



SOTA Python Streaming Pipelines for Fine-tuning LLMs and RAG - in Real-Time!
Use a Python streaming engine to populate a feature store from 4+ data sources

→ the 4th out of 11 lessons of the LLM Twin free course
What is your LLM Twin? It is an AI character that writes like yourself by incorporating your style, personality, and voice into an LLM.

Why is this course different?
By finishing the “LLM Twin: Building Your Production-Ready AI Replica” free course, you will learn how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices.
Why should you care? 🫵
→ No more isolated scripts or Notebooks! Learn production ML by building and deploying an end-to-end production-grade LLM system.
More details on what you will learn within the LLM Twin course, here 👈
Latest Lessons of the LLM Twin Course
Lesson 1: An End-to-End Framework for Production-Ready LLM Systems by Building Your LLM Twin
→ LLM Twin Concept, 3-Pipeline Architecture, System Design for LLM Twin
Lesson 2: The importance of Data Pipeline in the era of Generative AI
→ Data crawling, ETL pipelines, ODM, NoSQL Database
Lesson 3: CDC: Enabling Event-Driven Architectures
→ Change Data Capture (CDC), MongoDB Watcher, RabbitMQ queue
Lesson 4: Streaming Pipelines for Fine-tuning LLMs and RAG — in Real-Time!
In the 4th lesson, we will focus on the feature pipeline.
The feature pipeline is the first pipeline presented in the 3 pipeline architecture: feature, training and inference pipelines.
A feature pipeline takes raw data as input, processes it into features, and stores it in a feature store, from which the training & inference pipelines will use it.
The component is completely isolated from the training and inference code. All the communication is done through the feature store.
By the end of this article, you will learn to design and build a production-ready feature pipeline that:
uses Bytewax as a stream engine to process data in real-time;
ingests data from a RabbitMQ queue;
uses SWE practices to process multiple data types: posts, articles, code;
cleans, chunks, and embeds data for LLM fine-tuning and RAG;
loads the features to a Qdrant vector DB.
Note that we will only cover the vector DB retrieval client and advanced retrieval techniques in the 5th lesson!
Excited? Let’s get started!
Table of Contents:
Why are we doing this?
System design of the feature pipeline
The Bytewax streaming flow
Pydantic data models
Load data to Qdrant (our feature store)
The dispatcher layer
🔗 Check out the code on GitHub [1] and support us with a ⭐️
1. Why are we doing this?
A quick reminder from previous lessons
To give you some context, in Lesson 2, we crawl data from LinkedIn, Medium, and GitHub, normalize it, and load it to MongoDB.
In Lesson 3, we are using CDC to listen to changes to the MongoDB database and emit events in a RabbitMQ queue based on any CRUD operation done on MongoDB.
The problem we are solving
In our LLM Twin use case, the feature pipeline constantly syncs the MongoDB warehouse with the Qdrant vector DB (our feature store) while processing the raw data into features.
Why we are solving it
The feature store will be the central point of access for all the features used within the training and inference pipelines.
→ The training pipeline will use the feature store to create fine-tuning datasets for your LLM twin.
→ The inference pipeline will use the feature store for RAG.
2. System design of the feature pipeline: our solution
Our solution is based on CDC, a queue, a streaming engine, and a vector DB:
→ CDC adds any change made to the Mongo DB to the queue (read more in Lesson 3).
→ the RabbitMQ queue stores all the events until they are processed.
→ The Bytewax streaming engine cleans, chunks, and embeds the data.
→ A streaming engine works naturally with a queue-based system.
→ The data is uploaded to a Qdrant vector DB on the fly
Why is this powerful?
Here are 4 core reasons:
The data is processed in real-time.
Out-of-the-box recovery system: If the streaming pipeline fails to process a message will be added back to the queue
Lightweight: No need for any diffs between databases or batching too many records
No I/O bottlenecks on the source database
→ It solves all our problems!

