The third lesson of the open-source PhiloAgents course: a free course on building gaming simulation agents that transform NPCs into human-like characters in an interactive game environment.
A 6-module journey, where you will learn how to:
Create AI agents that authentically embody historical philosophers.
Master building real-world agentic applications.
Architect and implement a production-ready RAG, LLM, and LLMOps system.
Welcome to Lesson 3 of the PhiloAgents open-source course, where you will learn to architect and build a production-ready gaming simulation agent that transforms NPCs into human-like characters in an interactive game environment.
Our philosophy is that we learn by doing. No procrastination, no useless “research,” just jump straight into it and learn along the way. Suppose that’s how you like to learn. This course is for you.
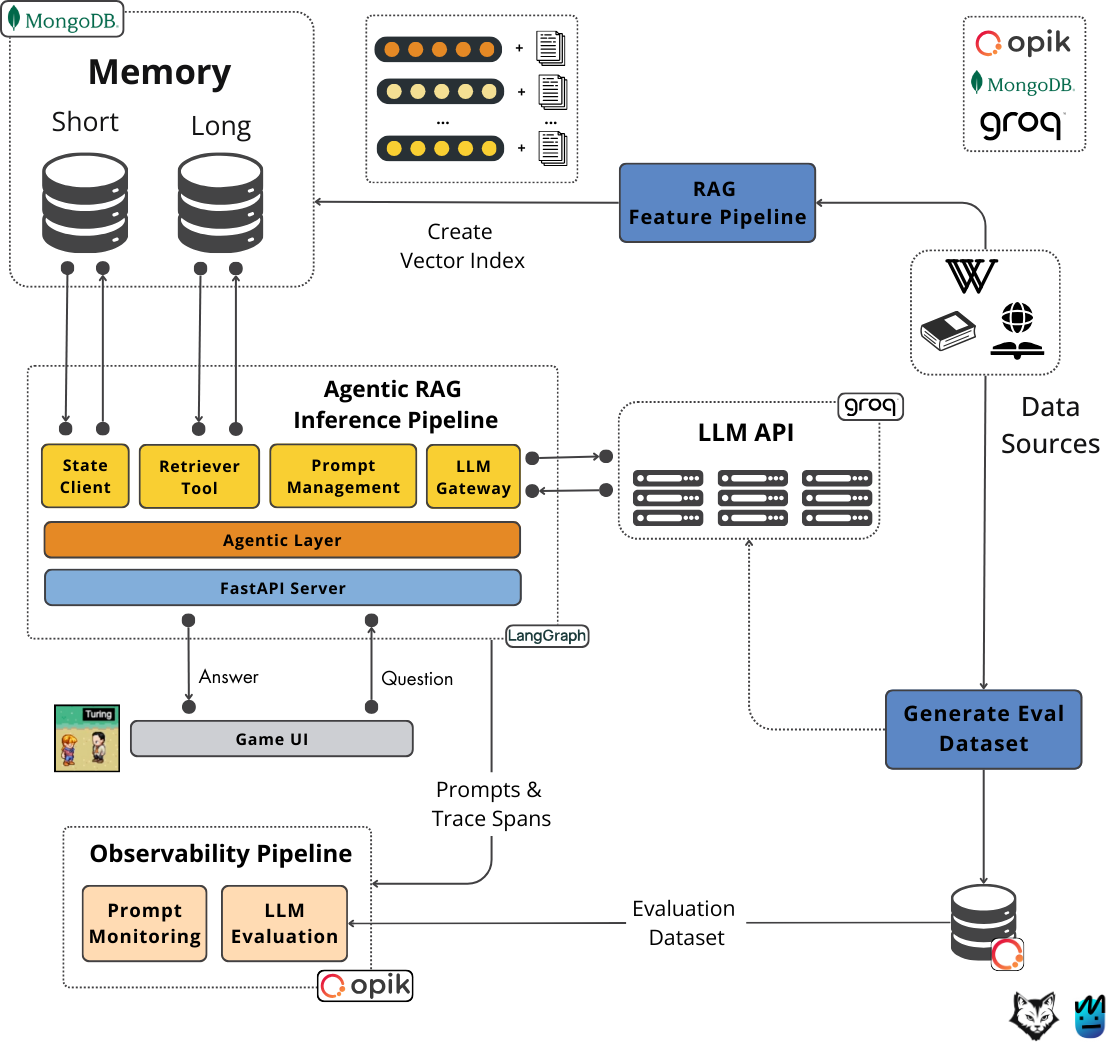
Designing a robust memory layer for your agents is one of the most underrated aspects of building AI applications. Memory sits at the core of any AI project, guiding how you implement your RAG (or agentic RAG) algorithm, how you access external information used as context, manage multiple conversation threads, and handle multiple users. All critical aspects of any successful agentic application.
