



The LLM-Twin Free Course on Production-Ready RAG applications.
Learn how to build a full end-to-end LLM & RAG production-ready system, follow and code along each component by yourself.

→ the last lesson of the LLM Twin free course
What is your LLM Twin? It is an AI character that writes like yourself by incorporating your style, personality, and voice into an LLM.

Why is this course different?
By finishing the “LLM Twin: Building Your Production-Ready AI Replica” free course, you will learn how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices.
Why should you care? 🫵
→ No more isolated scripts or Notebooks! Learn production ML by building and deploying an end-to-end production-grade LLM system.
More details on what you will learn within the LLM Twin course, here 👈
The LLM-Twin Free Course
This course teaches you how to design, build, and deploy a production-ready LLM-RAG system. It covers all the components, system design, data ingestion, streaming pipeline, fine-tuning pipeline, inference pipeline alongside production monitoring, and more.
What is the course about?
We’re building a production-ready RAG system, able to write content based on your unique style, by scrapping previous posts/articles and code snippets written by you to construct a fresh and continuously updated knowledge base, generate a dataset to fine-tune a capable and efficient open-source LLM, and then interconnect all components for a full end-to-end deployment while integrating evaluation and post-deployment monitoring.
This course follows best MLOps & LLMOps practices, focusing on the 3-pipeline-design pattern for building ML-centered applications.
Lesson 1: Presenting the Architecture
Presenting and describing each component, the tooling used, and the intended workflow of implementation. The first lesson will prepare the ground by offering a wide overview of each component and consideration.
We recommend you start here.
🔗 Lesson 1: An End-to-End Framework for Production-Ready LLM Systems by Building Your LLM Twin

Lesson 2: Data Pipelines
In this lesson, we’ll start by explaining what a data pipeline is, and the key concepts of data processing and streaming, and then dive into the data scrapping and processing logic.
🔗 Lesson 2: The Importance of Data Pipelines in the Era of Generative AI
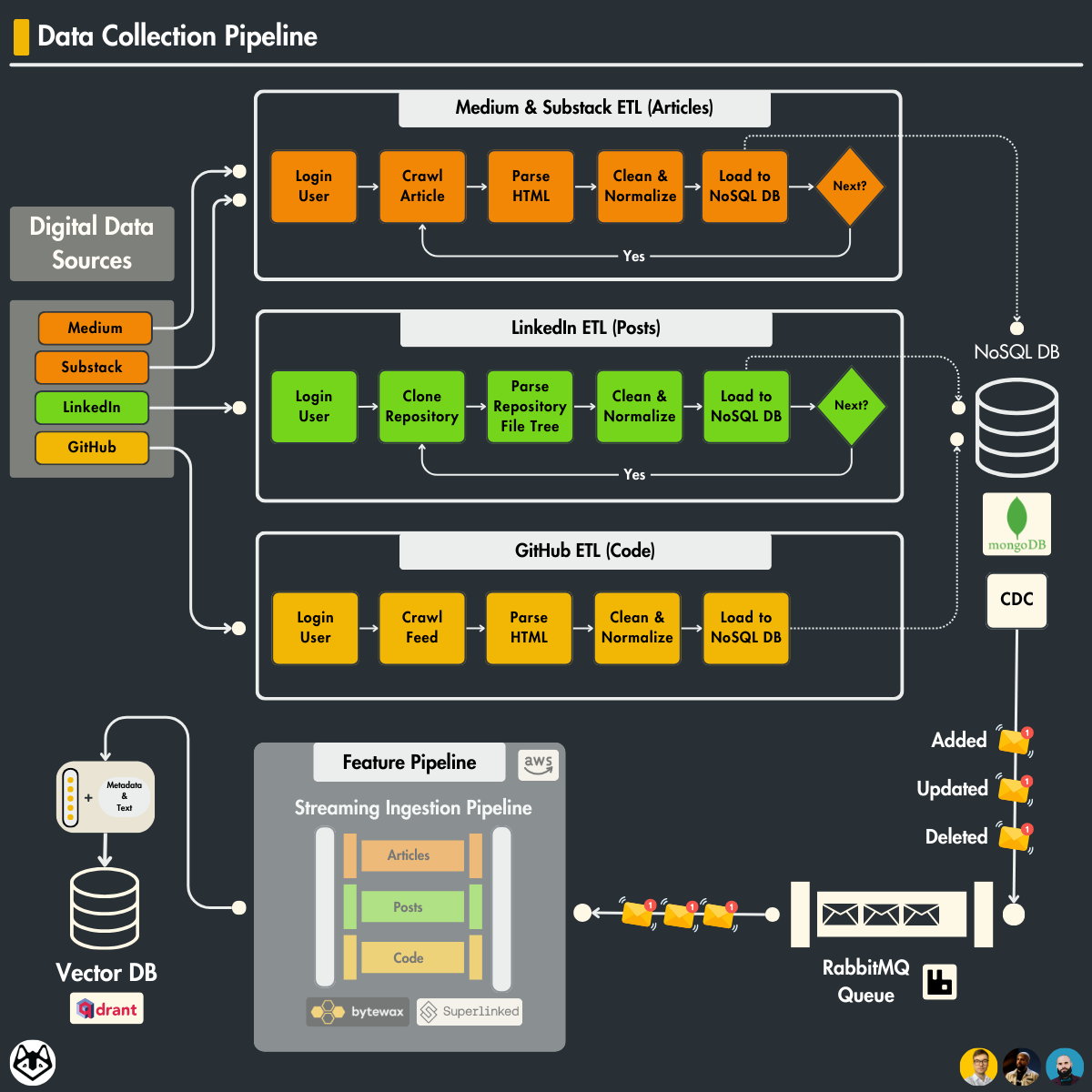
Lesson 3: Change Data Capture and Data Processing
In this lesson, we’re showcasing the CDC(Change Data Capture) integration within the LLM-Twin data pipeline. We’re showing how to set up MongoDB, the CDC approach for event-driven processing, RabbitMQ for message queuing, and efficient low-latency database querying using the MongoDB Oplog.
🔗 Lesson 3: CDC Enabling Event-Driven Architectures