How do we process multiple data types?
How do you process multiple types of data in a single streaming pipeline without writing spaghetti code?
Yes, that is for you, data scientists! Joking…am I?
We have 3 data types: posts, articles, and code.
Each data type (and its state) will be modeled using Pydantic models.
To process them, we will write a dispatcher layer, which will use a creational factory pattern to instantiate a handler implemented for that specific data type (post, article, code) and operation (cleaning, chunking, embedding).
The handler follows the strategy behavioral pattern.
Streaming over batch
Nowadays, using tools such as Bytewax makes implementing streaming pipelines a lot more frictionless than using their JVM alternatives.
The key aspect of choosing a streaming vs. a batch design is real-time synchronization between your source and destination DBs.
In our particular case, we will process social media data, which changes fast and irregularly.
Also, for our digital twin, it is important to do RAG on up-to-date data. We don’t want to have any delay between what happens in the real world and what your LLM twin sees.
That being said, choosing a streaming architecture seemed natural in our use case.
3. The Bytewax streaming flow
The Bytewax flow is the central point of the streaming pipeline. It defines all the required steps, following the next simplified pattern: “input -> processing -> output”.
As I come from the AI world, I like to see it as the “graph” of the streaming pipeline, where you use the input(), map(), and output() Bytewax functions to define your graph, which in the Bytewax world is called a “flow”.
As you can see in the code snippet below, we ingest posts, articles or code messages from a RabbitMQ queue. After we clean, chunk and embed them. Ultimately, we load the cleaned and embedded data to a Qdrant vector DB, which in our LLM twin use case will represent the feature store of our system.
To structure and validate the data, between each Bytewax step, we map and pass a different Pydantic model based on its current state: raw, cleaned, chunked, or embedded.

We have a single streaming pipeline that processes everything.
As we ingest multiple data types (posts, articles, or code snapshots), we have to process them differently.
To do this the right way, we implemented a dispatcher layer that knows how to apply data-specific operations based on the type of message.
More on this in the next sections ↓
Why Bytewax?
Bytewax is an open-source streaming processing framework that:
- is built in Rust ⚙️ for performance
- has Python 🐍 bindings for leveraging its powerful ML ecosystem
… so, for all the Python fanatics out there, no more JVM headaches for you.
Jokes aside, here is why Bytewax is so powerful ↓
- Bytewax local setup is plug-and-play
- can quickly be integrated into any Python project (you can go wild — even use it in Notebooks)
- can easily be integrated with other Python packages (NumPy, PyTorch, HuggingFace, OpenCV, SkLearn, you name it)
- out-of-the-box connectors for Kafka and local files, or you can quickly implement your own
We used Bytewax to build the streaming pipeline for the LLM Twin course and loved it.
To learn more about Bytewax, check out their Substack, where you have the chance to dive deeper into streaming engines. In Python. For FREE:
4. Pydantic data models
Let’s take a look at what our Pydantic models look like.
We defined a hierarchy of Pydantic models for:
all our data types: posts, articles, or code
all our states: raw, cleaned, chunked, and embedded
This is how the set of classes for the posts will look like ↓

We repeated the same process for the articles and code model hierarchy.
5. Load data to Qdrant (our feature store)
The first step is to implement our custom Bytewax DynamicSink class ↓

