

Why MCP Breaks Old Enterprise AI Architectures
Build from scratch an AI PR reviewer integrated with GitHub, Slack and Asana that scales within your organization.

The first lesson of the open-source course Designing Enterprise MCP Systems — a free course that will teach you how to architect and build AI-powered developer workflows that scale across teams and tools.
A 3-lesson journey, where you will learn how to:
Architect LLM applications with clean, modular MCP-based designs.
Build real-world developer experience automations, like an AI PR Reviewer Assistant.
Choose the right AI agent architecture for scale and adaptability.
Lessons:
Lesson 1: Why MCP Breaks Old Enterprise AI Architectures
Lesson 2: Build with MCP Like a Real Engineer
Lesson 3: Getting Agent Architecture Right
🔗 Learn more about the course and its outline.
Why MCP Breaks Old Enterprise AI Architectures
MCP is everywhere these days.
Scroll through any developer feed, and you’ll see tutorials on how to spin up an MCP server, plug it into your IDE, or connect it to Claude Desktop. It’s cool, it’s shiny, and it feels like the future.
But most tutorials stop at the basics. They show you how to connect one thing to another, but skip over why it’s worth your attention. The real beauty of MCP isn’t in the connection—it’s in how it changes the way you design automations at scale.
This piece isn’t another “how to build a server” guide. It’s about why you might want MCP at the base of your systems. By the end, you’ll know what MCP really brings to the table, and whether it’s worth starting with it on day one.
Most LLM projects start with a prompt or a hack. Ours starts with a use case and the solution architecture—and continues with a deep dive on how to implement it.
🔍 The use case? An assistant that reviews your pull requests before your teammates even get the chance. Fast, automated, and context-aware.
Think of it as the code reviewer who never ghosts your PR, never nitpicks semicolons, and actually reads the diff.
In these series, we’re building a production-ready PR reviewer assistant—an LLM-powered system that listens for GitHub pull requests, analyzes them, and posts review summaries directly to Slack. It’s a real use case, with real integrations and real constraints.
But what really matters is how we’re building it—with the Model Context Protocol (MCP), a standard that makes LLM systems modular, testable, and built to scale.
🧑💻 This is a hands-on walkthrough, not just theory. In this lesson, we break down the design decisions—and in the next, we dive into the code. (If you're eager, you can jump straight to the GitHub repo and follow along as you read.)
In this lesson, you’ll learn:
What MCP is and the problem it solves in real-world AI systems
How its core architecture of clients, hosts, and servers fits together
How to build a PR reviewer assistant and put MCP into action
When MCP is the right choice compared to traditional LLM setups
Table of contents:
What is MCP really? (and why should you care?)
Traditional agent setups vs MCP-based architecture
How MCP Works
Designing The PR Reviewer Assistant with MCP
Why This Scales (and Why You’ll Thank Yourself Later)
↓ But first, a quick word from our sponsors.
Learning Rust or Go with AI won’t cut it (Affiliate)
The truth is that using AI tools such as Cursor, Claude or ChatGPT to learn or code in new programming languages, such as Rust or Go, won’t help you. Most probably, it will confuse you.
Why? Because LLMs work best when the proper context is provided. When learning or coding in a new programming language, this translates to knowing what to ask for, such as how the code should be structured, how the function or classes should look, what paradigms to look for, and what specific features or syntax sugar to use.
For example, when using Python (using it for 10+ years) in Cursor, I rarely write any code because I know exactly what to ask for. However, when I switch to SQL or Rust, it often slows me down, putting me in a never-ending loop, which usually results in suboptimal solutions that are excessively complex.
This bugs me because this strategy never aligns with my north star. Simplicity.
That’s why, when picking up a new language, you still have to learn the basics the old way. And what’s the best way to learn coding? By building projects!
For that, I recommend CodeCrafters. A fantastic educational experience with the aim of building projects at heart.

For example, for their Rust track, you can start building something easier, such as your shell or grep command, to more complex apps such as replicating Kafka, git and Redis (totalling 314 exercises from very easy to hard).
They usually have the same projects in multiple languages, such as Go, Python or JavaScript.
I am recommending it because I am using it. I love how, on top of learning a new programming language, you also learn how to build the tools you love and use every day.
If you consider subscribing, use my affiliate link to support us and get 40% off on CodeCrafters.io:
↓ Now, back to our lesson. Let’s dive into what makes MCP stand out - and why it takes you from simply building with AI to actually engineering with it.
1. What is MCP really? (and why should you care?)
AI systems start simple, but they get messy fast. Add a few tools, connect some APIs, and suddenly you're dealing with brittle integrations and custom glue code everywhere.
Every framework, SDK, or service seems to define its own tool format, its own way of handling inputs and outputs, its own undocumented conventions. One expects OpenAPI-style schemas, another wants function signatures embedded in JSON, a third relies on hardcoded Python decorators with custom parsing logic.
Even calling two different tools that “do the same thing” can require completely different invocation logic.
The result? Nothing fits together.
You end up writing adapters on top of wrappers on top of hacks. Tools can’t be reused. Workflows become tightly coupled to specific implementations. Testing becomes a nightmare. Scaling or swapping components feels like performing surgery on spaghetti.
This fragmentation isn't just annoying—it’s the core bottleneck for building maintainable, extensible LLM systems.
That’s the problem the Model Context Protocol (MCP) is designed to solve.
MCP is a protocol , a formal standard for building modular, message-driven LLM systems. It’s not just a library or framework. It’s a way to architect AI software that doesn’t collapse under its own weight.
It defines how clients, hosts, and servers communicate, with clear roles and structured messages, so your workflows stay composable, testable, and scalable by default.
