

How to evaluate your RAG using RAGAs Framework
Evaluate your RAG, following the best industry practices using the RAGAs framework. Learn about Retrieval & Generation specific metrics and advanced RAG chain monitoring using CometML LLM

→ the 10th out of 11 lessons of the LLM Twin free course
What is your LLM Twin? It is an AI character that writes like yourself by incorporating your style, personality, and voice into an LLM.

Why is this course different?
By finishing the “LLM Twin: Building Your Production-Ready AI Replica” free course, you will learn how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices.
Why should you care? 🫵
→ No more isolated scripts or Notebooks! Learn production ML by building and deploying an end-to-end production-grade LLM system.
More details on what you will learn within the LLM Twin course, here 👈
Latest Lessons of the LLM Twin Course
Lesson 7: How to fine-tune LLMs on custom datasets at Scale using Qwak and CometML
→ QLoRA, PEFT, Fine-tuning Mistral-7b-Instruct on custom dataset, Qwak, Comet ML
Lesson 8: Best practices when evaluating fine-tuned LLM models
→ Quantitative/Qualitative Evaluation Metrics, Human-in-the-Loop, LLM-Eval
Lesson 9: Architect scalable and cost-effective LLM & RAG inference pipelines
→Monolithic vs. microservice, Qwak Deployment, RAG Pipeline Walkthrough
Lesson 10: How to evaluate your RAG using RAGAs Framework
In Lesson 10 we’ll focus on the RAG evaluation stage, using one of the best frameworks available for this task - RAGAs. We’ll showcase the step-by-step workflow, explain the metrics used, and exemplify advanced Comet ML LLM RAG observability techniques.
Here’s what we’re going to learn in this lesson:
Evaluation techniques for RAG applications.
How to use RAGAs to evaluate RAG applications.
How to build metadata chains and log them to CometML-LLM.
The LLM-Twin RAG evaluation workflow.
Table of Contents:
What is RAG evaluation?
The RAGAs Framework
Advanced Prompt-Chain Monitoring
Conclusion
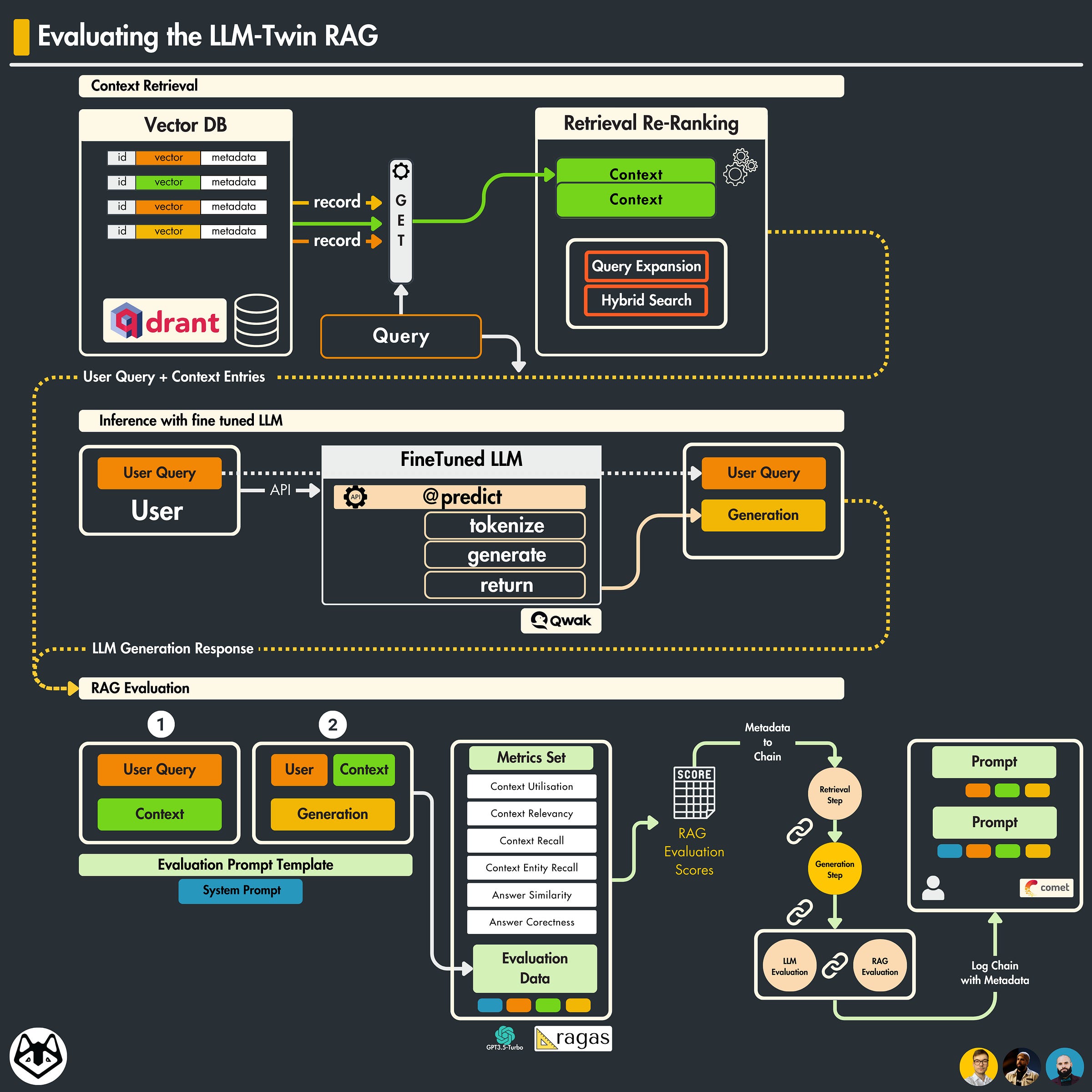
1. What is RAG evaluation?
RAG evaluation involves assessing how well the model integrates retrieved information into its responses. This requires evaluating not just the quality of the generated text, but also the accuracy and relevance of the retrieved information, and how effectively it enhances the final output.
Building an RAG pipeline is fairly simple. You just need a Vector-DB knowledge base, an LLM to process your prompts, and additional logic for interactions between these modules.
