

Getting Agent Architecture Right
Designing real-world AI agents with MCP without burning your time, money, and SANITY.

The third lesson of the open-source course Designing Enterprise MCP Systems — a free course that will teach you how to architect and build AI-powered developer workflows that scale across teams and tools.
A 3-lesson journey, where you will learn how to:
Architect LLM applications with clean, modular MCP-based designs.
Build real-world developer experience automations, like an AI PR Reviewer Assistant.
Choose the right AI agent architecture for scale and adaptability.
Lessons:
Lesson 1: Why MCP Breaks Old Enterprise AI Architectures
Lesson 2: Build with MCP Like a Real Engineer
Lesson 3: Getting Agent Architecture Right
🔗 Learn more about the course and its outline.
Getting Agent Architecture Right
Building AI agents or LLM workflows isn’t just about choosing the right model or plugging in tools — it’s about choosing the right structure.
Take our AI PR reviewer.
The temptation to over-engineer is always there: slap on a planner, dynamic routing, memory, tool orchestration — the full “agent stack.”
But does reviewing a pull request really need that level of complexity?
Most of the time, the answer is no. The smartest move is often the simplest: treat the task as a workflow first, and an AI problem second.
Before you add another layer of "thinking" to your system, ask yourself:
👉 What kind of reasoning and control does this use case actually require?
This lesson is about figuring out how much reasoning your PR reviewer really needs — and how to design the simplest architecture that actually gets the job done.
Up until now, in the first 2 lessons, we’ve mostly focused on MCP servers — how they expose tools and how the Host talks to them.
What we haven’t stopped to examine is the Host itself, and in particular, the logic that decides how a request is actually handled. This is where the real architectural choices start to matter.
We skimmed over this earlier, but it’s worth pausing to ask: did we really use the best design?
That’s what comes next.
We’ll use the PR Reviewer Assistant as a running example to explore different AI architectural patterns — and see how each one shapes reasoning, adaptability, cost, and long-term maintainability.
You’ll learn how to:
Weigh latency vs. cost vs. performance when deciding between workflows, agents, and hybrids
Balance control vs. delegation in agentic system design
Apply five core agent patterns — and see when each makes sense for our PR Reviewer
Ask the right architecture questions that matter in enterprise systems
By the end, you’ll have a framework for choosing the right architecture for your own systems — and the confidence to avoid overengineering when a simple workflow will do the job.
Table of contents:
Why agent architecture matters
When agents backfire
Agent patterns in action
How to pick the right architecture
Applying the decision framework to our use case
↓ But first, a quick word from our sponsors.
The Full Stack AI Engineering Course (Affiliate)
Trying to get into AI Engineering, but don’t know where to start?
When learning something new, to avoid wasting time, we need structure. That’s why if you consider a career in AI Engineering, we heartily recommend The Full Stack AI Engineering Course from the Towards AI Academy.
It’s full-stack. Therefore, it covers everything you need from LLMs, prompting, RAG, fine-tuning and agents.
Similar to what I preach through Decoding ML and my LLM Engineer’s Handbook, the course is project-focused. Made for active builders who, through a bit of sweat, want to build awesome stuff!

Instead of focusing on dozens of mini-projects that don’t reflect the real world. During the course, you will design, implement and deploy an AI Tutor as your capstone project, reflecting an end-to-end workflow similar to what you would do at your job.
You can find more details by clicking the button below. They offer a free preview of the course and a 30-Day Money-Back Guarantee.
Use code Paul_15 for 15% off and to keep Decoding ML free.
💭 As I am developing my Agentic AI Engineering course together with the Towards AI team, I am confident that we are 100% on the same page. A massive passion for AI and the will to put in hard work for something worth your time.
↓ Now, back to our lesson.
1. Why agent architecture matters
When I first started building the AI PR reviewer, I thought: this is perfect for a full agentic setup.
Multiple steps, external tools, reasoning across different contexts — it feels like a textbook agent problem, right?
But the deeper I went, the more obvious it became: I wasn’t adding power, I was adding complexity. Each new layer didn’t make the reviewer smarter, it just made it harder to predict, debug, and scale.
Agentic design is powerful — but it’s not free.
As soon as you introduce planning, tool selection, or dynamic reasoning into your system, complexity starts to creep in. Without the right structure, that complexity becomes a problem.
Poor agent architecture shows up fast, and not in fun ways:
Inconsistent behavior across similar inputs
Higher latency and unnecessary token usage
Logic that’s difficult to trace, test, or maintain
Systems that don’t scale or generalize across use cases
These issues aren’t theoretical. They show up quickly in production, especially in internal tooling and automation pipelines.
The truth is that architecture shapes everything: how decisions are made, how tools are invoked, and how context is managed. Two systems using the same model and inputs can behave entirely differently depending on their underlying structure.
Good architecture leads to reliable, adaptive assistants. Poor structure leads to fragile pipelines, mounting costs, and painful rewrites.
Choosing the right level of agentic complexity early on — and applying it only where it adds real value — often makes the difference between a working demo and a maintainable product.
2. When agents backfire
The flip side of “agent everything” is that agents can easily make things worse. When you push too much logic into agents, things can go sideways fast.
Results that should be deterministic start to vary.
Latency and token costs creep up with every extra reasoning step.
Debugging becomes harder because there’s no clear, fixed path to trace.
And what looked fine in a demo suddenly struggles to scale or reproduce reliably in production.
Let’s take the PR Reviewer use case.
❌ When not to use an agent: the final step is always posting the review to Slack. There’s no ambiguity — it happens every time. That makes it a fixed workflow step, so we just call Slack directly at the end of the pipeline.
Note: We could let the agent decide, but (1) there’s no guarantee it will trigger reliably, and (2) it adds cost and latency—extra tokens and usually one more reasoning pass after gathering context.
✅ When to use an agent: linking Asana tasks is different. A PR may or may not reference a task, and detecting that requires interpretation. Here, agentic reasoning adds value — the LLM can infer from the PR description whether an Asana task is linked.
Note: In some setups, you could handle this with a simple regex if the naming convention is reliable — but agents give you flexibility when formats vary.
The lesson: use agents where ambiguity exists, not where the path is already clear.
So did we apply the lesson correctly in our design?
Not quite.
We nailed the Asana part — that’s ambiguous, and it’s exactly where agentic reasoning shines. The model can interpret whether a PR really links to a task, instead of relying on brittle regex rules. Perfect use case.
Where we slipped was in letting the agent handle something deterministic: asking for the code diff. That isn’t reasoning. The diff should be retrieved from the Github MCP Server directly using the webhook event and passed into the prompt at the first pass.
To see why, let’s revisit the PR Reviewer data flow.
If we look back at the data flow in Figure 2, the gap becomes obvious.
The real issue shows up after step 3, when the PR Review Prompt is fetched. Instead of calling the GitHub MCP Server tool immediately to retrieve the diff, we allowed the agent’s reasoning loop to decide when and how to request it.
That was a design mistake.
Retrieving a diff is not a reasoning task, it is a deterministic one. The correct approach is to fetch the diff directly from the GitHub MCP Server using the pull request webhook payload and inject it into the prompt at the very first pass in step 4.
By anchoring diff retrieval at this point in the flow, the agent begins reasoning with the right context already in place, instead of wasting cycles on something the host should handle deterministically.
That way, the agent spends its “intelligence budget” on interpretation and judgment — not on asking for data it could have been given in the first place.
3. Agentic patterns in action
Agent and workflow architectures differ in control, flexibility, and cost.
Workflows run a predefined sequence of steps — great for speed, testability, and cost control.
Agents decide which step to take next — useful for ambiguity and flexible contexts, but they add latency, variability, and debugging headaches.
Semi-workflows mix the two: a deterministic backbone with agentic branches only where interpretation or judgment is needed. Here, the LLM directs control flow through predefined code paths.