Think of it like HTTP:
The protocol defines how things should talk
The implementation is just how you choose to use it
Multiple systems can interact without writing custom integration code for each one
MCP doesn’t bring any new features.
What it brings is structure. It simply formalizes what we were already doing with tool-using agents in a form that scales like real software. It captures the patterns that emerged naturally as LLM systems matured and gives us a shared standard for building them.
So instead of reinventing that architecture for every project, MCP gives you a consistent, interoperable way to do it right, from day one.
If you want your AI workflows to scale, evolve, and stay sane, you need to think in protocols — not just prompts.
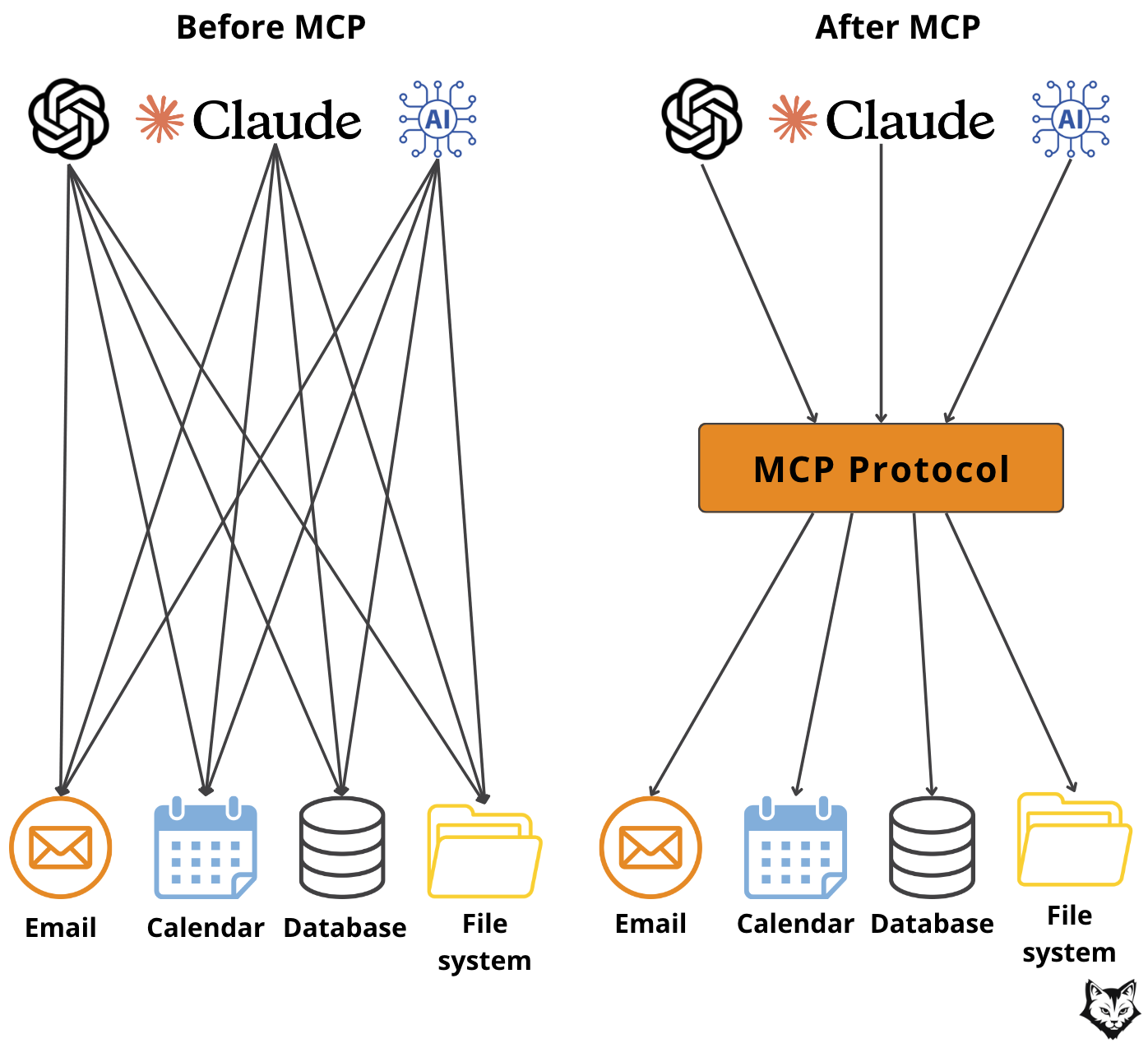
2. Traditional agent setups vs MCP-based architecture
Early agent builds are quick wins: wire in a few tools, get results, move on. But over time, those shortcuts turn into tangled code that’s hard to maintain or extend.
Think of it as inline, monolithic agents versus MCP, which enforces a clean separation of concerns. That difference in approach becomes clear when you look at how tools are integrated and managed.
The old way:
Tools are hardcoded into the agent loop (e.g., a
summarize_diff()call sitting inside the logic)No clear abstraction, so changes mean editing core code (hint: yep, the Open/Closed Principle we all nodded to in class!)
Scaling is painful, and reusing tools across different frameworks is nearly impossible
The MCP way:
Tools, resources and prompts sit on separate servers, decoupled from core logic
A standard interface keeps agents open for extension but closed for modification, letting you plug in multiple servers
The same interface makes tools reusable across frameworks, simplifying scaling and experimentation
This separation of concerns keeps your workflows clean, tools reusable, and systems easier to evolve as your needs change.
3. How MCP Works
So how does MCP actually pull this off?
It starts with a simple idea: every piece of the system has a clear job.
At its core, MCP uses a role-based architecture. Every component in an MCP-powered app plays one of three roles:
Host – the “agent brain.” It gathers context, decides which tools to use, and coordinates the workflow. Examples include a Python app, an IDE, or Claude Desktop.