Every agent has short-term memory and some level of long-term memory. Understanding the difference between the two and what types of long-term memory exist is essential to knowing what to adopt in your toolbelt and how to design your AI application system and business logic.
Also, before jumping into implementing your memory layer, you must carefully pick your database, as you have to be sure it hits your requirements, such as latency, throughput and semantic search support. But at the same time, you don’t want to slow down the progress of your development by using two or more databases, each specialized in its own thing, when a single piece of infrastructure can get the job done and allow you to focus on your application, rather than infrastructure.
With that in mind, in this lesson, we will explore short-term and long-term memory, what subtypes of long-term memory we can adopt, and how to implement them in our PhiloAgent use cases.
As a minor spoiler, long-term memory implies building an agentic RAG system!
Let’s get started. Enjoy!
Podcast version of the lesson
1×
0:00
-7:16
Table of contents:
Short-term vs. long-term memory
Adding short-term memory to our PhiloAgent
Supporting multiple conversation threads
Architecting the long-term memory layer
Choosing our agentic-ready database
Implementing procedural memory in our PhiloAgent
Implementing the RAG ingestion pipeline
Extracting philosopher data from the web
Understanding our RAG strategy
Deduplicating documents
Adding semantic memory to our PhiloAgent (aka agentic RAG)
Running the code
1. Short-term vs. long-term memory
AI memory systems can be broadly categorized into two main types: short-term and long-term.
Figure 2: Short-term vs. long-term memory
Short-term memory (or working memory)
Short-term memory, often called working memory, is the temporary storage space where an agent holds information it's currently using. This memory typically maintains active information like the current conversation context, recent messages, and intermediate reasoning steps.
Working memory is essential for agents to maintain coherence in conversations. Without it, your agent would respond to each message as if it were the first one, losing all the context and creating a frustrating user experience. The main limitation of working memory is its capacity - it can only hold a limited amount of information at once. In language models, this is directly related to the context window, which determines how much previous conversation and metadata the model can "see" when generating a response.
When implementing working memory in your agent, you need to decide what information to keep and what to discard. Most agents keep the most recent parts of a conversation, but more sophisticated approaches might prioritize keeping important information while summarizing or removing less critical details. This helps make the most efficient use of the limited working memory space.
Long-term memory: Semantic memory
Semantic memory stores factual knowledge and general information about the world. It's where your agent keeps the knowledge it has learned that isn't tied to specific experiences. This includes concepts, facts, ideas, and meanings that help the agent understand the world.
For AI assistants, semantic memory might include information about different topics, how to respond to certain types of questions, or facts about the world. This is what enables your agent to answer questions like "What's the capital of France?" or understand the concept of a vacation without needing to have experienced one.
In practice, semantic memory in AI systems is often implemented through vector databases that store information in a way that can be quickly searched and retrieved. When a user asks a question, the agent can search its semantic memory for relevant information to respond accurately.
Long-term memory: Procedural memory
Procedural memory contains knowledge about how to do things, such as performing tasks or following specific processes.
When building agents, procedural memory often takes the form of functions, algorithms, or code that defines how the agent should act in different situations. This could be as simple as a template for greeting users or as complex as a multi-step reasoning process for solving tough problems. Unlike semantic memory, which stores what the agent knows, procedural memory stores how the agent applies that knowledge.
Long-term memory: Episodic memory
Episodic memory stores specific past experiences and events. In humans, these are our autobiographical memories - the things that happened to us at particular times and places. For AI agents, episodic memory allows them to remember past user interactions and learn from those experiences.
With episodic memory, your agent can recall previous conversations with a specific user, remember preferences they've expressed, or reference shared experiences. This creates a sense of continuity and personalization, making interactions feel more natural and helpful. When a user says, "Let's continue where we left off yesterday," an agent with episodic memory can do that.
Implementing episodic memory typically involves implementing a RAG-like system on top of your conversation histories. Like this, you can move your short-term memory into the long-term memory, extracting only chunks of past conversation that are helpful to answer present queries (instead of keeping the whole history in the context window).