Next, for every type of operation we need (output cleaned or embedded data ), we have to subclass the StatelessSinkPartition Bytewax class (they also provide a stateful option → more in their docs)
An instance of the class will run on every partition defined within the Bytewax deployment.
In the course, we are using a single partition per worker. But, by adding more partitions (and workers), you can quickly scale your Bytewax pipeline horizontally.
Remember why we upload the data to Qdrant in two stages, as the Qdrant vector DB will act as our feature store:
The cleaned data will be used for LLM fine-tuning (used by the training pipeline)
The chunked & embedded data will be used for RAG (used by the inference pipeline)
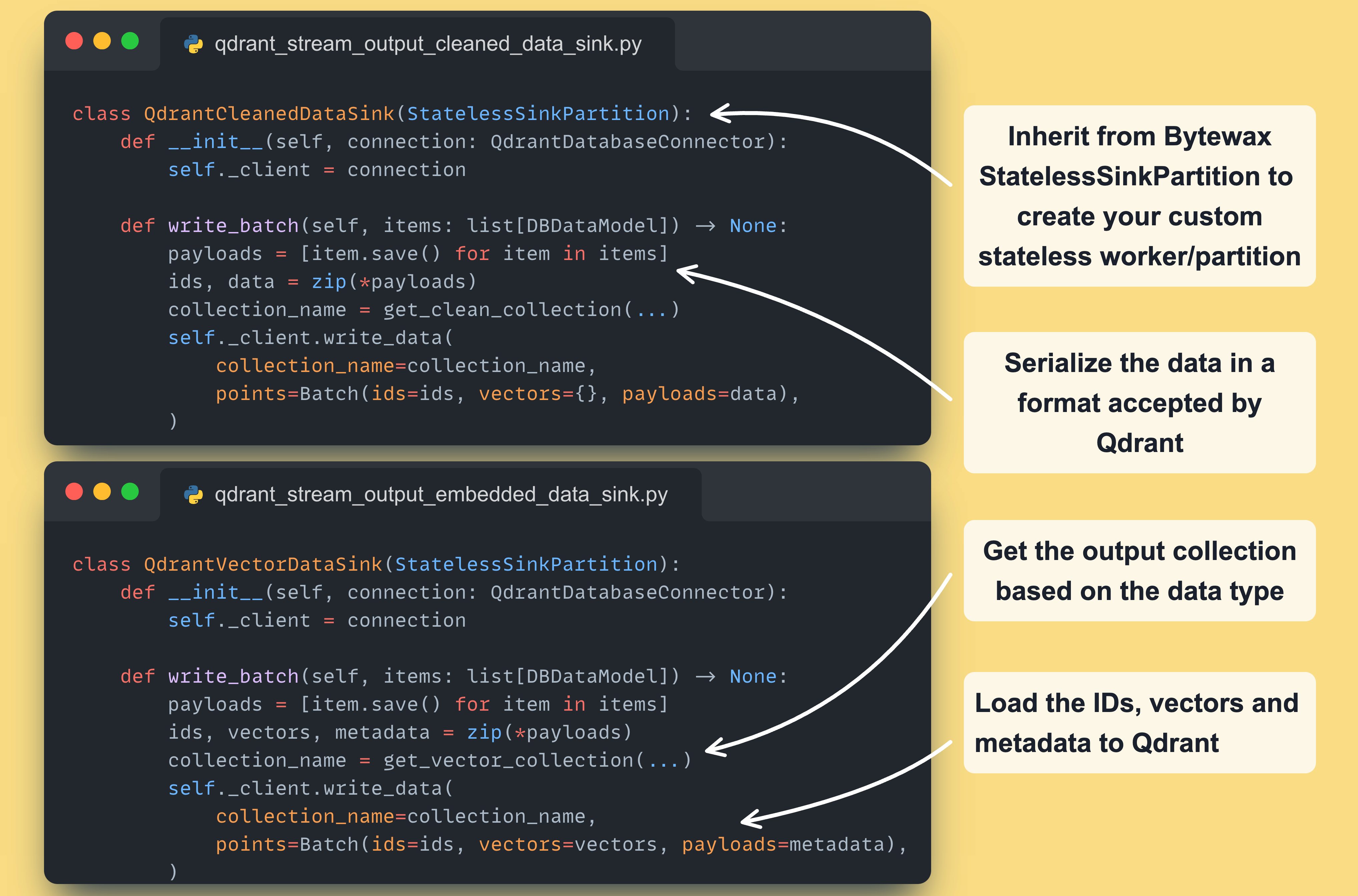
Note that we used Qdrant’s Batch method to upload all the available points simultaneously. By doing so, we reduce the latency on the network I/O side: more on that here
6. The dispatcher layer
Now that we have the Bytewax flow and all our data models.
How do we map a raw data model to a cleaned data model?
All our domain logic is modeled by a set of Handler() classes:
Now, to build our dispatcher, we need 2 last components:
a factory class: instantiates the right handler based on the type of the event
a dispatcher class: the glue code that calls the factory class and handler
Here is what the cleaning dispatcher and factory look like ↓
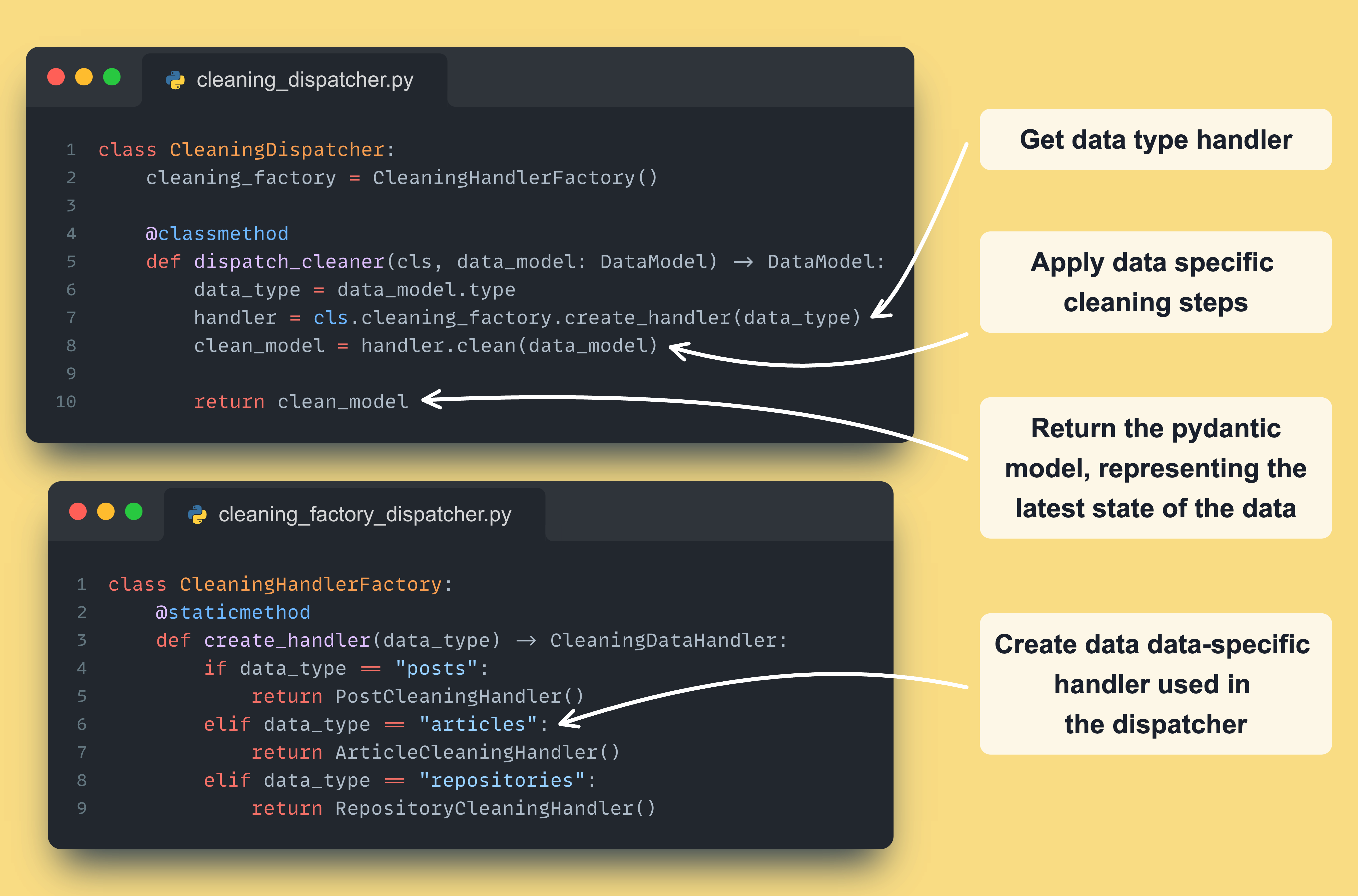