Client – initiates tasks and talks directly to servers, keeping 1:1 connection with each MCP Server.
Server – exposes tools, resources, and prompts for the AI Applications to use.
Think of it like this: clients ask, hosts decide, servers deliver.
Now let’s zoom in on one of the most common things an MCP server does — tool calling — and see how these pieces interact together.
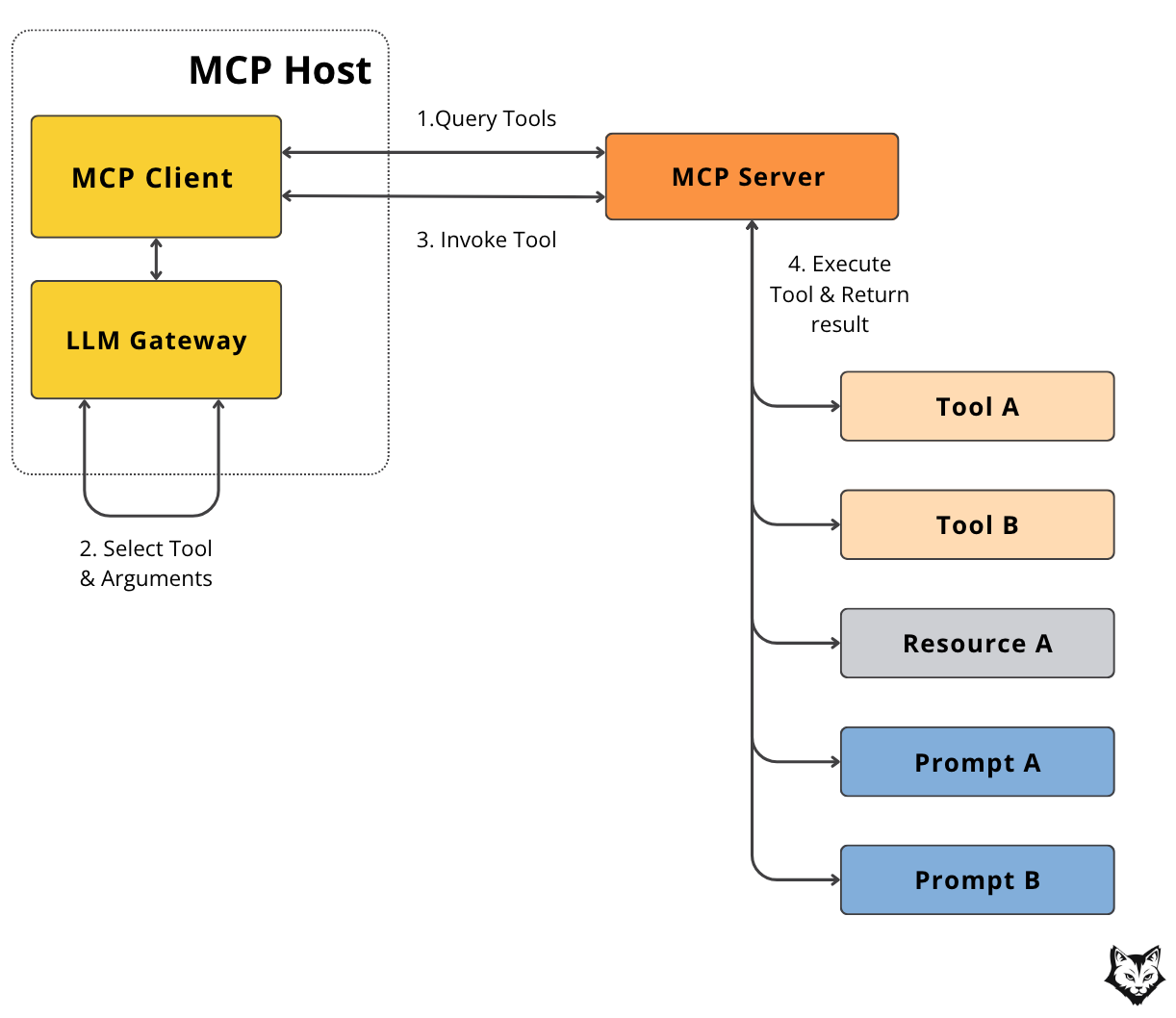
First, the MCP Client asks the MCP Server what tools are available.
Once the list comes back, the LLM Gateway (your agent logic) selects the right tool and fills in the arguments — for example, asking to run summarize_diff. The client then sends that request to the server.
The MCP Server executes the requested tool and sends the result back. The client passes it to the LLM, which uses it to continue the workflow and generate the final response.
Because MCP defines a common protocol, every server speaks the same “language”.
Your host and client don’t need to know how each server works internally. They simply send a request and get back a response in a standard format.
This means you can swap one server for another — maybe replace your PDF processor or change your GitHub integration — without touching the rest of your system.
You can also add new servers without rewriting your core logic, letting your system grow over time instead of getting stuck with one-off integrations.