From here, we’ll dive into five core patterns — ReAct, Self-Reflective Agent, Network of Agents (Swarm), Supervisor, and Hybrid Workflow (Semi-workflow) — and show how each could be used to model the PR Reviewer.
Most other agent designs are just small variations on these. In practice, if you understand the five we’re about to cover, you can map almost any new “agent framework” you see back to one of them.
Note: Tool-calling is not presented as a separate pattern here. Within MCP, tool execution is already a built-in capability, and it naturally integrates with the five patterns we’ll cover.
Let’s walk through each pattern and see how it plays out in the PR Reviewer — and whether it proves to be a good fit or not for this use case.
The Self-Reflective Agent Pattern
A self-reflective agent produces an initial answer, then deliberately critiques and revises it before returning the final output. Think of it as a built-in reviewer: one pass to draft, one (short) pass to check coverage, risks, tone, and fix gaps.
This Self-Reflective Agent pattern unfolds in five stages:
Prepare Context (Deterministic): Collect all inputs and package them cleanly for the LLM.
Draft (Generate → Initial Response): The LLM produces its best first answer given the context.
Reflect (Evaluate): The LLM critiques its own draft against a short rubric (e.g., “Did I cover security? Did I mention missing tests?”).
Revise (Loop): Based on the reflections, the LLM iterates — adjusting the draft and re-checking until it passes quality criteria or the max cycle limit (
n times).Return / Deliver (Final Response): The improved review is sent to its destination.
Why it’s useful
Big quality lift for a small latency/token bump (usually +1 model call).
More predictable and cheaper than full ReAct loops.
Easy to reason about and audit (draft → reflect → finalize).
When to use it: You need higher quality or consistent tone (at the expense of latency) but don’t want full multi-step agent complexity.
Now how can we apply it to redesign our PR Reviewer?
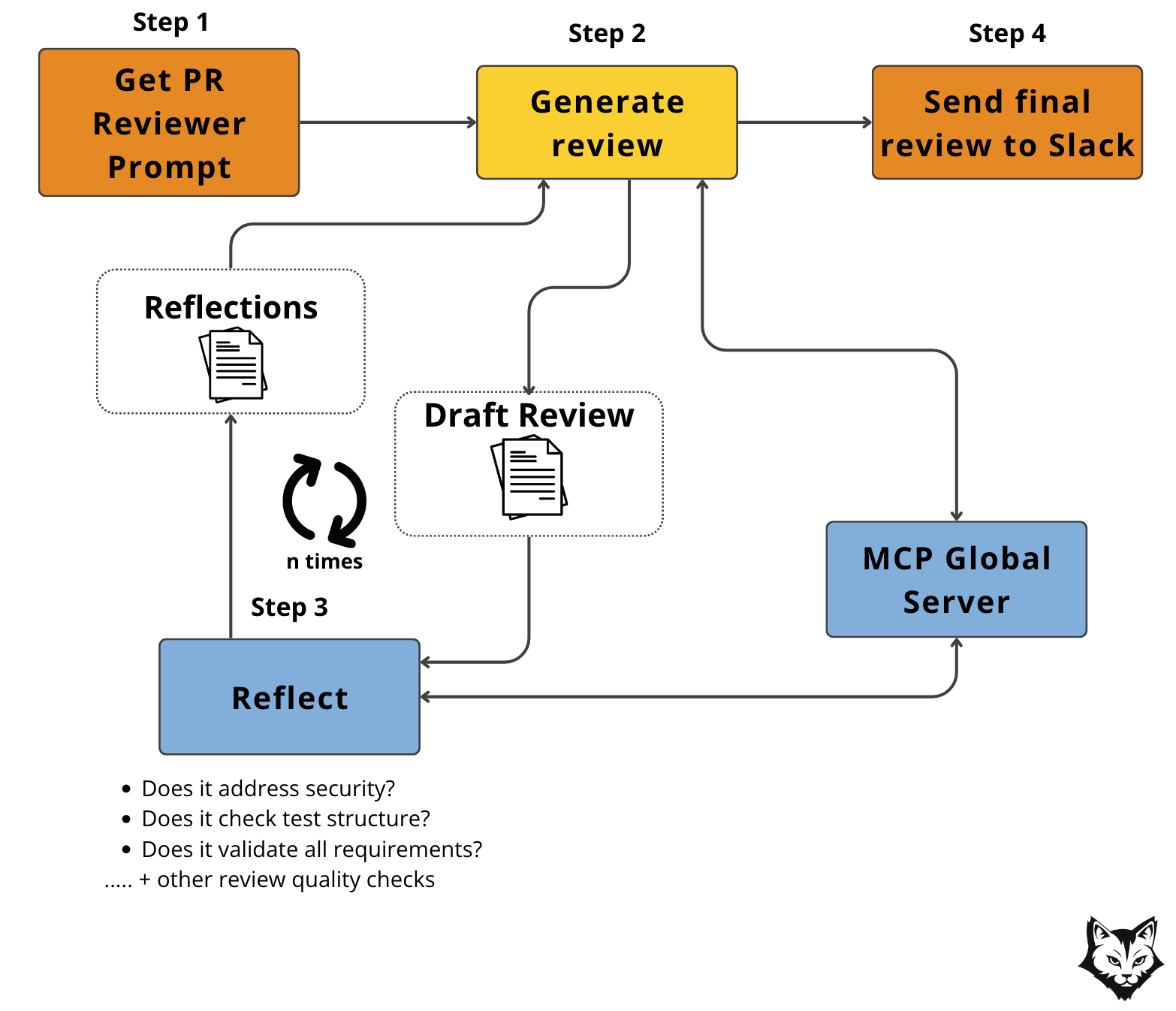
The flow starts with Step 1, getting the PR Reviewer Prompt — the raw context of a pull request, like diffs, metadata. This sets the stage for the review process.
In Step 2, Generate Review, the LLM drafts feedback while pulling extra context from the MCP Global Server: linked Asana tasks, past review comments, or JIRA issues. The first draft is generated using all the extra content given.
Next comes Step 3, the Reflection. The draft cycles through iterative passes to check various quality assessments such as security, test structure, requirements, and others. Here too, the MCP server can inject specialized prompts or embedded guidelines from the Agent Scope Server, ensuring the review matches company standards.
Once the loop produces a strong final version, the review is sent to Slack in Step 4. Finally, the team sees a review that’s context-aware, enterprise-aligned, and thoroughly refined.
The ReAct Agent Pattern
A ReAct agent explicitly interleaves reasoning with actions: it thinks, decides what tool to use, executes it, observes the result, and then continues reasoning.
It’s like watching a developer debug in real time — “Hmm, I need the diff → run the diff tool → oh, here’s the result → now I can check security → …” until the job is done.
