

The 4 Advanced RAG Algorithms You Must Know to Implement
Implement from scratch 4 advanced RAG methods to optimize your retrieval and post-retrieval algorithm

→ the 5th out of 11 lessons of the LLM Twin free course
Why is this course different?
By finishing the “LLM Twin: Building Your Production-Ready AI Replica” free course, you will learn how to design, train, and deploy a production-ready LLM twin of yourself powered by LLMs, vector DBs, and LLMOps good practices.
Why should you care? 🫵
→ No more isolated scripts or Notebooks! Learn production ML by building and deploying an end-to-end production-grade LLM system.
More details on what you will learn within the LLM Twin course, here 👈
Latest Lessons of the LLM Twin Course
Lesson 2: The importance of Data Pipeline in the era of Generative AI
→ Data crawling, ETL pipelines, ODM, NoSQL Database
Lesson 3: CDC: Enabling Event-Driven Architectures
→ Change Data Capture (CDC), MongoDB Watcher, RabbitMQ queue
Lesson 4: Python Streaming Pipelines for Fine-tuning LLMs and RAG - in Real-Time!
→ Feature pipeline, Bytewax streaming engine, Pydantic models, The dispatcher layer
Lesson 5: The 4 Advanced RAG Algorithms You Must Know to Implement
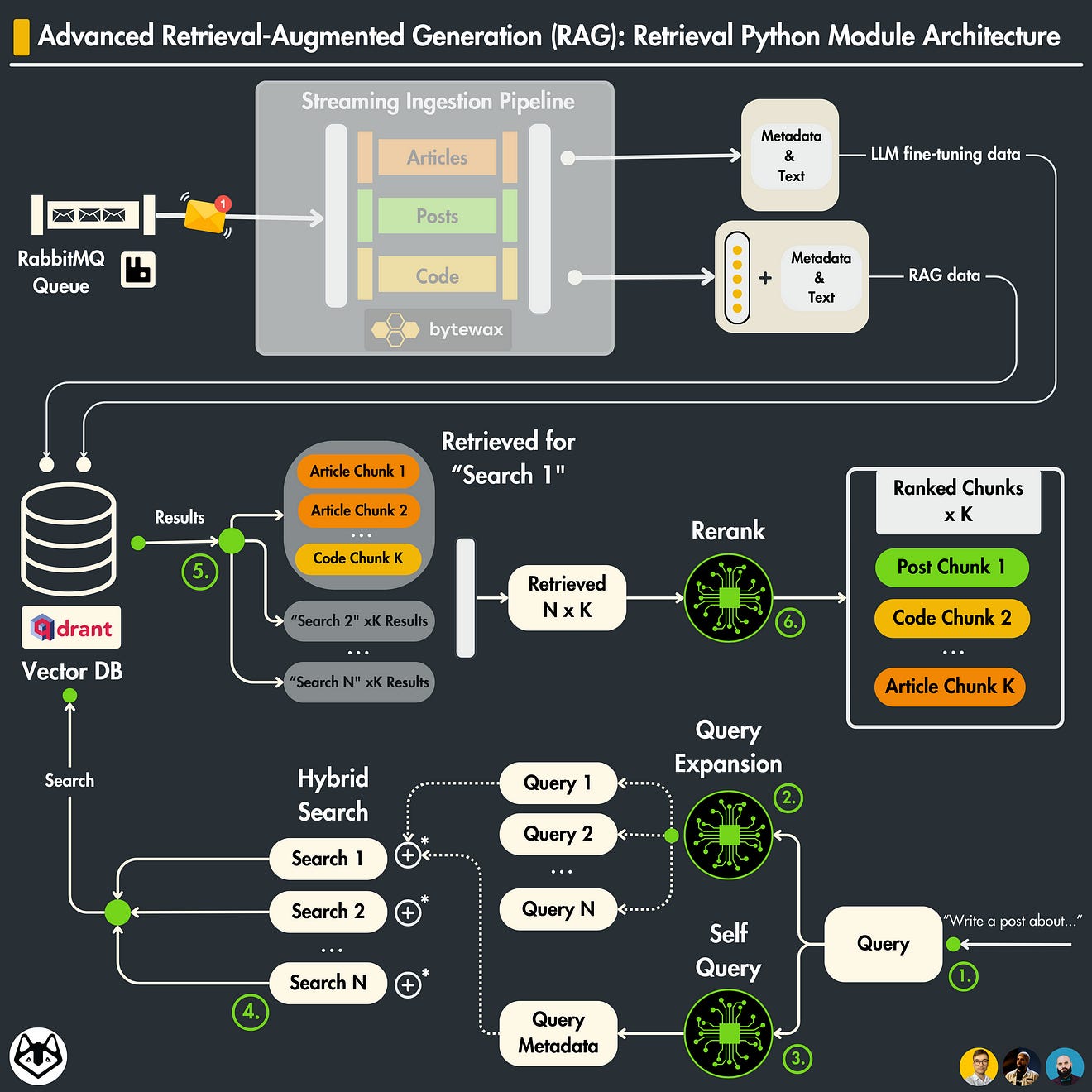
In Lesson 5, we will focus on building an advanced retrieval module used for RAG.
We will show you how to implement 4 retrieval and post-retrieval advanced optimization techniques to improve the accuracy of your RAG retrieval step.
In this lesson, we will focus only on the retrieval part of the RAG system.
In Lesson 4, we showed you how to clean, chunk, embed, and load social media data to a Qdrant vector DB (the ingestion part of RAG).
In future lessons, we will integrate this retrieval module into the inference pipeline for a full-fledged RAG system.
1. Overview of advanced RAG optimization techniques
A production RAG system is split into 3 main components:
ingestion: clean, chunk, embed, and load your data to a vector DB
retrieval: query your vector DB for context
generation: attach the retrieved context to your prompt and pass it to an LLM
The ingestion component sits in the feature pipeline, while the retrieval and generation components are implemented inside the inference pipeline.
You can also use the retrieval and generation components in your training pipeline to fine-tune your LLM further on domain-specific prompts.
You can apply advanced techniques to optimize your RAG system for ingestion, retrieval and generation.
That being said, there are 3 main types of advanced RAG techniques:
Pre-retrieval optimization [ingestion]: tweak how you create the chunks
Retrieval optimization [retrieval]: improve the queries to your vector DB
Post-retrieval optimization [retrieval]: process the retrieved chunks to filter out the noise
The generation step can be improved through fine-tuning or prompt engineering, which will be explained in future lessons.
The pre-retrieval optimization techniques are explained in Lesson 4.
In this lesson, we will show you some popular retrieval and post-retrieval optimization techniques.
2. Advanced RAG techniques applied to the LLM twin
Retrieval optimization
We will combine 3 techniques:
Query Expansion
Self Query
Filtered vector search
Post-retrieval optimization
We will use the rerank pattern using GPT-4 and prompt engineering instead of Cohere or an open-source re-ranker cross-encoder [4].
I don’t want to spend too much time on the theoretical aspects. There are plenty of articles on that.
So, we will jump straight to implementing and integrating these techniques in our LLM twin system.
But first, let’s clarify why we picked Qdrant as our vector DB ↓
2.1. Why Qdrant?
There are many vector DBs out there, too many…
But since we discovered Qdrant, we loved it.
Why?
It is built in Rust.
Apache-2.0 license — open-source 🔥
It has a great and intuitive Python SDK.
It has a freemium self-hosted version to build PoCs for free.
It supports unlimited document sizes, and vector dims of up to 645536.
It is production-ready. Companies such as Disney, Mozilla, and Microsoft already use it.
It is one of the most popular vector DBs out there.
To put that in perspective, Pinecone, one of its biggest competitors, supports only documents with up to 40k tokens and vectors with up to 20k dimensions…. and a proprietary license.
I could go on and on…
…but if you are curious to find out more, check out Qdrant ←
3. Retrieval optimization (1): Query expansion
Query expansion is quite intuitive.
You use an LLM to generate multiple queries based on your initial query.
These queries should contain multiple perspectives of the initial query.
Thus, when embedded, they hit different areas of your embedding space that are still relevant to our initial question.
You can do query expansion with a detailed zero-shot prompt.

