


Hey everyone,
Thursday is coming in with a hands-on experience! But first, let me take you back to my last article, which has generated a lot of interest in our community.
Last week, we discussed multi-replica endpoint deployment with AWS Sagemaker and HuggingFace DLC.
This week, we will tackle the practical aspects of how to use this endpoint to do ‘real-time’ inference.
To emphasize the hands-on experience, we will use the endpoint we deployed last week, to solve a real-world problem: summarization documents.
Why is this important?
You cannot integrate Sagemaker Endpoints into complex systems if you don’t know for what you build these endpoints.
Therefore, you should know how to design the whole system that solves the real-world problem, Sagemaker Endpoint being just a plug-and-play component.
Today, our focus will be on hands-on experience by integrating a document summary task with a Sagemaker Endpoint.
This article's scope is to help you find solutions to any kind of real-world problems.
This week’s topics:
Overview of last week's article
Hands-on code with Inference Component
Document Summarize Task
FastAPI encapsulation
Test Real-Time Inference
Spoiler Alert: I warn you. This article is based on practical execution.
You will need the following tools:
Phone - read this article to warm up your brain.
Laptop - give your brain what it deserves: knowledge. Nothing better than a real-time coding experience.
Snacks - it will be a long journey. Food helps.
1. Overview of last week’s article
To ensure you understand today's article, you must read our last article about AWS Sagemaker deployment.
You're not digging deeper into concepts?

I hope that the title has already made you curious. Today’s article is about how we should -at least try- understand complex concepts, get into details, and not be scared about possible errors. Decoding ML Newsletter is a reader-supported publication. To receive new posts and support my work, consider becoming a free or paid subscriber.
Today's Article Architecture:
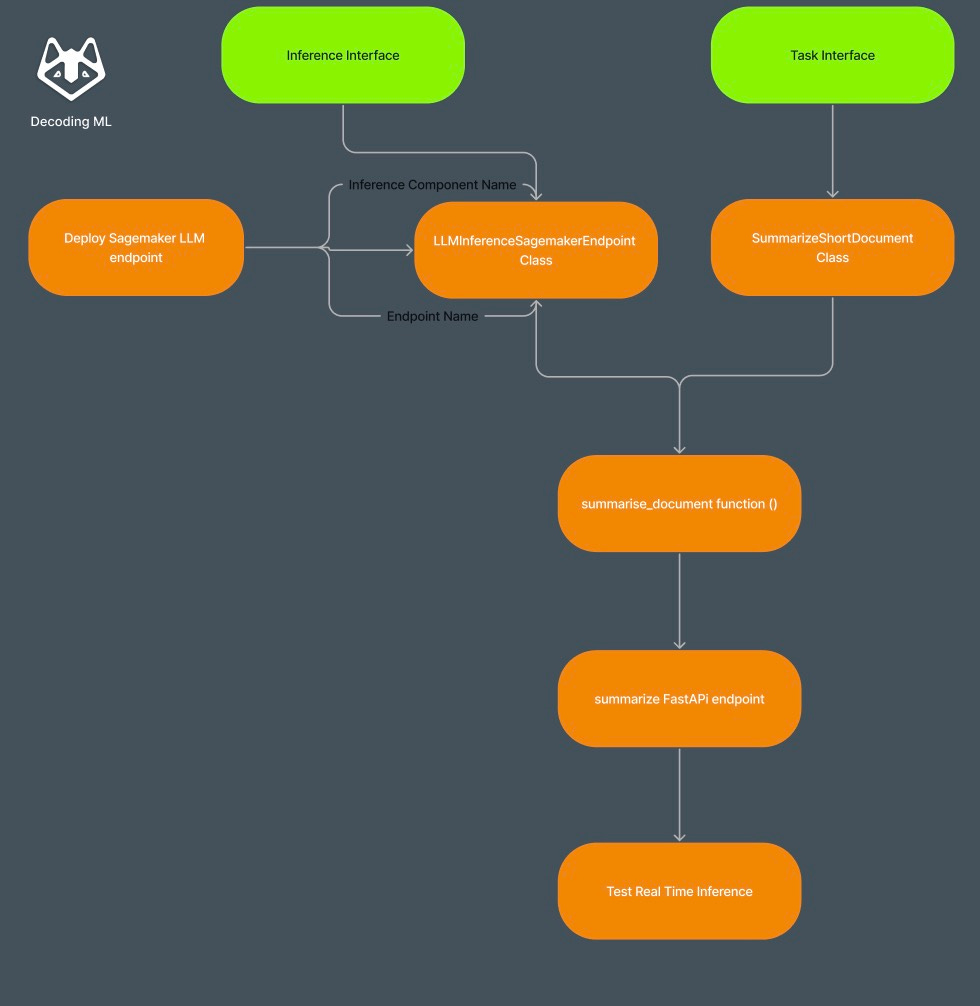
2. Hands-on code with Inference Component
Step 1: Settings.py for summarization task
For this part, we will tackle a real-world problem: document summarization.