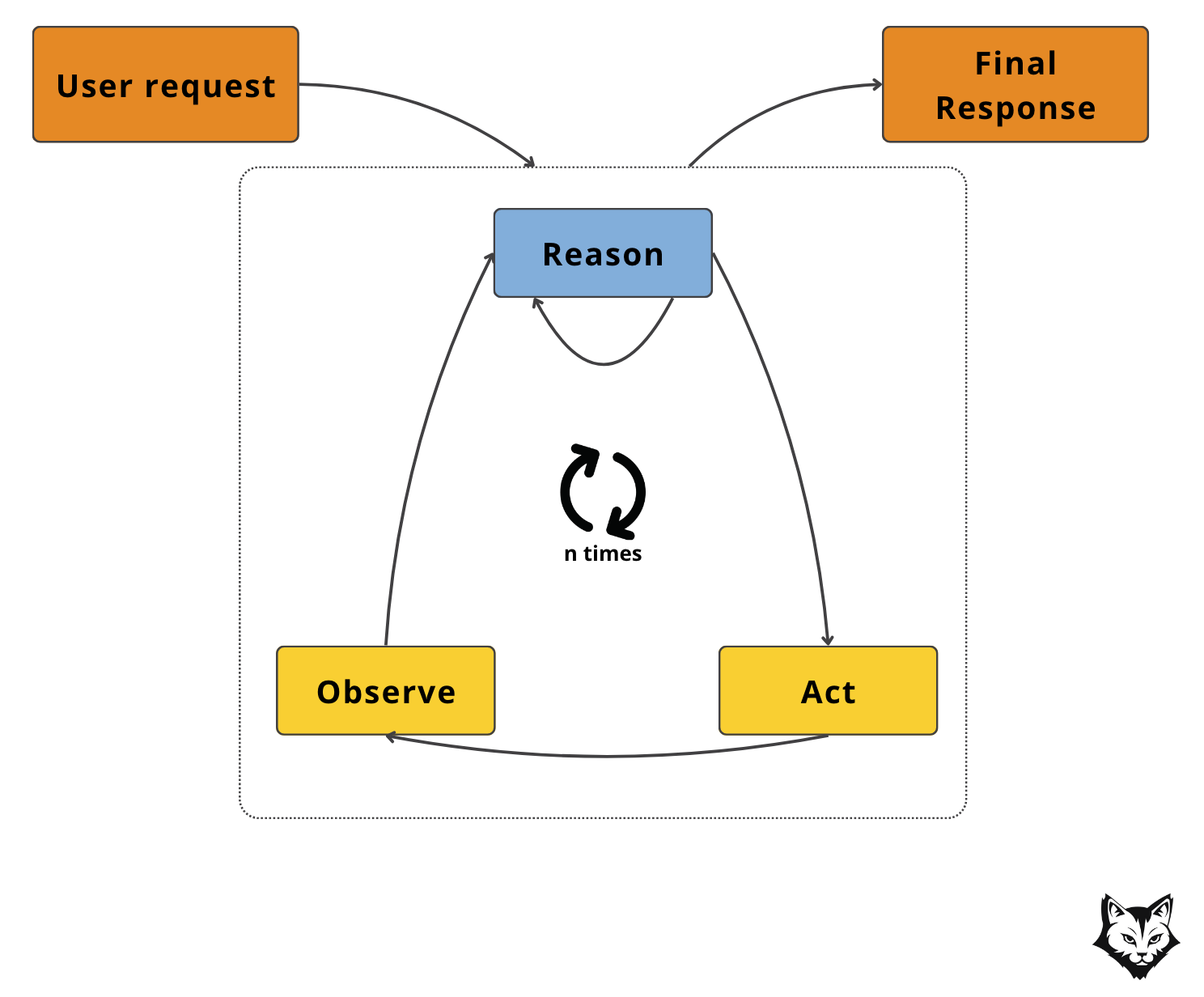
This ReAct Agent pattern unfolds in four key stages:
Prepare Context (Deterministic): Collect initial inputs like PR metadata and set up the environment.
Reason → Act → Observe Loop: The LLM alternates between internal reasoning (“What do I need?”), tool execution (e.g., fetch diff, scan code), and incorporating the tool’s output back into its reasoning.
Iterate (n times): The loop continues until the agent reaches a state where no new actions are needed.
Return / Deliver (Final Response): The agent consolidates all findings and outputs the review.
Why it’s useful
Extremely flexible: the agent decides dynamically which tools to call and in what order.
Handles ambiguity gracefully (e.g., deciding if a security scan is needed).
More transparent than black-box models: you can trace its thought-action-observation steps.
When to use it: When the sequence of tasks can’t be fully predefined — e.g., sometimes the agent needs to fetch Asana context, other times just run a security scan — and you want a single agent to decide step by step which tools to invoke.
It’s actually very easy to evolve our PR Reviewer implementation into a full ReAct pattern.
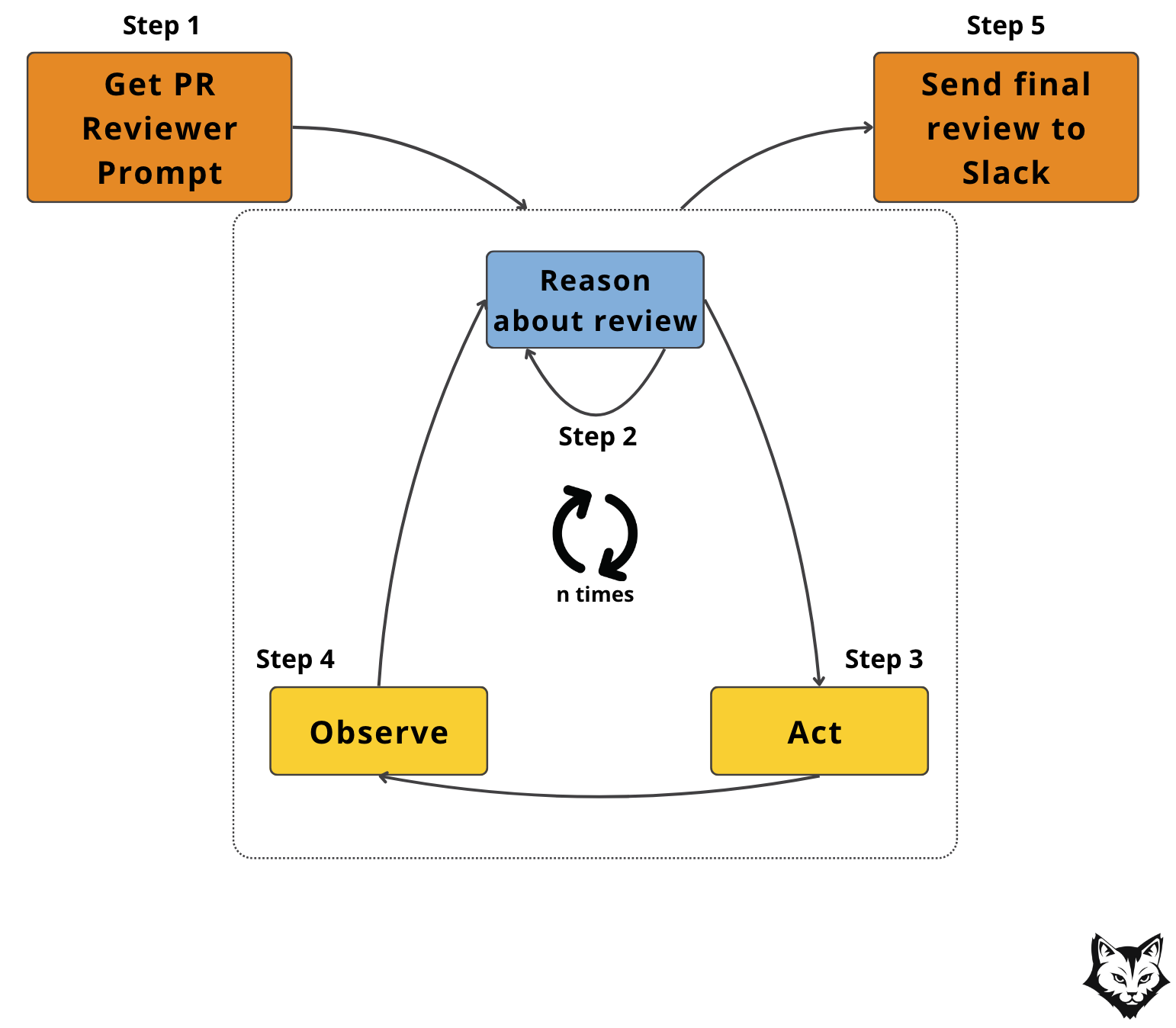
We already have two of the three key pieces in place:
Act: the LLM can call tools (e.g., fetch diff, pull Asana tasks).
Observe: each tool’s response is fed back into the conversation history, so the model can use it in the next step.