Reaching a satisfying performance level for a RAG pipeline imposes its challenges because of the “separate” components:
Retriever — which takes care of querying the Knowledge Database and retrieves additional context that matches the user’s query.
Generator — which encompasses the LLM module, generating an answer based on the context-augmented prompt.
When evaluating a RAG pipeline, we must evaluate both components separately and together to understand if and where the RAG pipeline still needs improvement, this will help us identify its “quality”.
Additionally, to understand whether its performance is improving, we need to evaluate it quantitatively.
RAG evaluation involves assessing how well the model integrates retrieved information into its responses. This requires evaluating not just the quality of the generated text, but also the accuracy and relevance of the retrieved information, and how effectively it enhances the final output.
2. The RAGAs Framework
Ragas is a framework that helps you evaluate your Retrieval Augmented Generation (RAG) pipelines. There are existing tools and frameworks that help you build these pipelines, (e.g. LLamaIndex), but evaluating it and quantifying your pipeline performance can be hard.
This is where Ragas (RAG Assessment) comes in.
The RAGAs framework (5.3k ⭐️) is open-source, part of explodinggradients group, and it comes with a paper submission: RAGAs Paper.
RAGAs Metrics
Faithfulness
Measures how accurately the generated answer reflects the source content, ensuring the generated content is truthful and reliable.Answer Relevance
Assesses how pertinent the answer is to the given question.Validating that the response directly addresses the user’s query.Context Precision
Evaluates the precision of the context used to generate an answer, ensuring relevant information is selected from the context.Context Relevancy
Measures how relevant the selected context is to the question. Helps improve context selection to enhance answer accuracy.Context Recall
Assesses the extent to which relevant context information is retrieved, ensuring that no critical context is missed.Context Entities Recall
Evaluates the recall of entities within the context, ensuring that no important entities are overlooked in context retrieval.Answer Semantic Similarity
Quantifies the semantic similarity between the generated answer and the expected “ideal” answer. Shows that the generated content is semantically aligned with expected responses.Answer Correctness
Focuses on fact-checking, assessing the factual accuracy of the generated answer.
