preferences, and style considerations in our ranking decisions.
Semantic search integration: Enable users to search for products using natural language queries, making the recommendation system more intuitive and accessible. Users can express their preferences directly: "Show me summer dresses similar to what I bought last month, but in lighter fabrics."
We'll implement these changes using the same production-ready architecture with Hopsworks Serverless and KServe [4], ensuring our system remains scalable and maintainable.
Table of Contents:
Building a ranking algorithm using LLMs
Deploying the ranking service using KServe
Using semantic search for personalized recommendations
Are LLMs for personalized recommendations any good?
Testing the H&M LLM-powered personalized recommender
1 - Building a ranking algorithm using LLMs
We will combine LLMs’ natural language understanding with the existing architecture’s structured data processing to rank products based on their purchase likelihood.
This approach is inspired by state-of-the-art research in the field. For example, the LlamaRec: Two-Stage Recommendation using Large Language Models for Ranking [2] leverages user interaction history and a verbalizer-based approach for ranking recommendations without generating long texts. Another valuable resource is the Survey on Large Language Models for Recommendation [3]. It discusses how LLMs can improve recommendation quality thanks to their extensive data training and high-quality textual representations.
Building on this research, our ranking system has three main components:
The prediction function handles the ranking logic
The prompt template guides the LLM’s behavior
An output parser processes LLM's responses
As seen in Lesson 1, the ranking algorithm is used in the 4-stage recommendation architecture. At Stage 1, a course list of candidate H&M articles is returned by querying the vector index using the customer embedding.
The ranking algorithm reorders the H&M items based on their predicted purchase likelihood. This LLM-based ranker uses detailed product attributes and customer context to enhance the final ordering of recommendations, improving the initial nearest-neighbor results.
Let's examine each component in detail.

The Prediction Function
The heart of our ranking system lies in the predict() method:
class Predict(object):
... # Other methods
def predict(self, inputs):
features = inputs[0].pop("ranking_features")[:20]
article_ids = inputs[0].pop("article_ids")[:20]
preprocessed_features = self._preprocess_features(features)
scores = []
for candidate in preprocessed_features_candidates:
try:
text = self.llm.invoke(candidate)
score = self.parser.parse(text)
except Exception as exception:
logging.error(exception)
# Add minimum default score in case of error
score = 0
scores.append(score)
return {"scores": scores, "article_ids": article_ids}The prediction function processes product features through the LLM in batches of 20 candidates, maintaining a reasonable inference time while ensuring reliable scoring. Each product's features are preprocessed, scored by the LLM, and paired with its article ID for tracking.
The Prompt Template
The prompt template structures the interaction with the LLM.
The prompt is designed to:
Define the assistant's role
Specify the exact format for input features
Handle both numeric and categorical features
Request a precise probability output with 4-decimal precision
PROMPT_TEMPLATE = """
You are a helpful assistant specialized in predicting customer behavior.
Your task is to analyze the features of a product and predict the
probability of it being purchased by a customer.
### Instructions:
1. Use the provided features of the product to make your prediction.
2. Consider the following numeric and categorical features:
- Numeric features: These are quantitative attributes
- Categorical features: These describe qualitative aspects
### Product and User Features:
Numeric features:
- Age: {age}
- Month Sin: {month_sin}
- Month Cos: {month_cos}
Categorical features:
- Product Type: {product_type_name}
- Product Group: {product_group_name}
- Graphical Appearance: {graphical_appearance_name}
- Colour Group: {colour_group_name}
- Perceived Colour Value: {perceived_colour_value_name}
- Perceived Colour Master Value: {perceived_colour_master_name}
- Department Name: {department_name}
- Index Name: {index_name}
- Department: {index_group_name}
- Sub-Department: {section_name}
- Group: {garment_group_name}
### Your Task:
Based on the features provided, predict the probability that the
customer will purchase this product to 4-decimals precision.