Reason: this is the piece we’ve kept minimal so far. In our current loop, the model only reasons enough to decide on the next action. To fully embrace ReAct, we’d add an explicit internal reasoning loop — letting the LLM reflect with itself between actions, before deciding what to do next.
That reasoning loop is the difference between “tool calls on demand” and a true Reason → Act → Observe cycle. With it, the PR Reviewer could pause, weigh different options, and plan multi-step strategies instead of reacting tool-by-tool.
💡 Remember the Self-Reflective Agent Pattern? You can essentially achieve that using ReAct and some smart prompt engineering.
In other words: our implementation is already 80% of the way there. All it needs is the inner reasoning pass to become a full ReAct agent.
👉 Want to implement these patterns from scratch? Check out the Agentic Patterns Course made by
.
The Network of Agents Pattern
Now let’s dive into some multi-agent patterns.
A Network (or Swarm) of Agents spreads the workload across multiple specialized agents, each with its own role and scope.
Instead of one model juggling everything, you get a swarm where each agent tackles a slice of the problem — style, tests, security, Asana context — and then their results are combined.
It’s like having a review board instead of a single reviewer: one person checks code quality, another checks documentation, another ensures security — all working in parallel.
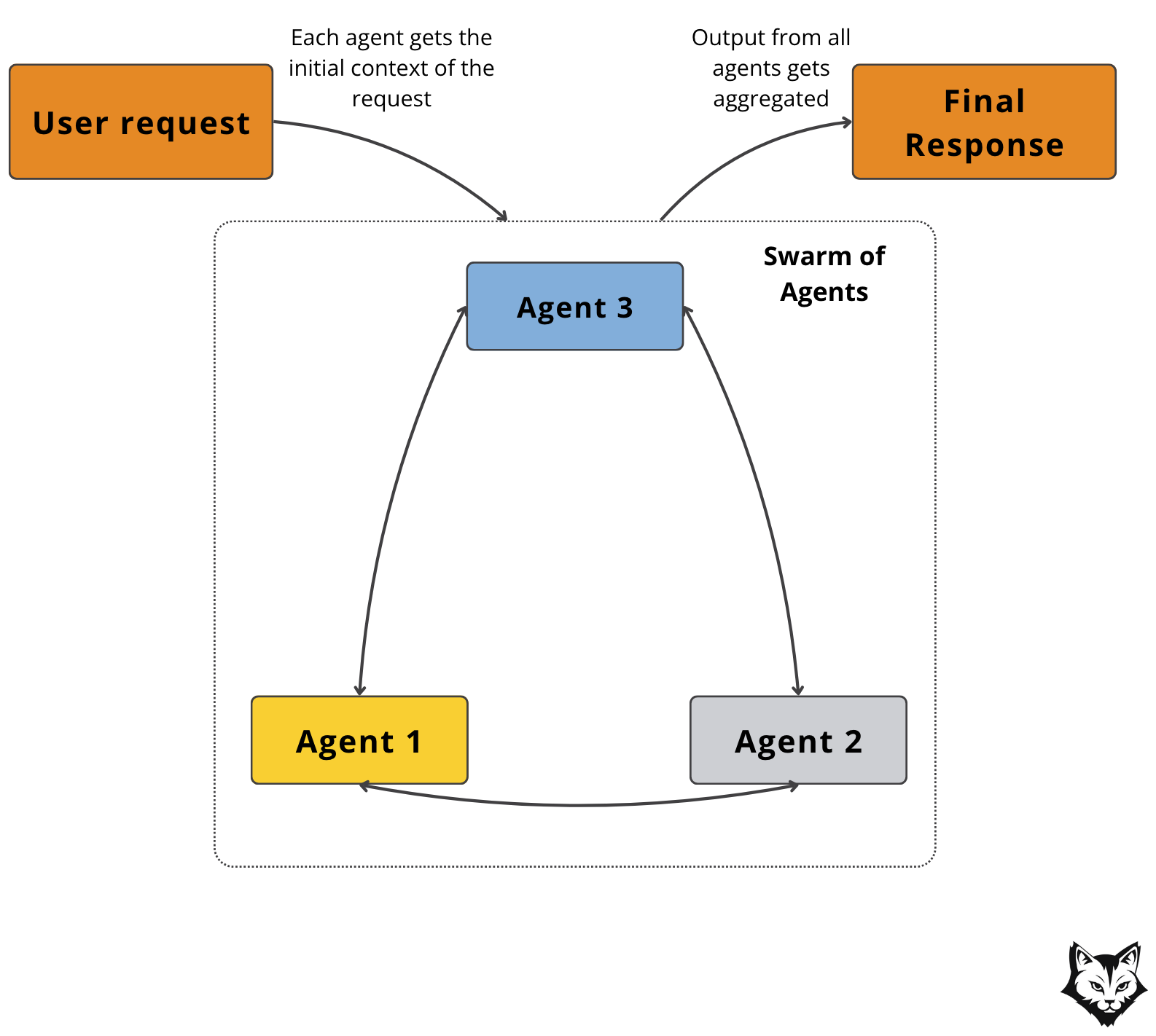
This Network of Agents pattern unfolds in four key stages:
Prepare Context (Deterministic): Collect the PR metadata, diffs, and any linked task data. Distribute the same base context to all agents.
Parallel Agent Runs: Each specialized agent executes its reasoning independently. For example, the Security Agent might run a static analysis, while the Style Agent checks formatting.
Aggregate Results: The system collects outputs from all agents and merges them into a coherent review.
Return / Deliver (Final Response): The combined review is sent to its destination (e.g., Slack).
Why it’s useful
Increases coverage: different aspects (security, style, requirements) are guaranteed to be checked.
Parallel execution can reduce total latency.
Easier to evolve: add or remove agents without disrupting others.
When to use it: When review requirements are broad and heterogeneous — you need multiple perspectives (style, security, requirements, compliance) and can’t rely on a single LLM to cover all domains reliably.
We can actually evolve our PR Reviewer implementation into a Network of Agents.