When implementing AI agents, you always have short-term memory. Depending on your use case, you have one or more types of long-term memory, where the procedural and semantic ones are the most common.
To avoid keeping the conversation too theoretical, let’s explore how to add short-term memory to our PhiloAgent, allowing it to maintain context throughout a conversation.
2. Adding short-term memory to our PhiloAgent
When working with LangGraph, at the core of the short-term memory, we have the state, which is used to keep in memory the context and other metadata passed between different steps of the agent:
class PhilosopherState(MessagesState):
philosopher_context: str
philosopher_name: str
philosopher_perspective: str
philosopher_style: str
summary: str
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]
More concretely, within the state, we have static information, such as the philosopher's name, perspective, and style (defined only once when initializing the agent), and dynamic context, such as the messages, summary, and context retrieved using RAG, which is different for every conversation.
Figure 3: Adding short-term memory to our PhiloAgent
The last step is to persist the state to a database, such as MongoDB, which we can do by defining a checkpointer object and attaching it to the LangGraph instance:
from langgraph.checkpoint.mongodb.aio import AsyncMongoDBSaver
async with AsyncMongoDBSaver.from_conn_string(
conn_string=settings.MONGO_URI,
db_name=settings.MONGO_DB_NAME,
collection_name=settings.MONGO_CHECKPOINT_COLLECTION,
writes_collection_name=settings.MONGO_WRITES_COLLECTION,
) as checkpointer:
graph = graph_builder.compile(checkpointer=checkpointer)
... # Rest of calling the agent logic
Persisting the state of the LangGraph agent is essential for 2 key reasons:
We can reuse the state between multiple processes (e.g., if we close the game and reopen it, the state persists).
The agent is shipped as a RESTful API. Thus, we can run the agent for multiple users without overlaps by persisting the state. We load the short-term memory specific to a given user only when required.
Another critical aspect of managing multiple users or conversations without overlapping the agent’s short-term memory is the concept of “threads.” Let’s see how it works.
3. Supporting multiple conversation threads
The concept of “threads” helps us manage multiple conversations without overlapping the agent’s state, which is known as “conversation threads”. For example, in our PhiloAgents use case, we want a different instance of the state for each conversation between you and a different philosopher.
By binding the thread_id to the philosopher_id, we ensure that each conversation between you and a different philosopher has its state and that messages do not overlap. Thus, Plato will not be aware of what you discussed with Turing. But both Plato and Turing will remember past conversations they had with you.
The current version of the PhiloAgents game supports only one user. Still, if we want to start supporting multiple users, it would be as easy as changing the thread ID to a unique string combining both the user and philosopher ID:
thread_id = f"{user_id}_{philosopher_id}"
Now that we have a strong intuition about how the PhiloAgent's short-term memory module works, let’s move on to the long-term memory layer.
4. Architecting the long-term memory layer
While short-term memory helps our PhiloAgent recall recent interactions within a single conversation, it doesn't provide a persistent knowledge base. To do that, we must implement a long-term memory layer to give the agent access to information about philosophers, their ideas, and historical context.
For this, we turn to Retrieval-Augmented Generation (RAG), a powerful technique that allows the agent to pull relevant information from an external knowledge source before generating a response.
Building a RAG system involves two distinct phases: ingestion and retrieval. The ingestion phase focuses on processing and preparing external data for efficient searching. The retrieval phase happens during a conversation, where the agent searches the prepared data for information relevant to the current context or query. We'll architect our long-term memory layer around these two core components.
The first component is the RAG ingestion pipeline,which extracts raw information about philosophers from sources such as Wikipedia and the Stanford Encyclopedia of Philosophy. The pipeline then processes the raw data and stores it in a specialized database optimized for semantic search. Think of it as building the library that the agent will consult later.
This ingestion process fits the definition of a feature pipeline. It extracts raw data and transforms it into a format our AI system can readily use as features during inference, more precisely in embeddings with valuable metadata attached to them that are discoverable through semantic and text search.