Provide the output in the following format:
Probability: """Parsing the Output
The ScoreOutputParser class leverages Pyndatic to ensure the extracted probabilities are valid numbers between 0 and 1, with error handling for malformed responses.
class ScoreOutputParser(BaseOutputParser[float]):
def parse(self, output) -> float:
text = output['text']
probability_str = text.split("Probability:")[1].strip()
probability = float(probability_str)
if not (0.0 <= probability <= 1.0):
raise ValueError("Probability value must be between 0 and 1.")
return probabilityThe ScoreOutputParser:
Extracts the probability value from the LLM's response
Convert the extracted value to a float
Validates the float is between 0 and 1
Returns the parsed score
Building with LangChain
Finally, we connect everything with LangChain:
class Predict(object):
... # Other methods
def _build_lang_chain(self):
model = ChatOpenAI(
model_name='gpt-4o-mini-2024-07-18',
temperature=0.7,
openai_api_key=self.openai_api_key,
)
prompt = PromptTemplate(
input_variables=self.input_variables,
template=PROMPT_TEMPLATE,
)
langchain = LLMChain(
llm=model,
prompt=prompt,
verbose=True
)
return langchainThis setup:
Initializes the LLM model
Creates the prompt template
Combines them into a chain for processing
In addition, we use Pydantic for data validation and settings management.
The error handling implementation includes:
Default scores of 0 for failed predictions
Validation of probability ranges
Logging of errors for debugging
This ensures that the data entering our models is validated and correctly structured, catching errors early and maintaining robust data handling. By combining LangChain and Pydantic, we balance the LLM's natural language capabilities with the need for reliable, structured outputs.

Access the entire Python class on our GitHub.
2 - Deploying the ranking service using KServe
Our LLM-based ranking deployment uses the same infrastructure built in Lesson 4, leveraging Kubernetes and KServe through Hopsworks serverless.
The query Transformer class
The online inference pipeline logic, which in our case follows the 4-stage design for recommenders, starts with the query Transformer class.
As explained in Lesson 4, the query Transformer computes the customer query embedding (stage 1) and then calls the ranking server for the rest of the steps.
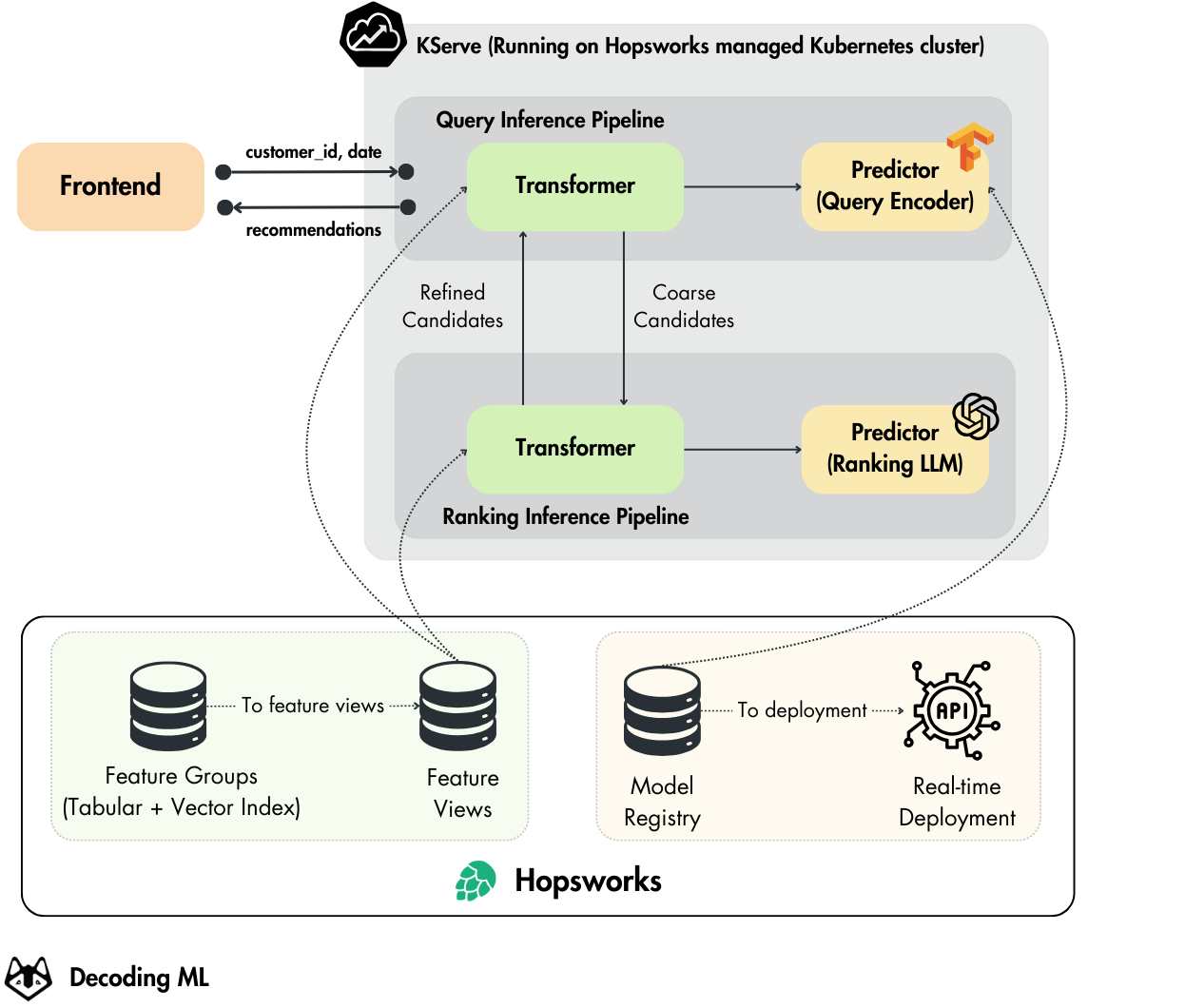
Thus, we implemented a flexible deployment architecture that uses a single line of code to route requests between our classical CatBoost and LLM-based rankers.