First, it’s very important to create a settings.py file in which we capture the main components that will be used in inference. All of these are obtained after deployment endpoint configuration, inference component, and the model.
from pydantic_settings import BaseSettings
class CommonSettings(BaseSettings):
ARN_ROLE: str
HUGGING_FACE_HUB_TOKEN: strclass SummarizationSettings(CommonSettings):
SAGEMAKER_ENDPOINT_CONFIG_SUMMARIZATION: str
SAGEMAKER_INFERENCE_COMPONENT_SUMMARIZATION: str
SAGEMAKER_ENDPOINT_SUMMARIZATION: str
SAGEMAKER_MODEL_SUMMARIZATION: str
TEMPERATURE_SUMMARY: float = 0.8
TOP_P_SUMMARY: float = 0.9
MAX_NEW_TOKENS_SUMMARY: int = 150Step 2: Create inference interface
For future purposes, we can have multiple types of inferences, so it’s good to create an interface that establishes a clear contract. It specifies what methods a subclass should implement, ensuring consistency across different implementations.
from abc import ABC, abstractmethod
class Inference(ABC):
"""An abstract class for performing inference."""
def __init__(self):
self.model = None
@abstractmethod
def set_payload(self, inputs, parameters=None):
pass
@abstractmethod
def inference(self):
pass
Step 3: Create inference.py class
In the first part of the class, we define the endpoint_name (from the deployment), the inference_component_name (from the deployment), and also the input payload with all parameters like top_p, temperature, and max_new_tokens for LLM output.
class LLMInferenceSagemakerEndpoint(Inference):
"""
Class for performing inference using a SageMaker endpoint for LLM (Language Model) schemas.
"""
def __init__(
self,
endpoint_name: str,
default_payload: Optional[Dict[str, Any]] = None,
inference_component_name: Optional[str] = None,
):
super().__init__()
self.client = boto3.client("sagemaker-runtime")
self.endpoint_name = endpoint_name
self.payload = default_payload if default_payload else self._default_payload()
self.inference_component_name = inference_component_name
logging.basicConfig(level=logging.INFO, format="%(asctime)s - %(levelname)s - %(message)s")
def _default_payload(self) -> Dict[str, Any]:
"""
Generates the default payload for the inference request.
Returns:
dict: The default payload.
"""
return {
"inputs": "How is the weather?",
"parameters": {
"max_new_tokens": settings.MAX_NEW_TOKENS_EXTRACTION,
"top_p": settings.TOP_P_EXTRACTION,
"temperature": settings.TEMPERATURE_EXTRACTION,
"return_full_text": False,
},
}
def set_payload(self, inputs: str, parameters: Optional[Dict[str, Any]] = None) -> None:
"""
Sets the payload for the inference request.
Args:
inputs (str): The input text for the inference.
parameters (dict, optional): Additional parameters for the inference. Defaults to None.
"""
self.payload["inputs"] = inputs
if parameters:
self.payload["parameters"].update(parameters)
The most important part of this class is the inference function with a part in which it must be specified the inference_component_name in the invoke_args dictionary.
This parameter, tells Sagemaker to use all the copies that were deployed.
invoke_args = {
"EndpointName": self.endpoint_name,
"ContentType": "application/json",
"Body": json.dumps(self.payload),
}
if self.inference_component_name not in ["None", None]:
invoke_args["InferenceComponentName"] = self.inference_component_name
response = self.client.invoke_endpoint(**invoke_args)def inference(self) -> Dict[str, Any]:
"""
Performs the inference request using the SageMaker endpoint.
Returns:
dict: The response from the inference request.
Raises:
Exception: If an error occurs during the inference request.
"""
try:
logging.info(f"Inference request sent with parameters: {self.payload['parameters']}")
invoke_args = {
"EndpointName": self.endpoint_name,
"ContentType": "application/json",
"Body": json.dumps(self.payload),
}
if self.inference_component_name not in ["None", None]:
invoke_args["InferenceComponentName"] = self.inference_component_name
response = self.client.invoke_endpoint(**invoke_args)
response_body = response["Body"].read().decode("utf8")
return json.loads(response_body)
except Exception as e:
logging.error(f"An error occurred during inference: {e}")
raise3. Document Summarize Task
To understand better how to use the LLMInferenceSagemakerEndpoint class, we will integrate it into a summarization of real-world problems.