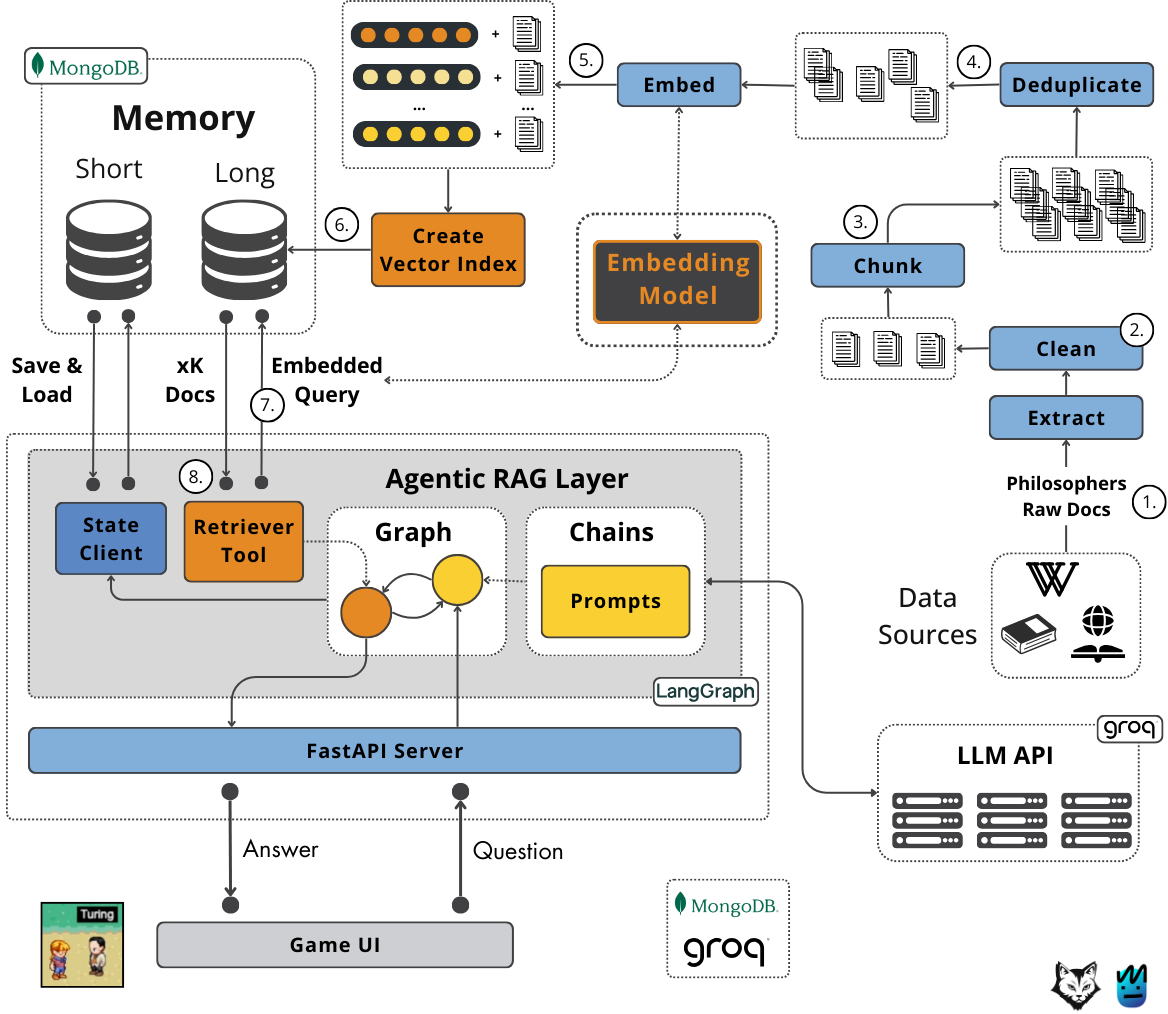
Figure 5: Architecting the long-term memory layer
Let's look at the steps involved in this RAG feature pipeline, as shown in Figure 5. It begins by extracting raw documents from our chosen data sources (Step 1). These documents then undergo cleaning (Step 2) to remove noise or irrelevant content, followed by chunking (Step 3), broken down into smaller pieces that fit into the embedding model context window. We deduplicate these chunks to ensure efficiency and relevance, removing redundant information (Step 4).
The core of the process is embedding (Step 5), where each chunk is converted into a numerical vector representation using a specific embedding model. Finally, these embeddings are loaded into our MongoDB document database (which supports vector search), and a vector index is created on top of the embeddings attribute (Step 6) to enable similarity searches.
This entire RAG feature pipeline operates offline. It doesn't run every time a user asks a question. Instead, it runs as a batch process – perhaps on a schedule, triggered by an event like new data becoming available, or run manually when we want to update the knowledge base. This separation ensures that the computationally intensive data processing doesn't slow down the agent's response time during a conversation. The knowledge base is prepared ahead of time.