To understand how this plays out in practice, let’s take a look at the full MCP architecture involving multiple servers:
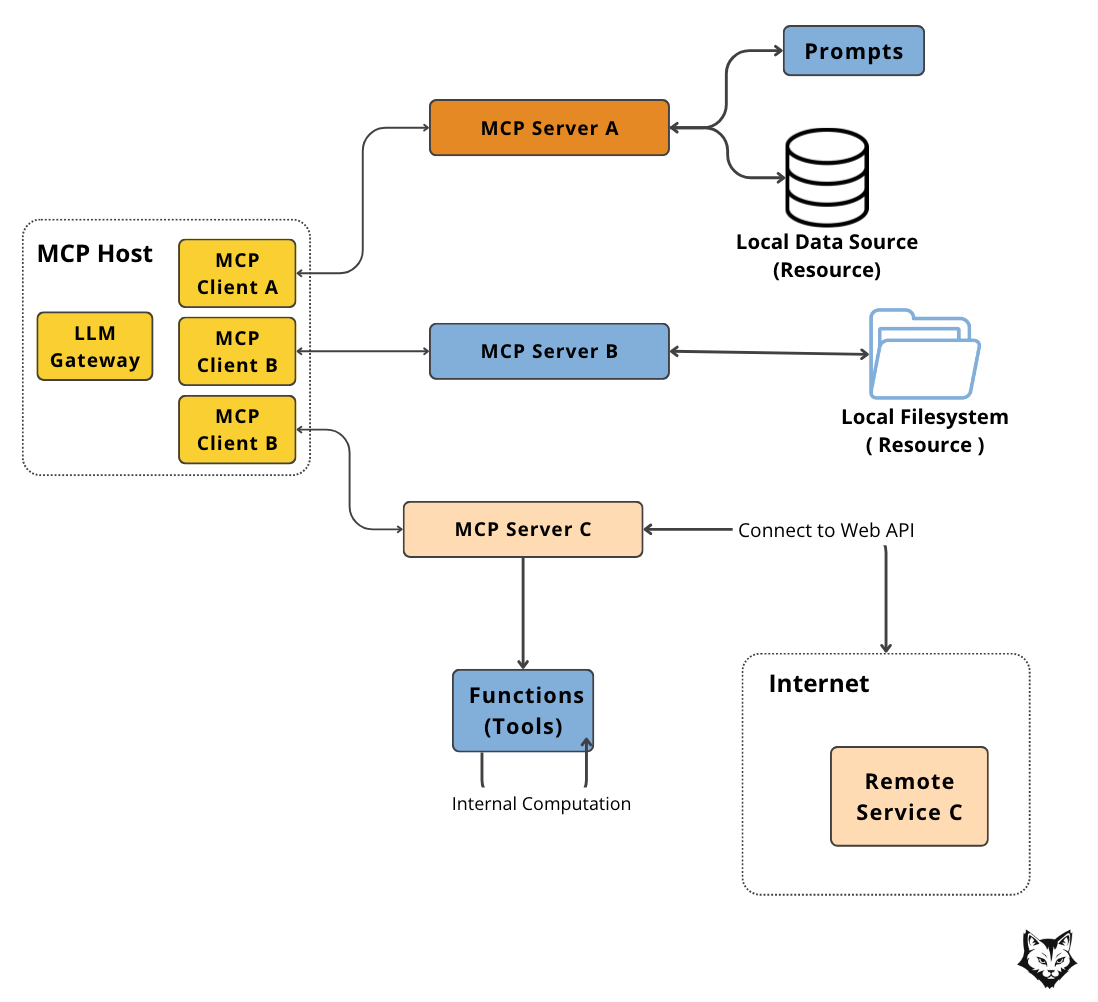
This diagram shows the MCP architecture in practice, where a single Host is hooked to multiple Servers across the system.
When you’re working with multiple servers, the overall flow stays familiar — but with one important change: the Host now needs to route each request to the server that owns the right tool for the job.
The Host still drives the process. It uses an LLM to reason about the task, then passes the request through its connected MCP Client to the appropriate server. Since each server exposes different tools, selecting the right one matters.
As we covered earlier, servers handle real functionality. They offer tools like summarize_diff, get_jira_issue, or extract_keywords, which the Host can call through standard MCP messages.
But tool execution is just part of the story. Let’s explore what else servers can provide.
What can servers provide?
Most articles oversimplify MCP servers as “just tools.”
That’s not true. Servers are much more than tool endpoints.
They can expose three types of things:
Tools – functions to call, like
send_slack_message,summarize_diff, orfetch_weatherResources – data to retrieve, such as files from a local file system or an internal database
Prompts – pre-defined templates or system messages that the client can fill and use for LLM calls
These servers act like modular building blocks, each focused on a single purpose but all speaking the same MCP “language.”
What protocol do they use?
MCP keeps things simple under the hood: it’s all built on JSON‑RPC.
This is a lightweight protocol commonly used in microservices for server-to-server communication, where everything is encoded as JSON and exchanged over a simple request-response format.
Check out a basic example of a JSON-RPC call to a tool named summarize_code:
{
"jsonrpc": "2.0",
"method": "summarize_code",
"params": {
"file_path": "src/utils/helpers.py"
},
"id": 1
}This standard defines how clients and servers exchange messages, but it doesn’t lock you into a single transport. You can choose the one that best fits your environment:
stdio (great for development)
The client spawns the server as a subprocess and communicates over
stdin/stdoutFast and synchronous
Perfect for running servers as Python modules or quick local testing
Streamed HTTP (production‑ready)
Allows servers to respond with standard HTTP responses or streaming data on demand
Supports optional session IDs for state management and recovery
Flexible enough for anything from serverless functions to full-scale AI applications
Replaces the older HTTP + SSE approach with better reliability and session recovery
🔗 Learn more about the protocol in the MCP transport specification
How can we secure them?
Now that we know they provide the actual data … how do we secure them?
When you expose an MCP server to the outside world, you’re effectively opening a door into your system.
If someone gets unauthorized access, they could:
Trigger tools they shouldn’t have access to (think deploying code or deleting files)
Pull sensitive data from resources
Abuse prompts for unintended automation
This isn’t theoretical — any open endpoint can be a target, and MCP servers are no different.
The go‑to: OAuth 2.0
The most common way to secure these servers is OAuth 2.0. Instead of handing out one static token that works for everyone (and everything), OAuth issues scoped, time‑limited tokens tied to specific users or systems.