4. Retrieval optimization (2): Self query
What if you could extract the tags within the query and use them along the embedded query?
That is what self-query is all about!
You use an LLM to extract various metadata fields that are critical for your business use case (e.g., tags, author ID, number of comments, likes, shares, etc.)
In our custom solution, we are extracting just the author ID. Thus, a zero-shot prompt engineering technique will do the job.
Self-queries work hand-in-hand with vector filter searches, which we will explain in the next section.
To define the SelfQueryTemplate, we have to:
Subclass the base abstract class
Define the self-query prompt
Create the LangChain PromptTemplate wrapper
class SelfQueryTemplate(BasePromptTemplate):
prompt: str = """
You are an AI language model assistant.
Your task is to extract information from a user question.
The required information that needs to be extracted is the user id.
Your response should consists of only the extracted id (e.g. 1345256), nothing else.
User question: {question}
"""
def create_template(self) -> PromptTemplate:
return PromptTemplate(
template=self.prompt, input_variables=["question"], verbose=True
)5. Retrieval optimization (3): Hybrid & filtered vector search
Combine the vector search technique with one (or more) complementary search strategy, which works great for finding exact words.
It is not defined which algorithms are combined, but the most standard strategy for hybrid search is to combine the traditional keyword-based search and modern vector search.
How are these combined?
The first method is to merge the similarity scores of the 2 techniques as follows:
hybrid_score = (1 - alpha) * sparse_score + alpha * dense_scoreWhere alpha takes a value between [0, 1], with:
alpha = 1: Vector Search
alpha = 0: Keyword search
Also, the similarity scores are defined as follows:
sparse_score: is the result of the keyword search that, behind the scenes, uses a BM25 algorithm [7] that sits on top of TF-IDF.
dense_score: is the result of the vector search that most commonly uses a similarity metric such as cosine distance
The second method uses the vector search technique as usual and applies a filter based on your keywords on top of the metadata of retrieved results.
→ This is also known as filtered vector search.
In this use case, the similar score is not changed based on the provided keywords.
It is just a fancy word for a simple filter applied to the metadata of your vectors.
But it is essential to understand the difference between the first and second methods:
the first method combines the similarity score between the keywords and vectors using the alpha parameter;
the second method is a simple filter on top of your vector search.
How does this fit into our architecture?
Remember that during the self-query step, we extracted the author_id as an exact field that we have to match.
Thus, we will search for the author_id using the keyword search algorithm and attach it to the 5 queries generated by the query expansion step.
As we want the most relevant chunks from a given author, it makes the most sense to use a filter using the author_id as follows (filtered vector search) ↓
self._qdrant_client.search(
collection_name="vector_posts",
query_filter=models.Filter(
must=[
models.FieldCondition(
key="author_id",
match=models.MatchValue(
value=metadata_filter_value,
),
)
]
),
query_vector=self._embedder.encode(generated_query).tolist(),
limit=k,Note that we can easily extend this with multiple keywords (e.g., tags), making the combination of self-query and hybrid search a powerful retrieval duo.
The only question you have to ask yourself is whether we want to use a simple vector search filter or the more complex hybrid search strategy.
6. Implement the advanced retrieval Python class
Now that you’ve understood the advanced retrieval optimization techniques we're using, let’s combine them into a Python retrieval class.