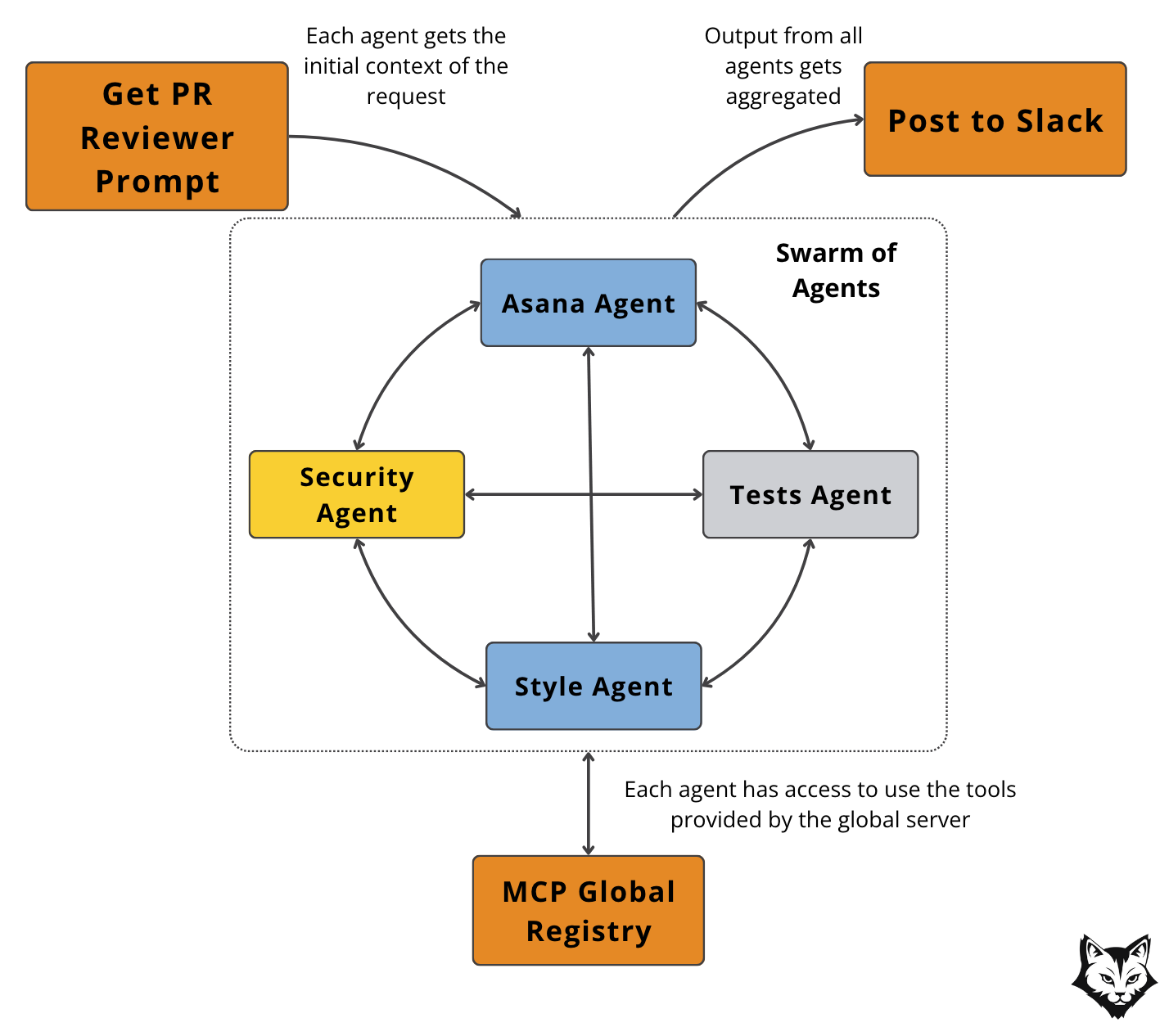
Each specialized agent handles its own piece of the review:
Security Agent runs a vulnerability scan over the diff.
Asana Agent pulls linked task context and checks whether requirements are satisfied.
Style Agent reviews code formatting and documentation consistency.
Tests Agent verifies whether test coverage is updated.
Note: The specialized prompts for each “role” don’t need to live inside the Host logic. We can store them in the Agent Scope Server, along with company guidelines or best practices. This keeps role definitions centralized, consistent, and reusable across patterns.
These agents don’t just work in isolation — they can also interact when their domains overlap.
For example, the Tests Agent might flag missing coverage, prompting the Security Agent to highlight risks in untested areas. The Asana Agent could notice a requirement for performance benchmarks, which then directs the Style or Security Agent to double-check specific aspects of the code.
The Supervisor Pattern
The Supervisor Pattern introduces a central controller agent that coordinates the work of multiple specialized agents.
Instead of every agent running in parallel, the Supervisor decides which agents to activate, in what order, and how their outputs should be combined. Think of it less like a review board and more like a project manager assigning tasks to team members.
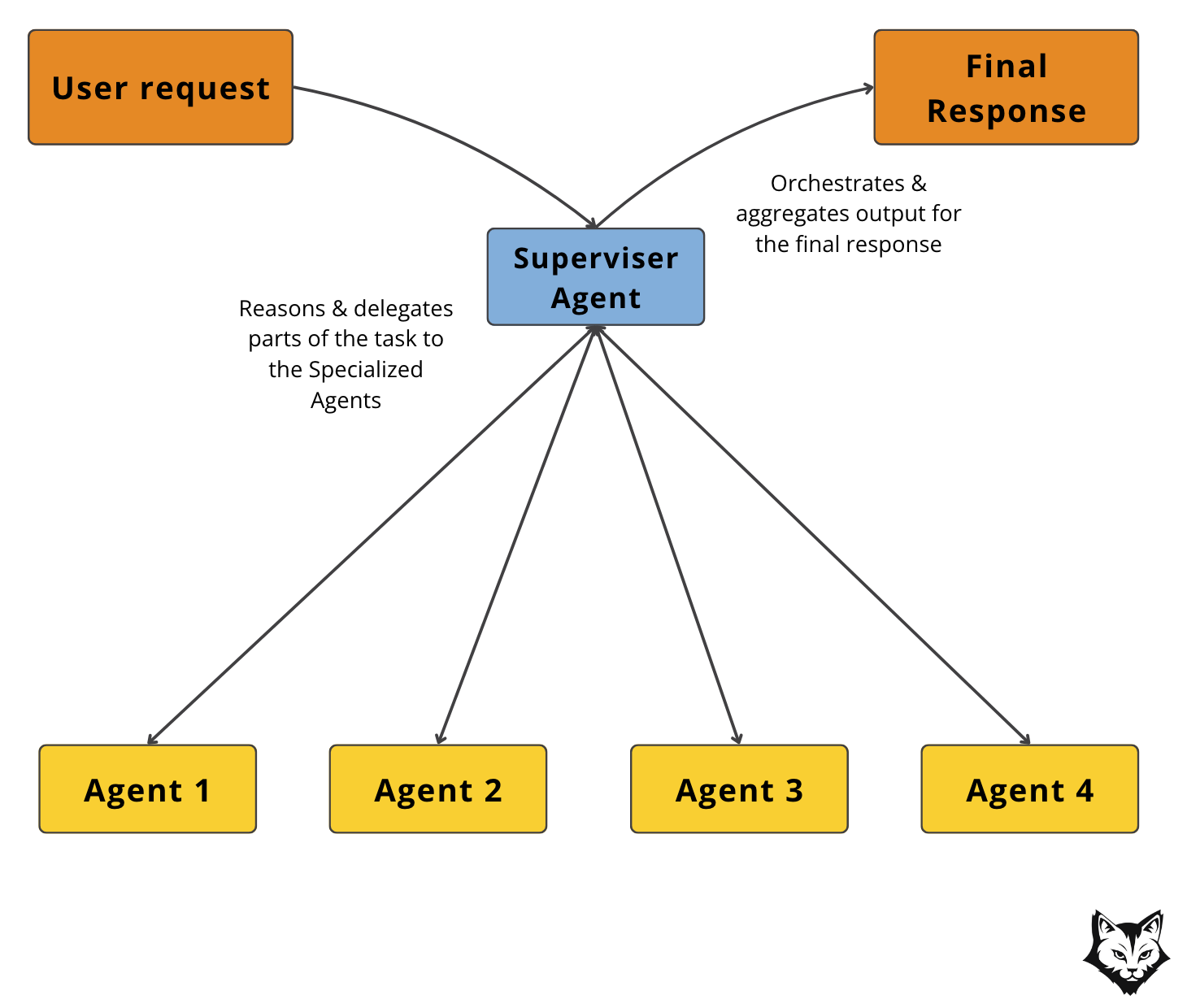
This pattern unfolds in four stages:
Supervisor Analysis (Agentic): The Supervisor inspects the PR context and determines which checks are needed. For example, it may decide a security review is necessary but skip style if no code formatting changes were detected.
Directed Agent Calls: Based on this plan, the Supervisor routes tasks to the relevant agents. Each specialized agent receives only the scope it’s responsible for.
Iterative Integration: The Supervisor evaluates agent outputs as they arrive and may refine the plan, asking for clarifications, or sending follow-up requests to specific agents.
Final Assembly: Once satisfied, the Supervisor merges the collected insights into a single, coherent review for delivery.
Why it’s useful
Controlled delegation: Instead of wasting cycles on irrelevant checks, only necessary agents are called.
Dynamic adaptation: The Supervisor can adjust the sequence depending on task complexity.
Better quality control: A single decision-maker ensures results are consistent before merging.
Distinction from Network of Agents: A Network of Agents has no single coordinator agent deciding who does what. Each agent runs independently in parallel, and their outputs are later merged. By contrast, a Supervisor pattern has a central model directing the others.
