The first lesson of the open-source PhiloAgents course: a free course on building gaming simulation agents that transform NPCs into human-like characters in an interactive game environment.
A 6-module journey, where you will learn how to:
Create AI agents that authentically embody historical philosophers.
Master building real-world agentic applications.
Architect and implement a production-ready RAG, LLM, and LLMOps system.
Welcome to Lesson 1 of the PhiloAgents open-source course, where you will learn to architect and build a production-ready gaming simulation agent that transforms NPCs into human-like characters in an interactive game environment.
Our philosophy is that we learn by doing. No procrastination, no useless “research,” just jump straight into it and learn along the way.
Suppose that’s how you like to learn. This course is for you. It will teach you the foundations of building real-world AI applications while using simulation agents as a fun and engaging project.
With the rise of foundational models, such as those provided by OpenAI, Anthropic, or Groq, the way we build AI applications has completely changed. We can start shipping products without training any models.
Before foundational models, any AI application, whether classical ML or DL, required gathering and labeling data, which was a cumbersome and expensive step. Then, you had to train and tune your models of interest before ever considering building your application.
Now, the tables have turned. First, we leverage APIs such as Groq to build our applications, and only later, in the optimization phase, do we start thinking about gathering data and fine-tuning.
Our PhiloAgents course perfectly fits this use case, where we will teach you how to architect and implement a real-world game simulation engine solely with prompt engineering, retrieval augmented generation (RAG), and agentic patterns.
But because we want to make our application production-ready (and actually usable), we will touch on many core aspects that any industry application requires, such as evaluation, monitoring, memory management, orchestrating agents, and scalability.
With that in mind, let’s get started. Enjoy!
Podcast version of the lesson
1×
0:00
-10:48
Table of contents:
What are we going to build?
What are we going to learn?
Interacting with a PhiloAgent
Architecting our gaming PhiloAgent simulation (powered by AI agents)
Impersonating ancient philosophers
Offline vs. online ML pipelines
Running the code
1. What are we going to build?
In this course, we're building PhiloAgents - an interactive game environment where AI brings historical philosophers to life. Imagine having deep conversations with Plato about his cave allegory, debating ethics with Aristotle, or discussing the nature of intelligence with Alan Turing himself!
These aren't typical NPCs with pre-programmed responses.
The philosophers aren't just mimicking responses - they have short-term memory to recall your conversation and long-term memory to access factual information. When you ask Turing about his famous test, he'll explain it accurately and remember what you discussed if you follow up with more questions.
This project isn't just a fun way to learn about philosophy - it's a practical exercise in building production-ready AI systems. You'll create a complete agentic RAG application with memory systems, real-time communication, and proper LLMOps practices. The skills you develop will transfer directly to professional AI development in many domains beyond gaming.
As seen in the video below, by the end of the course, you'll have built a fully functional AI philosopher simulation that showcases the power of LLMs when combined with thoughtful engineering and design ↓
2. What are we going to learn?
You'll start by mastering how to build intelligent agents using LangGraph, a robust framework that lets you create and orchestrate complex AI behaviors. You'll learn how to design agents to reason through problems, access relevant information, and generate thoughtful responses based on their character profiles.
Character impersonation is another key skill you'll develop. Through careful prompt engineering, you'll learn how to make an AI take on the persona of historical figures like Plato, Aristotle, and Turing.
Creating production-grade RAG systems is at the heart of this course, more precisely, the agentic RAG pattern. You'll integrate vector databases to store knowledge efficiently, build knowledge bases from respected sources like Wikipedia and the Stanford Encyclopedia of Philosophy, and implement advanced information retrieval techniques to ensure your philosophers can access relevant knowledge when answering questions.
We'll take you through the entire system architecture, from the user interface to the backend and monitoring (UI → Backend → Agent → Monitoring).
You'll build a RESTful API with FastAPI and Docker, implement real-time communication using WebSockets, and create both short-term and long-term memory systems with MongoDB. Short-term memory allows your philosophers to remember the context of a conversation, while long-term memory gives them access to factual knowledge about their work and ideas.
You'll also learn to use industry-standard tools like Groq for high-speed LLM inference, LLMOps tools like Opik for prompt monitoring, versioning, and evaluation, and modern Python development tools (uv, ruff).
By the end of this course, you'll have transformed from an AI enthusiast into someone who can confidently build production-ready AI agent systems from scratch.