The second component is the RAG retrieval tool, which comes into play during the agent's interaction with the user. When the agent needs information from its long-term memory to answer a question or contribute to the conversation, it uses this tool. The process starts by taking the user's query or relevant conversational context and embedding it using the same embedding model used during ingestion (Step 7). This ensures we're comparing apples to apples – searching for similar meanings in the same semantic space.
This embedded query is then used by the Retriever Tool (Step 8) to search the vector index in MongoDB. The tool finds the top K document chunks whose embeddings are most similar to the query embedding, which are then passed back to the agent as context.
This RAG retriever tool is integrated directly into the agent's core logic, which is known as Agentic RAG. When the agent determines it needs external knowledge, it activates this tool. The LLM then uses this context to generate an information answer, avoiding hallucination.
Before implementing the long-term memory layer, let’s understand why we chose MongoDB as our agentic-ready database.
5. Choosing our agentic-ready database
Selecting the proper database is critical for efficiently managing short-term and long-term memory. For example, it will directly impact the semantic memory, such as creating or retrieving information from it.
Thus, it is critical to pick the correct database to ensure the right latency, throughput and cost for the memory layer of your agentic application.
We chose MongoDB, a document database supporting unstructured collections combining text and vectors into a unified structure.
Remember that our PhiloAgent game heavily depends on text data and vectors. Thus, having all our data in a single database is a massive bonus.
MongoDB allows us to attach text and vector search indexes to custom fields, enabling hybrid search in our columns of choice, such as on the text and embedding of the chunk.
What we like is that by using MongoDB, we can keep all our data in a single database, which has the following benefits:
Less infrastructure to manage, as you no longer need a specialized vector database.
For RAG, you don’t have to sync the data between the raw data source and the RAG collection, simplifying your overall application. (In case you adopt new embeddings, you have to recompute only the embeddings)
Ultimately, this makes everything more manageable to set up, use, and maintain.
Also, MongoDB is a solid choice because it’s already battle-tested and has powered small to large applications for over 15 years.
But what about scalability? If all your data points, regardless of whether they are standard documents or vectors, are stored in the same database, how does this scale?
For example, in open-source databases like Postgres that use pgsearch for vector search support, you must manually create read replicas to scale your read operations.
Fortunately, MongoDB implements out-of-the-box two scaling strategies to keep requirements such as latency and throughput in check:
Workload isolation: When adding text or vector search indexes, they are isolated, scaling independently on optimized hardware.
Horizontal scalability: It supports sharding applied to text and vector search indexes.
Given this, MongoDB is a solid choice for building applications that leverage RAG and AI agents.
For more information, we recommend you check out their GenAI Cookbook GitHub repository, which contains 100+ examples of MongoDB being used to build advanced apps with RAG and AI agents.
Let’s move back to implementing our long-term memory layer, starting with the procedural memory.
6. Implementing procedural memory in our PhiloAgent
There is not much to say about the procedural memory of our PhiloAgent in addition to what we already said at the beginning of the lesson. As illustrated in Figure 6, the procedural memory is encoded directly into the LangGraph agent, explained in detail in Lesson 2.
Figure 6: Implementing procedural memory in our PhiloAgent
All the nodes, edges, tools, prompts, and API calls to Groq sum up and create the procedural memory.
Still, things get more interesting within the semantic memory layer. But we can’t talk about semantic memory without digging into RAG. As RAG sits at the core of the long-term memory layer, let’s zoom in on the RAG ingestion pipeline used to populate the database with relevant context about the philosophers.
7. Implementing the RAG ingestion pipeline
As explained in a few sections above, any RAG system is divided into the ingestion and retrieval steps. The first phase of the implementation is to understand how the RAG ingestion pipeline works. Let’s take a top-down approach by starting with the higher-level classes.