Step 1: Create Summarization Prompt
This is a more complex prompt, with multiple steps and instructions. It is designed for financial documents.
SUMMARY_PROMPT_TEMPLATE = (
"Task: Analyze and ai_document_tasks the provided legal or financial text enclosed within triple backticks. "
"Your summary should be concise, aiming for around 150 words, while capturing all essential aspects of the document. "
"Focus on the following key elements: "
"Think step by step:"
"1. Accurately identify the document's nature (e.g., legal letter, invoice, power of attorney) and the involved parties, including specific names, addresses, and roles (sender, recipient, debtor, creditor, etc.). "
"2. Clearly state the main purpose or subject matter of the document, including any legal or financial context (e.g., debt collection, contract details, claim settlement). "
"3. Provide exact financial details as mentioned in the document. This includes total amounts, itemized costs, interest rates, and any other monetary figures. Be precise in interpreting terms like 'percentage points above the base interest rate' and avoid misinterpretations. "
"4. If applicable, note any specific requests, deadlines, or instructions mentioned in the document (e.g., repayment plans, settlement offers). "
"5. Correctly interpret and include any relevant legal or financial terminology. "
"6. Identify and include any additional details that provide context or clarity to the document's purpose and contents, such as case numbers, invoice details, or specific legal references. "
"7. Avoid introducing information not present in the original text. Ensure your summary corrects any inaccuracies identified in previous evaluations and does not repeat them. "
"8.Recheck for step 7: do not introduce details there are not present in the original texts "
"Don't do assumption about some information.Focus only on original text"
"Text: {text} "
"SUMMARY:"
)Step 2: Create a Task Factory class to tackle multiple tasks like short documents or long documents (> 4096 tokens)
class TaskFactory:
@staticmethod
def get_task(task_type: str, *args, **kwargs) -> Task:
"""
The get_task function is a factory function that returns an instance of the appropriate Task subclass.
:param task_type: str: Specify the type of task to be created
:param *args: Pass a variable number of arguments to the function
:param **kwargs: Pass in keyword arguments to the function
:return: A task object
"""
if task_type == "summarize_short":
return SummarizeShortDocument(*args, **kwargs)
elif task_type == "summarize_long":
return SummarizeLongDocument(*args, **kwargs)
else:
raise ValueError(f"Unknown task type: {task_type}")
Step 3: Create the SummarizeShortDocument class
The SummarizeShortDocument class is responsible for generating the summary of a document by using an LLM object of type Inference.
class Task:
"""An abstract class for performing a task."""
def execute(self, data: Dict[str, Any]) -> Dict[str, Any]:
"""Executes the task."""
raise NotImplementedError
class SummarizeShortDocument(Task):
"""
A class for summarizing short documents.
Attributes:
document_type (str): The type of the document, set to 'short'.
prompt (str): The prompt for ai_document_tasks.
llm (Inference): The language model for inference.
Methods:
summarize(document_structure: dict) -> Tuple[list, str]: Summarizes the short document.
"""
document_type = 'short'
def __init__(self, prompt: str, llm: Inference, language: str = 'en'):
"""
Initializes a SummarizeShortDocument object.
Args:
prompt (str): The prompt for ai_document_tasks.
llm (Inference): The language model for inference.
language: The language for translation.
"""
self.llm = llm
self.prompt = prompt
self.language = language
def execute(self, data: dict) -> Tuple[list, str]:
logging.info('Starting short document ai_document_tasks')
try:
text = [content for page, content in data['text'].items()]
summary = self._generate_summary(text)
translated_summary = translate_large_text(text=summary, target_language=self.language)
return text, translated_summary
except Exception as e:
logging.error('Error in summarizing short document: %s', e)
raise
def _generate_summary(self, text: list) -> str:
self.llm.set_payload(
inputs=self.prompt.format(text=text),
parameters={
"max_new_tokens": settings.MAX_NEW_TOKENS_SUMMARY,
"top_p": settings.TOP_P_SUMMARY,
"temperature": settings.TEMPERATURE_SUMMARY
}
)
result = self.llm.inference()
return result[0]['generated_text']
4. FastAPI encapsulation
Maybe you wonder why we need a FastAPI endpoint if AWS Sagemaker has already done an endpoint for us.