That means:
Each user or client authenticates and gets a unique token.
Tokens can expire or be revoked, limiting long‑term risk.
Access can be scoped so one user might only read data while another can run administrative tools.
This is why OAuth 2.0 is the standard for production MCP deployments — it’s battle‑tested, flexible, and integrates with many identity providers.
🔐 Want to go deeper? Check out this guide on securing MCP servers with OAuth 2.0 for real-world tips and best practices.
To visualize how this works, here’s what a typical OAuth 2.0 flow looks like between an MCP Host and a remote MCP Server:
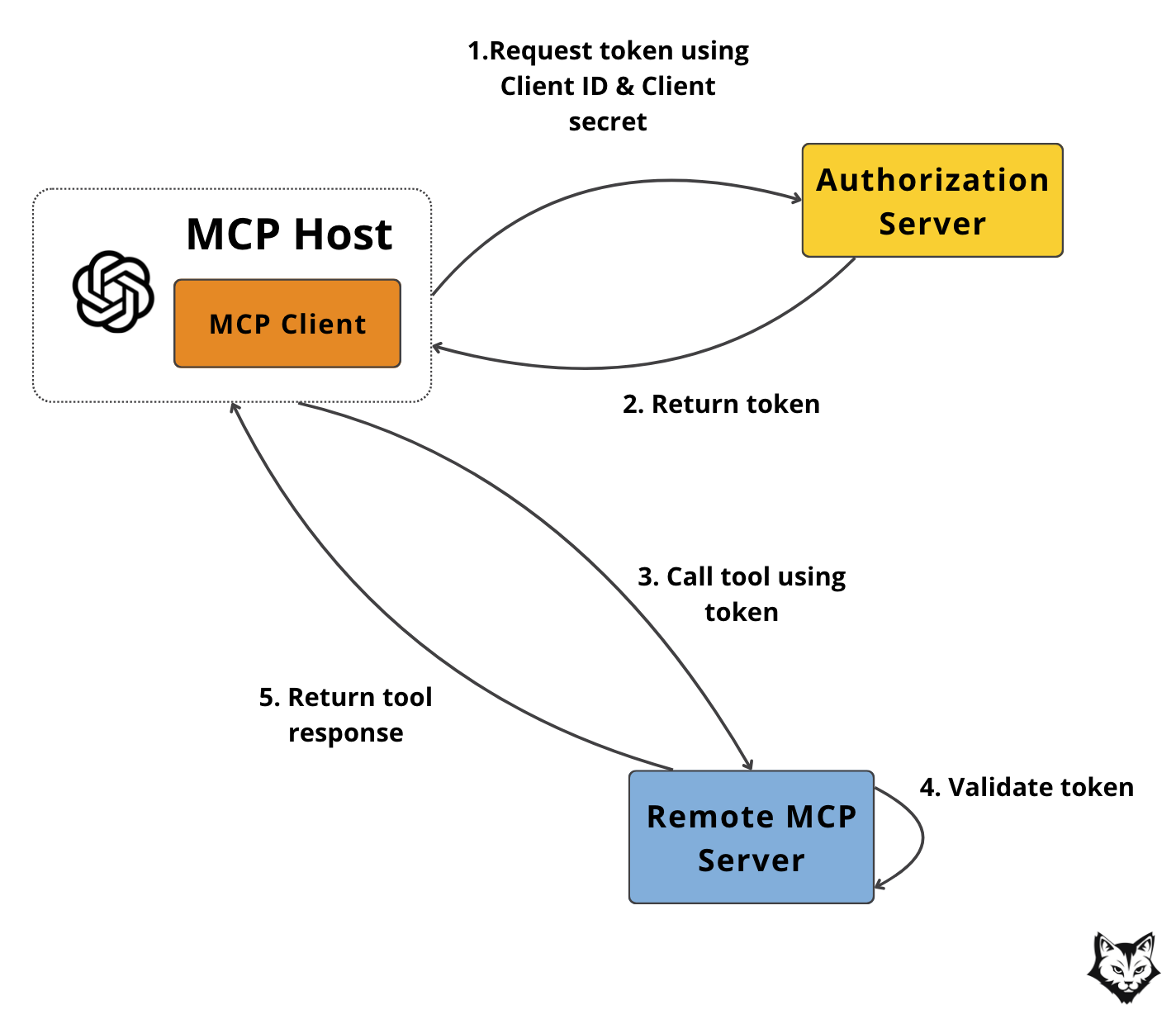
Let’s briefly go through each step in the diagram:
The MCP Host authenticates with the Authorization Server using its
client_idandclient_secret.It receives a scoped access token—not a catch-all credential, but one limited to only what this host is allowed to do (e.g., call specific tools, not all tools).
The MCP Host sends a request to the Remote MCP Server, including the token in the
Authorizationheader.The MCP Server validates the token.
If valid and authorized, the server executes the requested tool and returns the result.
This setup ensures fine-grained access control and keeps your system secure.
4. Designing The PR Reviewer Assistant with MCP
Now let’s break down a real use case to make the mental model stick.
Imagine you want an AI teammate that reviews pull requests the moment they’re opened — and delivers feedback to your team without you lifting a finger. No waiting on busy reviewers, no half-finished feedback, and no hunting through Asana tickets for missing context.
We’ve all been there — the reviewer staring at a thousand-line diff wondering where to start, while the reviewee refreshes the page like it’s a flight status update.
So, how would you actually design something like this?