class Transformer(object):
def __init__(self) -> None:
... Other attributes
self.ranking_server = ms.get_deployment(self.ranking_model_type)This setup allows us to dynamically switch between ranking models using the ranking_model_type environment variable, which can be set to:
"ranking" for the classical CatBoost ranker
"llmranking" for our new LLM-based ranker
The Transformer class orchestrates this process through three key stages:
Initialization: Connects to Hopsworks and sets up the appropriate ranking model based on environment configuration
Preprocessing: Extract customer information, computes temporal features, and format inputs consistently for both rankers
Postprocessing: Returns ranked predictions in a standardized format, regardless of which ranking model was used
This unified pipeline allows us to experiment with different ranking approaches while maintaining consistent feature processing and prediction serving across all deployments without requiring any changes to our infrastructure code.
Environment Configuration in KServe
Our deployment settings are managed through a dedicated secrets preparation method:
class HopsworksQueryModel:
... # Other methods
@classmethod
def _prepare_secrets(cls, ranking_model_type: Literal["ranking", "llmranking"]):
connection = hopsworks.connection(
host="c.app.hopsworks.ai",
hostname_verification=False,
port=443,
api_key_value=settings.HOPSWORKS_API_KEY.get_secret_value(),
)
secrets_api = connection.get_secrets_api()
secrets = secrets_api.get_secrets()
existing_secret_keys = [secret.name for secret in secrets]
if "RANKING_MODEL_TYPE" in existing_secret_keys:
secrets_api._delete(name="RANKING_MODEL_TYPE")
project = hopsworks.login()
secrets_api.create_secret(
"RANKING_MODEL_TYPE",
ranking_model_type,
project=project.name,
)This approach is especially valuable in production environments, as it allows us to manage multiple deployment variants with different settings, all controlled via environment variables.
In practice, this means we can:
Run A/B tests with multiple configurations
Maintain separate testing and production environments
Quickly switch ranking models without redeploying the entire system
Deploying the ranking service using KServe
Since we maintain the same input/output interface across both CatBoost and LLM-based predictor, we can leverage the same Ranking Inference Pipeline Transformer class.
This ensures the preprocessing and postprocessing steps remain consistent across both ranking approaches.