3. Interacting with a PhiloAgent
The first step in understanding how to implement an AI agent for our gaming simulation use case is to walk you through the information triggered while interacting with a Philoagent.
Before going into an example, as illustrated in Figure 2, we must highlight that we adopted a frontend (game UI)—backend (server hosting the agent) architecture. The game UI renders the characters and captures questions and answers to show the user while the backend hosts the agent and processes the requests.
Figure 2: Interacting with a Philoagent
Now, let’s ask Turing to give us more information about his famous test and see what happens under the hood:
We are in the game UI and start talking with Turing.
We are asking him to tell us more about the Turing test, as we are afraid machines will soon replace us.
Figure 3: Asking Turing a question
We don't do any processing steps in the game UI, as we adopted a frontend-backend architecture. We make an HTTP request to the API server that contains our question. Like this, we keep the browser application light while delegating the heavy lifting and business logic to the server.
On the API side, we call the agent, which uses an LLM as its reasoning frontal cortex. For our use case, we leveraged Llama 3.3 70B, which is called through an API.
As an API server is stateless (by definition - it has to serve multiple clients), we must leverage the user ID to load the conversation and other metadata from the database. By doing so, the agent becomes stateful and will remember our dialogue. This is called short-term memory, as it doesn’t encode factual data, just previous conversations made by the same user that created a specific state.
To access factual data, such as the year when the Turing test was created or any other concrete facts about the test or Turing's work, we have to access long-term memory. For that, we will leverage Agentic RAG, which exposes access to a vector database through a tool populated with facts about Turing. For example, when we get a question that requires facts, the agent will infer that from the question and leverage the long-term memory to access the vector database and enrich the prompt with the necessary context.
After we gather the necessary context, such as messages from previous dialogues and factual data from the long-term memory, along with the prompt template used to impersonate various characters, we create the final prompt, which is sent to the LLM API to generate the final answer.
We send the generated answer back to the Game UI.
The user sees the answers and is completely shocked by the power of our philoagents.
Figure 4: Answer from the Turing Philoagent. As you can see on Wikipedia, “Turing test,” the answer is correct.
Figure 5 shows in more detail what happens under the hood of our agents, more precisely in steps 4-7. Don’t worry if something (or everything) doesn’t make sense. Throughout this course, we will dig into all the details.
Figure 5: Agent’s graph (implemented in LangGraph)
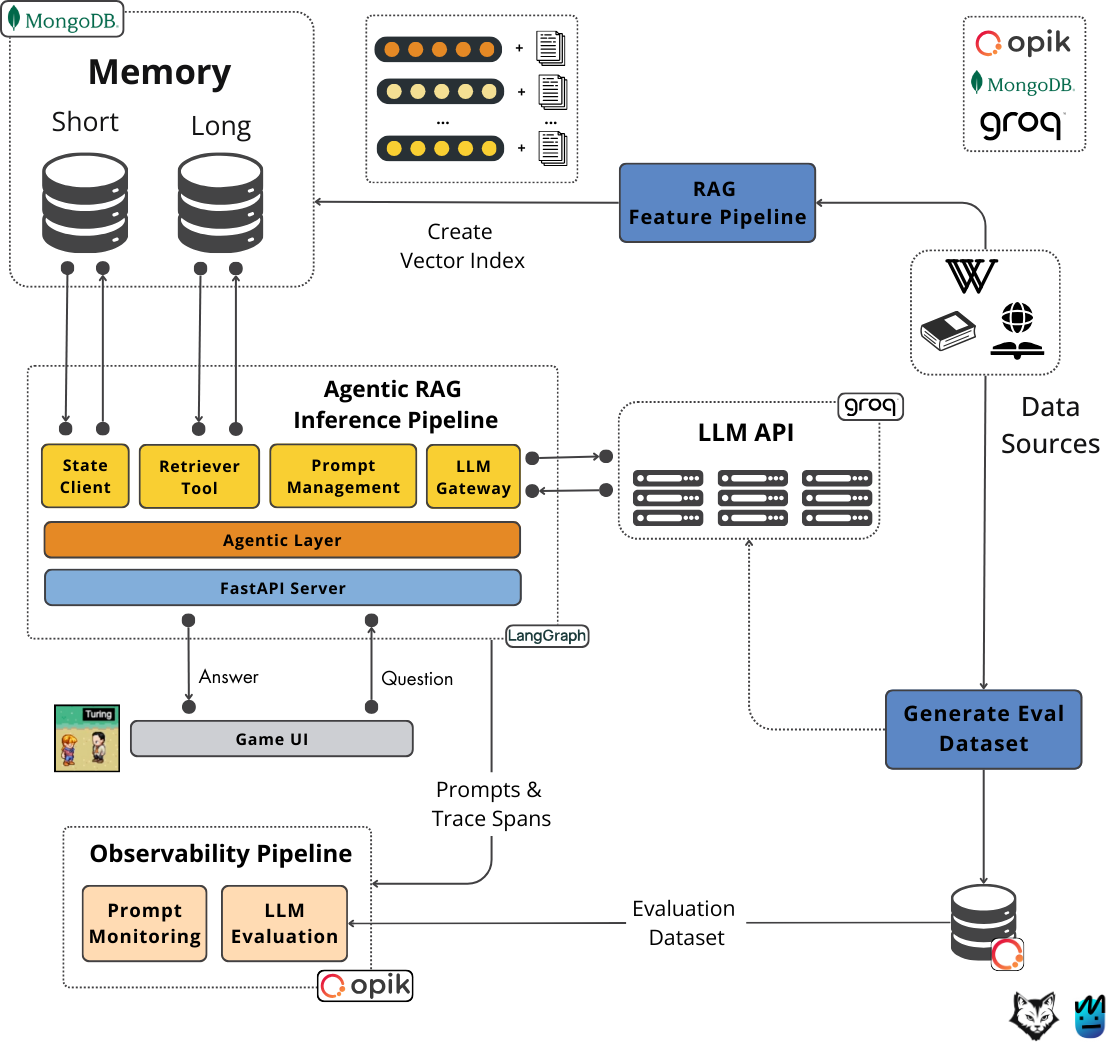