When to use it: When review needs differ widely across cases — e.g., one PR only needs a quick style check, another demands security, compliance, and requirements validation — and you want a central agent to coordinate which specialists are called instead of running everything every time.
Now let’s see how we can model our use case with this pattern.
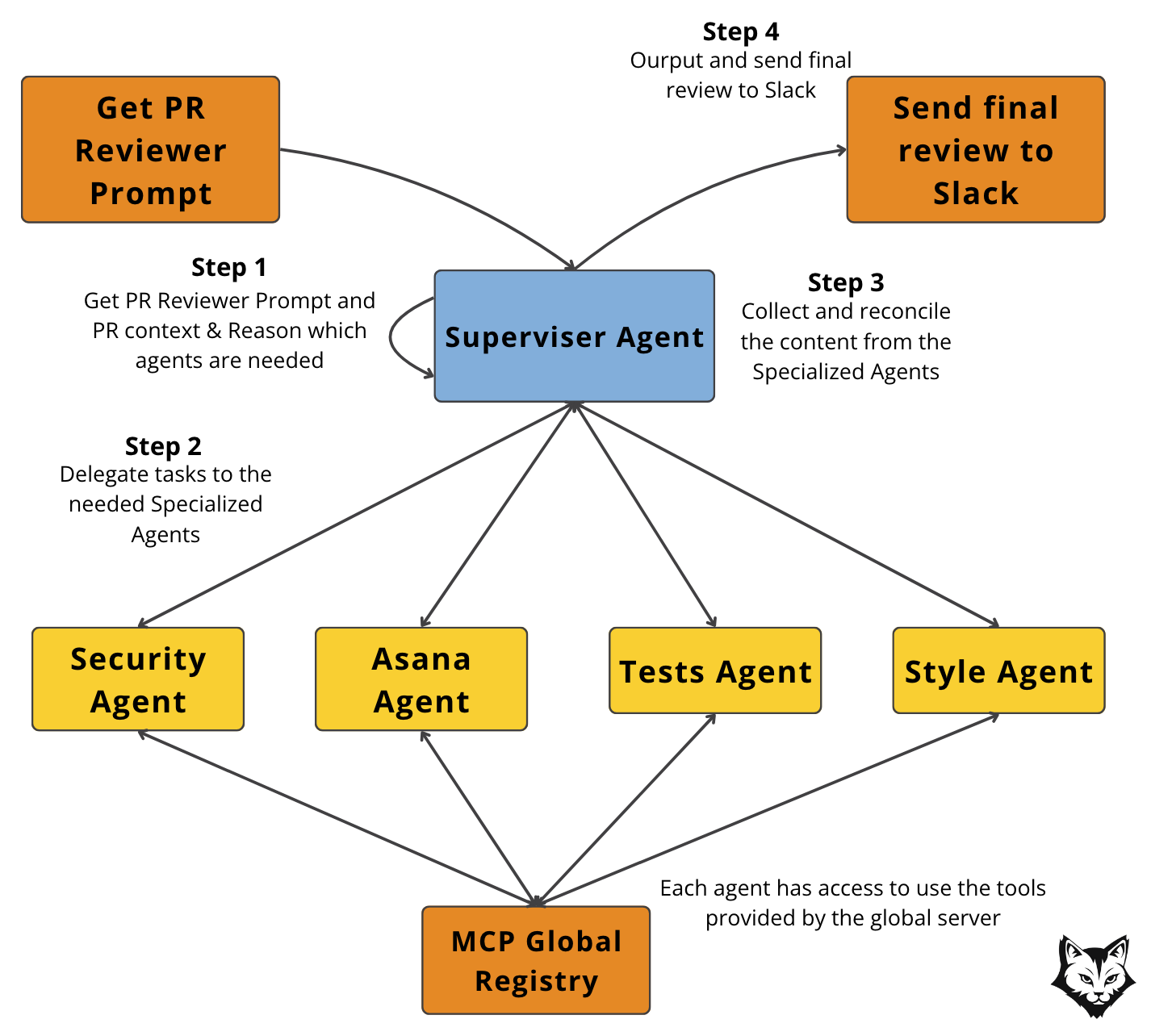
Step 1 — Inspect the PR
The Supervisor agent examines the pull request and determines which areas are relevant (security, style, documentation, testing, requirements, etc.).
Step 2 — Delegate to specialists
Based on its inspection, the Supervisor triggers the appropriate specialized agents.
Security-sensitive code → Security Agent
Documentation changes → Style Agent
Large or complex updates → Tests Agent and Asana Agent
Step 3 — Collect and reconcile
The Supervisor gathers the outputs from the active agents, resolves overlaps, and ensures consistency.
Step 4 — Return the unified review
A polished review is assembled and delivered to the target channel (e.g., Slack).
Note: Role-specific prompts and company guidelines live in the Agent Scope Server, so the Supervisor always works with consistent, reusable definitions.
The Hybrid Workflow Pattern (Semi-Workflow)
A Hybrid Workflow pattern combines the determinism of workflows with the flexibility of agentic reasoning.
In this setup, the system relies on deterministic, rule-based steps for tasks that are always the same (e.g., fetching inputs, formatting results, sending notifications). These steps run quickly and reliably, without needing model intervention.
Where uncertainty or nuance arises, the workflow hands control to the LLM, allowing it to interpret ambiguous signals, make context-dependent decisions, or generate nuanced outputs.
There isn’t really a template of steps for a semi-workflow, but what is essential is that the LLM directs control flow through predefined code paths.
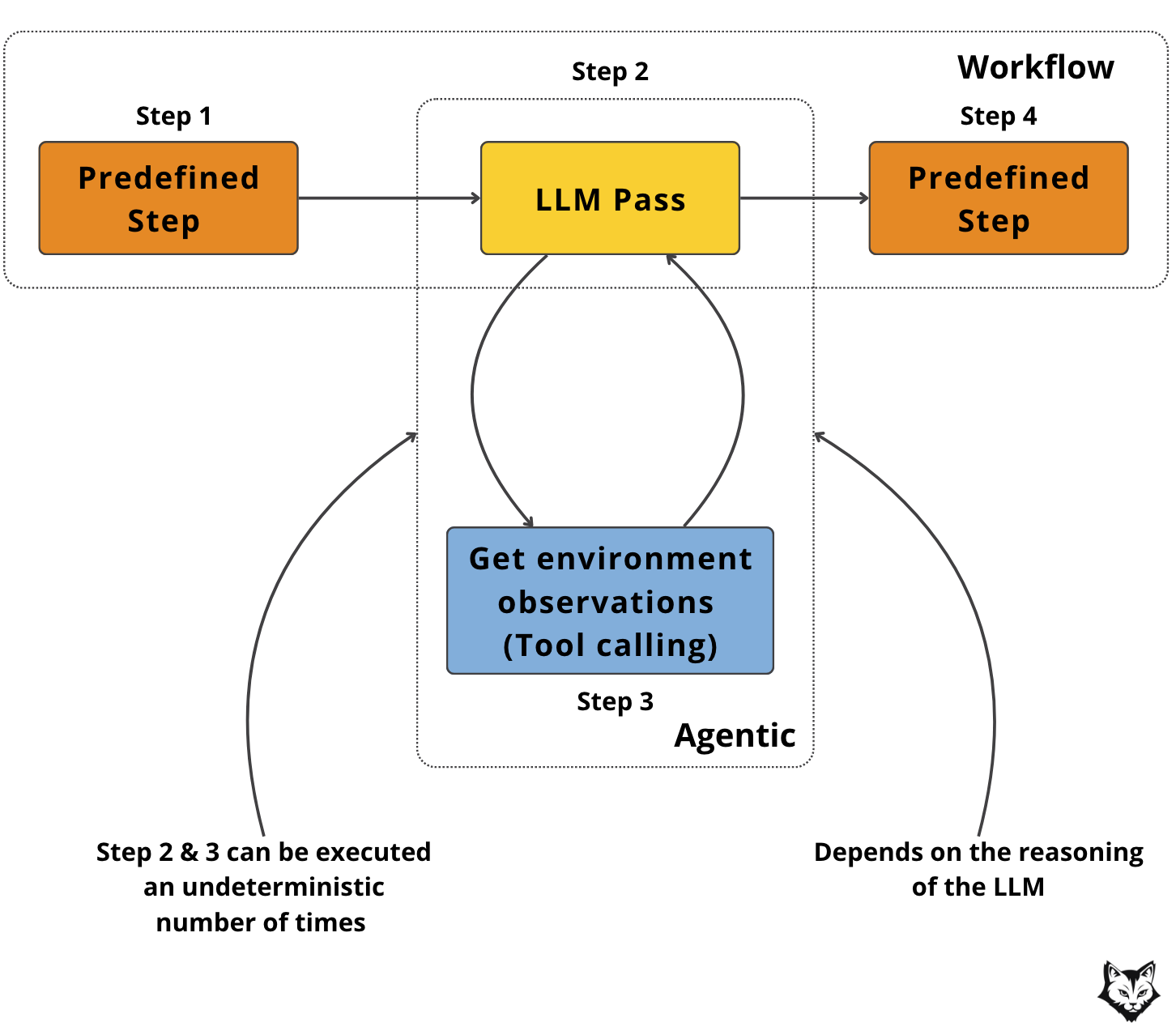
Why it’s useful
Balances efficiency with intelligence: saves tokens by limiting LLM calls.