To communicate with other systems, it’s important to encapsulate the entire business logic into a FastAPI endpoint, especially if your logic depends on multiple parameters not only the Sagemaker endpoint.
Step 1: Create a summarized document function
This function serves as the core logic that will be invoked by the FastAPI endpoint.
It takes necessary parameters such as the document ID, and it interacts with the previously set up AWS SageMaker endpoint for document summarization.
def summarize_document(
document_id: uuid,
sagemaker_endpoint: str,
summary_prompt: str,
inference_component_name: Optional[str] = None,
) -> dict[str, dict[str, str] | str]:
"""
Summarizes a document based on its ID using a language model, with the Task Factory.
Args:
document_id (uuid): The ID of the document to be summarized.
sagemaker_endpoint: The endpoint name of the SageMaker instance.
summary_prompt: The prompt for generating the summary.
Returns:
dict: A dictionary containing the summarized document information, including the summary,
document type, and original content.
"""
try:
logging.info(f"Starting summarization for document ID: {document_id}")
document_content, document_structure = get_document_content(id_document_dynamodb=document_id)
document_type = analyze_document(document_content)
# Instantiate the appropriate LLM based on document type
llm= LLMInferenceSagemakerEndpoint(endpoint_name=sagemaker_endpoint,
inference_component_name=inference_component_name)
# Select the task type
task_type = "summarize_short"
# Create the task using the Task Factory
summarization_task = TaskFactory.get_task(task_type, summary_prompt, llm)
# Execute the task
original_content, translated_summary = summarization_task.execute(document_structure)
# Prepare the result dictionary
doc = {
"summary": translated_summary,
"document_type": document_type,
"original_content": original_content,
}
logging.info(f"Summarization completed for document ID: {document_id}")
return doc
except Exception as e:
logging.error(f"Error in summarizing document ID: {document_id} - {e}")
raise eStep 2: Create the FastAPI endpoint
router = APIRouter()
@router.post("/summarize/", response_model=SummarizationResponse)
async def summarize(request: SummarizationRequest):
"""Summarize a document"""
try:
document_id_str = str(request.document_id)
result = summarize_document(
document_id=document_id_str,
sagemaker_endpoint=settings.SAGEMAKER_ENDPOINT_SUMMARIZATION,
inference_component_name=settings.SAGEMAKER_INFERENCE_COMPONENT_SUMMARIZATION,
summary_prompt=SUMMARY_PROMPT_TEMPLATE,
)
return result
except Exception as e:
raise HTTPException(status_code=500, detail=str(e))
5. Test Real-Time Inference
For this test, we need to have installed asyncio and httpx.
In my setup, I used Dynamodb Table, but you can use any database you want. I’m using only 10 examples, but you can try to send 1000 documents to see what happens. Check also the AWS Sagemaker logs and graphs to see if the endpoint is using all the copies you deployed.
import asyncio
import json
import httpx
from httpx import Timeout
async def make_async_request(url, payload):
timeout = Timeout(5.0, read=1000.0)
async with httpx.AsyncClient(timeout=timeout) as client:
response = await client.post(url, json=payload)
if response.status_code == 200:
return "Success:", response.json()
else:
return "Error:", response.status_code, response.text
async def main():
tasks = []
data = get_data_from_dynamo(table_name=settings.DYNAMO_TABLE)
dynamo_data_ids = [element["id"] for element in data][0:10]
id_to_task_mapping = {} # Create a mapping to track document_id for each task
for document_id in dynamo_data_ids:
payload = {"document_id": document_id}
# Create tasks and map them to document_id
summarization_task = make_async_request(summarization_url, payload)
# Add tasks with document_id as the key
id_to_task_mapping[summarization_task] = document_id
tasks.extend([summarization_task])
# Execute all tasks concurrently
results = await asyncio.gather(*tasks, return_exceptions=True)
results_to_save = []
for task, result in zip(tasks, results):
document_id = id_to_task_mapping[task] # Retrieve document_id for the task
if isinstance(result, Exception):
# Handle exceptions if needed
continue
if result[0] == "Success:":
result_data = result[1]
result_data["document_id"] = document_id # Ensure document_id is included in the result
results_to_save.append(result_data)
# Save the results to a JSON file
with open("results.json", "w", encoding="utf-8") as f:
json.dump(results_to_save, f, ensure_ascii=False, indent=4)
I hope this was a helpful and motivating experience to try AWS Sagemaker to solve problems.
Let me know if you want this kind of practical articles that involve more code.