At the core of our system, we have a LongTermMemoryCreator class, that can be initialized using the settings object:
The main processing logic happens in the __call__ method. Here, we take a list of philosopher extracts, process them into chunks, remove duplicates, and store them in MongoDB:
def __call__(self, philosophers: list[PhilosopherExtract]) -> None:
if len(philosophers) == 0:
logger.warning("No philosophers to extract. Exiting.")
return
with MongoClientWrapper(
model=Document, collection_name=settings.MONGO_LONG_TERM_MEMORY_COLLECTION
) as client:
client.clear_collection()
extraction_generator = get_extraction_generator(philosophers)
for _, docs in extraction_generator:
chunked_docs = self.splitter.split_documents(docs)
chunked_docs = deduplicate_documents(chunked_docs, threshold=0.7)
self.retriever.vectorstore.add_documents(chunked_docs)
self.__create_index()
To make our stored information quickly searchable, we create a MongoDB index that supports hybrid search (combining vector similarity with text search on each document chunk containing information about our philosophers):
Now, let’s zoom in on each element from the LongTermMemoryCreator class, starting with the extraction generator that retrieves data about each philosopher.
We aim to gather data about each philosopher from Wikipedia and the Stanford Encyclopedia of Philosophy. Thus, we must search, crawl, and clean both sites for all our philosophers. Let’s get started:
At the core of our extraction pipeline, we have a generator function that processes philosophers one at a time, making it memory-efficient and perfect for handling large datasets. We also added a progress bar to track the extraction:
Wikipedia extraction is easy, as it’s used everywhere and already standardized. We use the WikipediaLoader from LangChain, which handles all the complexities of fetching and parsing Wikipedia content:
The Stanford Encyclopedia of Philosophy (SEP) extraction is more complex, as we must implement our web scraping and content cleaning logic. Still, SEP web pages are static. Thus, we use a simple WebBaseLoader that retrieves the data with a simple GET request. Further, we use BeautifulSoup to parse the HTML and extract only relevant content while excluding bibliographies and other non-essential sections:
from langchain_community.document_loaders import WebBaseLoader
def extract_stanford_encyclopedia_of_philosophy(
philosopher: Philosopher, urls: list[str]
) -> list[Document]:
def extract_paragraphs_and_headers(soup) -> str:
excluded_sections = [
"bibliography",
"academic-tools",
"other-internet-resources",
"related-entries",
"acknowledgments",
"article-copyright",
"article-banner",
"footer",
]
for section_name in excluded_sections:
for section in soup.find_all(id=section_name):
section.decompose()
content = []
for element in soup.find_all(["p", "h1", "h2", "h3", "h4", "h5", "h6"]):
content.append(element.get_text())
return "\n\n".join(content)
loader = WebBaseLoader(show_progress=False)
soups = loader.scrape_all(urls)
documents = []
for url, soup in zip(urls, soups):
text = extract_paragraphs_and_headers(soup)
metadata = {
"source": url,
"philosopher_id": philosopher.id,
"philosopher_name": philosopher.name,
}
if title := soup.find("title"):
metadata["title"] = title.get_text().strip(" \n")
documents.append(Document(page_content=text, metadata=metadata))
return documents
Now that we understand how the data is extracted, let’s examine our RAG strategy more closely.
9. Understanding our RAG strategy
When building a RAG system within the LangChain ecosystem, we mainly need text splitters (used to chunk the documents), embedding models, and retrievers (used to talk to the database). Other frameworks might use different terminology, but any RAG system has the same components at its core.
We use MongoDBAtlasHybridSearchRetriever from LangChain that combines the power of vector search with traditional text search to find the most relevant documents in our MongoDB Atlas database(Atlas is the fully managed cloud option of MongoDB that simplifies deploying and scaling). Combining vector and search indexes is a common strategy in the RAG world. They provide the best from both worlds: the flexibility of semantic search and the sniper-focused precision of text search to find exact word matches. This is important to remember because semantic search is bad regarding keyword matching. That’s why text search complements it:
The vector and full-text penalty parameters control the weight of each index. In our case, we want to consider both indexes 50%, but for example, if we picked (90, 10), then the semantic search results would have been more predominant with 90% of the results.
To make our retriever more accessible, we wrap it in a helper function that handles the embedding model initialization:
We use open-source embedding models from Hugging Face to generate embeddings. To load them, we use LangChain’s HuggingFaceEmbeddings wrapper class. In our use case, we use a “sentence-transformers/all-MiniLM-L6-v2” to keep the RAG system light and be able to run it on any machine, but you can easily switch it to any other model through the settings object, which can be configured through the .env file:
Finally, to chunk our documents before embedding, out of simplicity, we use the RecursiveCharacterTextSplitter from LangChain. This naive solution works quite well because we work with simple web documents that contain only text and are structured nicely in paragraphs. But most probably we could have done better with other, more advanced chunking techniques, such as semantic or context chunking:
The retriever, embedding model and chunking algorithm are the core elements of any RAG system. Let’s move on to the final puzzle: deduplicating documents.