Easy to debug since deterministic steps remain transparent.
Adaptable to enterprise environments where some steps are fixed by policy, but others need reasoning.
When to use it: When parts of the process are straightforward and always needed (e.g. fetching diffs, sending messages) but other parts require interpretation (e.g. task linkage, review text generation).
Note: this is how we modeled our PR Reviewer — deterministic steps like fetching the prompt and posting to Slack are fixed, while agentic reasoning is used only where ambiguity exists, such as checking if an Asana task is linked or inferring additional context from the available tools to produce a richer review.
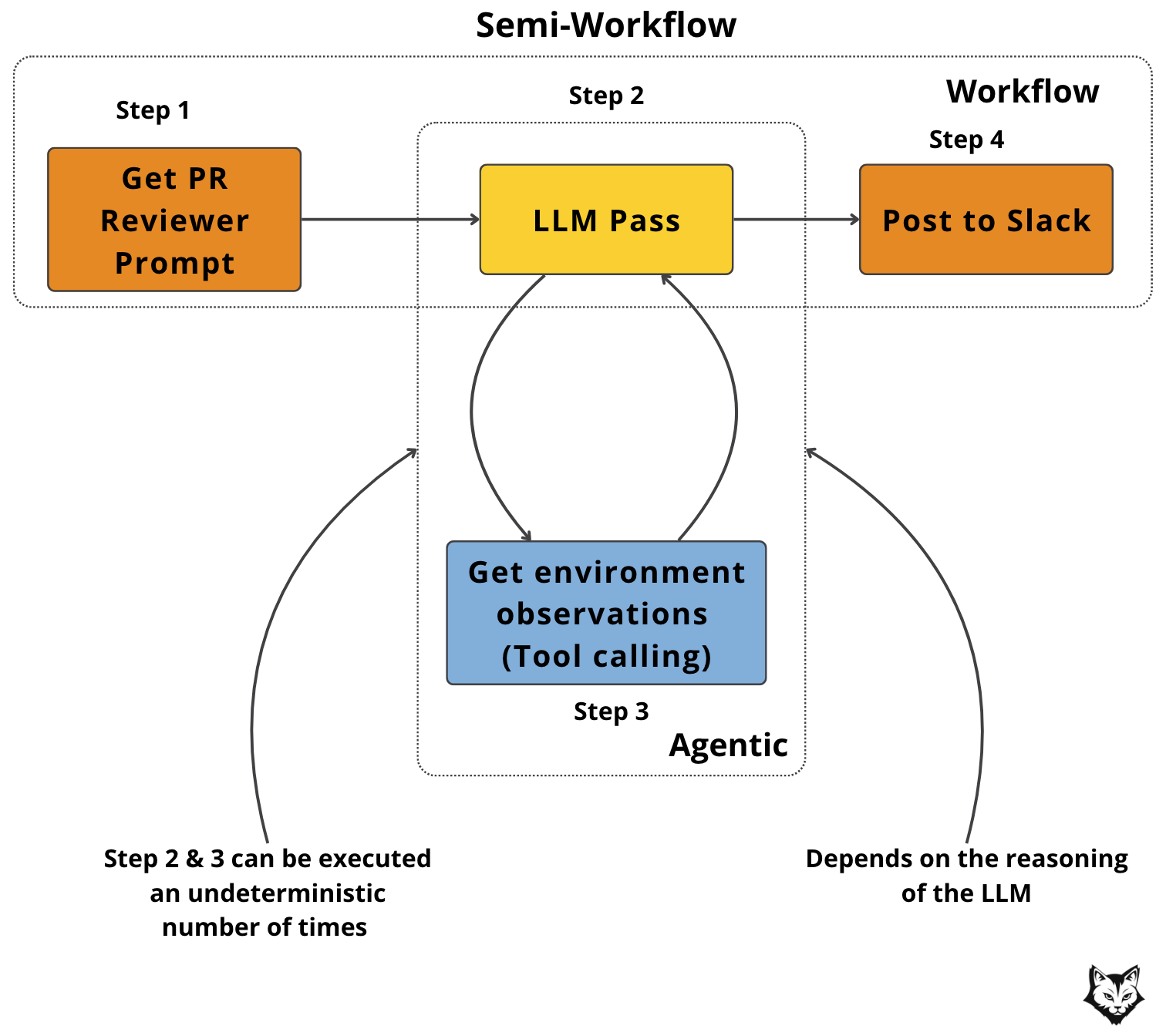
4. How to pick the right architecture
At this point, we’ve seen the spectrum: workflows, agents, hybrids, supervisors, swarms. But how do you know which one your system needs?
More agents don’t mean better results, but better questions do.
Here’s the decision lens I use.
1. Is the flow predictable or flexible?
If it always runs the same way (fetch → format → send), that’s a workflow. If the steps depend on context (“Only run security if this file changed”), bring in agent reasoning.
2. Do tools run every time, or only sometimes?
Always-on tools (Slack, logs) belong in the workflow. Conditional ones (Asana, JIRA, test runners) benefit from agent control.
3. Does quality need a double-check?
One-pass logic is fast. But if tone, coverage, or compliance matter, you’ll need reflection or a supervisor in the loop. It adds cost, but it saves bad reviews from slipping through.
4. How much latency can you afford?
Parallel networks of agents can move quickly, but a Supervisor who plans and checks each step adds seconds. In production, those seconds add up.
5. What’s your budget for tokens?
Every reasoning pass costs tokens. A workflow is dirt cheap. A ReAct loop with multiple tool calls can balloon cost. Ask: will quality gains justify the bill?
6. Who needs to debug this later?
If a teammate has to trace failures, workflows are transparent. Pure agent flows? Less so. Semi-workflows give you both: traceable structure with flexible branches.
The takeaway is simple.
Start with the simplest workflow that works. Add agentic reasoning only where ambiguity exists. Scale into multi-agent setups only when your use case truly demands it.
5. Applying the decision framework to our use case
Up to now, we have broken down patterns and trade-offs in isolation.
In this section, we bring everything together and show how the decision framework guides system design when the pieces are glued into a single flow.
We will do this with our running example, the PR Reviewer.
As mentioned earlier, the focus here is on redesigning the MCP Host of the PR Reviewer in an enterprise setting.