Lesson 4: Efficient Data Streaming Pipelines
In this lesson, we’ll focus on the feature pipeline. Here, we’re showcasing how we ingest data that we’ve gathered in the previous lesson, and how we’ve built a stream-processing workflow with Bytewax that fetches raw samples, structures them using Pydantic Models, cleans, chunks, encodes, and stores them in our Qdrant Vector Database.
🔗 Lesson 4: SOTA Python Streaming Pipelines for Fine-tuning LLMs and RAG — in Real-Time!

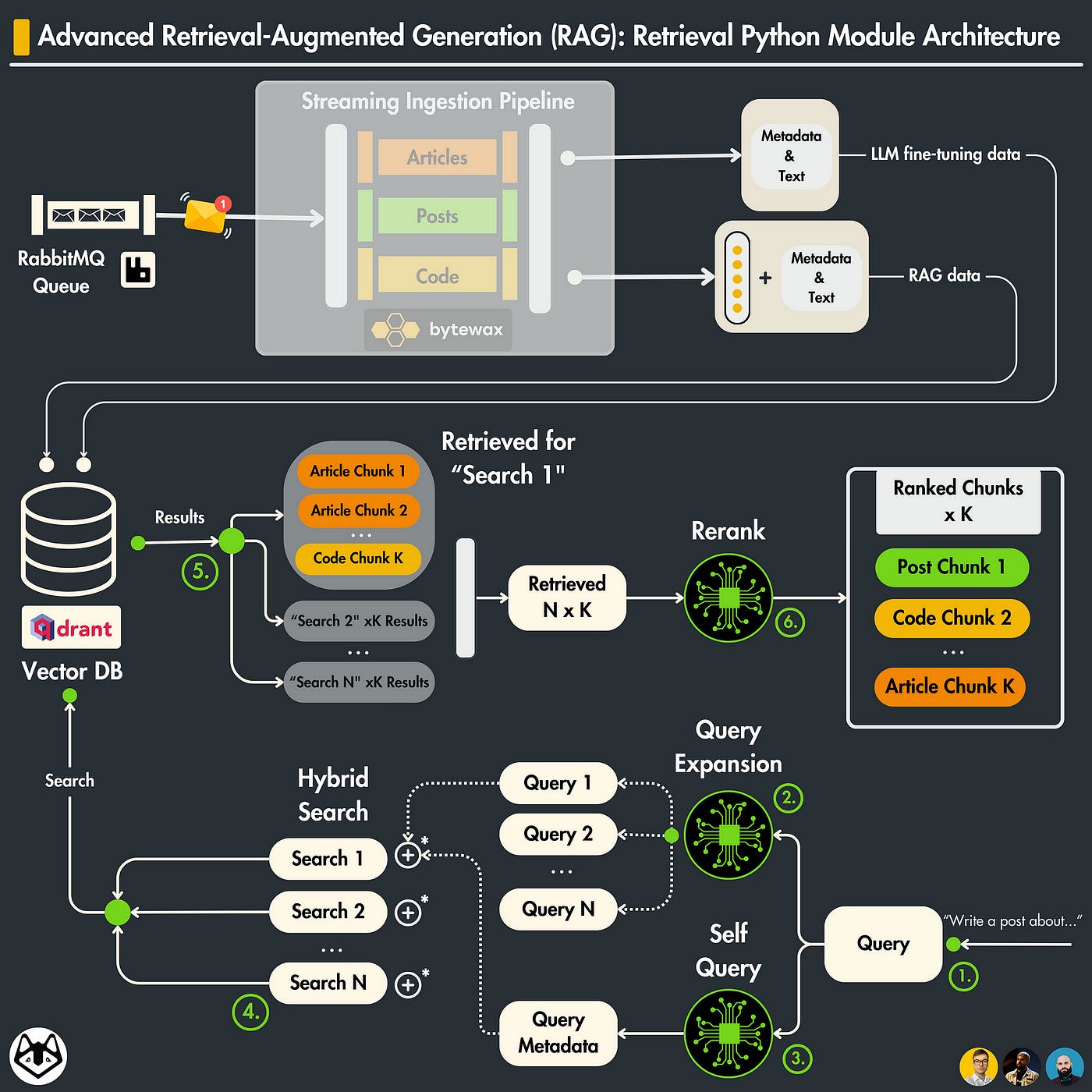
Lesson 5: Advanced RAG Optimization Techniques
In this lesson, we’ll showcase a few advanced techniques to increase the similarity and accuracy of the embedded data samples from our Qdrant Vector Database. The contents of this lesson could make a significant difference between a naive RAG application and a production-ready one.
🔗 Lesson 5: The 4 Advanced RAG Algorithms You Must Know to Implement
Lesson 6: Dataset preparation for LLM fine-tuning
In this lesson, we’ll discuss the core concepts to consider when creating task-specific custom datasets to fine-tune LLMs. We’ll use our cleaned data from our Vector Database, and engineer specific Prompt Templates alongside using GPT3.5-Turbo API to generate our custom dataset and version it on Comet ML.
🔗 Lesson 6: The Role of Feature Stores in Fine-Tuning LLMs

Lesson 7: Fine-tuning LLMs on custom datasets
We’ll show how to implement a fine-tuning workflow for a Mistral7B-Instruct model while using the custom dataset we’ve versioned previously. We’ll present in-depth the key concepts including LoRA Adapters, PEFT, Quantisation, and how to deploy on Qwak.
🔗 Lesson 7: How to fine-tune LLMs on custom datasets at Scale using Qwak and CometML