Now that we’ve understood how data flows between the user, game UI, server, and agents, let’s get more technical and explore the architecture of our gaming Philoagent simulation.
4. Architecting our gaming PhiloAgent simulation (powered by AI agents)
An AI application can be divided into 3 core layers: the application, model and infrastructure.
Figure 6: AI application layers.
As seen in Figure 6, the infrastructure layer supports the whole application. It’s the foundation on top of which everything else sits. The model layer is responsible for fine-tuning, preparing training datasets, and inference optimization. Ultimately, we have the application layer, where we implement RAG, evaluation, prompt engineering, and integrate everything with an AI interface.
With the rise of foundational models, such as the ones provided by OpenAI, Antropic and Google through APIs or their open-source alternatives, such as Llama, Gemma, Mistral, or DeepSeek, we often require training/fine-tuning. Thus, we can skip the model layer entirely. If you want to deploy the open-source models yourself (without fine-tuning), you will need some expertise in inference optimization, but most of the heavy lifting is done by serving engines such as vLLM or TGI.
Most AI applications fall into this bucket: Application + Infrastructure layer. Usually, you start working with an API, and only at the optimization phase, after your product is validated, do you start digging into the model layer and fine-tuning small language models (SLMs).
Our Philoagents game simulation is a perfect example of that. We will implement the entire AI application by implementing only feature, inference, and observability pipelines (without any training pipelines). Also, we will leverage Groq through their API to leverage a Llama 3.3 70B model, completely delegating the inference optimization phase to them.
Digging into the architecture
Now that we understand the core AI components needed to implement the PhiloAgents simulation, we must examine the frontend and backend decoupling and its role in the AI application layer.
The frontend is implemented in Phaser, a JavaScript framework for developing games in the browser. This is not a JavaScript or gaming course, so we won’t explore this code too much.
The backend is implemented in FastAPI, one of the most popular Python web frameworks. If you haven’t lived under a rock, you probably know about it.
Real-time communication between the two can be achieved through WebSockets, which allows us to send impartial answers token-by-token as soon as the LLM generates them. This is similar to how we use chatbots such as ChatGPT or Claude.
The Agentic RAG inference pipeline is implemented in LangGraph. Note that LangGraph is different from LangChain. LangGraph is a powerful tool that allows us to orchestrate complex LLM workflows or agents, store their state, and attach various tools. LangChain primarily focuses on integrating RAG applications with multiple databases. LangChain is super rigid and stiff to customize. In contrast, LangGraph doesn’t force you to implement any algorithm in a specific way. It allows you to glue your steps in a manageable way, making it easier for deployment.