To make this concrete, let’s revise Figure 14. This diagram shows the PR Reviewer modeled with the five distinct agentic patterns we have explored so far.
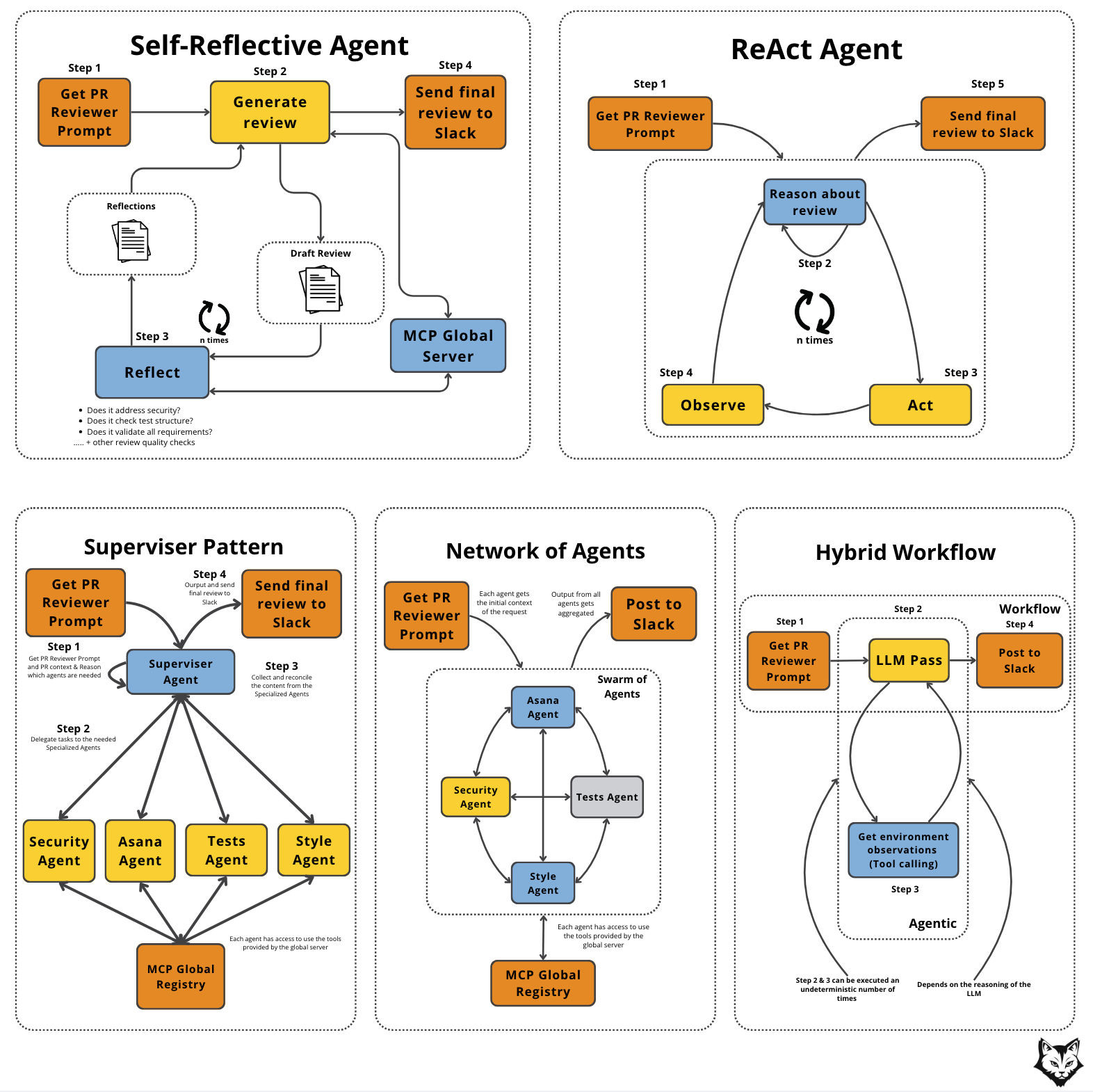
💡 With these options laid out, we can now turn to the decision flow presented in the previous section and examine how the framework helps us choose the right approach. ↓↓↓
Is the flow predictable or flexible?
Some parts are entirely predictable.
Every review needs the diff, and every review ends with posting the result to Slack. There’s no ambiguity there, so those belong in a workflow.
But other steps are context-dependent. Asana tasks, for example, don’t appear in every PR, and detecting them requires interpretation. That’s a flexible branch, where agent reasoning adds value.
Do tools run every time, or only sometimes?
Slack is always-on, so it stays in the workflow backbone.
Asana, JIRA, or other task tools only come into play when referenced in the PR. Those conditional calls are a natural fit for agent logic.
Does quality need a double-check?
A one-pass summary could work, but real enterprise reviews need judgment — tone checks, compliance, security coverage. That’s where a reflective pattern or even a supervisor layer can catch issues before they slip through.
The tradeoff is cost and latency, but in regulated or high-stakes environments, the extra passes are worth it.
How much latency can you afford?
For a small team with a handful of reviews per day, a second or two of delay won’t matter, and quality may trump speed.
For a large enterprise running thousands of reviews, latency and token bills add up fast. In that setting, semi-workflows strike the balance: workflows for the fixed backbone, agents only where ambiguity exists.
What’s your budget for tokens?
Every reasoning pass the model makes comes with a price tag.
A simple workflow is almost free. But a ReAct loop, with multiple tool calls and reasoning iterations, can balloon costs quickly at scale.
The question is whether those extra cycles deliver enough improvement in review quality to justify the bill. In lean enterprise setups, keeping token use predictable and capped often wins out over squeezing marginal gains from more reasoning.
Who needs to debug this later?
If a teammate needs to trace a failed review, workflows are transparent, while pure agent flows can feel like a black box.
Semi-workflows strike the balance: clear structure with flexible branches, making them ideal for enterprise systems where debugging and maintainability matter as much as output.
👉 Putting it all together, the PR Reviewer fits best as a hybrid.
The deterministic steps — fetching the diff, formatting outputs, posting to Slack — stay in a workflow. Agent reasoning handles ambiguity, like linking Asana tasks or interpreting nuanced review guidelines.
This setup is fast, cost-efficient, and reproducible, while leaving room to evolve toward a full ReAct or Supervisor model as enterprise needs expand.
Conclusion
We’ve gone from mapping out why architecture matters to testing each agent pattern against a real use case.
The PR Reviewer Assistant shows that structure is everything: the same tools and models behave completely differently depending on how you wire the logic.
The takeaway is simple: don’t reach for “agent everything.” Start with the simplest workflow that works, add reasoning only where ambiguity exists, and scale into more complex patterns only when the context truly demands it.
📚 If you haven’t seen our GitHub PR AI Reviewer implementation, start with Lesson 1 or check out the complete code.
Whenever you’re ready, there are 3 ways we can help you:
Perks: Exclusive discounts on our recommended learning resources
(books, live courses, self-paced courses and learning platforms).
The LLM Engineer’s Handbook: Our bestseller book on teaching you an end-to-end framework for building production-ready LLM and RAG applications, from data collection to deployment (get up to 20% off using our discount code).
Free open-source courses: Master production AI with our end-to-end open-source courses, which reflect real-world AI projects and cover everything from system architecture to data collection, training and deployment.
References
Decodingml. (n.d.). GitHub - decodingml/enterprise-mcp-series. GitHub. https://github.com/decodingml/enterprise-mcp-series
Neural-Maze. (n.d.). GitHub – agentic-patterns-course: Implementing the 4 agentic patterns from scratch. GitHub. https://github.com/neural-maze/agentic-patterns-course
Images
If not otherwise stated, all images are created by the author.
Love this lesson!
Thanks for the comprehensive design patterns and services to the same for the good 😊