RAGAs Evaluation Format
To evaluate the RAG pipeline, RAGAs expects the following dataset format:
[question] : The user query, this is the input to our RAG.
[answer] : The generated answer from the RAG pipeline
[contexts] : Context retrieved from the the VectorDB
[ground_truths] : The ground truth answer to the question.
[Note] : The `ground_truths` is necessary only if the ContextRecall metric is used.To exemplify it shortly, here’s an example:
from datasets import Dataset
questions= ["When was the Eiffel Tower built and how tall is it?"],
answers= ["As of my last update in April 2023, the Eiffel Tower was built in 1889 and is 324m tall"]
contexts= [
"The Eiffel Tower is one of the most attractive monuments to visit when in Paris, France. It was constructed in 1889 as the entrance arch to the 1889 World's Fair. It stands at 324 meters tall."
]
ground_truths=[
["The Eiffel Tower was built in 1889 and it stands at 324 meters tall."]
]
sample = {
"question": questions,
"answer": answers,
"contexts": contexts,
"ground_truths": ground_truths
}
eval_dataset = Dataset.from_dict(sample)And, here’s how the dataset object looks like:
#> print(eval_dataset)
Dataset({
features: ['question', 'answer', 'contexts', 'ground_truths'],
num_rows: 1
})Now that we’ve gone over the prerequisites necessary to work with RAGAs, let’s see the framework applied to our LLM-Twin RAG evaluation use case.
How do we evaluate our RAG Application?
To evaluate our RAG application, we’re going to use this workflow:
Defining the Evaluation Prompt Template
Define the user query
Retrieve context from our Vector Database, related to our user query
Format the prompt and pass it to our LLM model.
Capture the answer, and use query/context to prepare the evaluation data samples
Evaluate with RAGAs
Construct the evaluation Chain, append metadata, and log to CometML

Let’s go over the evaluation method implementation:
if enable_evaluation is True:
if enable_rag:
st_time = time.time_ns()
rag_eval_scores = evaluate_w_ragas(
query=query, output=answer, context=context
)
en_time = time.time_ns()
self._timings["evaluation_rag"] = (en_time - st_time) / 1e9
st_time = time.time_ns()
llm_eval = evaluate_llm(query=query, output=answer)
en_time = time.time_ns()
self._timings["evaluation_llm"] = (en_time - st_time) / 1e9
evaluation_result = {
"llm_evaluation": "" if not llm_eval else llm_eval,
"rag_evaluation": {} if not rag_eval_scores else rag_eval_scores,
}
else:
evaluation_result = NoneKey insights from this implementation:
We’re applying the LLM evaluation stage described in Lesson8, to evaluate
(query,response)pairs.We’re applying the RAG evaluation stage to evaluate
(query,response,context)pairs.We use a
_timingsdictionary to track the execution duration for performance profiling purposes.