The diagram below shows one way to wire it up using MCP:
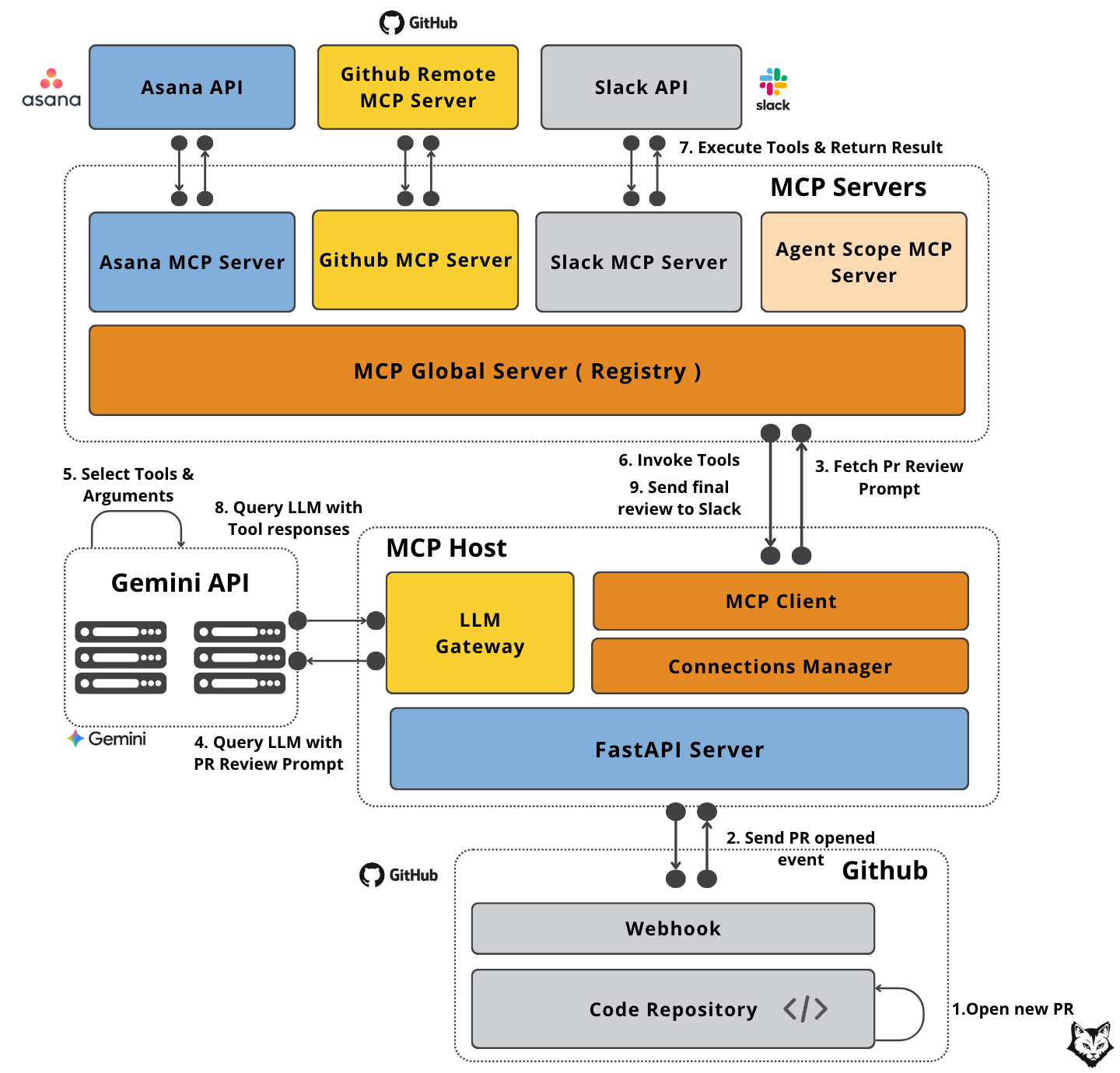
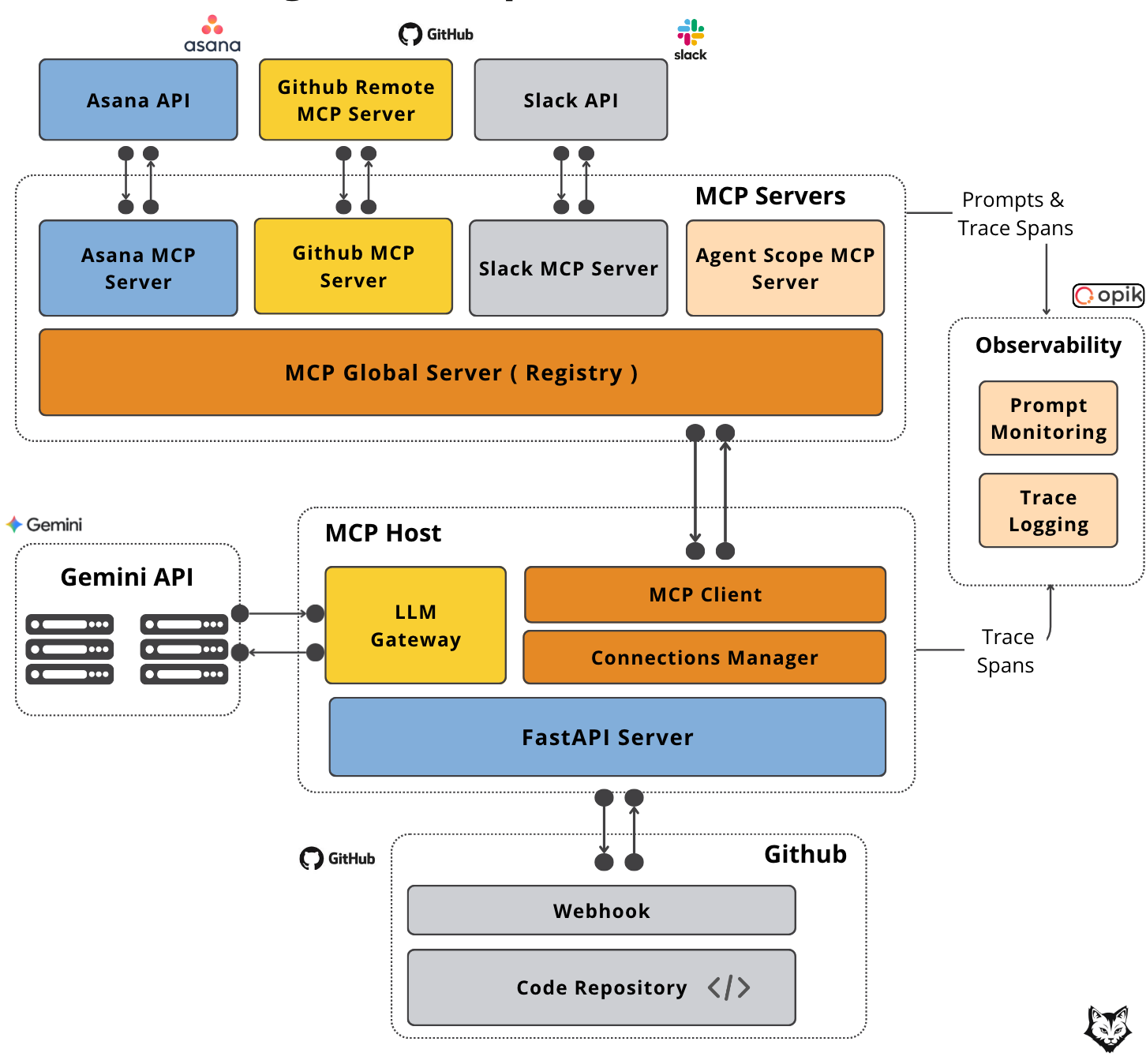
In our use case, the MCP Host is a FastAPI app powered by a Gemini LLM, wired into your GitHub repo through a webhook. It’s the component that reacts the instant a PR appears and decides exactly what should happen next.
The host runs a single MCP Client connected to the MCP Global Server, which keeps every MCP server in one place. It organizes tools, prompts and resources, tags them, and makes it easy to find exactly what you need without going through scattered configs.
For this setup, four MCP servers handle the heavy lifting — each with a specific job:
GitHub MCP Server – The primary source for PR context. It pulls metadata, file changes, and code diffs so the review has the full picture of what’s being proposed.
Asana MCP Server – Provides the task-level context behind the PR. It surfaces linked tasks and requirements so you can tell whether the changes actually deliver what was promised.
Agent Scope MCP Server – The starting point for the review logic. This is where the host retrieves the initial PR review prompt from, ensuring the LLM knows exactly how to frame and approach the evaluation.
Slack MCP Server – Handles the final step of delivery. It posts the completed review into the right Slack channel, ensuring the feedback is instantly visible where the team already communicates.
Now that we understand each component, let’s walk through the flow:
A developer opens a pull request in GitHub.
GitHub fires a PR
openedevent to our FastAPI host with all the PR metadata.The host asks the Agent Scope MCP Server (via the Global Server) for the right PR review prompt.
The host sends the PR data and prompt to Gemini, asking which tools to run.
Gemini returns a plan — e.g., fetch PR content, grab linked tasks.
The host calls the Global MCP Server to invoke the required tools and gather the needed data.
Each MCP server talks to its external API, executes the job, and sends the results back.
The host sends those results to Gemini to create the final review.
The review goes to the Slack MCP Server, which posts it directly to the team.
Note: In some cases, Gemini may request additional tool calls in a subsequent pass, meaning steps 5–9 can loop until all required data is gathered and the review is complete.
And just like that, your PR is reviewed, contextualized, and shared — before you’ve even switched tabs.
5. Why This Scales (and Why You’ll Thank Yourself Later)
MCP isn’t just clean architecture — it’s a future-proof way to build AI systems that won’t collapse under their own complexity.
This scales because every component follows the same protocol. Adding a new capability doesn’t mean rewriting everything else — it’s simply a matter of plugging in another piece.
Instead of a single, heavy system that grows harder to maintain, you’re building small, independent units that fit together naturally.
Now picture this.