Lesson 8: Evaluating the fine-tuned LLM
In this lesson, we’re discussing one core concept of ML - Evaluation.
We’ll present the evaluation workflow we’ll showcase the full process of assessing the model’s performance using the GPT3.5-Turbo model and custom-engineered evaluation templates.
🔗 Lesson 8: Best Practices When Evaluating Fine-Tuned LLMs

Lesson 9: Deploying the Inference Pipeline Stack
In this lesson, we’ll showcase how to design and implement the LLM & RAG inference pipeline based on a set of detached Python microservices. We’ll split the ML and business logic into two components, describe each one in part, and show how to wrap up and deploy the inference pipeline on Qwak as a scalable and reproducible system.
🔗 Lesson 9: Architect scalable and cost-effective LLM & RAG inference pipelines

Lesson 10: RAG Pipeline Evaluation
In this lesson, we’re covering RAG evaluation — which is one of great importance. If no proper evaluation metrics are monitored or techniques are used, the RAG systems might underperform and hallucinate badly.
Here, we’ll describe the workflow of evaluating RAG pipelines using the powerful RAGAs framework, compose the expected RAGAs evaluation format, and capture eval scores which will be included in full LLM execution chains and logged on Comet ML LLM.
🔗 Lesson 10: Evaluating RAG Systems using the RAGAs Framework

Next Steps
Step 1
Check out the full versions of all Lessons 1-11 on our Medium publication, under the LLM-Twin Course group tag. It’s still FREE:
Step 2
→ Check out the LLM Twin GitHub repository and try it yourself 🫵
Nothing compares with getting your hands dirty and building it yourself!
Images
If not otherwise stated, all images are created by the author.