Within the evaluate_w_ragas method, we have:
from ragas.metrics import (
answer_correctness,
answer_similarity,
context_entity_recall,
context_recall,
context_relevancy,
context_utilization,
)
METRICS = [
context_utilization,
context_relevancy,
context_recall,
answer_similarity,
context_entity_recall,
answer_correctness,
]
def evaluate_w_ragas(query: str, context: list[str], output: str) -> DataFrame:
"""
Evaluate the RAG (query,context,response) using RAGAS
"""
data_sample = {
"question": [query], # Question as Sequence(str)
"answer": [output], # Answer as Sequence(str)
"contexts": [context], # Context as Sequence(str)
"ground_truth": [context], # Ground Truth as Sequence(str)
}
oai_model = ChatOpenAI(
model=settings.OPENAI_MODEL_ID,
api_key=settings.OPENAI_API_KEY,
)
embd_model = HuggingfaceEmbeddings(model=settings.EMBEDDING_MODEL_ID)
dataset = Dataset.from_dict(data_sample)
score = evaluate(
llm=oai_model,
embeddings=embd_model,
dataset=dataset,
metrics=METRICS,
)
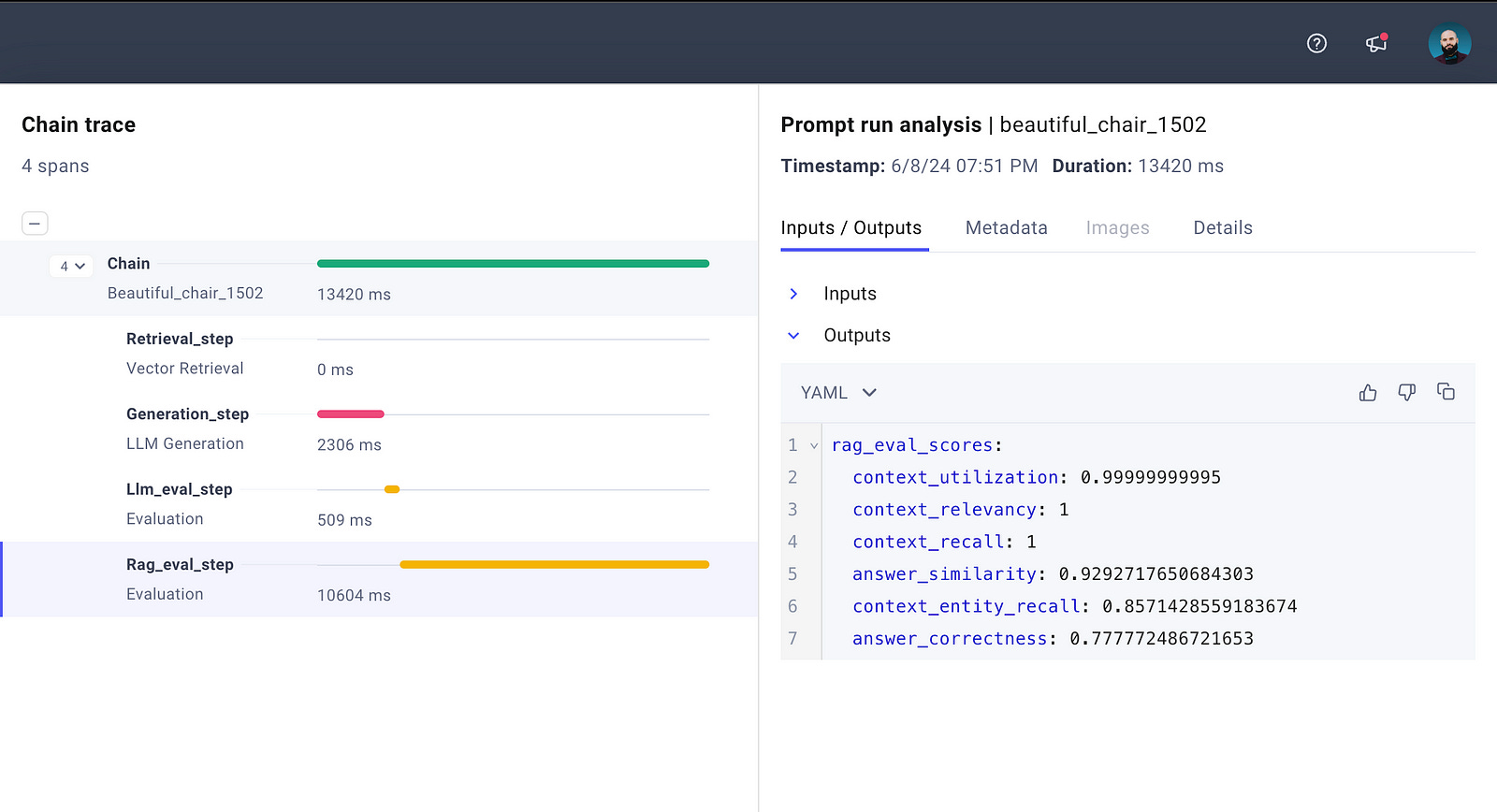
return scoreOnce the evaluation is completed, in the score variable we would have a dictionary of this format:
score = {
"context_utilization": float, # how useful is context to answer
"context_relevancy": float, # how relevant is context to query
"context_recall": float, # proportion of retrieved context
"answer_similarity": float, # semantic similarity
"answer_correctness": float, # factually correctness
"context_entity_recall": float,# recall of useful entities in context
}To be able to effectively make use of these scores and attach them to a specific evaluation flow, let’s go over the Chain Monitoring functionality and logging with CometML.