During initialization, the Transformer class:
Connects to Hopsworks and sets up the feature store
Retrieves necessary feature groups and views: transactions, articles, customers, and candidate embeddings
Gets the ranking model from the model registry (either CatBoost or LLM-based)
Prepares the feature view for batch scoring
Extracts the required feature names for the ranking model
The preprocess method transforms raw inputs into the format needed for ranking:
class Transformer(object):
...
def preprocess(self, inputs):
# Extract customer ID and find nearest neighbors
customer_id = inputs["instances"][0]["customer_id"]
neighbors = self.candidate_index.find_neighbors(
inputs["instances"][0]["query_emb"],
k=100,
)
# Filter out already purchased items
already_bought_items_ids = self.transactions_fg.select("article_id")
.filter(self.transactions_fg.customer_id==customer_id)
.read(dataframe_type="pandas").values.reshape(-1).tolist()
# Prepare features for ranking
# [... feature preparation code ...]
return {
"inputs": [{
"ranking_features": ranking_model_inputs.values.tolist(),
"article_ids": item_id_list,
}]
}The postprocess() method handles the output standardization:
class Transformer(object):
...
def postprocess(self, outputs):
ranking = list(zip(outputs["scores"], outputs["article_ids"]))
ranking.sort(reverse=True)
return {"ranking": ranking}The LLM-based predictor replaces the CatBoost predictor while maintaining compatibility with the KServe interface.
class Predict(object):
def __init__(self):
self.input_variables = ["age", "month_sin", "month_cos", "product_type_name",
"product_group_name", ...]
self._retrieve_secrets()
self.llm = self._build_lang_chain()
self.parser = ScoreOutputParser()
def predict(self, inputs):
features = inputs[0].pop("ranking_features")[:20]
article_ids = inputs[0].pop("article_ids")[:20]
preprocessed_features = self._preprocess_features(features)
scores = []
for candidate in preprocessed_features:
try:
text = self.llm.invoke(candidate)
score = self.parser.parse(text)
except Exception as exception:
score = 0
scores.append(score)
return {
"scores": scores,
"article_ids": article_ids,
}The predictor is wrapped in a KServe-compatible class that implements the required interface:
Inherits from KServe's
ModelclassImplements
load()andpredict()methodsMaintains compatibility with the transformer pipeline
This modular setup makes deployment easier and allows for future experiments with new ranking methods without needing major infrastructure changes.
By keeping this consistent interface, we can easily switch between the CatBoost and LLM-based ranking approaches while reusing the same preprocessing and postprocessing pipeline.
LLM ranking deployment
To deploy the LLM ranker, we will create a new deployment that will override the classic one. This new deployment will include both the query and ranking inference pipelines.
This deployment leverages the Transformer class and the ranking_model_type environment variable to dynamically route requests to either the classical CatBoost ranker or the LLM-based ranker.
The deployment of the LLM ranker involves:
Model registration
Deployment
Starting the service
Testing functionality using the provided inference pipeline
Retrieve Top Recommendations
Debugging
1 - Register the LLM ranking model
First, register the LLM ranking model in the Hopsworks Model Registry to ensure it is properly versioned and ready for deployment:
ranking_model = hopsworks_integration.llm_ranking_serving.HopsworksLLMRankingModel()
ranking_model.register(project.get_model_registry())After registration, you can explore the model in Hopsworks Serverless: Data Science → Model Registry.
2 - Deploy the LLM ranking model
Initiate the deployment process using the deploy() method of the HopsworksLLMRankingModel class. This sets up the necessary infrastructure to serve the LLM ranker as a real-time service:
ranking_deployment = hopsworks_integration.llm_ranking_serving.HopsworksLLMRankingModel.deploy()3 - Start the deployment
Once the deployment is created, start it explicitly using the start() method to activate the ranking service:
ranking_deployment.start()Explore the deployments in Hopsworks Serverless: Data Science → Deployments.
4 - Test the deployment
Create a test example to verify the ranking deployment. Use the predict() method to perform inference on the deployed LLM ranker with features such as customer_id, query_emb (query embeddings), and temporal features (month_sin, month_cos):
test_ranking_input = [
{
"customer_id": "d327d0ad9e30085a436933d...",
"month_sin": 1.2246467991473532e-16,
"query_emb": [
0.214135289, 0.571055949, 0.330709577, -0.225899458,
...