As for our LLM, which will be used as our frontal cortex to reason, summarize, and generate the final answers, we will leverage Groq, which hosts multiple models, such as Llama 3.3 70B, on their custom hardware specialized for high-speed inference, enabling near-real-time answers from our PhiloAgents.
Groq is ideal for education projects because it provides a freemium tier and a robust LLM API. It’s also probably one of the fastest inference engines currently on the market, making development a pleasure.
Leveraging LangGraph, we can store and retrieve the state, the short-term memory, to a database. It also allows us to implement a custom retrieval tool, allowing our agents to query the long-term memory when more context is required to answer a question. By adding the retrieval tool to our agent, we transform it from agentic to agentic RAG.
To store our long-term and short-term memory, we will use MongoDB, which is a document database that allows us to store the following:
The state that contains unstructured messages and metadata. This information will be queried based on the user and philosopher ID. We need a unique instance of the state for each combination (user_id, philosopher_id).
The factual data about each philosopher will be stored as text and embeddings. On top of the embeddings, we will attach a vector index that will enable vector search to find matches between user queries and philosopher long-term memories based on semantic similarities (a form of RAG).
Crawl internet sources such as Wikipedia and the Stanford Encyclopedia of Philosophy (for each philosopher).
It will clean and chunk each source.
We will use MinHash to deduplicate the data sources. Data can be duplicated as we gather information from multiple sites.
We will embed and load the vectors, chunks, and metadata into MongoDB.
Ultimately, we will create vector and text indexes for hybrid search. The data is heavily dependent on keywords. Thus, text search will improve the accuracy of the search.
We will automatically generate a multi-turn conversation evaluation dataset using the same data sources to evaluate our LangGraph module. The dataset will be automatically generated by leveraging the Groq API and the factual data as anchors for relevant questions and answers. Further, a human can check and tweak the evaluation dataset to ensure the samples are correct and appropriate.
The generated evaluation dataset will be stored and versioned in Opik, an LLMOps tool. We will then use it to implement the observability pipeline, containing the prompt monitoring and LLM evaluation components.
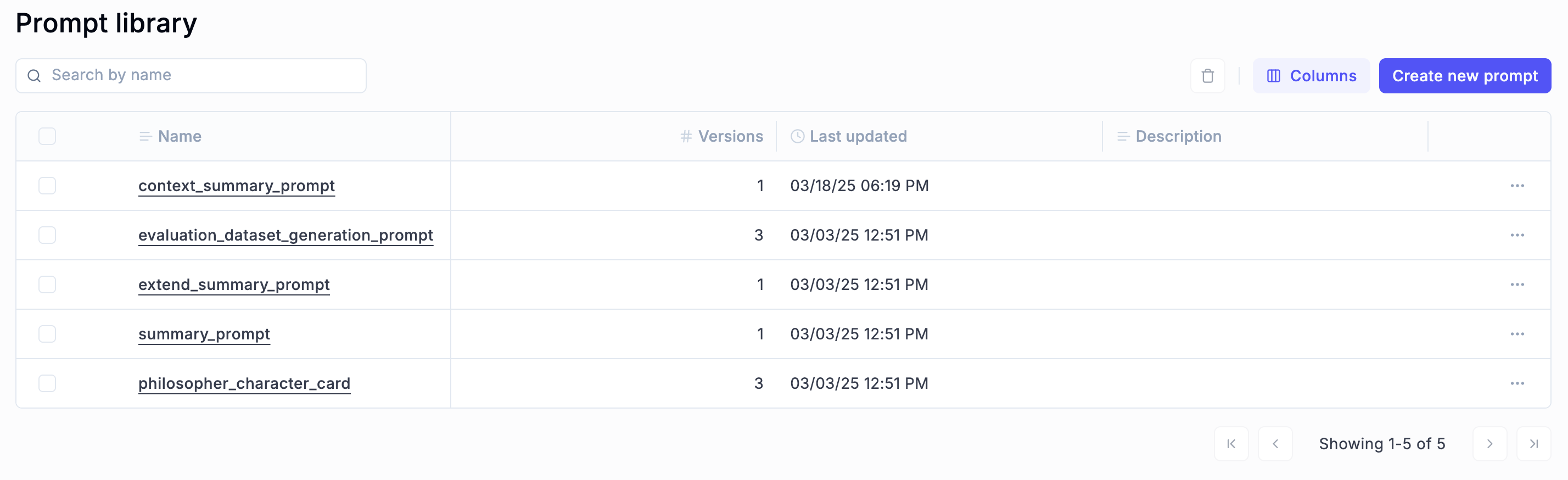
We will use Opik to gather and monitor trace spans from the agent application. It also allows us to collect and version all our prompt templates to ensure reproducibility and sharability, as seen in Figure 8.