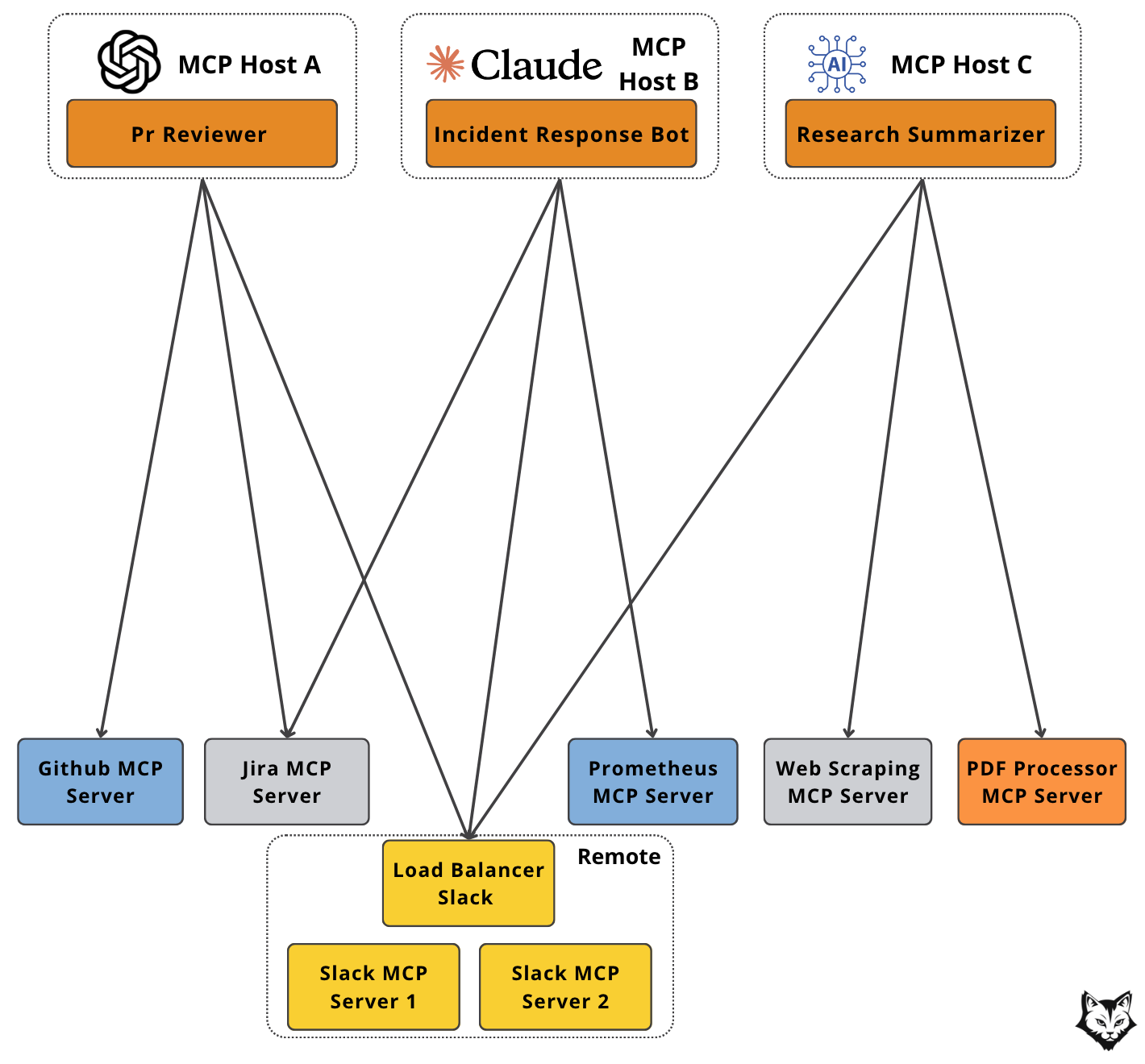
Say your enterprise wants three developer-experience automations: a PR reviewer, an incident response bot, and a research summarizer. In most setups, each would need its own integrations with GitHub, Slack, Jira, and other services.
With MCP, they all connect to the same set of shared servers. If one service gets a lot of traffic — like Slack — you can simply spin up another server of the same type to handle the load. And the same GitHub or Jira server can be reused across all AI applications, no matter how many you add.
All of this means you get some very real perks.
Reusability. You can swap Claude for OpenAI or Gemini without touching the rest of your workflow. The same Slack server you built for one project? You can reuse it across ten others. Need to support multiple products? Just plug in a different map server for each one — no glue code, no duplication.
Reliability. Because everything runs through a standard interface, every step is traceable. You can see which server ran what tool, with what inputs and outputs. And since servers are stateless and mockable, writing tests becomes straightforward. No more faking end-to-end flows just to check if a tool works.
Scalability. And when you’re ready to scale — really scale — you’re not locked into one machine or repo. Servers can live on separate machines, in different teams, even across org boundaries. It’s distributed by design.
Cost efficiency. Shared servers mean you’re not rebuilding the same integrations repeatedly. You save on engineering time, reduce infrastructure costs, and can move workloads to cheaper environments without disruption.
MCP brings a microservices mindset to AI development.
It turns your LLM workflows into composable infrastructure — not just clever wrappers around chat models.
Conclusion
So we’ve gone from “MCP is a buzzword” to “I know how to architect my next AI system with MCP.”
Theory time is over — now it’s time to make it real.
In the next lesson, we’ll walk through the full implementation from start to finish — spinning up the servers, linking them through the host, and watching the PR Reviewer Assistant run its first complete review like it’s always been part of the team.
Already curious? Check out the full codebase here:
📖 Or continue reading with lesson 2 from the series. Enjoy!
Whenever you’re ready, there are 3 ways we can help you:
Perks: Exclusive discounts on our recommended learning resources
(books, live courses, self-paced courses and learning platforms).
The LLM Engineer’s Handbook: Our bestseller book on teaching you an end-to-end framework for building production-ready LLM and RAG applications, from data collection to deployment (get up to 20% off using our discount code).
Free open-source courses: Master production AI with our end-to-end open-source courses, which reflect real-world AI projects and cover everything from system architecture to data collection, training and deployment.
References
Decodingml. (n.d.). GitHub - decodingml/enterprise-mcp-series. GitHub. https://github.com/decodingml/enterprise-mcp-series
Model Context Protocol. (n.d.). Official website. Model Context Protocol. https://modelcontextprotocol.io/
Model Context Protocol. (2025, June 18). Basic transports specification. Model Context Protocol. https://modelcontextprotocol.io/specification/2025-06-18/basic/transports
Infracloud. (n.d.). Securing MCP servers with OAuth 2.0. Infracloud Blog. https://www.infracloud.io/blogs/securing-mcp-servers/
Images
If not otherwise stated, all images are created by the author.
Finally a true engineer perspective. I thought I’m loosing my mind. No - actually majority of info on the web has low quality. But this one is great
This is great! Looking forward to next lessons 🚀