],
"month_cos": -1.0,
}
]
ranked_candidates = ranking_deployment.predict(inputs=test_ranking_input)5 - Retrieve top recommendations
Use the get_top_recommendations() function to extract the top-ranked article IDs based on the predictions returned by the LLM ranker:
def get_top_recommendations(ranked_candidates, k=3):
return [candidate[-1] for candidate in ranked_candidates["ranking"][:k]]
recommendations = get_top_recommendations(ranked_candidates["predictions"], k=3)6 - Debugging logs
In case of failures, access the logs through Kibana for debugging. The logs provide detailed information about the inference pipeline and any errors that may have occurred:
ranking_deployment.get_logs(component="predictor", tail=200)3 - Using semantic search for personalized recommendations
Now that we understand how our system leverages semantic search with LLMs, let's explore how it integrates into a broader framework for personalized product recommendations.
The system operates with a structure similar to RAG but is adapted for product recommendations:
1. Embedding & indexing phase
Embedding: Process product descriptions and metadata through an embedding model
Indexing: Store these embeddings in a vector index, which acts as our "knowledge base" of products maintained in Hopsworks
2. Retrieval phase
When a user interacts with the system:
Query generation: Generate a query based on the users’ input and profile information
Retrieval: Retrieve similar products from the vector index using the query
Result: Return the most relevant products based on vector similarity
3. Personalization with LLM
In this system, there’s no generation or ranking phase. Instead, we:
Use an LLM to map the user profile and input query to a list of generated product candidates.
Use these LLM-generated items in the semantic search process to access similar H&M fashion articles in stock.
Combines embeddings with user preferences and product metadata for personalized recommendations
Figure 6 shows a high-level overview of the system operations.
The recommendation pipeline
Our recommendation pipeline consists of several key components:
1 - Feature Pipeline
Input: Takes H&M article data as input
Processing: Cleans H&M product descriptions and converts them into vectors using an embedding model
Storage: Stores article embeddings along with metadata
2 - Vector Index Layer
Maintenance: Stored in Hopsworks
Storage: Contains both article embeddings and metadata
Function: Enables efficient similarity search across the product catalog and retrieves similar articles based on the H&M articles description
3 - Personalization with LLM
Input: Takes user input and profile information
Processing: An LLM generates 3 to 5 fashion articles leveraging user profiles and preferences. As the LLM-generated items do not exist, we will use them as a proxy to query the H&M fashion articles index, returning items similar to those generated by the LLM.
Vector index for semantic search on fashion item descriptions
In Lesson 4, we used a pre-trained Sentence Transformer model all-MiniLM-L6-v2 to create embeddings for article descriptions.
These embeddings map each article description in a vector space, enabling semantic similarities comparison between articles.
Below is the code snippet used for creating the embeddings:
for i, desc in enumerate(articles_df["article_description"].head(n=3)):
logger.info(f"Item {i+1}:\n{desc}")
device = (
"cuda"
if torch.cuda.is_available()
else "mps"
if torch.backends.mps.is_available()
else "cpu"
)
logger.info(
f"Loading '{settings.FEATURES_EMBEDDING_MODEL_ID}' embedding model to {device=}"
)
model = SentenceTransformer(settings.FEATURES_EMBEDDING_MODEL_ID, device=device)
articles_df = generate_embeddings_for_dataframe(
articles_df, "article_description", model, batch_size=128
) # Adjust batch size as needed.To retrieve articles based on semantic similarity, the embeddings must be accessible through a feature view. This view combines multiple feature groups, ensuring the retrieval model has all the necessary features for downstream tasks, all achieved using the create_articles_feature_group function.
def create_articles_feature_group(
fs,
df: pd.DataFrame,
articles_description_embedding_dim: int,
online_enabled: bool = True,
):
emb = embedding.EmbeddingIndex()
emb.add_embedding("embeddings", articles_description_embedding_dim)
articles_fg = fs.get_or_create_feature_group(
name="articles",
version=1,
description="Fashion items data including type of item, visual description and category",
primary_key=["article_id"],
online_enabled=online_enabled,
features=constants.article_feature_description,
embedding_index=emb,
)
articles_fg.insert(df, wait=True)
return articles_fgThe EmbeddingIndex object was initialized using the following snippet:
emb = embedding.EmbeddingIndex()
emb.add_embedding("embeddings", articles_description_embedding_dim)This setup defined the embeddings column as the vector index, specifying its dimensionality through articles_description_embedding_dim. This configuration enables efficient similarity searches.