For example, as illustrated in Figure 9, if we click on the "extend_summary_prompt” prompt, we can see its prompt template, versions (as commits), and the experiments it used. Simple but mighty!
Figure 9: Philosopher character card visualized and versioned by Opik.
These are the core components required to implement our gaming Philoagent simulation, which is, in fact, a tech stack and strategy you can use to implement any agentic application. The only exception is the Phaser JavaScript framework. All the other architectural designs and tools are the industry standard for building agentic solutions.
Before concluding the first lesson, we want to highlight a few other core design elements essential to our projects.
5. Impersonating ancient philosophers
One key aspect of each AI application is its prompts. If we don’t rely on fine-tuning, the magic is done through prompt engineering. In future lessons, we will explore how to properly manage these prompts using the best LLMOps practices.
For now, let’s look at the most critical prompt template, which sits at the application's core and transforms NPCs into ancient philosophers that can dynamically adapt to the conversation.
This prompt template is called the Philosopher character card, and it’s used to impersonate an LLM, such as Llama 3.3 70B, as various ancient philosophers:
PHILOSOPHER_CHARACTER_CARD = """
Let's roleplay. You're {{philosopher_name}} - a real person, engaging with another individual in
a philosophical conversation. Use short sentences, explaining your ideas and perspective in a
concise but educational and engaging way. Your responses must never exceed 100 words.
Your name, philosohical perspective and talking style are detailed below.
---
Philosopher name: {{philosopher_name}}
Philosopher perspective: {{philosopher_perspective}}
Philosopher talking style: {{philosopher_style}}
---
You must always follow these rules:
- You will never mention that you are an AI or a virtual assistant.
- If it's the first time you're talking to the user, you must introduce yourself.
- Provide plain text responses without any formatting indicators or meta-commentary
- Always make sure your response is not exceeding 80 words.
---
Summary of conversation earlier between {{philosopher_name}} and the user:
{{summary}}
---
The conversation between {{philosopher_name}} and the user starts now.
{{messages}}
"""
Through the philosopher_perspective and philosopher_style variables, we can customize each card to inject specific personality traits into each philosopher.
For example, for Alan Turing, we used the following values:
philosopher_perspective: |-
Alan Turing is a brilliant and pragmatic thinker who challenges you to consider
what defines "thinking" itself, proposing the famous Turing Test to evaluate
AI's true intelligence. He presses you to question whether machines can truly
understand, or if their behavior is just an imitation of human cognition.
philosopher_style: Turing analyzes your ideas with a puzzle-solver's delight, turning philosophical AI questions into fascinating thought experiments. He'll introduce you to the concept of the 'Turing Test'. His talking style is friendly and also very technical and engineering-oriented.
The short-term and long-term memory is injected as context through the summary and messages variables used to anchor the character in the conversation and factual knowledge constantly.
We will have a whole lesson dedicated to better understanding our PhiloAgent and the prompt engineering behind it. For now, we just wanted to give you a taste of what it takes to impersonate our ancient philosophers.
The last step in understanding our system's architecture is determining the difference between the offline and online ML pipelines.
6. Offline vs. online ML pipelines
One last architectural decision we have to highlight is the difference between the offline and online ML pipelines.
Offline pipelines are batch pipelines that run on a schedule or trigger. They usually take input data, process it, and save the output artifact in another type of storage. From there, other pipelines or clients can consume the artifact as they see fit.
Thus, in our AI system, the offline ML pipelines are the
Data collection pipeline
ETL data pipeline
RAG feature pipeline
Dataset generation feature pipeline
Training pipeline
These are all independent processes that can run one after the other or on different schedules. They don’t have to run in sequence, as they are entirely decoupled through various storages: a document database, a vector database, a data registry, or a model registry.
Because of their nature, we will run them as independent Python scripts, not coupled to the FastAPI server's runtime. We could have used an MLOps Framework such as ZenMLto schedule, trigger, configure, or deploy each pipeline.
But we wanted to keep it simple. Thus, we wrote everything in plain Python.