Now the final step is to call Qdrant for each query generated by the query expansion step ↓

Note that we have 3 types of data: posts, articles, and code repositories.
Thus, we have to make a query for each collection and combine the results in the end.
We gathered data from each collection individually and kept the best-retrieved results using rerank.
Which is the final step of the article.
7. Post-retrieval optimization: Rerank using GPT-4
We made a different search in the Qdrant vector DB for N prompts generated by the query expansion step.
Each search returns K results.
Thus, we end up with N x K chunks.
In our particular case, N = 5 & K = 3. Thus, we end up with 15 chunks.

We will use rerank to order all the N x K chunks based on their relevance relative to the initial question, where the first one will be the most relevant and the last chunk the least.
Ultimately, we will pick the TOP K most relevant chunks.
Rerank works really well when combined with query expansion.
A natural flow when using rerank is as follows:
Search for >K chunks >>> Reorder using rerank >>> Take top KThus, when combined with query expansion, we gather potential useful context from multiple points in space rather than just looking for more than K samples in a single location.
Now the flow looks like:
Search for N x K chunks >>> Reoder using rerank >>> Take top KA typical solution for reranking is to use open-source Bi-Encoders from sentence transformers [4].
These solutions take both the question and context as input and return a score from 0 to 1.
In this article, we want to take a different approach and use GPT-4 + prompt engineering as our reranker.
If you want to see how to apply rerank using open-source algorithms, check out this hands-on article from Decoding ML:

Now let’s see our implementation using GPT-4 & prompt engineering.
Similar to what we did for the expansion and self-query chains, we define a template and a chain builder ↓
class RerankingTemplate(BasePromptTemplate):
prompt: str = """
You are an AI language model assistant.
Your task is to rerank passages related to a query
based on their relevance. The most relevant passages
should be put at the beginning.
You should only pick at max {k} passages.
The following are passages related to this query: {question}.
Passages: {passages}
"""
def create_template(self) -> PromptTemplate:
return PromptTemplate(
template=self.prompt,
input_variables=["question", "passages"])…and that’s it!
Conclusion
Congratulations!
In Lesson 5, you learned to build an advanced RAG retrieval module optimized for searching posts, articles, and code repositories from a Qdrant vector DB.
First, you learned about where the RAG pipeline can be optimized:
pre-retrieval
retrieval
post-retrieval
After you learn how to build from scratch (without using LangChain’s utilities) the following advanced RAG retrieval & post-retrieval optimization techniques:
query expansion
self query
hybrid search
rerank
Ultimately, you understood where the retrieval component sits in an RAG production LLM system, where the code is shared between multiple microservices and doesn’t sit in a single Notebook.
Next week, in Lesson 6, we will move to the training pipeline and show you how to automatically transform the data crawled from LinkedIn, Substack, Medium, and GitHub into an instruction dataset using GPT-4 to fine-tune your LLM Twin.
See you there! 🤗
Next Steps
Step 1
This is just the short version of Lesson 5 on the advanced RAG retrieval module.
→ For…
The full implementation.
Discussion on our custom implementation vs. LangChain.
More on the problems these 4 advanced RAG techniques solve.
How to use the retrieval module.
Check out the full version of Lesson 5 on our Medium publication. It’s still FREE:
Step 2
→ Check out the LLM Twin GitHub repository and try it yourself 🫵
Nothing compares with getting your hands dirty and building it yourself!
Images
If not otherwise stated, all images are created by the author.
Great, thanks for sharing!