As we extract data for each philosopher from Wikipedia and SEP, we will end up with duplicates in our knowledge base, which can drastically reduce the performance of our retrieval system.
For example, when a user asks Turing about his test, we might retrieve five document chunks containing the same information, formulated differently, rather than five different pieces of information. The key to RAG is to cover as much information as possible in our context and not repeat the same information.
Here is the trick: the duplicates between the two data sources will not be exact, as the articles are written by different people. Then, you might think that we might use embedding models to deduplicate this. We could, but that can be very slow.
Thus, we used MinHash, one of the most popular algorithms for deduplicating documents, which uses hashes to compute a fuzzy representation of each document, which can be used to calculate the similarity between two pieces of text. It’s similar to embeddings, but because it uses hashes, it is much faster but fuzzier. Because it’s fast and has a fuzzy nature (remember that we explicitly don’t want exact matches), it’s perfect for our use case.
Let’s see how it works:
We start with the deduplicate_documents function, which is a wrapper function that calls the MinHash algorithm and removes the duplicates based on a given threshold:
def deduplicate_documents(
documents: List[Document], threshold: float = 0.7
) -> List[Document]:
if not documents:
return []
duplicates = find_duplicates(documents, threshold)
indices_to_remove = set()
for i, j, _ in duplicates:
# Keep the document with more content
if len(documents[i].page_content) >= len(documents[j].page_content):
indices_to_remove.add(j)
else:
indices_to_remove.add(i)
return [doc for i, doc in enumerate(documents) if i not in indices_to_remove]
The real magic happens in the find_duplicates function, where we use MinHash and Locality Sensitive Hashing (LSH) to identify similar document pairs efficiently. First, we create MinHash signatures for each document by processing its content into word-based shingles, also known as N-grams. In our use case, we used 3-grams (we used datasketch for the MinHash and LSH algorithms):
from datasketch import MinHash, MinHashLSH
def find_duplicates(
documents: List[Document],
threshold: float = 0.7,
num_perm: int = int(settings.RAG_CHUNK_SIZE * 0.5),
) -> List[Tuple[int, int, float]]:
minhashes = []
for doc in documents:
minhash = MinHash(num_perm=num_perm)
text = doc.page_content.lower()
words = re.findall(r"\w+", text)
# Create shingles (3-grams of words)
for i in range(len(words) - 3):
shingle = " ".join(words[i : i + 3])
minhash.update(shingle.encode("utf-8"))
minhashes.append(minhash)
By playing around with the number of permutations of the MinHash algorithm, you can control the “fuzziness” of the algorithm. Higher permutations result in better matches, while lower permutations produce more fuzziness.
Next, we use LSH to find similar document pairs efficiently. This is much faster than comparing every possible pair of documents. We create an LSH index (similar to a vector index), add all documents to it, and then query it to find similar documents:
lsh = MinHashLSH(threshold=threshold, num_perm=num_perm)
# Add documents to LSH index
for i, minhash in enumerate(minhashes):
lsh.insert(i, minhash)
duplicates = []
for i, minhash in enumerate(minhashes):
similar_docs = lsh.query(minhash)
# Remove self from results
similar_docs = [j for j in similar_docs if j != i]
# Find duplicates
for j in similar_docs:
similarity = minhashes[i].jaccard(minhashes[j])
if similarity >= threshold:
# Ensure we don't add the same pair twice (in different order)
pair = tuple(sorted([i, j]))
duplicate_info = (*pair, similarity)
if duplicate_info not in duplicates:
duplicates.append(duplicate_info)
return duplicates
Note how similar this is to a RAG system. But instead of using an embedding model to compute a document's representation, we used MinHash, which uses a hash function to create a fuzzy representation of each document.
11. Adding semantic memory to our PhiloAgent (aka agentic RAG)
The last phase of implementing our memory layer is to connect the agent to MongoDB, our semantic memory, and transform it into agentic RAG!
We will do that by wrapping the LangChain retriever as a tool and connecting it to the agent as a separate node that can be accessed whenever the agent decides it needs more context about a specific philosopher.
Hooking the semantic memory (usually implemented as a vector database) through a tool is known as agentic RAG. It’s that simple!
In other words, instead of querying the vector database through a static step only once, by hooking it as a tool, the agent can dynamically decide how many times it needs to query the semantic memory until it has enough context to answer a given query.