By joining this feature group with others in a feature view, we ensured all necessary data was accessible for retrieval models:
def create_retrieval_feature_view(fs):
trans_fg = fs.get_feature_group(name="transactions", version=1)
customers_fg = fs.get_feature_group(name="customers", version=1)
articles_fg = fs.get_feature_group(name="articles", version=1)
selected_features = (
trans_fg.select(
["customer_id", "article_id", "t_dat", "price", "month_sin", "month_cos"]
)
.join(
customers_fg.select(["age", "club_member_status", "age_group"]),
on="customer_id",
)
.join(
articles_fg.select(["garment_group_name", "index_group_name"]),
on="article_id",
)
)
feature_view = fs.get_or_create_feature_view(
name="retrieval",
query=selected_features,
version=1,
)
return feature_viewDynamic recommendations with LLMs
The llm_recommendations() function is the backbone of our personalized recommendation system, combining LLM-based reasoning with semantic search and state management to provide tailored suggestions for users.
Below, we break down its key steps and their integration into the broader recommendation pipeline.
1 - Initializing the recommendation system
The function begins by setting up the necessary environment for generating and displaying recommendations.
This includes initializing the session state to track user interactions, loading the embedding model, and configuring the interface for user input.
# Initialize session state and load embedding model
initialize_llm_state()
embedding_model = SentenceTransformer(settings.FEATURES_EMBEDDING_MODEL_ID)
# Gender selection
gender = st.selectbox("Select gender:", ("Male", "Female"))
# Input options for fashion needs
input_options = [
"I'm going to the beach for a week-long vacation. What items do I need?",
"I have a formal winter wedding to attend next month. What should I wear?",
"I'm starting a new job at a tech startup with a casual dress code. What items should I add to my wardrobe?",
"Custom input",
]
selected_input = st.selectbox("Choose your fashion need or enter a custom one:", input_options)
# Handle custom user input if selected
if selected_input == "Custom input":
user_request = st.text_input("Enter your custom fashion need:")
else:
user_request = selected_inputThis setup captures user preferences, including gender and specific fashion needs, which are later used to tailor the recommendations.
2 - Generating initial recommendations
When the user clicks the “Get LLM Recommendations” button, the system activates the LLM to generate context-aware recommendations. These are tailored to the user’s input and gender.
if st.button("Get LLM Recommendations") and user_request:
with st.spinner("Generating recommendations..."):
fashion_chain = get_fashion_chain(api_key)
item_recommendations, summary = get_fashion_recommendations(
user_request, fashion_chain, gender
)The output includes a categorized list of recommended items and a summary of the outfit or style suggested.
3 - Integrating semantic search for similar items
The system uses semantic search to retrieve products similar to the LLM-generated descriptions, leveraging embeddings stored in the vector index.
similar_items = get_similar_items(description, embedding_model, articles_fv)4 - Real-time user interaction and updates
The system dynamically tracks user interactions, such as purchases, and updates the recommendations in real time. For example, if a user marks an item as purchased, a replacement is automatically selected from the extra items.
# Track purchased items and update recommendations
tracker.track_shown_items(customer_id, [(item[1][0], 0.0) for item in shown_items])
if was_purchased:
category_updated = True
extra_items = st.session_state.llm_extra_items.get(category, [])
if extra_items:
new_item = extra_items.pop(0)
remaining_items.append(new_item)This mechanism ensures that the recommendations evolve based on user feedback, maintaining a dynamic and personalized experience.