Note that we will have a different Handler() for every (data_type, state) pair — resulting in 3 x 3 = 9 different handlers.
For Example, we will have 3 handlers based on their data type for the cleaned post state: PostCleaningHandler, ArticleCleaningHandler, and RepositoryCleaningHandler.
By repeating the same logic, we will end up with the following set of dispatchers:
RawDispatcher (no factory class required as the data is not processed)
CleaningDispatcher (with a ChunkingHandlerFactory class)
ChunkingDispatcher (with a ChunkingHandlerFactory class)
EmbeddingDispatcher (with an EmbeddingHandlerFactory class)
To Summarize
In Lesson 4 of the LLM Twin course, we learned how to:
Design a streaming pipeline in Python using Bytewax
Load data to a Qdrant vector DB
Use Pydantic models to add types and validation to the data points
Implement a dispatcher layer to process multiple data types in a modular way
→ In Lesson 5, which will be held in two weeks, we will focus on the vector DB retrieval client and advanced retrieval techniques.
Next Steps
To dig into the details of the streaming pipeline and how to:
implement cleaning, chunking, and embedding strategies for digital data
design the AWS infrastructure for the streaming pipeline
understand how to run the component
Check out the full-fledged version of the article on our Medium publication.
↓↓↓
Images
If not otherwise stated, all images are created by the author.