Advanced Prompt-Chain Monitoring
In this section, we’ll focus solely on how to compose end-to-end Chains and log them to Comet ML LLM. Let’s dive into the code and describe each component a Chain consists of.
📓 In Lesson8, we’ve described Prompt Monitoring advantages in more detail.
Step 1: Defining the Chain Start
Here we specify the project, workspace from Comet ML LLM where we want to log this chain and set its inputs to mark the start.
import comet_llm
comet_llm.init([project])
comet_llm.start_chain(
inputs={'user_query' : [our query]},
project=[comet-llm-project],
api_key=[comet-llm-api-key],
workspace=[comet-llm-ws]
)Step 2: Defining Chain Stages
We’re using multiple Span (comet_llm.Span)objects to define chain stages. Inside a Span object, we have to define:
category— which acts as a group key.name— the name of the current chain step (will appear in CometML UI)inputs— as a dictionary, used to link with previous chain steps (Spans)outputs— as a dictionary, where we define the outputs from this chain step.
with comet_llm.Span(
"category"="RAG Evaluation",
"name"="ragas_eval",
"inputs"={
"query": [our_query],
"context": [our_context],
"answers": [llm_answers]
}
) as span:
span.set_outputs(outputs={"rag-eval-scores" : [ragas_scores]})Step 3: Defining the Chain End
The last step, after starting the chain and appending chain-stages, is to mark the chain’s ending and returning response.
comet_llm.end_chain(outputs={"response": [our-rag-response]})📓 For the full chain monitoring implementation, check the PromptMonitoringManager class.
In the end, we would have a chain like this:
🆕 INPUT → 🆗 RETRIEVAL → 🆗 PROMPT_COMPOSE → ✅ LLM Generation → ⚙️ RAGAs Eval → 💻 Chain Monitoring → 🔚END .
Once the evaluation process is completed, and the chain is logged successfully to Comet ML LLM, this is what we’re expecting to see:

If we want to see the RAG evaluation scores, we would have to select the Rag_eval_step chain-step which logs them:
Conclusion
Here’s what we’ve learned in Lesson 10:
We’ve described the LLM-Twin RAG evaluation workflow.
We’ve exemplified a full RAG-evaluation workflow using the RAGAs framework.
How to use RAGAs and understand what’s under the hood.
Advanced Prompt & Chain monitoring using Comet ML LLM feature.
In Lesson 11, we’ll re-iterate and get a refresher on the full workflow of the LLM-Twin course, describing each module and mentioning all the resources required for you to be able to follow up and build an amazing production-ready RAG application for free, using the best insights from our experience. See you there!
🔗 Check out the code on GitHub and support us with a ⭐️
Next Steps
Step 1
This is just the short version of Lesson 10 on How to evaluate RAG applications using the RAGAs Framework
→ For…
The full implementation.
Discussion on detailed code
In-depth walkthrough of how common evaluation methods.
More insights on how to use Comet ML LLM
Check out the full version of Lesson 10 on our Medium publication. It’s still FREE:
Step 2
→ Check out the LLM Twin GitHub repository and try it yourself 🫵
Nothing compares with getting your hands dirty and building it yourself!
Images
If not otherwise stated, all images are created by the author.