Figure 7: Adding semantic memory to our PhiloAgent
To transform the retriever into a tool, we have to use a few LangChain utilities:
from langchain.tools.retriever import create_retriever_tool
from philoagents.application.rag.retrievers import get_retriever
from philoagents.config import settings
retriever = get_retriever(
embedding_model_id=settings.RAG_TEXT_EMBEDDING_MODEL_ID,
k=settings.RAG_TOP_K,
device=settings.RAG_DEVICE)
retriever_tool = create_retriever_tool(
retriever,
"retrieve_philosopher_context",
"Search and return information about a specific philosopher. Always use this tool when the user asks you about a philosopher, their works, ideas or historical context.",
)
tools = [retriever_tool]
Next, we convert it to a LangGraph ToolNode:
from langgraph.prebuilt import ToolNode
retriever_node = ToolNode(tools)
Ultimately, we have to hook it to the LangGraph graph, as follows:
The last step in this lesson is understanding how to run the code.
12. Running the code
We use Docker, Docker Compose, and Make to run the entire infrastructure, such as the game UI, backend, and MongoDB database.
Thus, to spin up the code, everything is as easy as running:
make infrastructure-up
But before spinning up the infrastructure, you have to fill in some environment variables, such as Groq’s API Key, and make sure you have all the local requirements installed.
After having the infrastructure up and running (e.g., MongoDB), run the following to create the long-term memory:
make create-long-term-memory
For more details, our GitHub repository has step-by-step setup and running instructions (it’s easy—probably a 5-minute setup).
You can also follow the first video lesson, where Miguel explains the setup and installation instructions step-by-step. Both are valid options; choose the one that suits you best.
After going through the instructions, type in your browser http://localhost:8080/, and it’s game on!
You will see the game menu from Figure 8, where you can find more details on how to play the game, or just hit “Let’s Play!” to start talking to your favorite philosopher!
Figure 8: Philoagents game menu.
For more details on installing and running the PhiloAgents game, go to our GitHub.
As this course is a collaboration between Decoding ML and Miguel Pedrido (the Agent’s guy from The Neural Maze), we also have the lesson in video format.
The written and video lessons are complementary. Thus, to get the whole experience, we recommend continuing your learning journey by following Miguel’s video ↓
Conclusion
This lesson from the PhiloAgents course taught you how to design and implement the memory layer of your agents.
We walked you through the difference between short-term and long-term memory. Afterward, we showed you how to implement both in our PhiloAgent use case using LangChain and MongoDB.
In Lesson 4, we will take the project a step further and deploy the LangGraph PhiloAgent as a RESTful API using FastAPI and WebSockets (to send the generated answer token-by-token instead of waiting for the entire answer).
💻 Explore all the lessons and the code in our freely available GitHub repository.
Free open-source courses:Master production AI with our end-to-end open-source courses, which reflect real-world AI projects and cover everything from system architecture to data collection, training and deployment.
Sumers, T. R., Yao, S., Narasimhan, K., & Griffiths, T. L. (2023, September 5). Cognitive architectures for language agents. arXiv.org. https://arxiv.org/abs/2309.02427
A16z-Infra. (n.d.). GitHub - a16z-infra/ai-town: A MIT-licensed, deployable starter kit for building and customizing your own version of AI town - a virtual town where AI characters live, chat and socialize. GitHub. https://github.com/a16z-infra/ai-town
Chen, W., Su, Y., Zuo, J., Yang, C., Yuan, C., Chan, C., Yu, H., Lu, Y., Hung, Y., Qian, C., Qin, Y., Cong, X., Xie, R., Liu, Z., Sun, M., & Zhou, J. (2023, August 21). AgentVerse: Facilitating Multi-Agent collaboration and exploring emergent behaviors. arXiv.org. https://arxiv.org/abs/2308.10848
OpenBMB. (n.d.). GitHub - OpenBMB/AgentVerse: 🤖 AgentVerse 🪐 is designed to facilitate the deployment of multiple LLM-based agents in various applications, which primarily provides two frameworks: task-solving and simulation. GitHub. https://github.com/OpenBMB/AgentVerse
Sponsors
Thank our sponsors for supporting our work — this course is free because of them!
Images
If not otherwise stated, all images are created by the author.













Very important read for the Agentic RAG.
I love every bit of what you communicate and contribute to the community