5 - Displaying recommendations and summaries
The function organizes recommendations into categories, each accompanied by visual and textual details. It also provides a summary of the outfit or style, enhancing the user experience.
# Display outfit summary if available
if st.session_state.outfit_summary:
st.markdown("## 🎨 Outfit Summary")
st.markdown(
f"<h3 style='font-size: 20px;'>{st.session_state.outfit_summary}</h3>",
unsafe_allow_html=True,
)The recommendations are displayed in a clean, organized format, allowing users to browse and interact with the items easily.
Decomposing key functions in the LLM recommender
In the previous section, we described the high-level flow of how the system generates personalized fashion recommendations. Now, let’s dive deeper into the core functions that drive this process, ensuring that each step works in harmony to deliver tailored, context-aware suggestions.
The get_fashion_chain() function and its prompt template
The first critical piece is the get_fashion_chain() function, which sets up the conversational model used for generating recommendations.
This function uses a prompt template that structures the LLM’s response by defining how it should categorize, describe, and summarize the recommended items.
The prompt is designed to generate 3-5 fashion items that follow context-specific recommendations, providing a clear format for the LLM’s outputs.
template = """
You are a fashion recommender for H&M.
Customer request: {user_input}
Gender: {gender}
Generate 3-5 necessary fashion items with detailed descriptions, tailored for an H&M-style dataset and appropriate for the specified gender.
Each item description should be specific, suitable for creating embeddings, and relevant to the gender.
...
Example for male gender:
👖 Pants @ Slim-fit dark wash jeans with subtle distressing | 👕 Top @ Classic
...
"""The get_fashion_recommendations() function
Once the fashion chain is initialized, the get_fashion_recommendations() function takes over.
It receives user input and gender preferences and passes them to the LLM chain to produce a set of recommendations.
This function carefully parses the LLM’s response into categorized suggestions and an overall outfit summary that aligns with the user’s needs and preferences.
def get_fashion_recommendations(user_input, fashion_chain, gender):
response = fashion_chain.run(user_input=user_input, gender=gender)
items = response.strip().split(" | ")
outfit_summary = items[-1] if len(items) > 1 else "No summary available."
item_descriptions = items[:-1] if len(items) > 1 else items
parsed_items = []
for item in item_descriptions:
try:
emoji_category, description = item.split(" @ ", 1)
emoji, category = emoji_category.split(" ", 1)
parsed_items.append((emoji, category, description))
except ValueError:
parsed_items.append(("🔷", "Item", item))
return parsed_items, outfit_summaryThe get_similar_items() function
Now that we have a set of fashion items generated by the LLM, we must match them with our actual H&M inventory before showing them to the user.
The LLM-generated items are a proxy between the user’s preferences and the real H&M inventory.
We cannot directly use semantic search between the user query and item description because the semantics of the two are different.
But by mapping the user query (plus the customer features) to a set of article descriptions, we can successfully perform a semantic search between the generated and the real H&M fashion article descriptions:
def get_similar_items(description, embedding_model, articles_fv):
description_embedding = embedding_model.encode(description)
return articles_fv.find_neighbors(description_embedding, k=25)Streamlit code for content display
Finally, the entire recommendation process is presented to the user through a Streamlit interface.
This section of the code handles the visualization of recommendations, displaying categories, individual items, and outfit summaries.
It also integrates interactive features that allow users to engage with the recommendations and track their actions, such as making a purchase or revisiting previous suggestions.
The entire semantic search for recommendations code is available on our GitHub.
4 - Are LLMs for Personalized Recommendations Any Good?
Using LLMs for personalized recommendations is an exciting approach that opens up many opportunities, but it comes with challenges that make it an experimental exploration at this stage.
Early and experimental: While research and early experiments are promising, this approach is still in its infancy. The integration of LLMs into large-scale recommendation systems is a developing field, and established best practices have yet to be fully defined.
Cost implications: One of the biggest challenges with LLMs is their computational cost. Running LLMs in real-time for ranking or semantic search requires substantial hardware resources. This can significantly increase operational expenses compared to traditional ML methods.