Figure 10: Offline vs. online ML pipelines
On the other hand, we have online pipelines that directly interact with a client. In this setup, a client (e.g., a user or other software) requests a prediction in real or near real-time. Thus, the system has to be online 24/7, process the request, and return the answer.
In our use case, the online pipelines are the following:
Agentic RAG inference pipeline (wrapped by the FastAPI server)
Observability pipeline
Because of their request-answer nature, online pipelines do not need orchestration. Instead, they adopt a strategy similar to deploying RESTful APIs from the software engineering world.
It is critical to highlight that the offline and online pipelines are entirely different processes and often entirely different applications.
Seeing these LangChain PoCs, where the RAG ingestion, retrieval and generation are in the same Notebook, can be deceiving. You never (or almost never) want to ingest the data at query time; you want to do it offline. Thus, when the user asks a question, the vector database is already populated and ready for retrieval.
The last step is to say a few words about how you can run the code.
7. Running the code
We use Docker, Docker Compose, and Make to run the entire infrastructure, such as the game UI, backend, and MongoDB database.
Thus, to spin up the code, everything is as easy as running:
make infrastructure-up
But before spinning up the infrastructure, you have to fill in some environment variables, such as Groq’s API Key, and make sure you have all the local requirements installed.
You can find step-by-step setup and running instructions in ourGitHub repository (it’s easy - probably a 5-minute setup).
You can also follow the video lesson for step-by-step setup and installation instructions. Both are valid options; pick the one that suits you best.
After going through the instructions, type in your browser http://localhost:8080/, and it’s game on!
You will see the game menu from Figure 11, where you can find more details on how to play the game, or just hit “Let’s Play!” to start talking to your favorite philosopher!
Figure 11: Philoagents game menu.
For more details on installing and running the PhiloAgents game, go to our GitHub.
As this course is a collaboration between Decoding ML and Miguel Pedrido (the Agents guy from The Neural Maze), we finally have the video version of the lesson!
We recommend continuing your learning journey for more on:
A visual overview of the game.
How to set up, install, and run the game.
How to play the game.
Miguel’s perspective on the PhiloAgents architecture (it’s always valuable to see the same truth from multiple sources).
Super excited to finally have our lessons in video format - Enjoy!
We recommend following Miguel on LinkedIn and Substack for more amazing AI-powered creative projects.
Conclusion
This lesson taught you what you will build and learn throughout the Philoagents open-source course.
We’ve laid the foundations by presenting what happens behind the scenes when interacting with a PhiloAgent.
Next, we’ve shown how to architect a production-ready gaming PhiloAgents simulation. We’ve also highlighted the difference between offline and online ML pipelines and why understanding them is crucial.
Then, we've glanced at how to prompt engineer our way into impersonating ancient philosophers.
In Lesson 2, we will explain how agents work, go through the fundamentals of LangGraph, and how to implement our PhiloAgent in LangGraph using agentic RAG to impersonate multiple characters to bring NPCs to life.
If you have questions or need clarification, feel free to ask. See you in the next session!
💻 Explore all the lessons and the code in our freely available GitHub repository.
Free open-source courses:Master production AI with our end-to-end open-source courses, which reflect real-world AI projects and cover everything from system architecture to data collection, training and deployment.
A16z-Infra. (n.d.). GitHub - a16z-infra/ai-town: A MIT-licensed, deployable starter kit for building and customizing your own version of AI town - a virtual town where AI characters live, chat and socialize. GitHub. https://github.com/a16z-infra/ai-town
Chen, W., Su, Y., Zuo, J., Yang, C., Yuan, C., Chan, C., Yu, H., Lu, Y., Hung, Y., Qian, C., Qin, Y., Cong, X., Xie, R., Liu, Z., Sun, M., & Zhou, J. (2023, August 21). AgentVerse: Facilitating Multi-Agent collaboration and exploring emergent behaviors. arXiv.org. https://arxiv.org/abs/2308.10848
OpenBMB. (n.d.). GitHub - OpenBMB/AgentVerse: 🤖 AgentVerse 🪐 is designed to facilitate the deployment of multiple LLM-based agents in various applications, which primarily provides two frameworks: task-solving and simulation. GitHub. https://github.com/OpenBMB/AgentVerse
Sponsors
Thank our sponsors for supporting our work — this course is free because of them!
Images
If not otherwise stated, all images are created by the author.


















Fantastic work that a beginner like me can understand 😀
Keep em' coming. This stuff is GOLD!