Latency and scalability: LLMs can introduce higher latency, which may negatively impact user experience, especially in real-time systems. Scaling these systems to serve millions of users simultaneously requires careful planning, optimization, and substantial infrastructure investments.
Potential for bias and overfitting: LLMs heavily rely on their training data, which can lead to biases or an overemphasis on textual features. This could result in suboptimal recommendations, especially if structured data signals like customer purchase history or behavioral patterns are not properly integrated.
Research and innovation needed: Further research is essential to understand how LLMs can complement or enhance classical recommender system architectures. Questions regarding hybrid approaches, efficient fine-tuning, and the trade-offs between accuracy, latency, and cost require deeper exploration before LLMs can be deemed production-ready.
In conclusion, while LLMs offer intriguing possibilities for personalized recommendations, they are not yet a silver bullet.
For now, they are best suited for experimental setups, PoCs, niche applications, or as a complementary layer to existing recommender systems.
5 - Testing the H&M LLM-Powered Personalized Recommender
We are finally here: the moment where we can test our H&M real-time personalized recommender powered by LLMs!
To make testing seamless, we’ve built a simple Streamlit app that allows us to visualize real-time recommendations for different users and interact with the system.
The app also lets you generate new user interactions to see how recommendations adapt over time. While we won’t dive into the Streamlit code itself, under the hood, calling the KServe LLM ranking deployment through Hopsworks is as simple as:
ranked_candidates = ranking_deployment.predict(inputs=test_ranking_input)Everything else is Streamlit code, which you can find in our GitHub repository.
Deploy the KServe LLM Ranking System
First, deploy the LLM ranker using the provided make command:
make create-deployments-llm-rankingAfter running this command, you can view and manage the deployment in Hopsworks Serverless → Data Science → Deployments.
Now, we can use our H&M personalized recommender using the LLM ranking service instead of the CatBoost one.
For the deployments to run successfully, you must first run the feature and training pipelines: do that with a few commands you can find on our GitHub ⇠
Use the Streamlit App with "LLM Recommendations"
Also, our Streamlit app has been updated to include an “LLM Recommendations” feature to test out the semantic search recommender.
This allows us to interactively test the semantic search feature, explore recommendations for different users, and compare the results to the standard recommender.
You can start the app by running:
make start-ui-llm-rankingOnce started, the app will be accessible at http://localhost:8501/
Find a step-by-step installation and usage guide on our GitHub ⇠
Conclusion
Congratulations on completing the "Hands-On Real-time Personalized Recommender" course! You've come a long way– from building basic recommendation systems to implementing sophisticated LLM-powered recommenders.
Throughout these five lessons, you've learned to:
Build and deploy a production-ready H&M real-time personalized recommender
Implement feature and training pipelines
Create scalable deployment architectures
Enhance recommendations with LLM capabilities
Whether you're working on e-commerce platforms like H&M or content recommendation systems like TikTok, the principles and architectures covered in this course provide a solid foundation for your recommender system projects.
Thank you for learning with Decoding ML and Hopsworks. We hope this course helps you create fantastic recommendation systems for your future projects!
💻 Explore all the lessons and the code in our freely available GitHub repository.
If you have questions or need clarification, feel free to ask. See you in the next session!
References
Literature
[1] Decodingml. (n.d.). GitHub - decodingml/personalized-recommender-course. GitHub. https://github.com/decodingml/personalized-recommender-course
[2] Yue, Z., Rabhi, S., Moreira, G. de S. P., Wang, D., & Oldridge, E. (2023). LlamaRec: Two-Stage Recommendation using Large Language Models for Ranking.
[3] Wu, L., Zheng, Z., Qiu, Z., Wang, H., Gu, H., Shen, T., Qin, C., Zhu, C., Zhu, H., Liu, Q., Xiong, H., & Chen, E. (2023). A Survey on Large Language Models for Recommendation.
[4] Hopsworks. (n.d.). What is Kserve? - Hopsworks. https://www.hopsworks.ai/dictionary/kserve
Images
If not otherwise stated, all images are created by the author.
Sponsors
Thank our sponsors for supporting our work!

Thank you so much for this.
I have learn a lot from this.